近期,我们与复旦大学、中国科学院大学联合开源了大模型网络安全综合能力评测套件CS-Eval,评测矩阵全面覆盖11个大类,能客观评估大模型综合网络安全能力。该评测平台的推出,促进了大模型和数字世界网络安全的协同发展。
大模型时代,网络攻防技术螺旋式上升。
攻击者不断通过大模型等新技术来提升技术储备,安全防御技术也主动配备大模型等智能武器。目前网络安全领域缺乏一个支持用户自主操作的大模型网络安全综合能力评测套件,极大限制了大模型在网络安全方向的发展与应用。
CS-Eval 应运而生,阿里安全联合复旦大学、中国科学院大学发起并建立了一个全面客观的大模型网络安全评估数据集和自主评测平台,旨在推动大模型与网络安全技术的融合发展。
这些数据涵盖网络安全产业界、学术界的各种知识及应用场景,包括威胁检测与预防、漏洞管理与渗透测试、供应链安全、系统及软件安全基础、AI与网络安全等11个大类,以便更好地评估大模型在应对各种网络安全挑战时的表现。
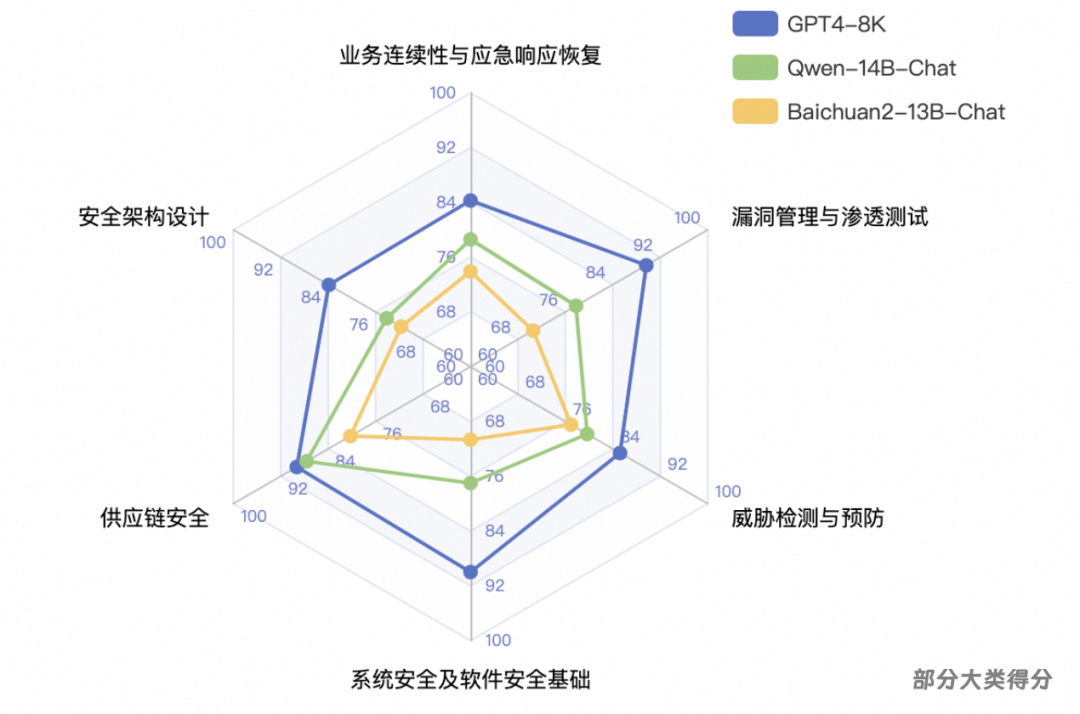
