摘要:生成式人工智能算法的发展使得生成式伪造语音更加自然流畅,人类听力难以分辨真伪.本文首先分析了生成式伪造语音不当滥用对社会造成的一系列威胁,如电信诈骗更加泛滥、语音应用程序安全性下降、司法鉴定公正性受到影响、综合多领域的伪造信息欺骗社会大众等.然后从技术发展角度,对生成式伪造语音的生成算法和检测算法分别进行总结与分类,阐述算法流程步骤及其中的关键点,并分析了技术应用的挑战点.最后从技术应用、制度规范、公众教育、国际合作4方面阐述了如何预防以及解决生成式伪造语音带来的安全问题.
冯畅(1,2)吴晓龙(2,3)赵熠扬(1,2)徐明星(1,2)郑方(1,2)
1.清华大学计算机科学与技术系
2.清华大学北京信息科学与技术国家研究中心
3.新疆大学计算机科学与技术学院
生成式伪造语音是基于生成式人工智能算法产生的语音.生成式人工智能通常是指“一种利用现有数据生成新的、真实的、反映训练数据特点但具有原创性内容的新数据的人工智能技术”[1].生成式人工智能一般要通过各种机器学习根据给定的输入数据或模式,自动生成新的输出数据或模式.近年来,随着深度神经网络研究和计算机算力的持续突破,通过生成式人工智能技术学习大量样本数据中的模式和规律,可以生成质量越来越高的文本、图像、语音、视频等各种模态的内容.生成式人工智能具有可自动生成大量内容、可根据用户需求和偏好进行定制化生成等优点,能帮助人们更快地获取信息,提高创造力和效率,也可以为人们提供更多的娱乐和文化体验.
然而,生成式人工智能的运用也存在一些风险,例如可能生成不准确或不合适的内容,或者被用于恶意目的.在语音领域,生成式伪造语音在人机交互中的不当使用带来的安全威胁同样令人担忧.因此,针对正在发展的生成式伪造语音技术,需要同时发展伪造语音检测技术,加强治理体系建设,对技术应用进行充分评估和监管,以保证技术发展朝着正确的道路前进,确保技术应用的安全性和合法性.
1 生成式伪造语音滥用引发的威胁
1.1增加电信诈骗防范难度
当前,随着生成式伪造语音技术的发展,电信诈骗已经演化到一个新的层次.诈骗者不再需要利用传统的社会工程手段模仿他人的声音,而是通过软件创建目标对象的克隆语音进行诈骗.国内外都有此类案例报告.诈骗者使用这种技术假冒亲人、银行工作人员或权威机构人员的声音,诱使受害者转账或泄露个人信息.
2022年,美国和加拿大发生了一系列利用AI合成声音实施诈骗的案件,这类案件不仅频发而且手段高明,涉案金额高达1100万美元,而且主要的受害群体为老年人.这些诈骗行为通常是通过获取目标受害者亲人的声音样本进行操作的,这些样本可能来自于社交媒体上的视频、电话留言或公开场合的语音录音.诈骗者利用AI语音合成软件处理这些声音样本,生成与受害者亲人极其相似的声音.接着,他们通过电话联系受害者,伪装成亲人,并编造紧急情况,比如事故、被捕等,以此来诱使受害者汇款或转账.由于合成的声音与真实语音有极高的相似性,使受害者难以识别出电话中的语音是伪造的,特别是在情绪紧张和发生紧急情况时,受害者往往会出于关心、担心、害怕而没有产生怀疑,就给犯罪分子进行汇款.
数据统计显示,这种新型电信诈骗的成功率远高于传统诈骗电话,它所带来的安全威胁正在呈现日益上升的趋势[2].
1.2降低语音应用程序安全性
随着智能家居和个人助理设备的普及,语音应用程序变得越来越重要,它们广泛应用于智能家居、移动设备以及企业系统中,使日常任务如购物、搜索信息和家居设备控制变得更加便捷.然而,由于上述语音应用通常采用声纹识别技术作为安全验证方式,生成式伪造语音技术的发展对这些语音应用程序的安全性构成了直接威胁.
以智能助理为例,这些设备通常通过声纹识别技术来识别和执行用户的命令.但现在,生成式伪造语音技术可以生成与用户声音听起来几乎相同的语音,这使得恶意攻击者可以通过模仿用户的声音控制智能设备,甚至进行非授权的购买或访问敏感信息.
