导读:2023 年 12 月,第二届 AI 对齐工作坊(Alignment Workshop)在新奥尔良的 NeurIPS 会议期间举办。本次工作坊是由 Adam Gleave 领导的非盈利性研究机构 FAR AI 主办。
 新奥尔良对齐工作坊(New Orleans Alignment Workshop)
新奥尔良对齐工作坊(New Orleans Alignment Workshop)
工作坊邀请到了来自工业界和学术界150余位AI研究者就 AI 安全和对齐相关的研究主题展开讨论和辩论,从而更好地理解前沿 AI 可能带来的风险,并寻找降低这些风险的策略。工作坊的讲者和参与者有来自OpenAI、Anthropic、Google DeepMind等顶尖业界AI实验室的AGI安全团队成员,也有来自MIT、UC Berkeley、CMU、剑桥大学、牛津大学、Mila等顶尖高校的学者。图灵奖得主Yoshua Bengio在工作坊上做了主旨演讲。
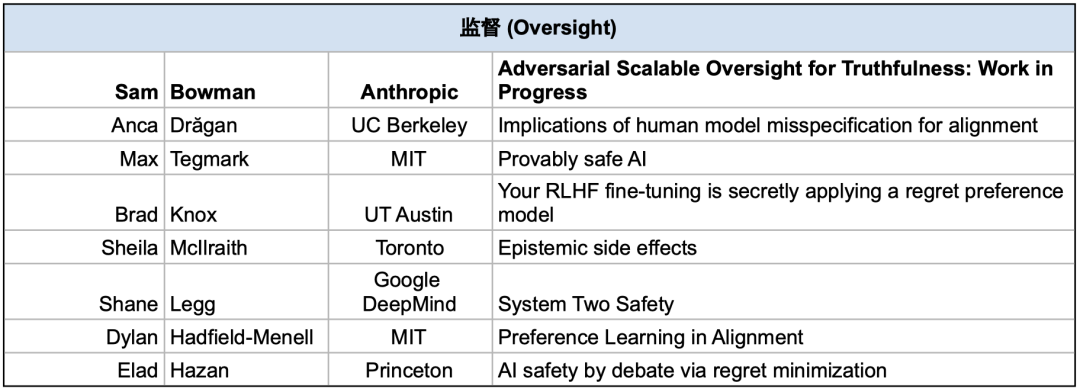
本文是工作坊总结系列推文的第二篇文章,主要总结了来自Sam Bowman(Anthropic/NYU)的关于监督(Oversight)的主旨演讲。
PART 1 Sam Bowman - Adversarial Scalable Oversight for Truthfulness:Work In Progress[1]
 Adversarial Scalable Oversight for Truthfulness:Work In Progress
Adversarial Scalable Oversight for Truthfulness:Work In Progress
关键词速览:Anthropic、可拓展监督、人类主持的AI-AI辩论、QuALITY阅读理解数据集、GPQA问答数据集。
讲者介绍:Sam Bowman是纽约大学(NYU)的副教授,是NYU Alignment Research Group的负责人,专注于可拓展监督(Scalable Oversight)研究。同时他也在Anthropic领导一个研究小组,专注于语言模型的训练和评估工作。他以其在大型神经网络语言模型及其在NLP中的应用方面的工作而闻名,包括GLUE和SuperGLUE等基准数据集等。
关于什么:很多时候,我们会把人类对模型提供的监督信号看作是我们对于模型信任的来源。然而,可拓展监督问的问题是:“如何保证人类在极其困难以至于难以评估的任务上还能对系统提供可靠的监督信号?” Bowman的讲座主要介绍了他在可拓展监督上的研究方向:人类主持的AI-AI辩论(Human-Moderated AI-AI Debate)[2]。他的研究方向追问的问题是:“如何保证人类即使是在不完全理解的领域里,还能够监督LLMs产出真实的回答?”
