
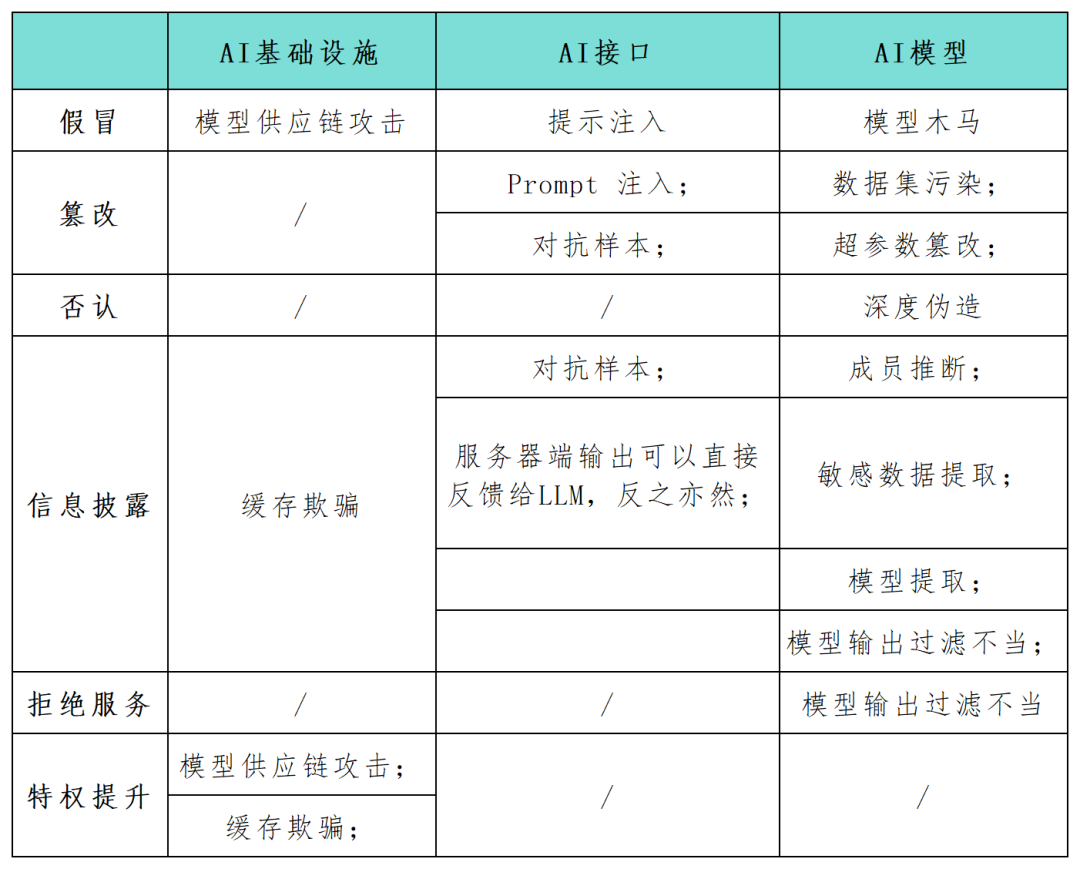
STRIDE是一个流行的威胁建模框架,目前已被广泛用来帮助组织主动发现那些可能对其应用系统造成影响的威胁、攻击、漏洞和对策。如果把“STRIDE”中的每个字母拆开,则分别代表了假冒(Spoofing)、篡改(Tampering)、否认(Repudiation)、信息披露(Information Disclosure)、拒绝服务(Denial of Service)和特权提升(Elevation of Privilege)。
随着人工智能(AI)系统应用逐渐成为企业数字化发展的关键组成部分,许多安全从业者呼吁必须尽快识别和防护这些系统的安全风险,而STRIDE框架无疑可以帮助组织更好地理解AI系统中可能的攻击路径,并强化其AI应用程序的安全性与可靠性。在本文中,安全研究人员使用STRIDE模型框架全面梳理映射了AI系统应用中的攻击面(见下表),并对特定于AI技术的新攻击类别和攻击场景进行了研究。随着AI技术不断发展,会有更多新的模型、应用、攻击和操作模式也随之演进。
针对AI基础设施的攻击
AI研究员Andrej Karpathy指出,新一代深度神经网络模型的到来,标志着传统概念化软件生产方式发生了范式转变。开发人员越来越多地将AI模型嵌入复杂的系统中,这些模型不是用循环和条件的语言来表达的,而是用连续向量空间和数值权重来表达的,这也为漏洞利用创造了新的途径,并催生了新的威胁类别。
篡改。攻击者如果能够篡改模型的输入和输出,或者改变AI基础设施的某些设置参数,就可能导致有害和不可预测的恶意结果,例如意外行为、与AI代理的交互以及对链接组件的影响。
伪冒。如果攻击者在模型或组件交付过程中模拟可信源,就会发生伪冒行为。这种技术可以让攻击者将恶意元素引入AI系统。同时,伪冒也可作为模型供应链攻击的一部分,例如,如果威胁行为者渗透了像Huggingface这样的第三方模型提供商,在下游进行AI输出的代码执行时,他们可以在某些情况下通过感染上游模型来控制周围基础设施。
信息披露。敏感数据暴露是任何网络应用程序的常见问题,包括为AI系统提供服务的应用程序。在2023年3月,Redis的错误配置导致一个Web服务器暴露了私人数据。一般来说,Web应用程序容易受到经典的OWASP十大漏洞的影响,如注入攻击、跨站脚本和不安全的直接对象引用。这种情况同样适用于为AI系统提供服务的Web应用程序。
拒绝服务(DoS)。DoS攻击也会给AI应用构成威胁,通过用流量淹没模型供应商的基础设施,攻击者可以使AI服务无法使用。在围绕AI模型的基础设施和应用程序中设计弹性是实现AI系统安全的基础要求,但这还远远不够。
针对模型训练和推理的攻击
对于已训练的AI模型以及较新的第三方生成型AI系统,同样存在以下攻击面威胁:
数据集污染和超参数篡改。AI模型在训练和推理阶段容易受到特定的威胁,数据集污染和超参数篡改是STRIDE篡改类别下的攻击,指的是威胁行为者将恶意数据注入训练数据集。例如,攻击者可以故意向人脸识别AI中输入误导性的图像,导致其错误地识别个体。