CS-Eval的核心目标,是促进网络安全行业的健康发展,消除评测偏见,构建一个用户主导、公平透明的测评生态系统。我们相信,通过这一平台,能够激发更多创新灵感,加速安全大模型技术迭代,共同守护数字世界的安全。
让网络安全大模型“有迹可循”
目前我们有三个主要使用场景。
一方面,对于大模型开发者而言,这样的评估数据集能够帮助他们全面了解自己模型在网络安全方面的水平并了解潜在弱点,进而针对性地加强模型处理网络安全任务的能力。由于部分开发者可能更加关注细分领域的网络安全水平,因此我们也提供了细分领域的模型评测及排行。
另一方面,对于大模型落地网络安全的应用者而言,可以根据我们的评估结果选择适合自己任务和领域的大模型,从而提高解决实际问题的效果。全面综合的评估数据集对于促进模型的发展和用户的选择都具有重要意义。
最后,对于在网络安全与大模型结合的研究者,我们一是提供了领域的竞赛参考标准,二是提供了大模型的能力矩阵,我们欢迎工业界与学术界共同讨论以增强大模型网络安全的评测全面性、平衡性、客观性。

大模型网络安全综合能力评估矩阵
CS-Eval推出了网络安全大模型能力矩阵,因此我们从矩阵的不同大类领域进行评测。覆盖的领域任务大类包括漏洞管理与渗透测试、威胁检测与预防、安全架构设计、供应链安全、基础设施安全、AI与网络安全、系统及软件安全基础、加密技术与密钥管理、访问控制与身份管理、业务连续性与应急响应恢复、数据安全和隐私保护。
