导读 在我国数字经济进入快车道的时代背景下,如何开展数据安全治理,提升全社会的“安全感”,已成为普遍关注的问题。近些年,随着各类数据法律法规的出台,安全事件也层出不穷,对企业的数据安全性也提出了非常大的挑战,小到数据字段的管理,大到任务、角色或者规则等方面,到底如何做数据安全的治理,本文通过数据安全治理6问,逐步深入展开探讨。
全文目录:
1. 数据安全治理与法律法规
2. 数据安全治理的本质与方向
3. 阿里云DataWorks数据治理实践
4. 阿里云数据安全治理场景与案例
5. Q&A
分享嘉宾|刘天鸢 阿里云 产品经理
编辑整理|天天 golden tech
内容校对|李瑶
出品社区|DataFun
01 数据安全治理与法律法规
下面和大家分享下数据安全治理与相关的法律法规。
1. 逐步完善的法律法规
近年来,数据安全相关的法律法规正在逐步完善。
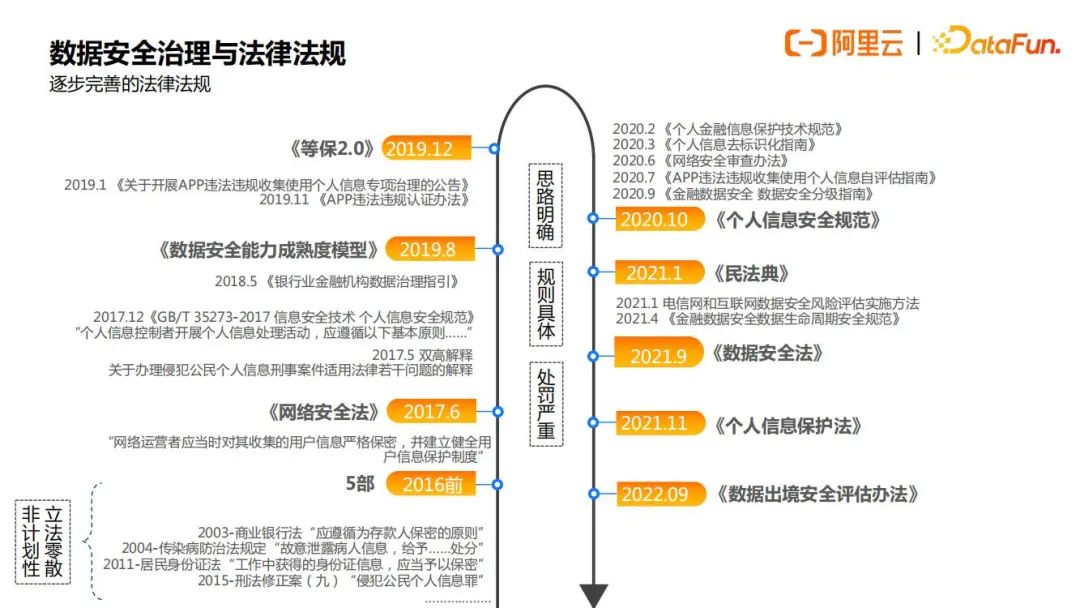
相关立法之前普遍是以国家或者行业的推荐性标准的形式存在,我们所熟知的数据安全能力成熟度模型(DSMM)中也提到过,但是现今已经明确立法,如果不遵守相关法律法规,未履行数据安全保护义务,可能会被立案处罚。
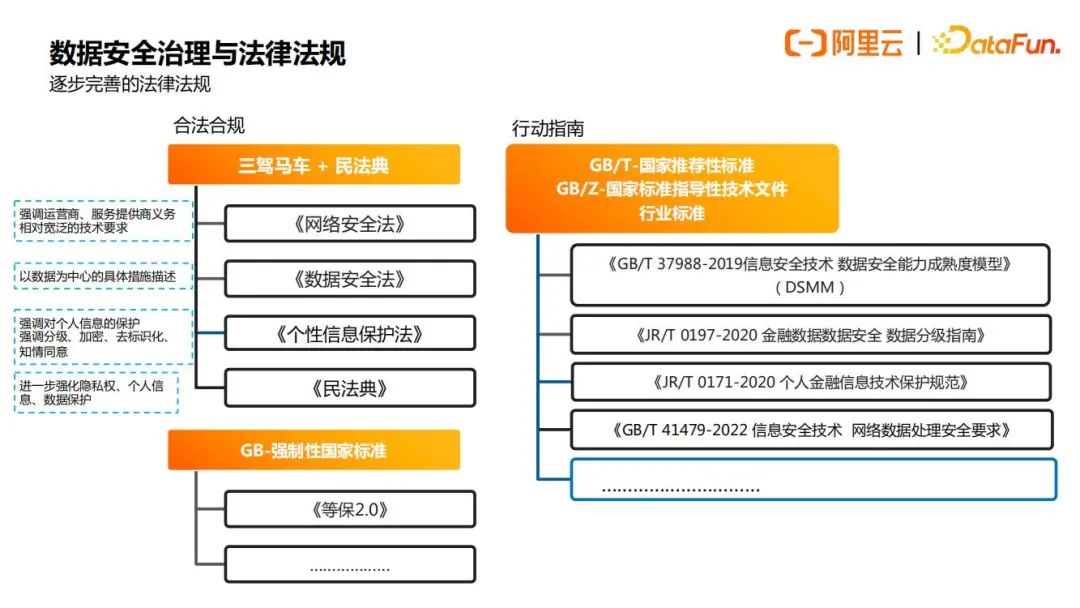
我们也可以看到,当今的企业开展相关业务时,只要存在数据收集行为,就需要重点关注以及遵守上图所示的法律法规(网络安全法、数据安全法、个性信息保护法、民法典,还有一个强制性的国家标准即等保2.0),企业开展数据安全治理可以参照相关行动指南(例如DSMM、特定行业相关标准等),从而使得企业的经营合法合规。
2. 法律条文中的数据安全治理
数据安全法中,第四条、第十一条都分别提到了数据安全治理,可见在政企单位数据安全建设中,建立数据安全治理体系的重要性。

例如下图中所示,数据安全法第21条,应该对数据实行分类分级保护,之前也是存在于国家或者行业的一些推荐性标准,目前已明确写入到了数据安全法中。
同样下图所示,数据安全法第24条,提到了数据安全审查,落地到数据安全治理中,就是操作审计,第29条提到了发现数据安全缺陷、漏洞等风险时应当立即采取的补救措施,发生数据安全事件时应当立即采取的处置措施,对应到数据安全治理中就是对风险的响应,主要包括告警、阻断、审批等方面。