 研究方向:人类主持的AI-AI辩论
研究方向:人类主持的AI-AI辩论
编者注:Bowman的研究议程是许多前人议程的延伸,例如:AI safety via debate[3],AI safety via marketing making[4],Debate update: Obfuscated arguments problem[5]等。针对辩论(AI Safety via Debate)研究方向其他议程的详细解读可参照《人机对齐概述|15. 如何让AI系统学会‘正确’的目标?‘超越老师’》。
人类主持的AI-AI辩论:最基本的任务设定有下面几个规则:
有一个人类裁判(judge)需要回答一个双项选择题(图中的例子是:海龟利大于弊还是弊大于利?)。
辩论采取非结构化的对话形式,正反方辩手为自己的立场进行辩护,它们相对于人类评委有一些信息优势或者技能优势。
辩手可以提出某种形式的证据来支撑他们的观点,例如,科学论文的链接、代码实验等等。但是这些证据应该是可以被人类裁判所验证的。
在辩手双方没有提出有说服力的证据的情况下,人类评委可以选择拒绝得出最终答案(decline to resolve)。
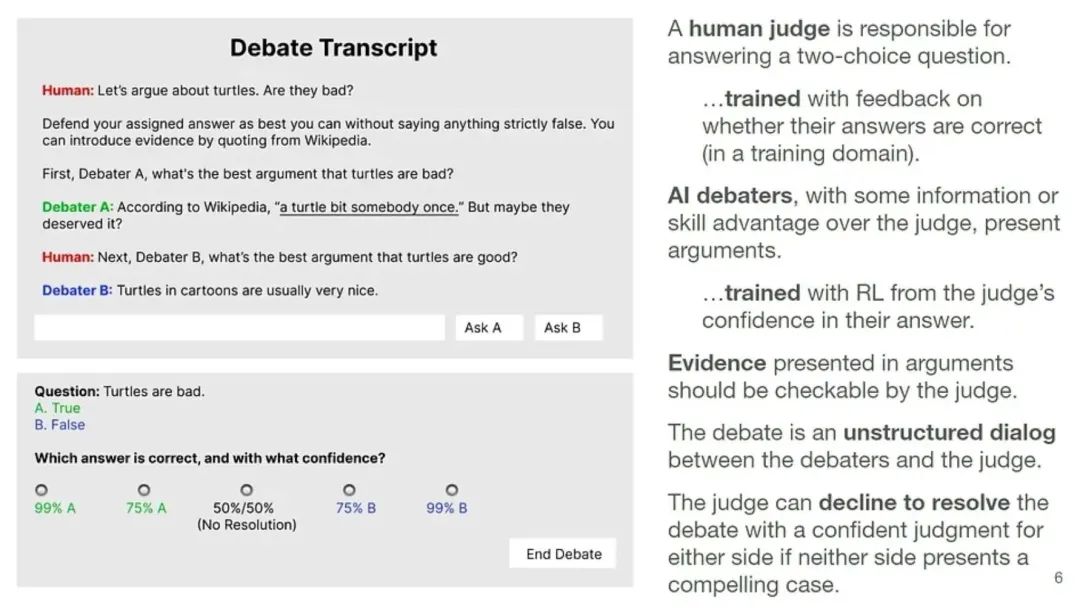 辩论任务设置:人类主持的AI-AI辩论
辩论任务设置:人类主持的AI-AI辩论
QuALITY阅读理解数据集[6]:Bowman设计的第一个测试数据集是名为QuALITY的阅读理解数据集。
数据集中包含了一段需要几十分钟才能读完的长故事(约5k tokens),以及多项选择题。
对于每个故事,作者逐一验证了想要答好每道题就需要好好读完这个故事。换句话说,只是浏览这些故事或者进行关键词搜索,是没办法回答好这些问题的。
在辩论任务的设置里面,辩手能够看到这些故事,但是裁判看不到原文,而只能看到辩手所截取的片段。
 QuALITY: Question Answering with Long Input Texts, Yes!