1.3破坏司法鉴定证据链公正性
由于语音设备的广泛使用以及通信技术的发展,以录音记录事件变得更加普遍.录音的语音作为证据已经在近几年的案件中作为重要线索和关键证据.所以录音语音的真实性与完整性是司法程序中判案的基石.在2023年通告的一起案例中,公安部鉴定中心的专家运用先进的技术对涉案的录音笔内的音频文件进行了深入的恢复和分析,以语音内容作为证据之一.鉴定中心的专家特别抽取了音频内容,通过与留存的语音样本进行声纹比对,并结合现场调查的具体情况,最终确认这些录音音频是否由比对者本人所录制.更重要的是,鉴定中心的专家还通过详细的声音分析,确认录音内容未经过人为的合成或篡改,确保了音频证据的真实性,保障了证据的公正性,为破案进一步提供了关键证据.
伪造语音使得语音证据在司法领域使用的公正性和可信度面临前所未有的挑战.这对司法部门提出了更高的要求,不仅需要更新的技术支持,也需要更为严谨的法律和程序规范,以应对未来可能出现的更加复杂的伪造案例.
1.4催生更多语音和图像结合的视频伪造欺骗
在生成式伪造技术的应用中,视频伪造尤其引人注目,它结合了精准模仿的语音和与之同步的视觉元素,能够对目标人物的语音和面部表情进行高度还原,从双模态上给人更高的信任度,使得伪造的视频更加逼真,具有极大的欺骗性.特别是国内外知名人士的视频语音数据,这类资料众多,更容易被获取并用于伪造.近年已有多个以知名人士作为主角的视频被伪造产生,以篡改原视频或生成全新视频的方式,负面影响包括有散布虚假言论或表现主角不当行为,可能导致公众对于真实事件的误解和混淆,损害其声誉和形象.虚假视频还有可能被用于传播虚假信息或进行欺骗活动,从而干扰社会秩序和破坏公信力.同时,互联网和社交媒体的普及也为这些虚假视频的传播提供了广阔的平台,使得它们能够迅速传播并引起公众的关注.根据对视频平台的监测,此类伪造视频的传播速度之快、观看量之高,均显示出其在社交网络中的强大影响力.
这些案例表明,深度伪造不仅能够在短时间内吸引巨大的观众量,而且其内容的可信度和真实性常常令人难以辨认,对于个人声誉、公众信任以及社会秩序都可能造成深远的负面影响.因此,探寻和发展相应的检测技术、防范策略,以应对这类视频伪造欺骗已经成为亟待解决的问题.
2 生成式伪造语音技术
2.1生成式伪造语音算法
生成式伪造语音是指通过语音合成、语音转换这2种生成式语音技术产生的语音信号,其中:语音合成技术是从给定的文本信息生成朗读该内容的语音信号;语音转换技术是从给定的源说话人语音转换为目标说话人说相同内容的语音.
语音合成技术可划分为发音器官模拟合成、共振峰合成、拼接合成、声学参数合成.发音器官模拟合成方法[3]通过模拟人类的发音器官(包括声门、声道、嘴唇、舌头等)的运动行为产生相应的声音,再根据语音信号的相关知识对每个模仿部位的声音进行滤波、卷积等操作,组合出最终的语音信号;共振峰合成方法[4]是利用发音器官模型简化的源-滤波器模型,将语音分解为共振峰结构与其他频谱结构,这2个结构用一个加性合成模块组合起来,最后通过估计这3个部分的参数实现合成语音;拼接合成方法[5]是将已有的真实语音片段根据文字内容提示进行拼接,语音片段是以句子、单词、字、音节等语音单位进行提前录制并分割好的,拼接算法包含搜索语音片段、平滑语音片段间的连接、统一整句语音风格等工作;声学参数合成方法是通过先生成语音中的声学特征参数,再从声学参数转换为语音采样点,就得到数字语音信号.早期的声学参数合成是采用统计参数合成的方法[6],由文本分析、声学模型预测声学参数、声码器转换采样点3个部分组成:文本分析是对文本进行预处理,转换为音节、音素等更细粒度的语言特征,根据语言特征采用声学模型预测基频、频谱等声学参数,将预测的声学参数用声码器的声码分析合成语音波形采样点.近年的声学参数合成方法采用深度神经网络分别实现文本分析语言特征、声学参数建模和声码器转换采样点这3个模块,更直接的还有从语言特征生成语音采样点波形,如WaveNet[7]的提出.完全的端到端模型,将文本分析也与语言特征合并进行联合训练,如FastSpeech 2[8]等实现从文本直接生成波形采样点.此外,视频合成算法中,利用文本-图像扩散模型,生成时间一致视频可以同时完成语音合成与图像合成的任务[9].
