基本信息
原文标题:SemFuzz: A Semantics-Aware Fuzzing Framework for Network Protocol Implementations
原文作者:Yanbang Sun, Quan Luo, Yuelin Wang, Qian Chen, Benjin Liu, Ruiqi Chen, Qing Huang, Xiaohong Li, Junjie Wang
作者单位:天津大学、奇安信代码安全团队、江西师范大学
关键词:网络协议、模糊测试、语义建模、大语言模型、漏洞检测
原文链接:https://arxiv.org/pdf/2603.05989
开源代码:暂无
论文要点
论文简介:网络协议是现代通信的基础,但其实现中常常包含由于对规范语义理解不足而产生的语义漏洞。现有的灰盒和黑盒测试方法缺乏对协议的语义建模,难以精确表达测试意图和覆盖边界条件。此外,它们通常依赖于崩溃等粗粒度的预言机,不足以识别深层的语义漏洞。为了解决这些局限性,本文提出了一个语义感知的模糊测试框架 SemFuzz。该框架利用大语言模型从 RFC 文档中提取结构化的语义规则,并生成故意违反这些规则的测试用例以编码特定的测试意图。然后通过比较观察到的响应与预期响应来检测深层语义漏洞。对七个广泛部署的协议实现的评估表明,SemFuzz 识别出了 16 个潜在漏洞,其中 10 个已被确认。在已确认的漏洞中,5 个是之前未知的,4 个已被分配 CVE 编号。这些结果证明了 SemFuzz 在检测语义漏洞方面的有效性。
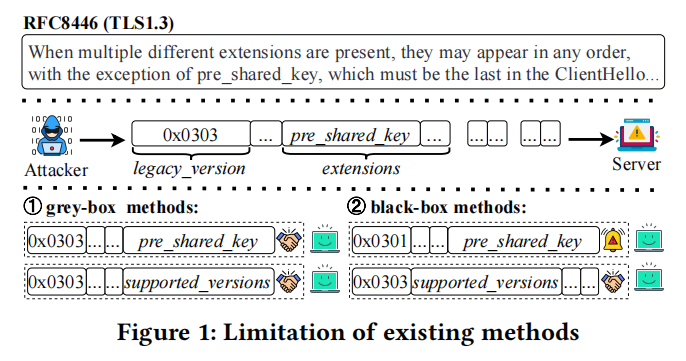
研究目的:本研究的主要目标是解决现有网络协议测试方法在检测语义漏洞时的两个核心问题。第一,现有方法缺乏语义感知能力,难以生成有效覆盖边界场景的测试用例。第二,它们依赖于粗粒度的预言机(如程序崩溃),导致许多不会立即触发崩溃的语义漏洞被忽略。研究的预期成果是开发一个能够系统性地发现深层语义漏洞的黑盒模糊测试框架,特别是针对闭源协议栈实现。研究的意义在于提高网络协议实现的安全性,防止大规模的安全威胁传播,尤其是在政府机构、工业控制系统和医疗基础设施等敏感领域。
研究贡献:
本文提出了一个语义感知的模糊测试范式,利用大语言模型从 RFC 文档中提取协议语义,将非结构化的语义知识转化为可执行的测试意图,以解决现有方法的局限性。
设计了一个闭环工作流,集成了语义建模、意图驱动的变异和响应验证,其中语义规则指导生成违反性测试用例和构建精确的语义预言机,从而实现对深层语义漏洞的高效检测。
对七个广泛部署的协议实现进行了系统评估,证明了 SemFuzz 的卓越有效性,发现了 10 个真实漏洞,包括 5 个之前未知的漏洞(4 个被分配了 CVE 编号)。
背景与动机