接下来我们一起讨论一下数据安全治理的本质和方向。
02 数据安全治理的本质与方向
提到数据安全治理,首先会想到保护企业自己的资产,数据资产最主要的就是数据表,但是数据安全治理保护的重点不是数据表本身,而是其中对应的信息,保护信息的手段是通过控制数据的访问(信息存储在数据中,数据存储在IAAS层)来实现的,如下图所示:
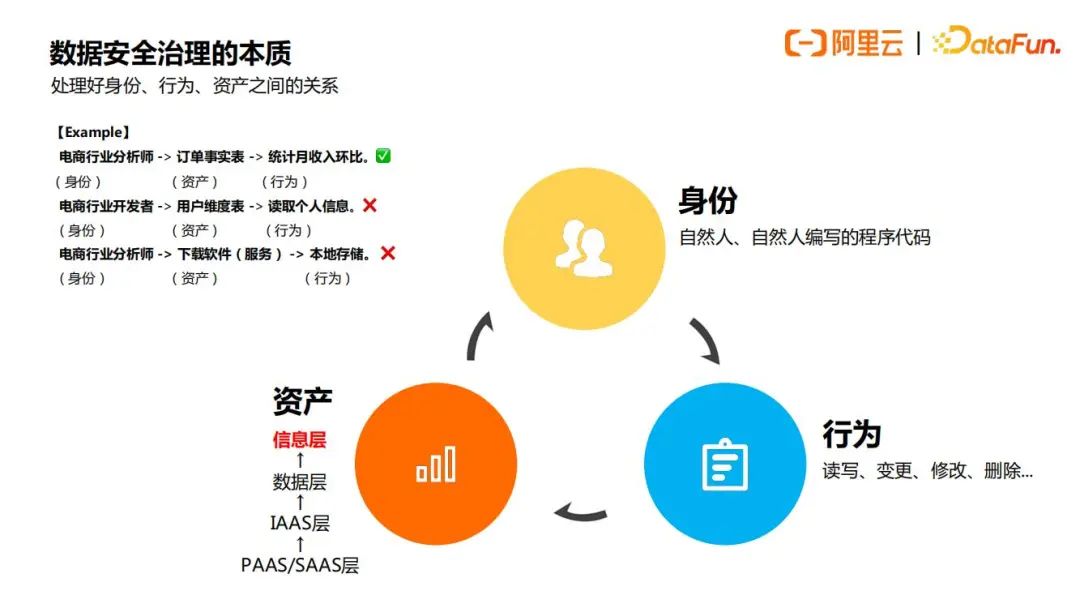
所以说,数据安全治理的本质是处理好身份、行为、资产之间的关系。
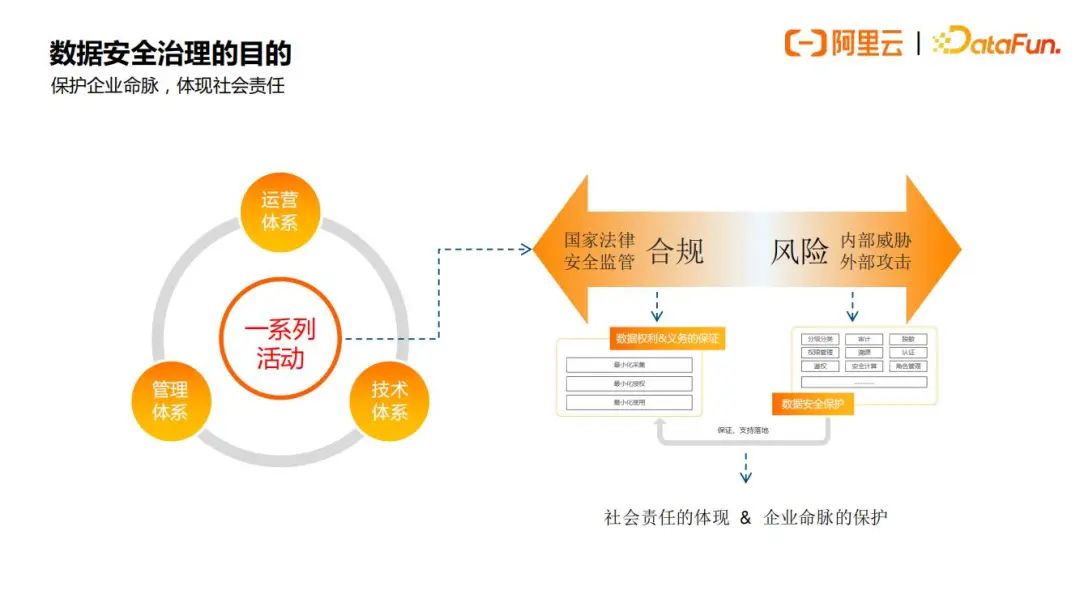
说到数据安全治理,它实际上是一系列运营体系,管理体系,技术体系融合起来的一系列活动,以前企业做数据安全治理的目的更多是从风险的角度出发,保证企业数据资产不被泄漏,不被滥用,随着现在监管越来越严格,更多是为了合规性考虑,但是仅仅是为了合规性,就有些舍本逐末了,做数据安全治理更多的是一种社会责任的体现,同时也是企业命脉的保护。
针对数据安全治理思路,从过去到现在是有一个本质的变化,以前更多的是南北向安全,也即企业南北向的数据访问和传输安全,防止外部入侵。现在更多的是东西向安全,涉及到了过程安全技术,实际上是对人员行为的管控,是一种零信任的理念,始终不信任,一直在验证,通过一些基线规则、检查规则,或者是机器学习的风险行为识别模型等进行拦截管控。

因为是对人员行为的管控,所以做数据安全治理就需要组织的建设,制度的建设和技术工具的建设,我们讨论的更多是技术工具的建设,以及基于技术工具的最佳实践的经验分享。
在开展数据安全治理之前,管理者都应该清楚下图所示的6个问题:
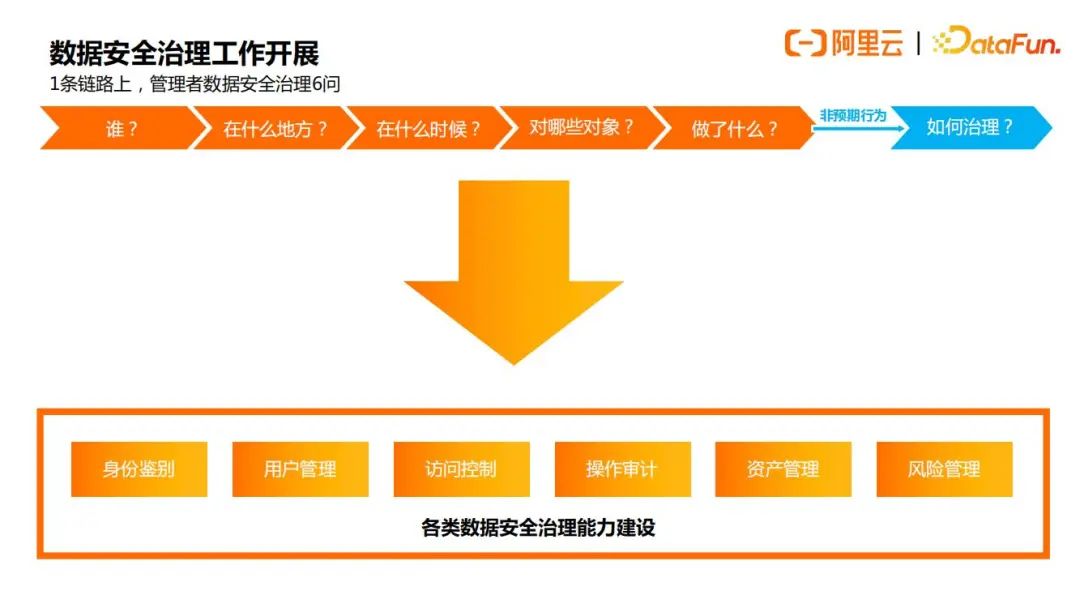
如果想要较好地回答上面的6个问题,就需要从身份鉴别,用户管理,访问控制,操作审计,资产管理,风险管理这几个方面做安全能力的建设。
03 阿里云DataWorks数据治理实践
接下来分享Dataworks如何帮助管理者去解决上述6个问题。
首先介绍一下什么是Dataworks,如下图所示:

DataWorks基于MaxCompute、Hologres、EMR、AnalyticDB、CDP等大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据可视化开发治理平台。从2009年起,DataWorks不断沉淀阿里巴巴大数据建设方法论,支撑数据中台建设,DataWorks十多年沉淀了数百项核心能力,通过智能数据建模、全域数据集成、高效数据生产、主动数据治理、全面数据安全、数据分析服务六大全链路数据治理的能力,帮助企业治理内部不断上涨的“数据悬河”,释放企业的数据生产力。这次主要分享的是Dataworks中数据安全相关的功能。
接下来我们具体看下上面提到的6个问题:
1.问题1 – 谁?通过什么方式来使用大数据系统
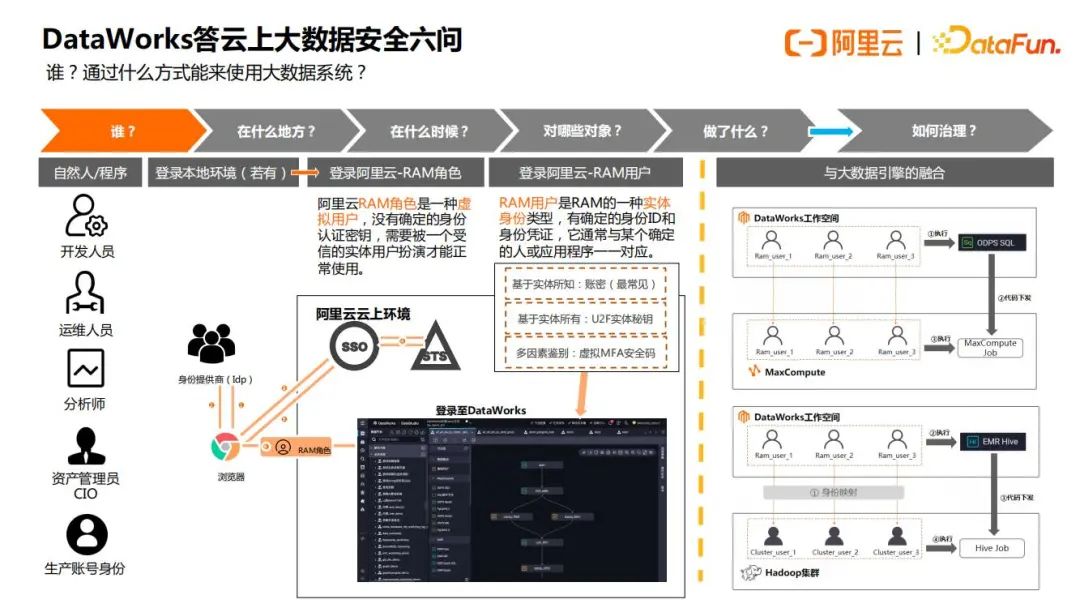
这个问题比较好理解,就是本公司内部的开发、运维、分析师,资产管理员,CIO或者开发者写的程序来访问大数据系统,Dataworks支持自主可用的登录认证体系,例如:部分企业倾向于统一管理一套本地账号(通过AD,LDAP等),而不愿去管理另一套云账上的子账号。DataWorks满足这样的诉求,即:允许用户通过本地账号扮演一个RAM Role,以角色扮演的方式登录至阿里云管控台上使用DataWorks;RAM Role可被加入至DataWorks空间作为空间成员,一个RAM Role可以被多人扮演,也可以被一个人扮演。通过这样的方式企业实现统一认证管理,做到自主可控。当然Dataworks也支持普通的云账号登录方式,RAM同时也支持U2F实体密钥,多因素鉴别等。登录完成之后,Dataworks开发平台与后端的大数据引擎(自研Maxcompute, 开源EMR,CDH等)对接时,身份都可以做到一一映射,保证用户的身份是可靠的。
2.问题2 – 用户在哪、通过哪个入口访问大数据系统
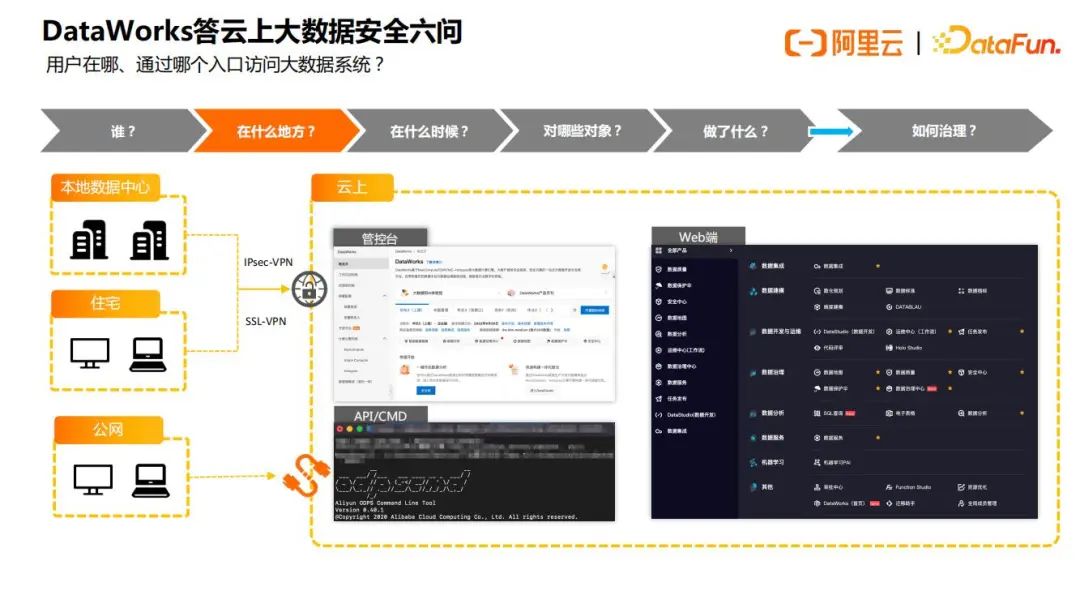
跟大多数产品一样,用户会在自己的办公地点、住宅、或者公网,通过VPN或者公网访问,Dataworks的入口有管控台,命令行OpenAPI,Web端,大部分用户是通过Web端去访问的,对于不同类型的用户,可以限制访问某一个云上的入口。