语音转换技术方案的基本原理是将输入的源说话人语音信号转换为源特征表示;然后将源特征表示转换为目标说话人的特征表示;最后将目标说话人的特征表示运用声码器等恢复为目标语音信号.源特征表示和目标特征表示可以是频谱包络、频谱图等语音声学特征.对特征表示的转换方法有早期的高斯混合模型、频率弯折、样例语谱图分解、说话人特征转换等方法[10],还有近年来以生成对抗网络[11]、自编码器[12]为代表的神经网络转换模型框架.随着语音合成中端到端模型的有效运用,语音转换中也能采用如WaveNet[7]等模型框架将特征转换和语音采样点恢复联合训练成一个模型.
2.2伪造语音效果及应用
伪造语音以生成自然流畅、符合人类听觉感知、具有内容可理解性、语音质量稳定的语音信号作为目标.当前的各类伪造语音已经能够达到以下效果[13]:
1) 自然度.非常接近自然语音,人类听力测试上已经难以分辨某些伪造语音.
2) 准确度和理解度.能准确表达相应的文本内容,在发音、语调、语速上均能保持可理解性.
3) 多音色支持.支持多种音色,包括男、女、老年、儿童等不同人群的音色.甚至能够根据用户的需求,在声音特征、语言习惯上进行定制.
4) 多场景支持.支持不同使用场景、不同采样设备下的定制表现,语音质量也能保持稳定.
语音合成已经广泛地用于实现人机交互的各种功能:可以将电子书、新闻文章等文本信息转换为语音,朗读读出,用户用“听书”实现电子阅读;在导航程序中将导航信息转换为导航语音;结合聊天机器人技术,可以在客服系统中将文本转换为语音,完成智能客服交流;还能用于语音广播、语音教育、语音翻译等实现让用户以听的方式接受信息输入;在新闻采访视频等领域,为了保护被采访人隐私,通过生成具有特定音色和语调的语音,掩盖原说话人的语音.
3 伪造语音的检测技术
人类发出的声音信号是一种模拟信号,需通过麦克风等传感器转换为数字语音信号才能在计算机等电子设备中进行处理和传输.为了检测伪造语音,通常使用语音信号处理技术和机器学习算法来分析语音信号的特征和模式,将伪造语音与真实语音的特征和模式进行比较,以确定语音的真伪.
伪造语音检测可以用于声纹认证、语音取证等领域,检测语音输入的真伪性以预防语音和视频欺诈,确保语音认证系统的安全可靠,证明音频证据的真实有效性,解决本文第1节中提到的各类伪造语音滥用安全问题.
根据听力测试[14],人类对伪造语音的敏感性主要集中在对韵律、字词衔接与连续性等语义听感方面.目前,对伪造语音检测研究主要集中在2大类上:对伪造语音特征的研究;对真伪语音模式学习的分类器模型研究.
3.1伪造语音检测算法
伪造语音检测以特征提取作为前端操作,将数字语音信号时序采样点表示为适合分类器的声学特征输入.传统方法是人工设计的声学特征,基于信号处理的相关知识,从频域、相位域、倒谱域及相关的信号变换操作中提取声学特征.如语音频谱图、梅尔倒谱系数(Mel frequency cepstrum coefficient, MFCC)、线性倒谱系数(linear frequency cepstrum coefficient, LFCC)[15],采用常数Q变换提取常数Q倒谱系数(constant Q cepstrum coefficient, CQCC)[16],对相位信息进行描述的群延迟特征[17]等.
针对伪造语音与真实语音的不同点,还可以设计韵律相关的可区分性特征.近年学者们开始使用深度神经网络学习特征表示,通过卷积神经网络及残差模块、记忆模块等,以学习真伪2类语音分布为目标,提取具有真伪可区分性的语音特征[18].随着预训练模型在语音类任务中的推广,也使用如Wav2Vec2.0[19], XLS-R[20]等大规模自监督模型计算语音特征表示.此外,端到端模型的出现使语音特征也可以直接以采样点原始数值的方式呈现,而无需经过其他变换.
