
前情回顾·AI网络攻击能力动态
安全内参12月12日消息,AI巨头OpenAI发布报告称,旗下前沿AI模型的网络能力正快速提升,并警告即将发布的模型很可能带来“高”等级风险。
这些模型日益增强的能力,可能会显著扩大能够实施网络攻击的潜在群体。
OpenAI指出,其近期发布的模型能力已出现明显跃升,尤其是在模型可自主运行更长时间方面,从而为类似暴力破解等依赖长时间运行的攻击创造条件。
该公司称,GPT-5在8月的夺旗赛(CTF)中得分为27%,而GPT-5.1-Codex-Max在11月则达到了76%。报告指出,这一变化反映出与网络安全相关的性能正加速提升。
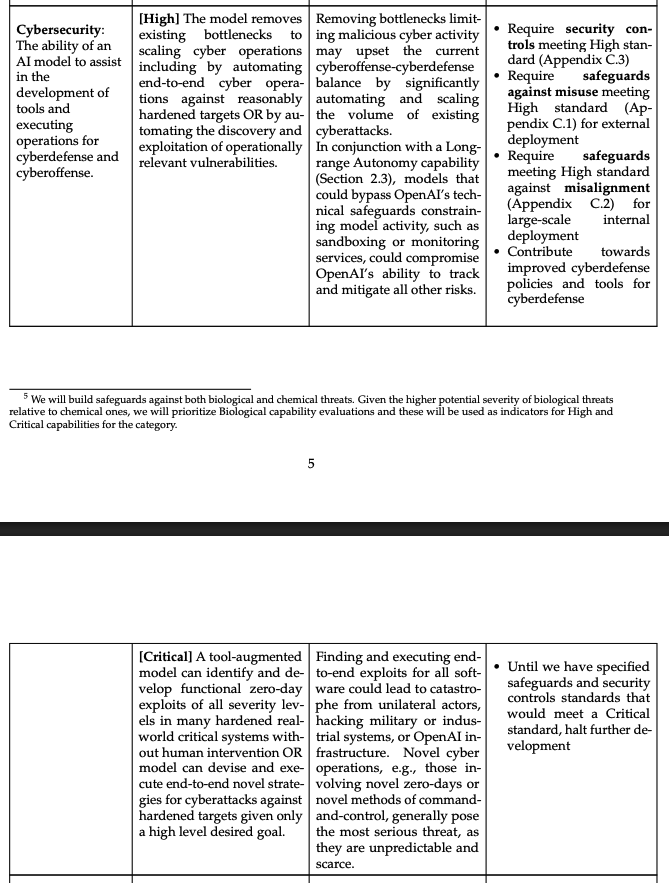
图:OpenAI定义的高级别网络安全能力
OpenAI在报告中表示:“我们预计即将推出的AI模型将沿着这一轨迹继续发展。因此,我们在规划和评估时,假设每个新模型都可能达到我们准备度框架中‘高’等级网络安全能力水平。”
高风险模型将拥有长期运行的能力
OpenAI在今年6月曾就生物武器风险发布类似警告,随后在7月推出了ChatGPT Agent,而这一模型的风险确实被评为“高”等级。当前的网络安全担忧,与OpenAI年初针对模型在生物武器滥用方面能力提升所发出的警示相呼应。
“高”是排名第二的风险等级,仅次于“关键”级别,即模型不适宜公开发布。
然而,公司并未说明何时会出现首批被评为具有“高”等级网络安全风险的模型,也未指出哪些未来模型类型可能构成此类风险。
OpenAI工程师Fouad Matin表示:“我想特别强调的一个触发因素,是模型能够长时间持续运行。”
Matin称,这类依赖长时间运行的暴力破解攻击更容易被防御。
他补充说:“在任何具有防御机制的环境中,这类行为都很容易被发现。”他指出,即便模型变得更强,暴力破解尝试依然可以被检测到。
OpenAI与行业伙伴共同加强网络韧性
能够发现安全漏洞的领先模型能力正不断提升,这不仅发生在OpenAI。
因此,OpenAI表示,它正持续加强与各方在网络安全威胁方面的合作。比如,2023年,OpenAI与其他领先实验室共同创办了前沿模型论坛。
公司称,将成立一个独立的前沿风险委员会。委员会将扮演咨询小组的角色,“使经验丰富的网络防御者和安全从业者能与OpenAI团队密切协作”,让外部网络安全专家定期参与内部工作交流。
此外,OpenAI正在对Aardvark进行私测,这是一款供开发者用来发现其产品安全漏洞的工具。开发者必须申请才能获得Aardvark的使用权限。OpenAI表示,在早期试用中,Aardvark已发现了多个关键安全漏洞。
参考资料:https://www.axios.com/2025/12/10/openai-new-models-cybersecurity-risks、https://www.grcreport.com/post/openai-flags-rising-cyber-threat-as-next-generation-models-advance
声明:本文来自安全内参,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