3.问题3 – 用户在什么时候会访问大数据系统
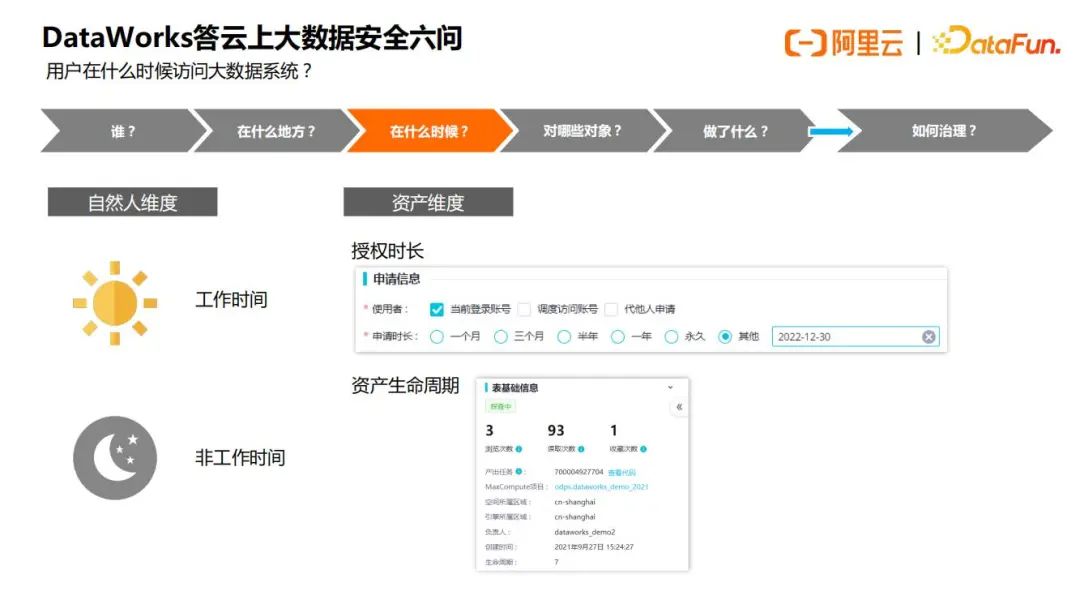
如果按照自然人维度来看,分为工作时间和非工作时间访问,根据业界相关统计,在非工作时间产生的数据风险,尤其是非工作目的的数据访问行为会占较大比例,在做一些数据审计时,要求着重去分析非工作时间的访问行为,例如:0点至凌晨5点的访问行为会不会存在风险。
如果从资产维度来看,对数据表申请访问时,一般会填写数据表使用时长,另外数据表本身也有生命周期,在这两个时间段内,都是可以正常去访问数据表资产。
4.问题4 – 哪些资产对象会被操作
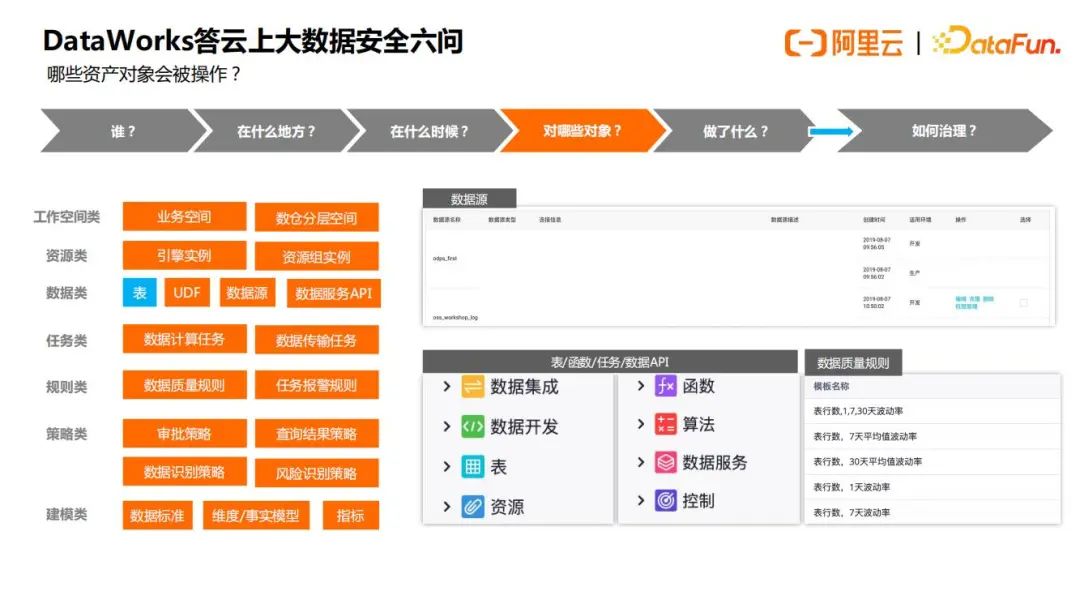
资产操作一般是对数据表的操作,除了数据表之外,还有对很多其他实体的访问也会间接地产生数据风险,例如UDF,有些UDF会有读表的逻辑,如果UDF授权不当的话,就会有越权访问的风险,另外Dataworks上也可以配置数据源,如果数据源不做访问控制,也是很危险的,还有数据服务,Dataworks有发布数据服务API的能力,可以把某张数据表快速生成HTTP Restful的API,发布出去的API也需要做访问管控。除了以上这些比较典型的资产对象,还有很多其他类型的,比如数据计算任务,如果提交到生产的SQL除了写入之外,还有读操作,这样也可以在运维界面直接读出数据。还有审批策略,如果策略配置不当,会产生越权审批,另外还有数据质量规则,如果配置不当,会导致产生脏数据或者资损等,所以上图中列出资产对象都是需要得到保护和访问管控的。
5.问题5 – 用户在何时何地可能产生哪些行为
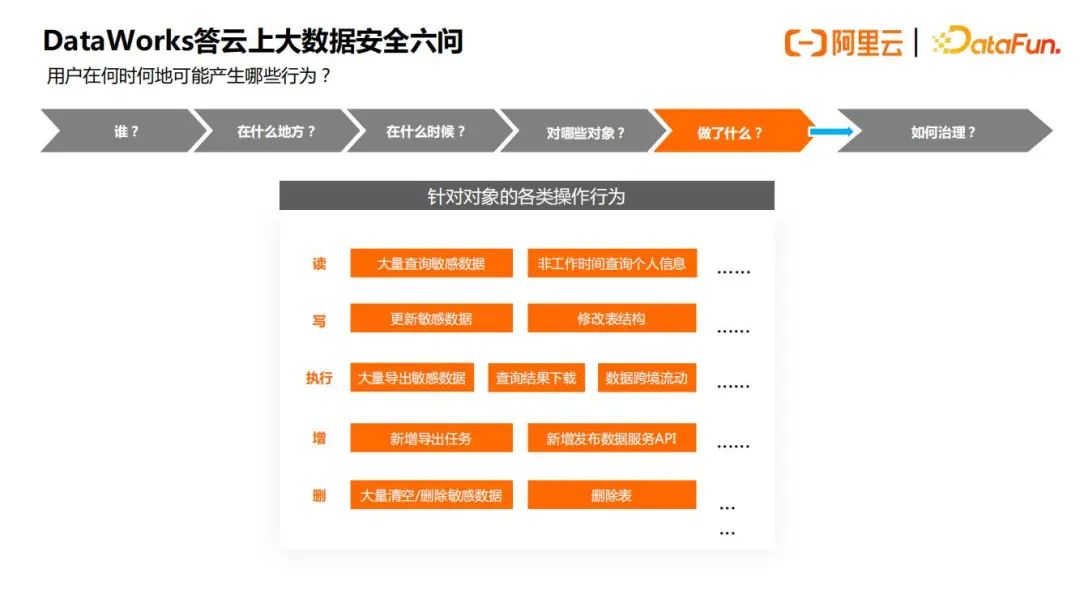
这些行为总结下来,读写主要是对数据表的读写,执行主要是对软件功能的执行,例如查出的结果下载到本地,或者发起一个数据跨境导出、流动任务,新增主要是新增导出任务,新增发布API等,删除更是比较敏感,如果没有备份,删除操作后一般都无法恢复,这些行为如果不当组合的话,会导致数据风险,数据安全治理的目的也就是逐步收敛这些风险。
6.问题6 – 如何治理
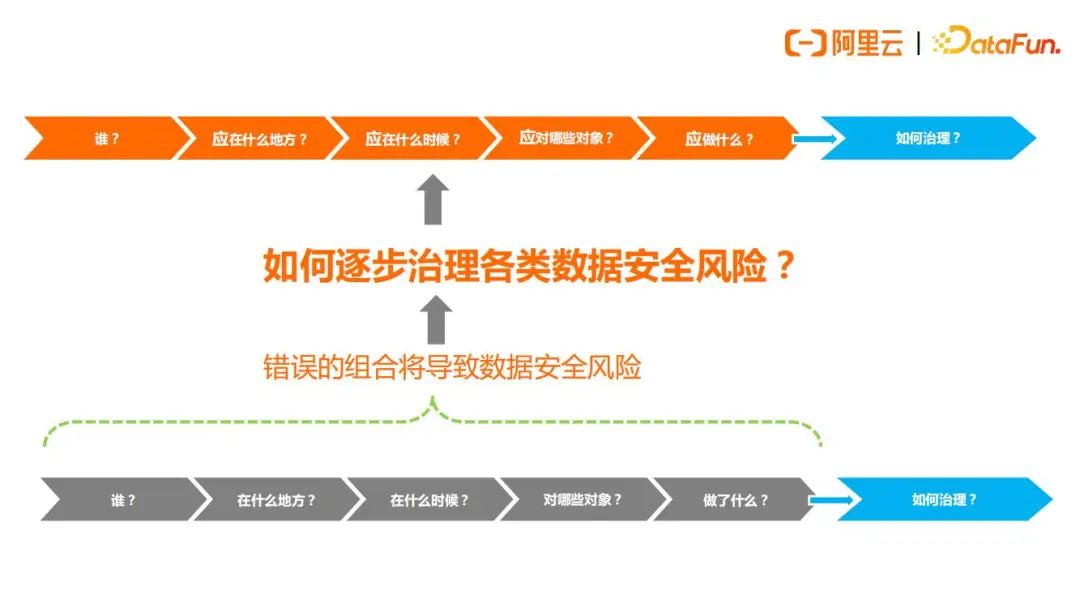