网络协议是现代通信系统的基石,支撑着各种公共服务的数据交换。然而,协议实现中的缺陷往往演变成严重的安全威胁。这个问题对于闭源协议栈尤为关键,因为它们广泛部署在政府机构、工业控制系统和医疗基础设施等敏感领域。一旦引入缺陷,其影响可能大规模传播。例如,Windows IPv6 协议栈(tcpip.sys)曾暴露出 Bad Neighbor 漏洞,使近十亿设备面临远程拒绝服务攻击的风险。最近的研究进一步表明,此类漏洞的数量正在增加,凸显了对更有效检测技术的迫切需求。
现有方法通常分为两类:灰盒测试和黑盒测试。尽管这些方法取得了显著成功,但在检测协议实现中的语义漏洞时,特别是在闭源系统中,仍然存在两个固有局限性。首先,它们缺乏语义感知能力,难以生成有效覆盖边界场景的测试用例。其次,它们依赖于粗粒度的预言机,导致许多不会立即触发崩溃的语义漏洞被忽略。
论文通过一个典型例子说明了这些局限性。根据 RFC 8446 第 4.2 节的规定,当 ClientHello 消息中存在 pre_shared_key 扩展时,它必须作为扩展列表中的最后一个扩展出现。然而,Windows 平台上的 TLS 实现(schannel.dll)并未严格遵守这一要求。攻击者可以构造一个将此扩展放置在非终端位置的消息,仍然能够完成握手。经过长时间的特定交互后,这种行为可能导致程序崩溃,从而引发拒绝服务攻击。现有方法难以检测此类语义漏洞。具体而言,灰盒方法依赖于覆盖率等运行时信号来驱动变异,但对于闭源协议栈,稳定的二进制插桩通常不可行;一旦失去反馈,灰盒工具就退化为随机或语法级变异器。此外,由于缺乏语义知识,它们难以构造边界测试用例,如扩展字段的重新排序,导致漏洞被遗漏。黑盒方法不依赖于插桩,但通常只建模语法结构,同样缺乏对语义的理解。它们可以变异字段值以触发警报,但仍然无法检测到这个漏洞。即使使用手工制作的模板生成语义违反输入,粗粒度的预言机(如崩溃)也常常无法识别不会立即显现的语义偏差,导致漏洞被遗漏。
研究方法
SemFuzz 是一个语义感知的黑盒模糊测试框架,专门用于检测协议实现中的深层语义漏洞。其核心思想是利用大语言模型从 RFC 文档中提取语义知识,并使用它来指导一个由语义建模、意图驱动变异和响应验证组成的闭环测试过程。为了弥补语义感知能力的不足,SemFuzz 引入了语义建模,利用大语言模型解析 RFC 文档并提取结构化的语义规则。重要的是,每条规则都指定了构造约束(描述有效的消息格式)和处理期望(定义这些消息应触发的预期响应)。它将非结构化的自然语言描述转换为精确的、机器可读的规则,从而为后续测试建立了坚实的语义基础。
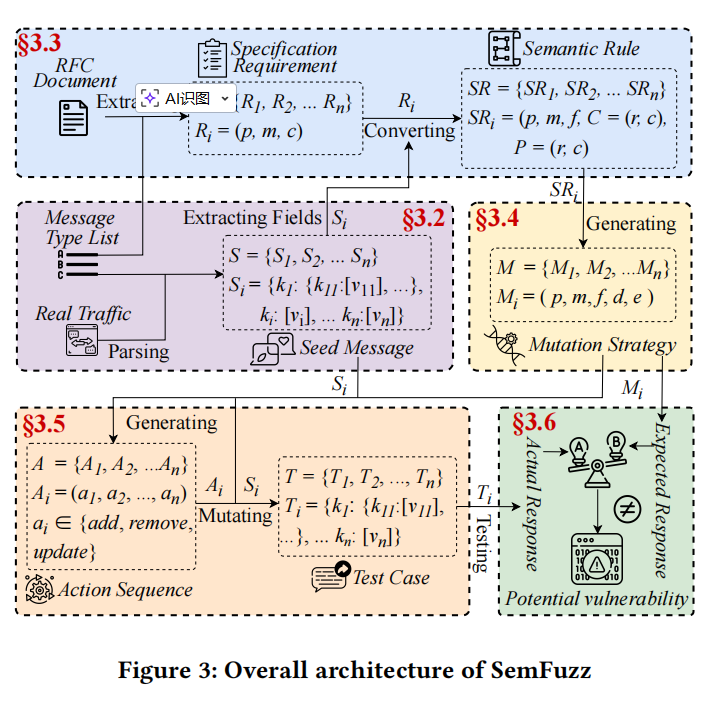