QuALITY: Question Answering with Long Input Texts, Yes!  QuALITY数据集的数据样例
QuALITY数据集的数据样例
实验设置:Bowman团队目前做了两组实验:针对人类裁判与LLM裁判的实验。第一篇文章《Debate Helps Supervise Unreliable Experts》[7]描述的是针对人类裁判的实验。团队招募了19名NYU的人类辩手同时做辩手和裁判,其中很多来自与NYU的专业辩论队。
 针对人类裁判的实验:Debate Helps Supervise Unreliable Experts
针对人类裁判的实验:Debate Helps Supervise Unreliable Experts
作者研究了两种设定:咨询(Consultancy)和辩论(Debate):在咨询任务中,裁判仅与一名专家互动,并对随机选择的一个立场进行辩护。在辩论任务中,专家们在开场陈述中同时辩护他们指定的选项。在两种设定中,裁判都可以选择何时结束辩论。
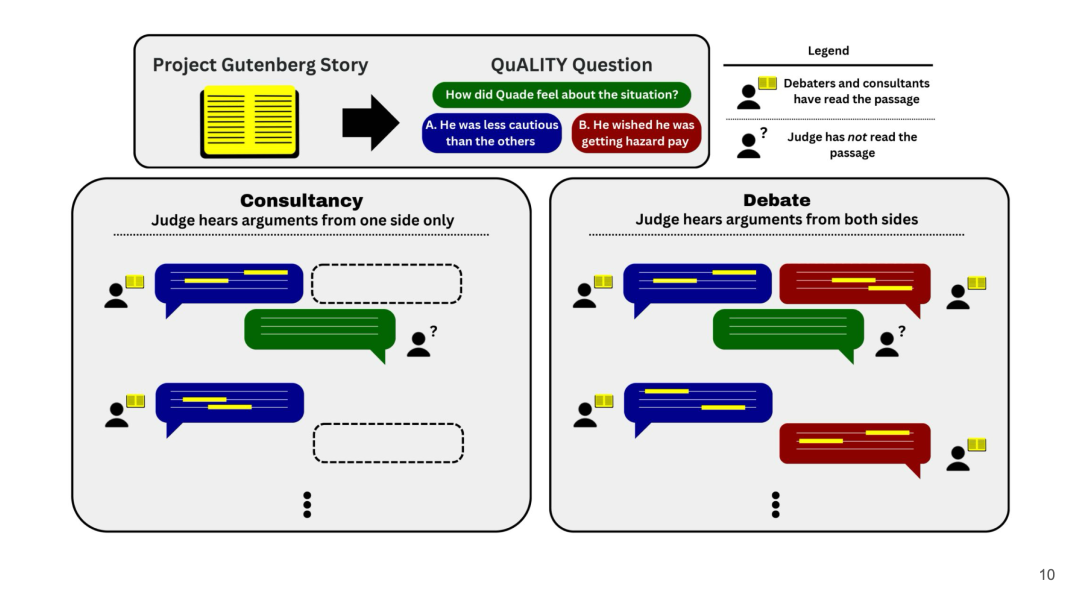 咨询(Consultancy)和 辩论(Debate)设定
咨询(Consultancy)和 辩论(Debate)设定
实验结果发现:在招募了人类辩手的实验中,人类裁判的判断准确率已经达到了84%,并且比咨询的任务好更多,说明辩论中的对抗元素有效地提高了裁判的真实性判断。
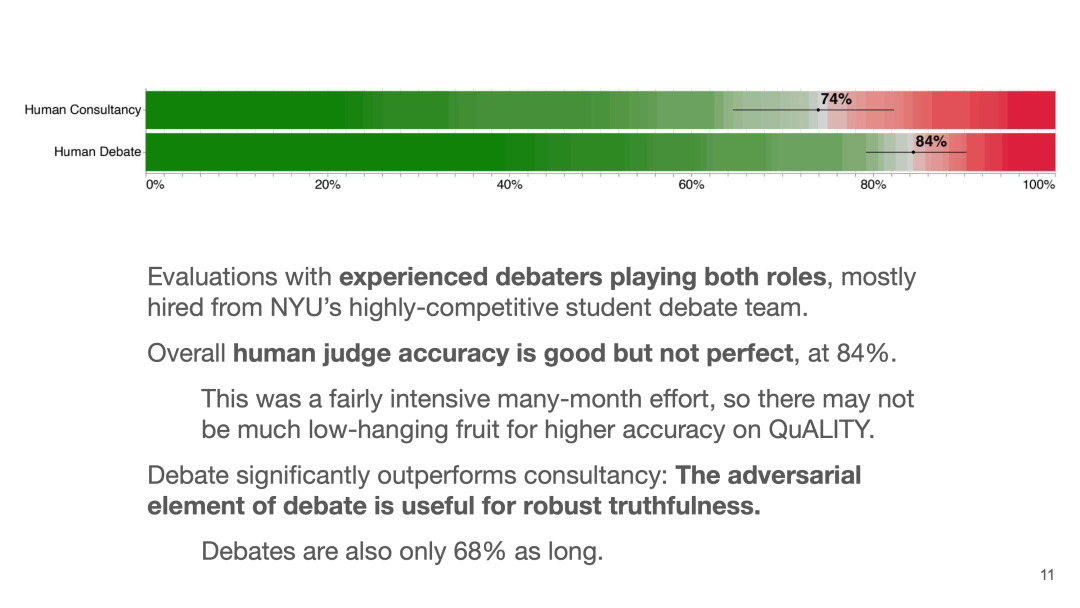 实验结果:辩论能够比咨询更好地提升人类裁判的判断
实验结果:辩论能够比咨询更好地提升人类裁判的判断
另外,团队也用LLM做了相关实验:团队首先用判断精确度微调了Claude 2得到了LLM裁判,接着基于裁判给出的答案用强化学习或Best-of-N(BoN)优化方法微调Claude 2 辩手,最终发现裁判给出答案的准确率从73%提高到了78%。同时辩手的有效性通过优化也得到了提高。
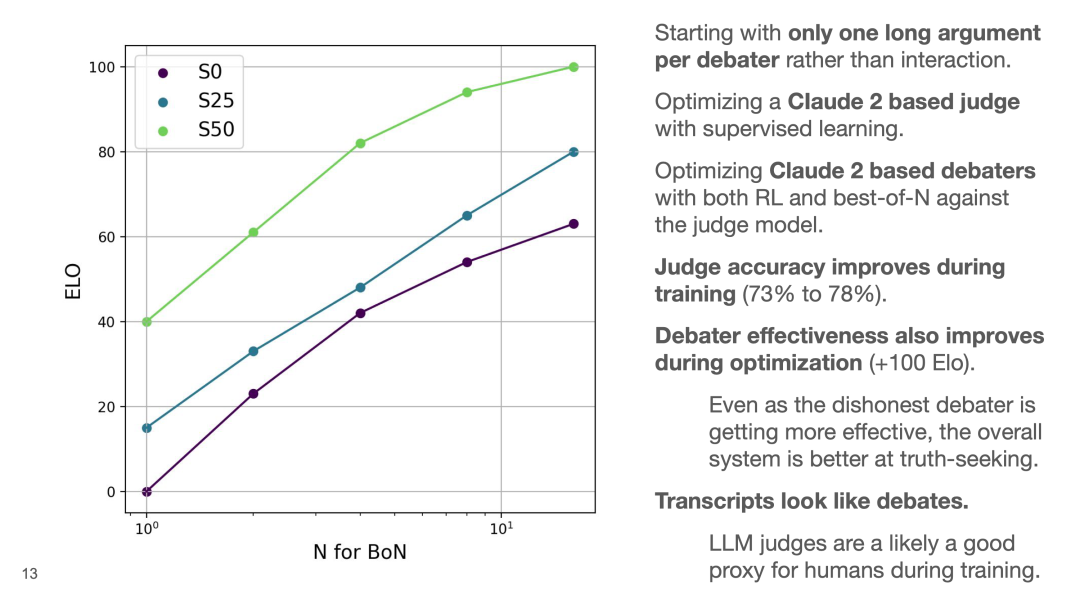 LLM辩手的实验结果
LLM辩手的实验结果
在辩论研究议程中,一个顾虑是辩手可能会使用不诚实的行为说服裁判同意它的立场,但是作者发现在任务的过程中系统整体都偏向了实事求是(truth-seeking)的行为。另外,作者发现最终得到的辩论对话看起来确实跟人类辩论的方式很相似。