所以企业的CIO或者安全合规部门应该都非常明确,谁应该在什么地方,应该在什么时候,应对哪些对象,应该做些什么,后面会着重来讲述,如何支持这个“应该”的“应”,来实现和落地。
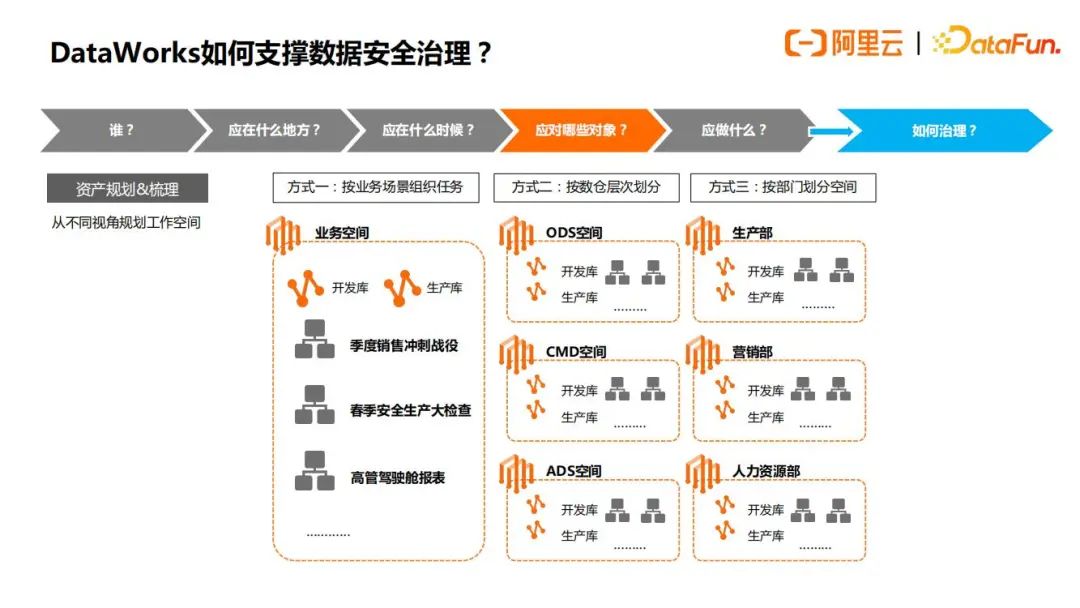
如下图所示,首先数据安全治理的第一步都是去梳理资产,哪些对象应该被保护,应该被访问,相应的在Dataworks平台上做开发和治理,第一步就是划分工作空间和项目空间,因为所有的代码和数据都会存储在项目空间中,目前有三种划分方式,方式一是按照业务场景划分,方式二是按照数仓层次划分,方式三是按照业务部门划分,目前采用最多的是方式二,其中ODS层,一般来说只需要业务系统开发的人员,用来配置相关数据集成(业务库数据源配置和同步),数仓开发人员不需要加入,其他层例如CDM,ADS层主要是数仓开发人员做数据开发,这个也可以按照各企业实际情况进行划分。只要把不同的人员加入不同的空间,就可以做到隔离。
数据安全治理的第二步是需要梳理另外一个很重要的资产就是数据,数据梳理就是对数据做分级分类,目前Dataworks中OEM了蚂蚁集团的数据保护伞敏感数据保护的能力,用户可以通过配置关键字,正则表达式,或者内置专家模版,语义特征模版,内容识别模版等,快速帮助用户识别敏感信息,如下图所示:
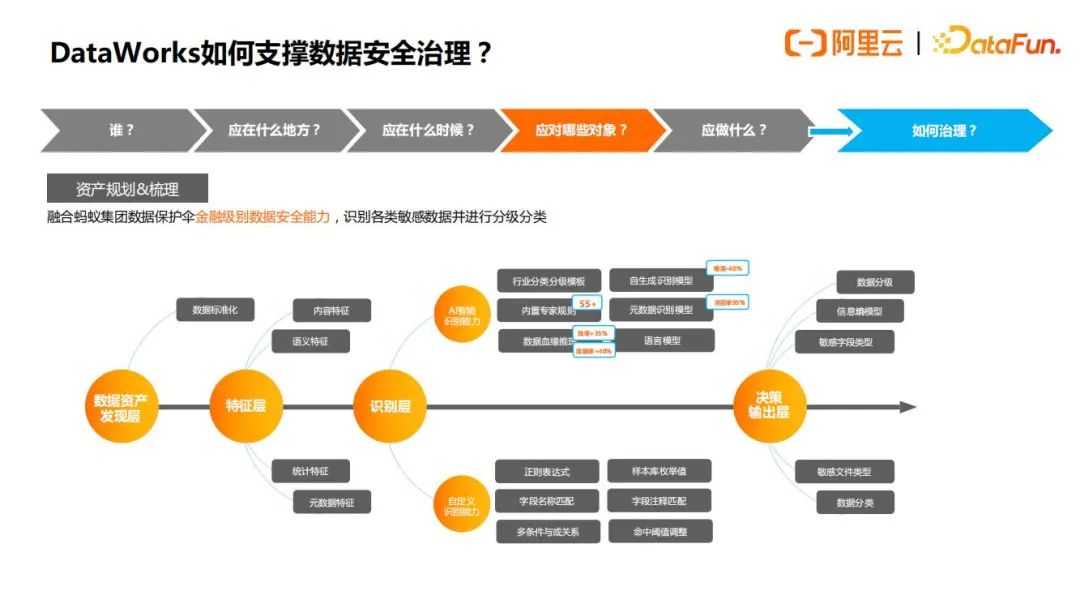
管理者只需要6步简单的配置,就可以完成敏感数据规则识别的配置,如果是金融企业的用户,还可以根据内置金融行业模版一键完成设置,如下图所示:
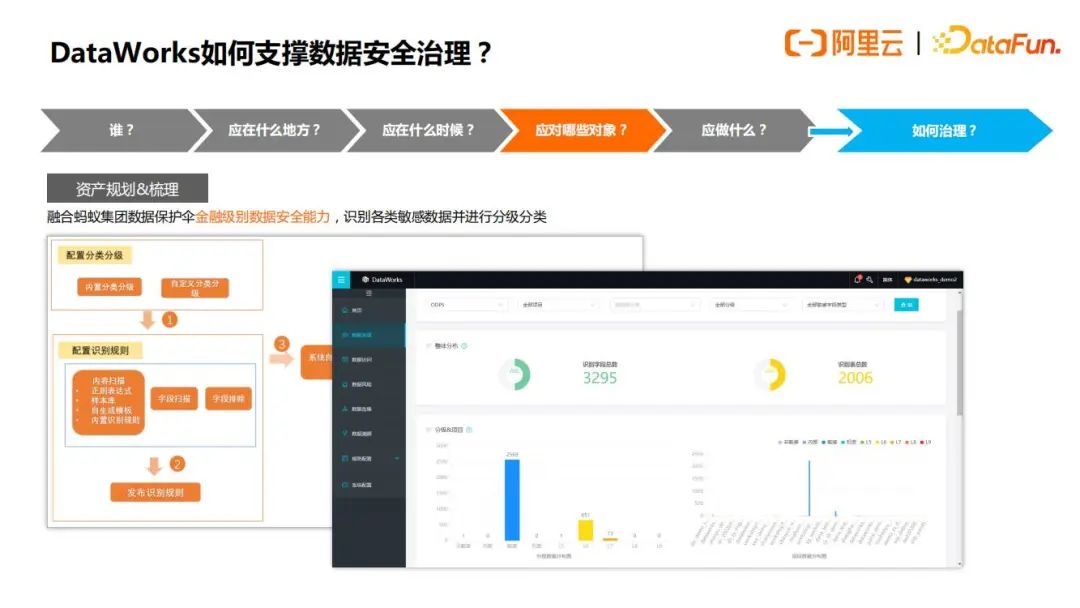
接下来,我们来看下“谁应该对哪些对象应该做什么”这个问题的答案。
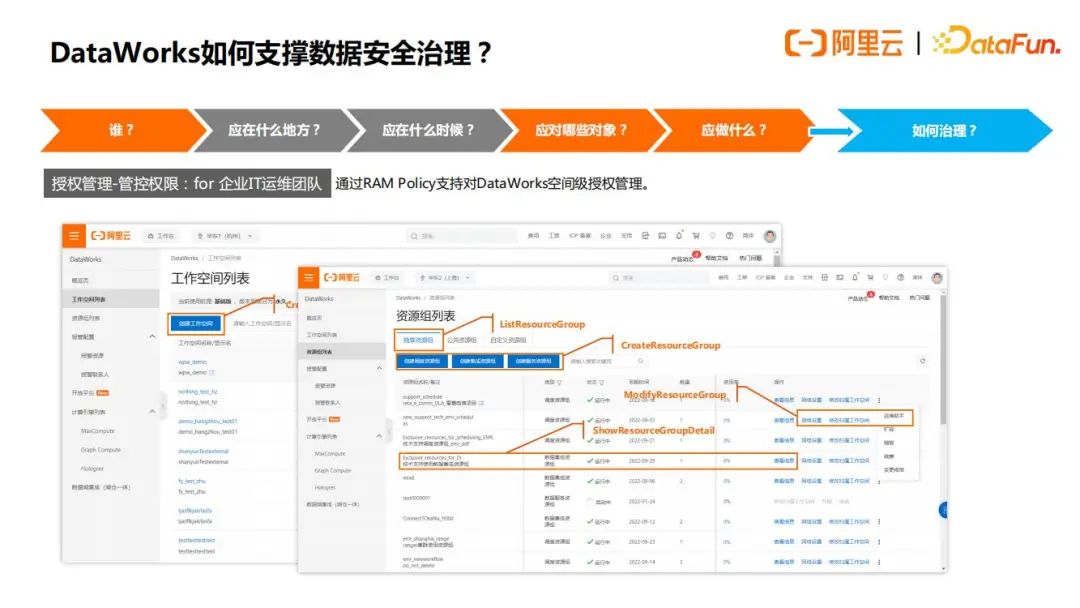
DataWorks在产品管控、功能使用等方面提供了完善的权限管控体系,其中产品管控通过阿里云RAM Policy实现,管控对象是控制台操作,如创建工作空间等;功能使用权限通过RBAC实现,通过定义成员角色并授权来管控功能使用,并根据产品功能范围分为全局级和空间级。