基于提取的语义规则,SemFuzz 采用意图驱动的变异策略来生成有针对性的测试用例。具体而言,它根据给定语义规则的构造约束,对从真实流量中捕获的种子消息应用原子操作(如添加、删除或更新字段),从而生成故意违反语义约束的测试输入。这确保了每个测试用例都带有明确的测试意图,旨在评估协议实现在特定边界条件下的行为。最后,为了解决预言机问题,引入了精确的语义预言机来检测语义漏洞。对于每个旨在违反特定构造约束的测试用例,SemFuzz 从语义规则中提取其相应的处理期望,并将其作为该测试的预期响应。预言机的定义如下:如果目标的实际响应偏离了这个预期响应,则识别出潜在漏洞。这种基于规范的响应比较机制使 SemFuzz 能够超越传统的崩溃或内存错误检测,从而系统性地揭示各种关键的语义漏洞。
SemFuzz 框架由五个阶段组成:流量收集器、结构化规则构造器、变异策略生成器、测试用例生成器和响应验证器。流量收集器首先基于给定的消息类型列表收集真实世界的流量,从中构造一组种子消息。每个种子表示为从字段键到值的映射。同时,结构化规则构造器使用大语言模型解析 RFC 文本,提取需求,并进一步将它们转换为语义规则。对于选定的语义规则,变异策略生成器生成一个或多个候选变异策略,每个策略编码一个违反构造规则的特定策略。基于变异策略和种子消息,SemFuzz 然后生成一组动作序列,动作序列由一系列原子动作组成,如添加、删除或更新。将动作序列应用于相应的种子消息,然后产生一组测试用例。每个测试用例在保持语法有效性的同时故意违反构造规则。最后,测试用例集被发送到目标协议实现。对于每个测试用例,记录其实际响应并与变异策略的预期响应进行比较。如果两者不一致,则认为实现存在潜在漏洞。
实验评估
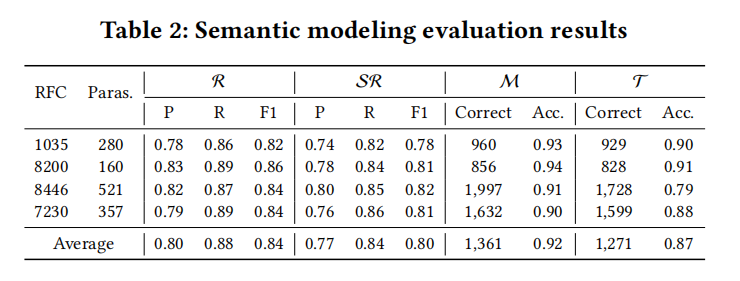
研究团队对 SemFuzz 进行了全面的实验评估,旨在回答四个核心研究问题。首先是基于大语言模型的语义建模的有效性。实验结果表明,在处理所有 1,318 个 RFC 段落后,框架在识别规范需求和将其转换为语义规则两个核心阶段都表现出强劲的性能。平均 F1 分数分别达到 0.84 和 0.80,表明 SemFuzz 能够准确地从非结构化文本中提取和结构化协议语义。高质量的语义规则为后续任务提供了坚实的基础。基于这些规则,下游模块成功生成了 5,940 个变异策略和测试用例,平均准确率分别达到 0.92 和 0.87。这为语义建模方法的有效性提供了有力证据。研究还观察到不同协议之间的性能差异。特别是对于 TLS 1.3(RFC 8446),测试用例生成的准确率降至 0.79,明显低于其他协议(均高于 0.90)。这种下降主要源于 TLS 消息(如 ClientHello)的结构复杂性,其深度嵌套的字段对大语言模型的推理能力提出了更大挑战,偶尔会导致引用不存在字段的变异策略。尽管存在这种差异,框架的整体性能仍然强劲,证实了语义规则建模方法的有效性。