在伪造语音检测中使用的分类器是以语音特征作为输入,输出真伪判决结果,早期的分类器包括混合高斯模型[21]、支持向量机[22]等.近年深度神经网络提高了对数据的学习和建模计算能力,以卷积神经网络、循环神经网络、全连接层[23]为基本架构的神经网络分类器也开始应用.端到端模型将语音采样点作为输入,通过频-时域图注意力网络模块[24]、异构堆叠图注意力网络模块[25]等以真伪语音分类为目标直接学习采样点信息,模型内语音特征和分类器能够实现共同训练.
3.2伪造语音检测应用
伪造语音检测可以应用于以下方面:
1) 银行金融系统.一是识别电话中的欺诈行为,包括虚假身份验证、冒充客户进行未经授权的交易;二是对在线应用程序中的用户登录、密码修改等确认账户访问时的真实性.
2) 法律应用方面.一是可以帮助法庭证据验证,在法庭上用于验证或驳斥证人证词,保证证据的可靠性;二是在刑事调查中,相关执法机构可使用伪造语音检测技术调查与语音记录有关的犯罪行为.
3) 社交媒体等多媒体平台.伪造语音检测可以用于虚假内容检测,对用户上传的虚假或有危害的语音音频或视频中的音频进行检测,监测和阻止用户的非法行为,维护平台的安全性和合规性.也可以在平台登录步骤用声纹验证时,对用户验证的语音进行伪造检测,防止身份欺诈.
4) 各类生活服务产品方面.在电信公司使用时,运营商可以使用伪造语音检测识别和阻止钓鱼电话,防止电信诈骗,保障用户个人信息.在医疗领域的电话咨询中,医疗保健者用伪造语音检测验证通话患者咨询的真实性,确保患者的隐私安全和诊断的有效性.在线教育领域中,在线教育平台可以用伪造语音检测验证学生提交的语音作业或考试是否真实,防止学术不端.
3.3伪造语音检测未来发展方向
基于深度学习的方法已经在伪造音检测中取得了巨大的成功,继续采用这种技术以提高检测的准确性和鲁棒性,是未来的一大探索方向.
伪造语音可以不单单只以语音形式存在,也可以和图像进行同步形成视频中的语音部分,视频伪造也愈发常见,多模态伪造语音检测也是一个重要的发展方向.
在提高伪造语音检测实用性的方面,如实时电话欺诈检测中,需要检测技术降低延迟,提供实时反馈,对实时检测性能有高要求.伪造音检测技术还需要能够处理多种语言和方言,以适应不同地区和文化的需求.在使用过程中,也要看重用户声音数据的隐私和合规性问题,需要与隐私法规和合规性标准保持一致.
此外,基于伪造语音检测的应用场景,如伪造语音检测与声纹身份验证相结合,可以将声纹特征与伪造声学特征进行结合,更好地实现场景需求.
3.4伪造语音检测技术面临的挑战
当前,伪造语音检测技术面临以下挑战:
1) 生成式伪造语音算法是多样化的,由此产生的伪造语音分布也是多种多样的,基于机器学习的检测技术需要解决这些多样化带来的问题,算法需要具备可泛化性,能够同时学习多种分布的伪造语音.
2) 除了要得出检测结果,检测算法还需要具有可解释性,即能对伪造语音检测结果进行溯源,追溯语音中的伪造点信息是什么.
3) 由于生成式伪造语音技术的发展速度很快,检测算法还需要具备可自我学习更新的能力,在学习新数据集的同时不灾难性遗忘旧数据,即增量学习.增量学习是使伪造语音检测技术快速用于实际应用并实现迭代更新的关键问题.
4 生成式伪造语音治理体系的构建
随着人工智能和数字技术的迅猛发展,音、图、文深度伪造技术快速普及,已引起全球对互联网空间信息安全的广泛关注.这些技术不仅增加了网络虚假信息的传播,也对国家安全等多个领域构成直接威胁.为此,我国亟需从技术应用、制度规范、教育宣传、国际合作等角度建立一个更系统全面的伪造语音综合治理框架,全面提升智能数字时代的安全水平.
4.1技术应用层面
加强深度伪造语音检测技术研究和应用,挖掘数据真实特征,提高检测算法对未知伪造方法鉴别的泛化性和鲁棒性,特别是对伪造语音当前面临的分布多样化、检测结果可解释性、学习更新能力等挑战进行深入研究.