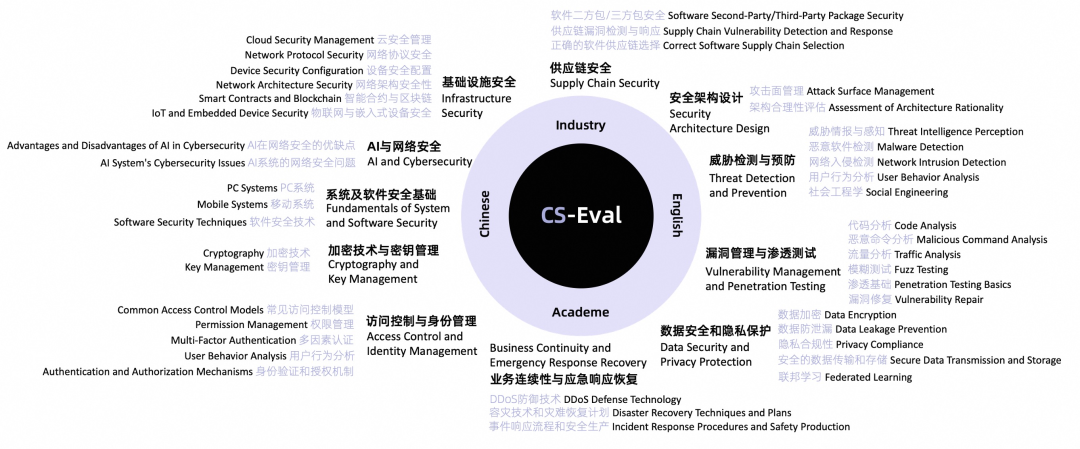
CS-Eval的优势
全面覆盖,题量均衡:CS-Eval精心设计题库,覆盖网络安全11个大领域,42个子领域,既参考了安全四大顶会的议程设置,又兼顾了大模型实际应用的需求,实现了理论与实践的结合。我们针对不同的网络安全子领域,针对性设计了单项选择题、多项选择题、判断题、知识抽取题等题目类型,每个子领域的题目量在100个左右。
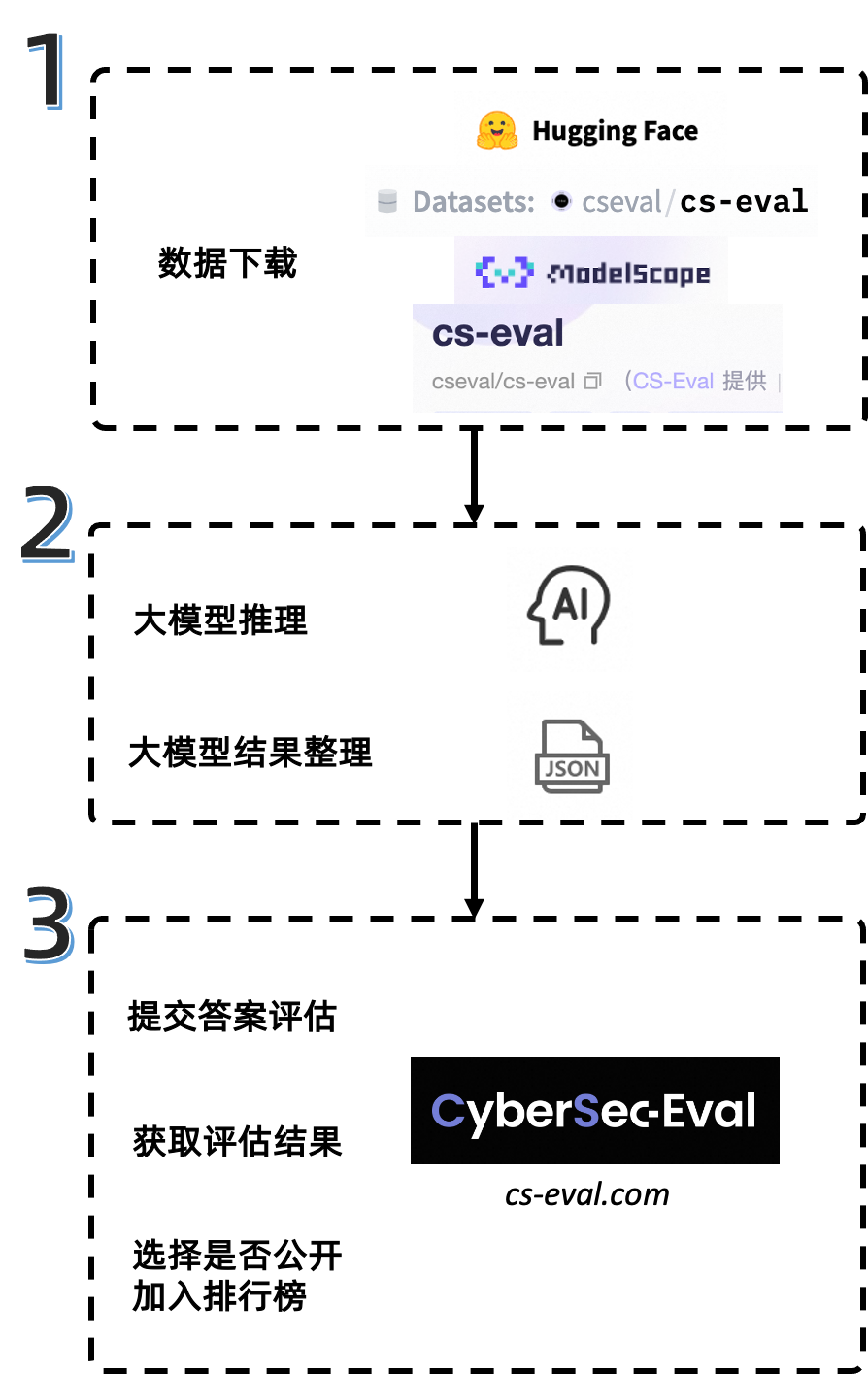
自主评测,高效便捷:用户从数据集下载到提交评估与结果反馈,全程可在Hugging Face/ModelScope + CS-Eval评测平台自主进行,具体细节可参考Github说明。
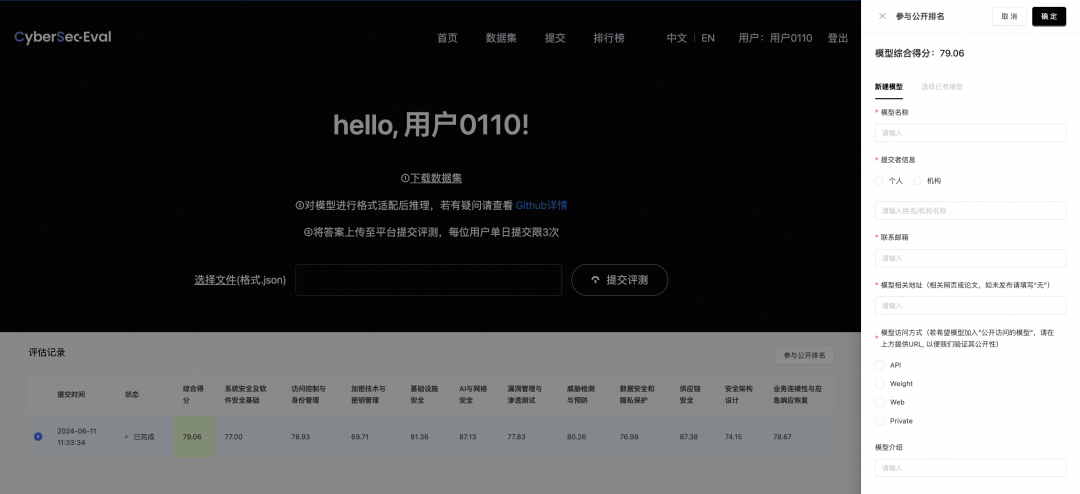
产研结合,贴近实战:联合产业界与学术界的共同力量,既有模拟真实世界的安全挑战,又有学术场景和课堂知识,题目语言覆盖中英双语,更加客观地从多维度评估大模型的综合能力。