对于企业的IT运维团队,可以对工作空间或者独享资源组,进行细粒度的授权,例如,工作空间列表页面中创建空间、禁用空间、删除空间等操作;资源组列表页面中的创建独享资源组、配置独享资源组网络等操作;报警配置页面的配置联系人等操作,如下图所示:
对于数据团队,做数据开发的时候,可以根据DataWorks预设的部分全局角色和空间级角色,可以直接使用这些角色给用户授权,也可以根据需要,自定义全局角色或空间级角色。用户、角色、权限之间的对应关系,如下图所示:

推荐最佳实践是按照下图所示的去做,如图是标准模式的开发流程,首先一个DW空间对应了两个引擎环境,一个用于开发,另一个用于生产。
在数据建模链路,先由数据团队主管定义好建模过程中可能使用到的数据标准,随后由数据建模人员设计模型,并对模型进行提交,最后经由数据团队主管、运维或部署人员审核无误后即可发布到生产环境。
在数据开发与生产链路,开发人员在开发环境先执行代码开发、依赖配置与调试,冒烟测试无误后可执行提交发布申请,此时应由一个运维/部署/管理员角色来进行代码Review,确认无误后即可执行发布到生产环境,让规范、安全的代码在生产环境定期运行产出数据。
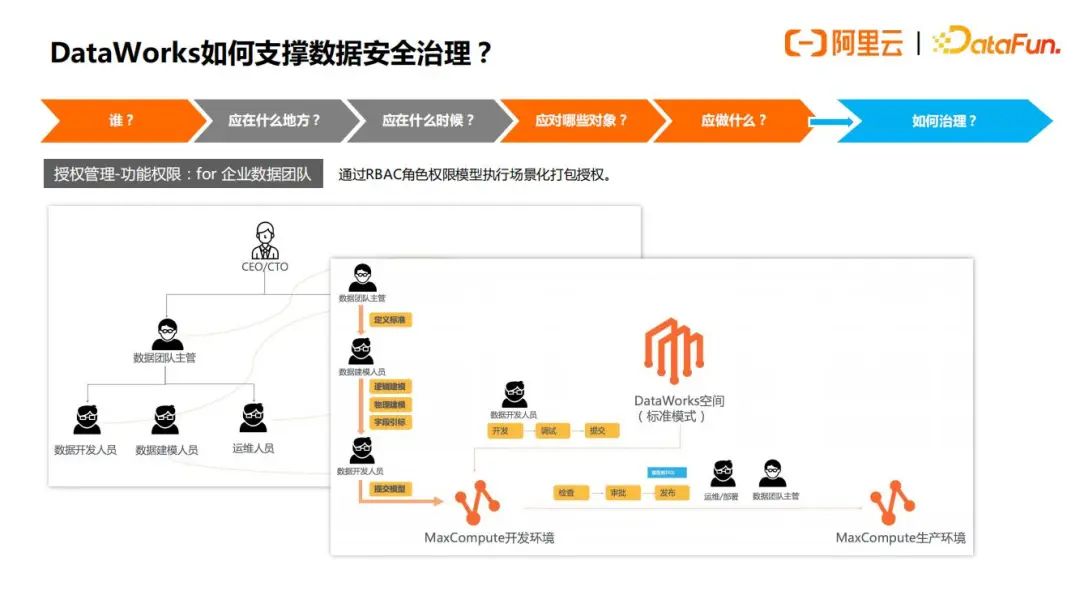
这里面需要注意的一点是针对不同角色的人员,只分配对应的角色给相应的角色,例如不可以给数据开发人员空间管理员的角色,或者既分配开发角色又分配运维角色,而是只分配开发角色。
对于数据分析师,经常会用到数据开发人员开发好的新的数据表,默认都是没有权限的,这时可以在Dataworks安全中心里面,进行表或者字段权限申请,如果企业已经做了数据分级分类,还可以自定义数据审批流程,例如对于级别较低的表,表Owner审批就可以了,对于级别较高的表,需要部门安全负责人审批,级别最高的表,需要CIO的审批,这样就不容易出现越权审批的情况。
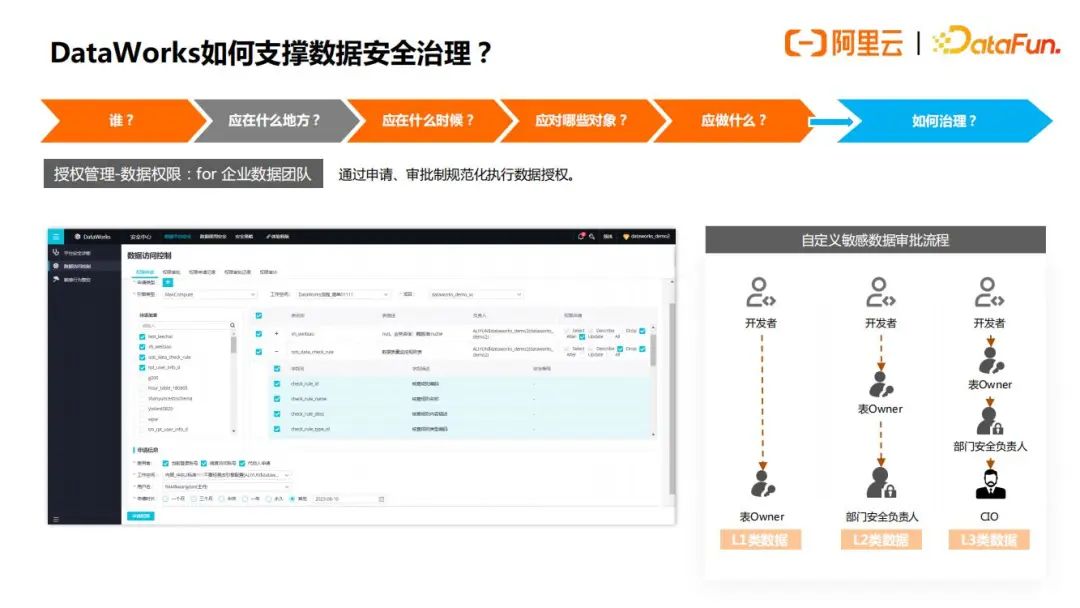
接下来是回答“谁应该在什么地方来访问”这样一个问题,这个问题也是很多高安全要求的企业的强诉求,目前Dataworks中支持了IP白名单访问,以及访问具体哪个入口(Web端和API端),如下图所示:
前面讲述的都是事前安全,这样就足够了吗?很明显,是不够的。当今主流趋势是过程安全,也就是之前提到的零信任。