推动伪造语音检测技术与语音应用程序之间的联合验证[24].以语音身份认证应用为例,用伪造语音检测解决语音身份认证的安全性问题,可以通过与身份认证算法串行、并行2种方法完成.伪造语音检测与身份认证系统串行流程如图1所示,把伪造语音检测置于身份认证系统之前,所有待认证语音第1步先进行伪造语音检测,如果第1步伪造语音检测结果将语音判为伪造语音,则身份认证系统可以直接输出认证拒绝结果;如果第1步伪造语音检测结果将语音判为真实语音,则可以进入第2步声纹识别,由声纹识别算法给出认证接受或拒绝结果.伪造语音检测在身份认证系统中与声纹识别模块并行流程如图2所示,将伪造语音检测并入身份认证系统中,语音信号同时被送入声纹识别和伪造语音检测中,根据2个算法计算的结果,再设置一层融合,根据融合后的结果判定身份认证接受还是拒绝.
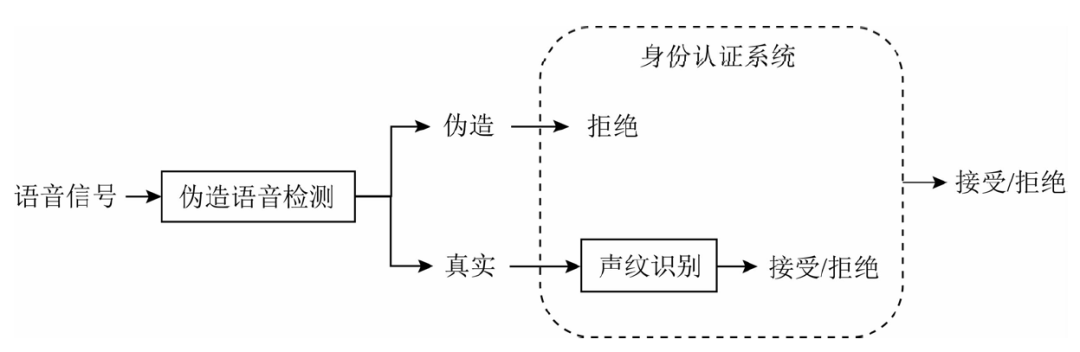
图1伪造语音检测与身份认证系统串行流程
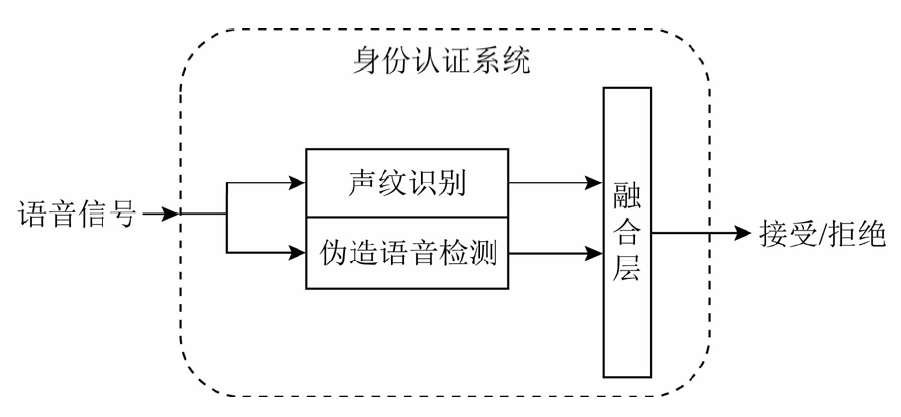
图2 伪造语音检测在身份认证系统中与声纹识别模块并行流程
强化数字水印和签名技术,在不影响整段语音音频的准确性和可理解性的前提下,为原始音频内容添加数字水印或加密签名,确保伪造语音设置了独特的标记,使音频具有来源可追溯性、防篡改性和真实性验证,保障语音音频的下游应用安全.
构建安全的语音数据库,创建被授权专用的声音样本数据库,保障未授权人的语音隐私,防止语音被随意采集与滥用.
4.2制度规范层面
对生成式伪造语音的技术发展和应用场景需要进一步进行指导与规范,可以从规范技术分类分级和健全伪造语音技术监管体系2个方面进行.