对抗样本。对抗样本已经成为AI应用信息泄露或篡改威胁的常见攻击方式,攻击者操纵模型的输入,使其做出错误的预测或分类。这些行为可能会泄露关于模型训练数据的敏感信息或者欺骗模型以意想不到的方式行事。例如,一组研究人员表明,在停车标志上添加小块胶带可能会混淆嵌入自动驾驶汽车的图像识别模型,这可能会导致严重后果。
模型提取。模型提取是一种新发现的恶意攻击形式,属于STRIDE的信息泄露类别。攻击者的目标是基于模型的查询和响应来复制专有的训练机器学习模型。他们精心设计一系列查询,并利用模型的响应来构建目标AI系统的副本。这种攻击可能侵犯知识产权,并可能导致重大的经济损失。同时,攻击者拥有模型副本后,还可以执行对抗性攻击或反向工程训练数据,从而产生其他威胁。
针对大语言模型(LLM)的攻击
大语言模型(LLM)的流行推动了新型AI攻击方式的出现,LLM开发和集成是一个非常热门的话题,因此,针对其的新攻击模式层出不穷。为此,OWASP研究团队已经开始起草首个版本的OWASP Top 10 LLM威胁项目。
提示注入。提示注入包括越狱、提示泄露和令牌走私。在这些攻击中,攻击者会操纵输入提示,以触发LLM的非预期行为。这种操纵可能导致AI产生不适当的响应或泄露敏感信息,与STRIDE的欺骗和信息泄露类别相吻合。当AI系统与其他系统结合使用或在软件应用程序链中使用时,这些攻击尤为强大。
不当的模型输出及过滤。大量的API应用可能以各种非公开暴露的方式被利用。比如,像Langchain这样的框架可以让应用程序开发人员在公共生成式模型和其他公共或私有系统(如数据库或Slack集成)上快速部署复杂的应用程序。攻击者可以构造一个提示,欺骗模型进行原本不允许的API查询。同样地,攻击者也可以将SQL语句注入通用未净化的web表单中以执行恶意代码。
成员推理和敏感数据提取。攻击者可以利用成员推理攻击以二进制方式推断特定数据点是否在训练集中,从而引起隐私问题。数据提取攻击允许攻击者从模型的响应中完全重建关于训练数据的敏感信息。当LLM在私有数据集上训练时,常见的情况就是模型可能具有敏感的组织数据,攻击者可以通过创建特定的提示来提取机密信息。
木马模型。LLM已被证明在微调阶段容易(即使是最小的操作)受到训练数据集污染的影响。此外,对熟悉的公共训练数据进行篡改在实践中也已被证明是可行的。这些弱点为公开可用的语言模型充当木马模型敞开了大门。从表面上看,它们的功能与大多数提示的预期一样,但它们隐藏了在微调期间引入的特定关键字。一旦攻击者触发这些关键字,木马模型就可以执行各种恶意行为,包括提升特权、使系统无法使用(DoS)或泄露私人敏感信息等。
参考链接:
https://www.secureworks.com/blog/unravelling-the-attack-surface-of-ai-systems
声明:本文来自安全牛,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