排行榜单,多维评价:提供综合Leaderboard与网络安全细分大领域的Leaderboard,充分契合网络安全行业的多元化需求。
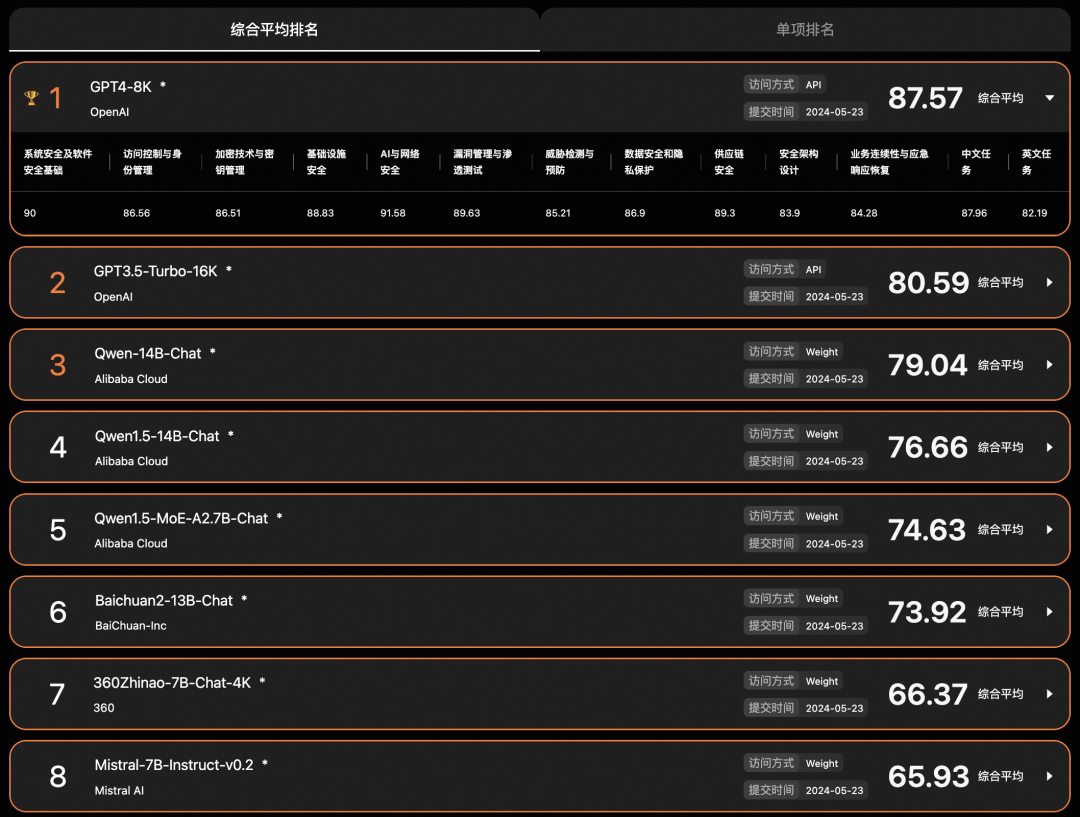
CS-Eval数据集已开源至多个社区,并提供用户可自主完成评估及展示的平台。
Github:
https://github.com/CS-EVAL/CS-Eval
CS-Eval评测平台:
https://cs-eval.com
Hugging Face:
https://huggingface.co/datasets/cseval/cs-eval
魔搭ModelScope:
https://modelscope.cn/datasets/cseval/cs-eval/summary
我们真诚邀请不同的安全平台/公司、科研机构及高校师生客观地使用CS-Eval,既可作为模型能力的客观考量,也可作为领域比赛的重要参考。
声明:本文来自知安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