4.2.1规范技术分类分级标准
1) 定义标准:制定一套全面的标准评估深度伪造语音的质量、真实性和潜在风险,包括技术的复杂性、使用的算法、生成音频的逼真程度,以及其可能对个人和社会的影响.
2) 技术复杂性分级:根据所使用的人工智能和机器学习算法的复杂性,对伪造语音技术进行分级.高级算法生成的伪造语音可能更难以检测,因此风险等级更高.
3) 真实性分级:依据伪造语音与真实语音相似度的高低,对相关技术划分成不同的风险等级.高逼真度的伪造语音可能用于更具有欺骗性的场合.
4) 潜在风险分级:对潜在风险定级需要根据伪造语音的创建目的(如娱乐、教育、欺诈、恶意攻击)以及个人隐私、企业声誉、国家安全和社会秩序的影响.用途恶意且影响范围越广,风险等级越高.
4.2.2健全伪造语音技术监管体系
1) 注册系统建立:建立一个全国性的深度伪造技术注册系统,记录所有相关技术的详细信息,包括技术描述、用途、开发者信息等.
2) 实名制管理:引入实名制管理,确保注册系统中记录的每项技术都能追溯到具体的开发者或公司.
3) 安全评估:开发和应用深度伪造技术前,要求进行安全和风险评估,评估报告必须在技术注册时提交.
4) 持续监管:注册后,监管机构需对深度伪造技术的使用情况进行持续监督,确保其符合法律法规和伦理标准.
5) 信息披露:鼓励透明度,要求开发者定期更新技术信息,包括使用情况、影响评估等,并向公众披露.
6) 可检测性:难以检测的伪造语音应归入更高的风险级别,因为其更有可能逃避现有的安全和验证措施.
4.3公众教育宣传层面
要向公众传达伪造语音的危害以及治理的必要性.可以通过广告、社交媒体、宣传活动和公共演讲等方式教育公众.重点要强调伪造语音可能导致的社会和个人损害,包括虚假信息的传播、个人声音被滥用等.要定期更新公众和利益相关者关于伪造语音治理进展的信息,以保持公众的关注和参与.
为公众提供检测伪造语音的工具和资源,让他们能够分辨真实的语音和伪造的语音,包括开发应用程序、浏览器插件或在线课程等,帮助用户学习如何分辨真实语音和伪造语音.
4.4国际合作治理层面
目前,国内外都面临伪造语音的威胁,有必要进一步加强国际间的技术合作[27],实现信息共享.
1) 制定国际法律框架:国际社区可以合作制定国际法律框架,明确深度伪造技术的法律地位和国际标准.
2) 数据分享和情报合作:各国可以分享有关深度伪造技术的情报和数据,以便更好地了解和监测其传播和使用.
3) 技术标准和验证:国际合作可以推动制定共同的技术标准,以帮助检测和验证深度伪造内容.国际执法合作:各国执法机构可以加强合作,跨国打击深度伪造技术的制造和传播.
参考文献
[1]Gartner. Hype cycle for data, analytics and AI in China[EB/OL]. 2023 [2024-01-20]. https://www.gartner.com/en/documents/4538299
[2]McAfee. Artificial intelligence voice scams on the rise with 1 in 4 adults impacted[EB/OL]. 2023 [2024-01-20]. https://www.businesswire.com/news/home/20230501005587enArtificial/Intelligence/Voice/Scams/on/the/Rise/with/1/in/4/Adults/Impacted
[3]Coker C H. A model of articulatory dynamics and control[J]. Proceedings of the IEEE, 1976, 64(4): 452460
[4]Klatt D H. Software for a cascadeparallel formant synthesizer[J]. The Journal of the Acoustical Society of America, 1980, 67(3): 971995
[5]Charpentier F, Moulines E. Pitch-synchronous waveform processing techniques for text-to-speech synthesis using diphones[J]. Speech Communication, 1990, 9(5/6): 453467
[6]Tokuda K, Yoshimura T, Masuko T, et al. Speech parameter generation algorithms for hmm/based speech synthesis[C] //Proc of the Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2000: 13151318
[7]Oord A V, Dieleman S, Zen H, et al. WaveNet: A generative model for raw audio[J]. arXiv preprint, arXiv:1609.03499, 2016
[8]Ren Yi, Hu Chenxu, Tan Xu, et al. Fastspeech 2: Fast and high/quality end-to-end text to speech[J]. arXiv preprint, arXiv:2006.04558, 2020
[9]Khachatryan L, Movsisyan A, Tadevosyan V, et al. Text2Video-Zero: Text-to-image diffusion models are zero-shot video generators[J]. arXiv preprint, arXiv:2303.13439, 2023
[10]Shuang Z W, Bakis R, Shechtman S, et al. Frequency warping based on mapping formant parameters[C] //Proc of the 9th Int Conf on Spoken Language Processing. Grenoble, France: ISCA, 2006: 22902293
[11]Kaneko T, Kameoka H. Parallel-data-free voice conversion using cycle-consistent adversarial networks[J]. arXiv preprint, arXiv:1711.11293, 2017
