
基于深度学习的虚假新闻检测领域内已有许多开创性的方法能通过特征提取与检测的方式进行自动检测假新闻的任务,通常使用预训练模型提取新闻内容的特征,并开发算法使用这些特征进行检测。许多此类方法通过找到假新闻中通行的特征模式(例如写作风格、常用词等)来判别假新闻。但模型的高性能严重依赖于大量高质量标注数据的训练。然而在实际应用场景中,不仅获取、标注数据十分困难,新伪造的虚假新闻往往还会避免采用以往假新闻的写作风格,导致了模型在时间性上缺乏泛化能力。
近年来事实核查在虚假新闻检测领域的发展为解决上述问题提供了新的研究思路,基于事实信息的虚假新闻检测提供了更可靠的检测解释性,通过对事件的真实性、描述与事实的匹配程度等的查验,很大程度上突破了以往方法依赖文本风格特征所带来的检测偏置。
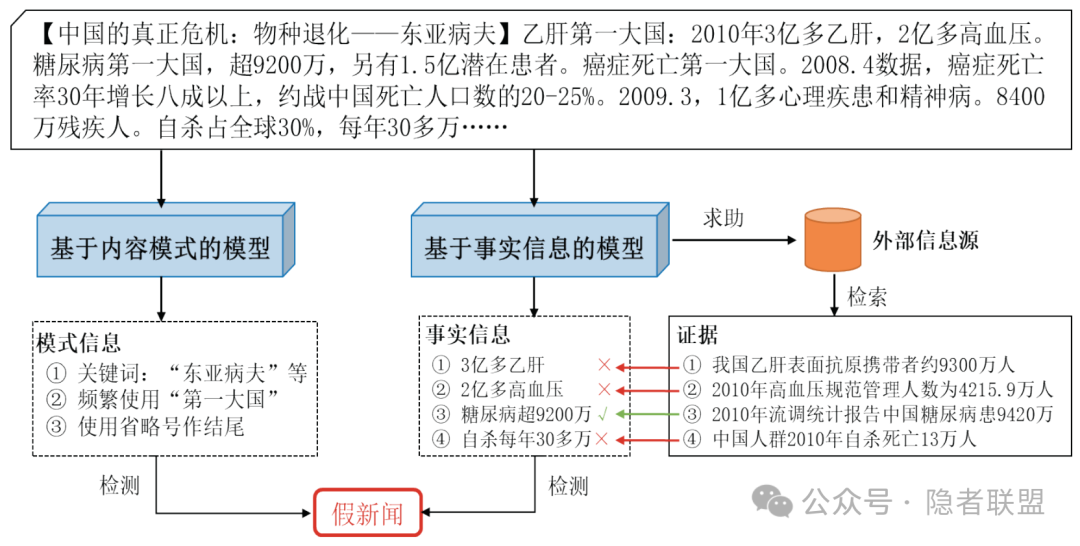
图1 基于内容模式的模型和基于事实信息的模型的工作流程对比
本文从任务和问题、算法策略、数据集等角度出发,对当前基于事实信息的虚假新闻的研究成果进行梳理和总结。首先,本文系统性地阐述了基于事实信息的虚假新闻检测的任务定义与核心问题。其次,从算法原理出发,对现有的检测方法进行归纳总结。之后,对领域内的经典与新提出的数据集进行了分析,对各数据集上的实验结果进行了总结。最后,本文概括性地阐述了现有方法的优势和劣势,提出了几个该领域方法可能面临的挑战,并对下一阶段的研究进行展望,期望为领域内的后续工作提供参考。
论文信息
相关论文已发表于中国传媒大学学报(自然科学版),作者为复旦大学计算机科学技术学院的杨昱洲、周杨铭、应祺超、钱振兴,上海大学通信与信息工程学院的曾丹以及来自中央广播电视总台视听新媒体中心技术应用部的刘亮。
杨昱洲,周杨铭,应祺超等.基于事实信息核查的虚假新闻检测综述[J].中国传媒大学学报(自然科学版),2023,30(06):28-36.DOI:10.16196/j.cnki.issn.1673-4793.2023.06.007.(查看论文全文:https://journal.cuc.edu.cn/frmShowPaperSummary.aspx?id=6141)
供稿:钱振兴教授,复旦大学计算机科学技术学院多媒体智能安全实验室
实验室简介:多媒体智能安全实验室(MAS Lab)现有教师3位(张新鹏教授、钱振兴教授、李晟副教授)、在站博士后2位、在读博士生17位、在读硕士生30位,主要研究多媒体与人工智能安全,包括信息隐藏、多媒体取证、人工智能安全、虚拟机器人、多媒体应用等五个方向。实验室团队已发表学术论文400余篇,多篇论文发表在IEEE TIFS、TIP、TDSC、TCSVT、TMM、TCYB、TCC、TNNLS、TPAMI、AAAI、IJCAI、NeurIPS、ACM MM、ICCV等顶刊顶会上。欢迎青年才俊加入复旦多媒体智能安全实验室!
复旦大学多媒体智能安全实验室主页:
https://fdmas.github.io/
神经网络模型研究资源:
https://fdmas.github.io/research/Neural_Network_Watermarking.html
虚假新闻检测研究资源:
https://fdmas.github.io/research/fake-news-detection.html
AIGC取证主页:
https://fdmas.github.io/AIGCDetect/
声明:本文来自隐者联盟,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