 Graduate-Level Google-Proof QA(GPQA)
Graduate-Level Google-Proof QA(GPQA)
更难的基准数据集 -GPQA[8]:上面的QuALITY benchmark的一个缺陷就是:还是不够难!如果辩手把所有故事节选都遍历出来,总会让裁判能够回答出正确答案。因此,团队又推出了一个更难的数据集:Graduate-Level Google-Proof QA(GPQA)。这个数据集的目标是希望能够将辩论的问题推到人类科学认知的前沿,触及只有专家才能作答的领域。
研究生水平:GPQA数据集包含了有生物、化学或物理博士背景的专家撰写的448个专业问题。
难以通过搜索获取的专业知识:团队验证了这些问题即使是让另一个理工科背景的人结合谷歌搜索也需要花费数十分钟才能作答。GPT-4 + 搜索也只能达到39%的回答准确率。
 GPQA的一个例题
GPQA的一个例题
最后,Bowman做了总结,并提出了辩论方法可能存在的局限性:
1)假设存在一些问题和回答,如果它们的最简论证对于任何评判者来说都过于复杂,那么辩论方法就会陷入困境;
2)另外人类评判中是否存在难以消除的重要盲点,比如说一些逻辑上的缺陷和不足?
PART 2 监督(Oversight)短演讲速览
Anca Drăgan (UC Berkeley / Google DeepMind): Implications of human model misspecification for alignment
Max Tegmark (MIT): Provably safe AI
Brad Knox (UT Austin): Your RLHF fine-tuning is secretly applying a regret preference model
Sheila McIlraith (Toronto): Epistemic side effects
Shane Legg (Google DeepMind): System Two Safety
Dylan Hadfield-Menell (MIT): Preference Learning in Alignment
Elad Hazan (Princeton): AI safety by debate via regret minimization
演讲原视频和幻灯片PDF:https://www.alignment-workshop.com/nola-2023