在Dataworks中,也基于机器学习模型,统计模型,还有一些基线分析方法,构建了用户行为识别机制,帮助管理者找出风险点,以及设置对这些风险点进行响应,如下图所示:
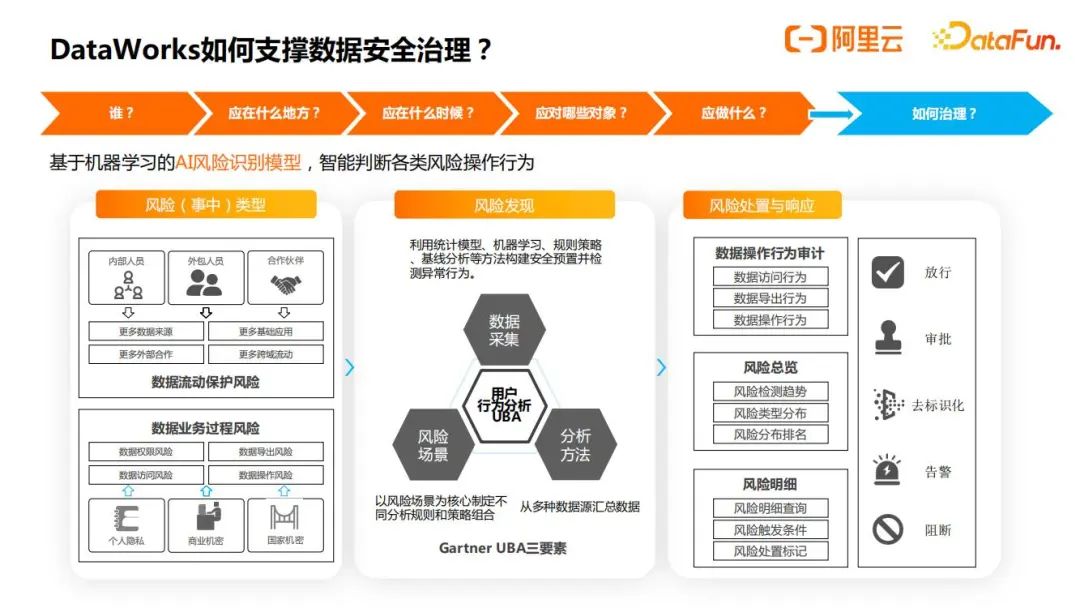
其中响应的方式有审批、去标识化(即脱敏)、告警和阻断。
下面主要来看下对于数据直接风险行为的响应,也即大家所熟知的脱敏,在很多法律法规中称为去标识化,目前支持了加密、掩盖、哈希的脱敏,场景一般分为数据分析场景和开发测试场景,如下图所示:
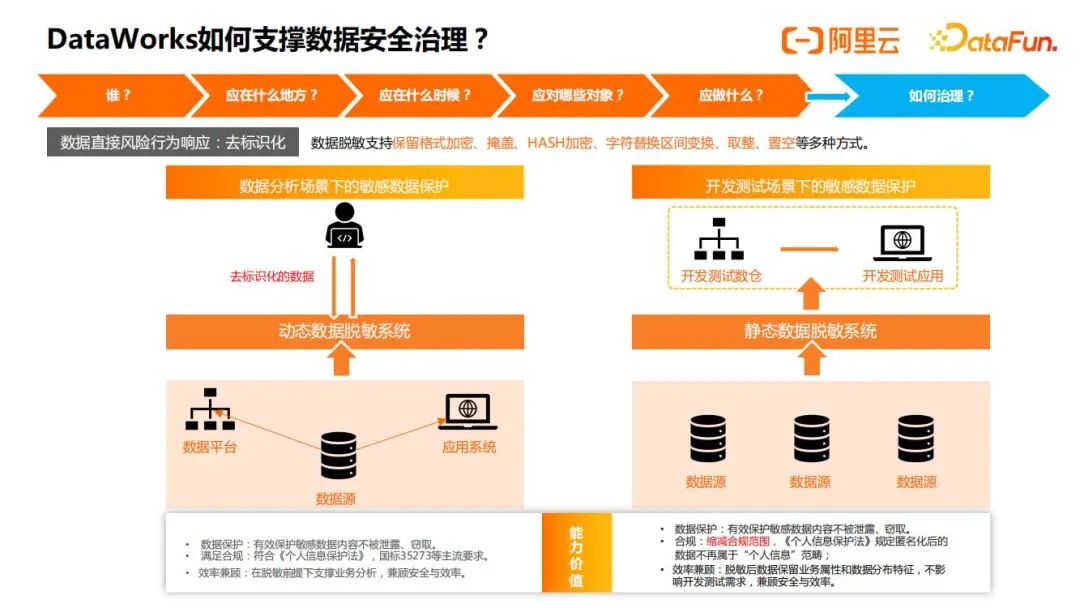
在数据分析场景下,数据分析师一般来说是不需要查询明细数据的,如果需要查询明细数据,例如查询手机号,可以把手机号中间的字符,替换成类似“*”这样的字符,用来掩盖。对于开发测试场景,开发人员在生产环境中导出数据进行开发或者测试的时候,导出的操作可以通过静态脱敏来支持,导出的数据以脱敏的形式写入到开发环境的存储中。
下图是一个实际的效果:
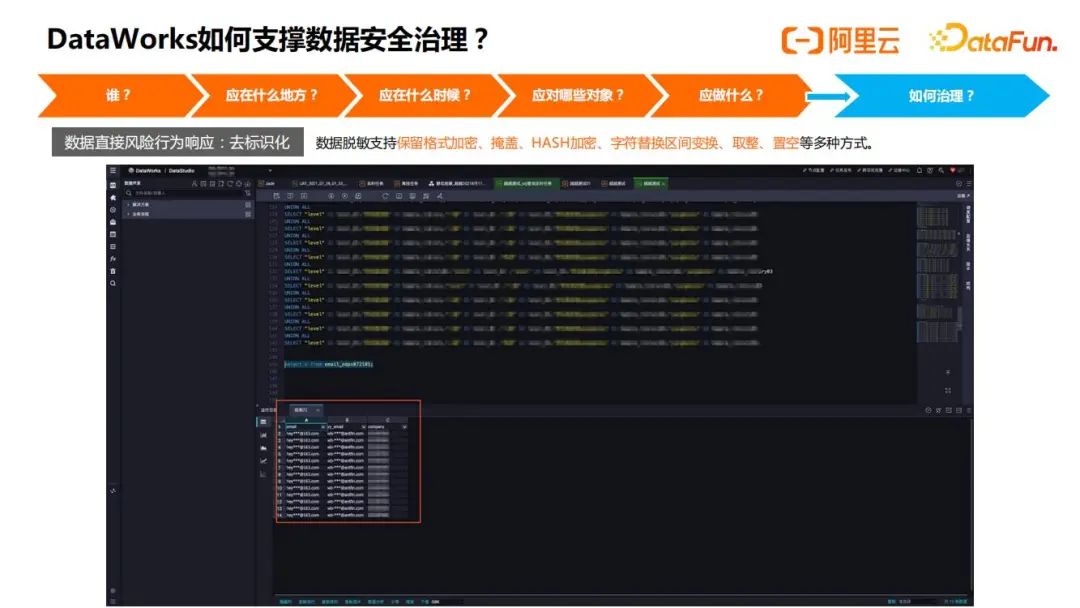
另外一个对数据直接风险行为的响应是告警和阻断。这个也是近期一直在探索的,对于告警的行为,可以在Dataworks数据保护伞中做自定义的配置,也可以通过默认的规则模版,例如非工作时间去访问数据,可以把非工作时间段设置为0点-6点,如果有这样的访问,就可以把它通过告警报出来,而针对阻断来说,对于大规模查询结果展示、下载、复制的阻断,用户可以对不同的角色设定不同的阈值,如果超过阈值,可以阻止这些行为,如下图所示:

下面所展现的是针对数据通过非直接的访问行为导致的风险的响应,目前是通过审批策略来支持,例如数据导出,开发者可以创建数据同步任务,目前支持管理者把任意的数据源配为源端和目的端来实施管控,也可以配置不同的人来进行审批,也包括数据API的发布(不同的数据源构建的API可以通过不同的人进行管控和审批)和数据跨境传输(由企业合规管理员去审批,后面也会帮助用户自动识别哪些同步链路是跨境的)。
下图是Dataworks安全能力概览图,其中标黄的部分是之前没有提到的,例如成员离职转交,风险处置等。