[12]Hsu C C, Hwang H T, Wu Y C, et al. Voice conversion from non-parallel corpora using variational auto-encoder[C] //Proc of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conf. Hawaii: APSIPA, 2016: 16
[13]Shi Z. A survey on audio synthesis and audio-visual multimodal processing[J]. arXiv preprint, arXiv:2108.00443, 2021
[14]Kirchhuebel C, Brown G. Spoofed speech from the perspective of a forensic phonetician[C] //Proc of Interspeech. Grenoble, France: ISCA, 2022: 13081312
[15]Todisco M, Delgado H, Lee K A, et al. Integrated presentation attack detection and automatic speaker verification: Common features and Gaussian back-end fusion[C] //Proc of Interspeech. Grenoble, France: ISCA, 2018: 7781
[16]Todisco M, Delgado H, Evans N W. A new feature for automatic speaker verification anti-spoofing: Constant Q cepstral coefficients[C/OL] //Proc of Odyssey. 2016 [2024-01-16]. https://www.odyssey2016.org/
[17]Wu Z, Chng E S, Li H. Detecting converted speech and natural speech for anti-spoofing attack in speaker recognition[C] //Proc of Interspeech. Grenoble, France: ISCA, 2012: 17001703
[18]Gomez-Alanis A, Peinado A M, Gonzalez J A, et al. A light convolutional GRU-RNN deep feature extractor for ASV spoofing detection[C] //Proc of Interspeech. Grenoble, France: ISCA, 2019: 10681072
[19]Baevski A, Zhou Y, Mohamed A, et al. Wav2Vec2.0: A framework for self-supervised learning of speech representations[J]. Advances in Neural Information Processing Systems, 2020, 33: 1244912460
[20]Lv Z, Zhang S, Tang K, et al. Fake audio detection based on unsupervised pretraining models[C] //Proc of the Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2022: 92319235
[21]Patel T B, Patil H A. Combining evidences from mel cepstral, cochlear filter cepstral and instantaneous frequency features for detection of natural vs spoofed speech[C] //Proc of Interspeech. Grenoble, France: ISCA, 2015: 20622066
[22]Novoselov S, Kozlov A, Lavrentyeva G, et al. Stc anti-spoofing systems for the asvspoof 2015 challenge[C] //Proc of the Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2016: 54755479
[23]Wu Z, Das R K, Yang J, et al. Light convolutional neural network with feature genuinization for detection of synthetic speech attacks[J]. arXiv preprint, arXiv:2009.09637, 2020
[24]Tak H, Jung J W, Patino J, et al. End-to-end spectro-temporal graph attention networks for speaker verification anti-spoofing and speech deepfake detection[J]. arXiv preprint, arXiv:2107.12710, 2021
[25]Jung J W, Heo H S, Tak H, et al. Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention network[C]//Proc of the Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2022: 63676371
[26]郑方, 徐明星, 程星亮. 数据特征提取方法、录音重放检测方法、存储介质和电子设备: 中国, ZL201910646885.5[P]. 2019-11-05
[27]孙珵珵. 网络安全治理对策研究[J]. 信息网络安全, 2023, 23(6): 104110
作者简介
冯畅,博士研究生.主要研究方向为伪造语音检测.
吴晓龙,博士研究生.主要研究方向为语音情感识别.
赵熠扬,硕士研究生.主要研究方向为说话人识别.
徐明星,博士,副研究员.主要研究方向为语音情感识别、声纹识别.
郑方,博士,教授.主要研究方向为说话人识别、语音识别、自然语言处理.
(本文刊载在《信息安全研究》2024年第10卷第2期)
声明:本文来自信息安全研究,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