参考资料
[1]Sam Bowman - Adversarial Scalable Oversight for Truthfulness:Work In Progress: https://www.alignment-workshop.com/nola-talks/sam-bowman-adversarial-scalable-oversight-for-truthfulness-work-in-progr
[2]The Anthropic–NYU Debate Agenda by Sam Bowman and Tamera Lanham: https://docs.google.com/document/d/173SpCyspboHBp3bHqWvUiduzatbuuv7QAvWVamwcGbk/edit
[3]AI Safety via Debate: https://arxiv.org/abs/1805.00899
[4]AI safety via marketing making: https://www.lesswrong.com/posts/YWwzccGbcHMJMpT45/ai-safety-via-market-making
[5]Debate update: Obfuscated arguments problem: https://www.alignmentforum.org/posts/PJLABqQ962hZEqhdB/debate-update-obfuscated-arguments-problem
[6]QuALITY: Question Answering with Long Input Texts, Yes!: https://arxiv.org/abs/2112.08608
[7]Debate Helps Supervise Unreliable Experts: https://arxiv.org/abs/2311.08702
[8]GPQA: A Graduate-Level Google-Proof Q&A Benchmark: https://arxiv.org/abs/2311.12022
通讯作者
段雅文
技术项目经理
专注 AI 对齐与安全研究
声明:本文来自安远AI,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