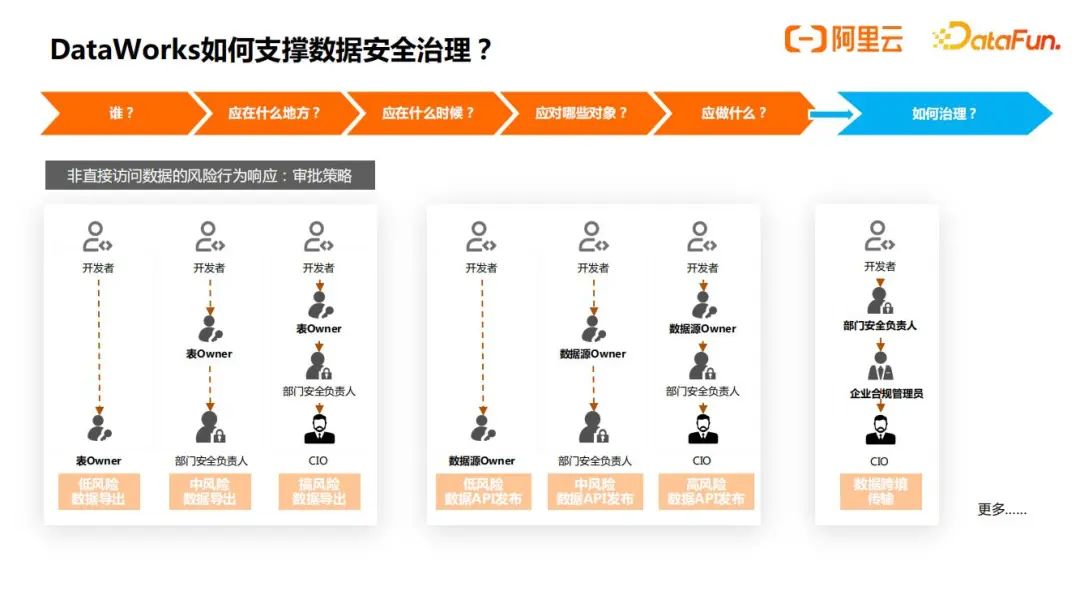
下面介绍四个不同类型的重点客户数据安全治理的案例。
04 阿里云数据安全治理场景与案例
具体案例以及详细内容如下面4张图所示:

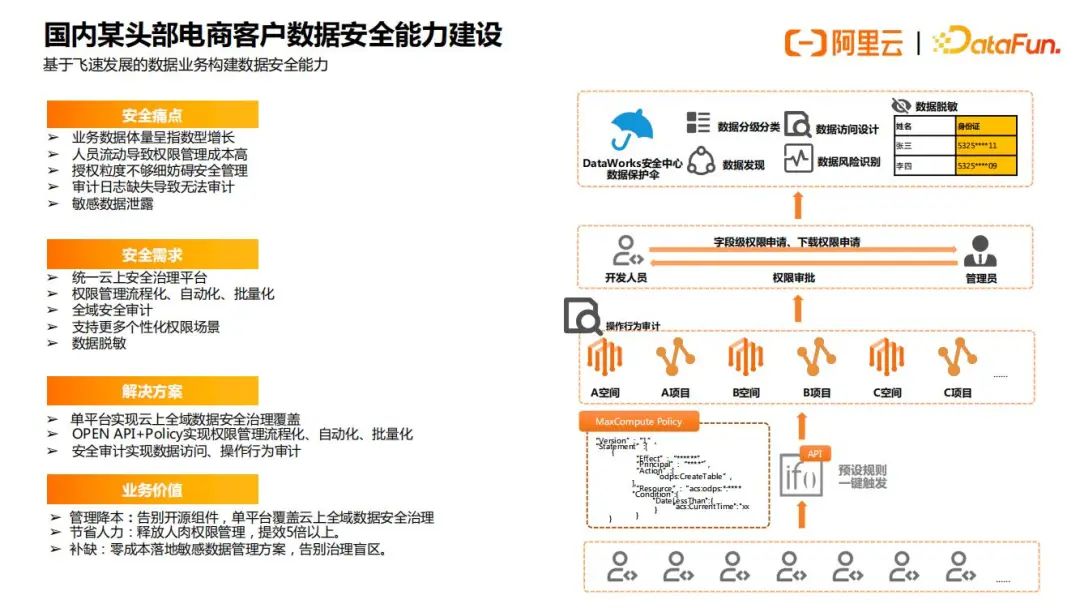
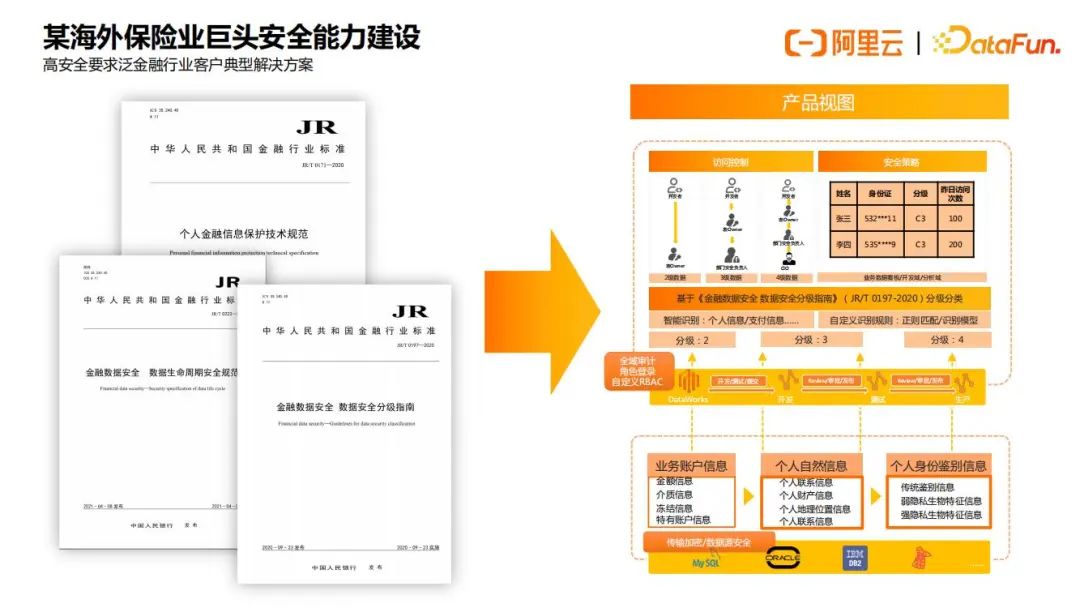
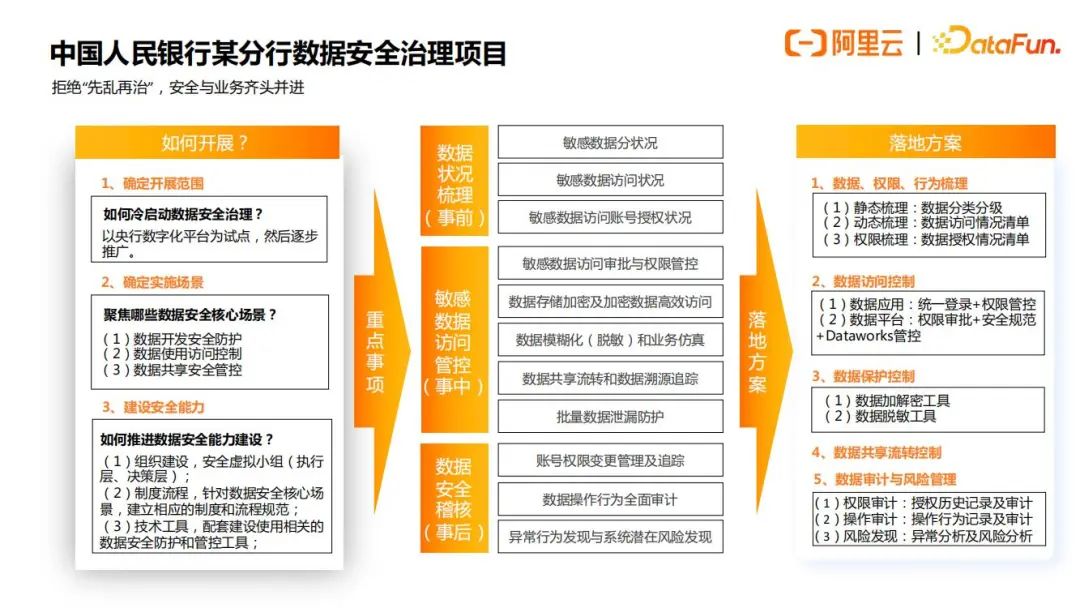
总之,数据安全治理体系是从制度,产品和运营三个方面来进行的,需要三个部分的共同协作,缺一不可。制度上确定了哪些是可以做的,哪些是不能做的,随后用产品去具象化这些制度,最后运营根据这些制度去奖惩、优化。这样就可以形成一个制度、产品、运营协同的数据安全治理体系的闭环。
阿里云DataWorks结合各引擎为企业提供一站式开箱即用的安全能力,这些能力可以覆盖DSMM中所述的几个重要的数据安全过程:传输、存储、处理、交换、通用等。从另一个维度来看,Dataworks产品安全能力也覆盖了事前、事中、事后结合的工作周期,从事前与事中的规范化开发生产、数据可用不可见,到数据风险行为管控,再到事后的敏感数据管控,为企业提供了周全的数据风险控制能力。
05 Q&A
Q1:开发和生产环境两套环境中,开发环境数据是怎么来的?
A:开发环境的数据可以自行造一些数据,或者使用Dataworks数据集成工具,从业务生产库中同步数据,同时开启静态脱敏。也可以通过命令行或者页面自行上传数据。
Q2:数据分类的方法,一般是线分类还是面分类,有些场景线分类不一定能Cover?
A:需要根据不同行业的规章制度来看。
Q3:不同行业有无分级分类的指南,例如广告行业?
A:金融行业比较多,保险、医疗、健康、汽车行业都有,广告行业不是很清楚,需要进一步了解。
今天的分享就到这里,谢谢大家。
分享嘉宾
刘天鸢,阿里云 产品经理
刘天鸢(阿里花名:扫尘),阿里云大数据平台DataWorks产品经理,负责公共云商业化与数据安全能力建设。
声明:本文来自DataFunTalk,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