其次是与现有方法的比较。SemFuzz 总共发现了 16 个潜在漏洞,其中 10 个被开发者确认为真实漏洞,准确率为 62.5%。基线方法检测到的真实漏洞数量分别为:BLEEM(5 个)、ChatAFL(1 个)、Hdiff(2 个)和 Fuzztruction-Net(0 个)。在所有工具共同发现的 11 个独特漏洞中,SemFuzz 覆盖了 10 个,表现最佳。对于灰盒方法,Fuzztruction-Net 依赖于通过源代码插桩进行故障注入,使其不适用于闭源目标(如 dns.exe、tcpip.sys)。此外,由于缺乏语义感知能力,它无法生成有针对性的测试用例,即使在开源目标上也未发现任何漏洞。ChatAFL 虽然利用了大语言模型,但主要针对基于文本的协议设计,无法处理 DNS、IPv6 和 TLS 等二进制协议。此外,它缺乏明确的语义建模,仅在 http.sys 中发现了一个漏洞。对于黑盒方法,Hdiff 专门针对 HTTP 协议设计,因此对其他协议的可扩展性较差。此外,它严重依赖于手动预定义的模板,限制了其探索边界条件的能力,仅发现了两个漏洞。BLEEM 表现出相对较强的性能,检测到 5 个漏洞。值得注意的是,它检测到 LibreSSL 中的一个独特漏洞。这个漏洞涉及 X.509 证书解析模块中的内存损坏,其行为由 RFC 5280 等独立标准指定。由于本研究专注于基于 RFC 8446 建模 TLS 1.3 协议的语义,因此未检测到此漏洞。尽管如此,BLEEM 缺乏对 RFC 规范的深入理解,其随机变异和状态探索策略难以覆盖复杂的边界条件。此外,它依赖于粗粒度的预言机(如服务器崩溃),进一步限制了其性能,导致遗漏了 5 个漏洞。

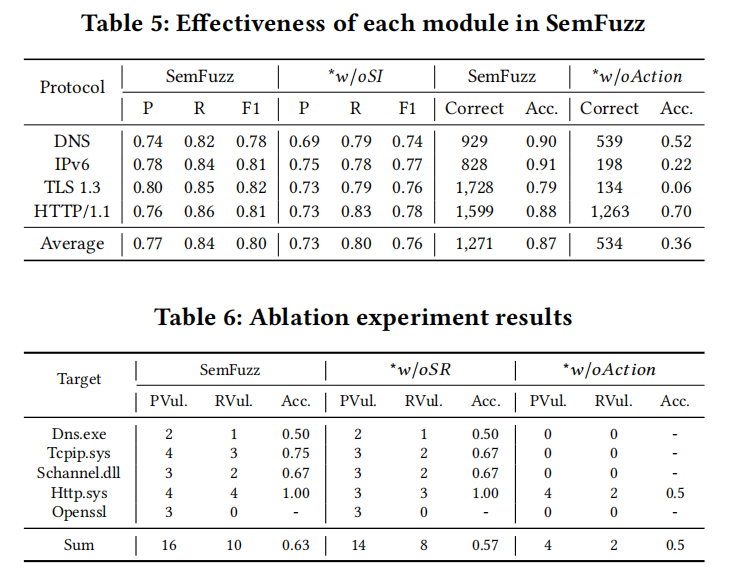
第三是消融研究。为了评估 SemFuzz 中每个核心模块的有效性,研究团队进行了一系列消融研究。首先,规范识别模块显著提高了从 RFC 文档中提取语义规则的质量。SemFuzz 在语义规则提取中实现了平均 77% 的精确率、84% 的召回率和 80% 的 F1 分数。相比之下,没有此模块的变体(w/o SI)的 F1 分数为 76%。这表明该模块有效地过滤了无关文本,并为后续结构化建模提供了精确的输入,从而提高了语义规则提取的整体性能。其次,动作序列生成模块对测试用例生成的质量具有决定性影响。结果显示,SemFuzz 平均生成 1,271 个正确的测试用例,准确率为 87%。当禁用此模块(w/o Action)时,系统仅生成 534 个正确用例,准确率急剧下降至 36%。对于 IPv6 和 TLS 1.3 等复杂协议,性能差距变得更加明显,准确率分别降至 22% 和 6%。这些结果表明,如果没有高级动作指导,大语言模型难以精确定位特定字段并生成一致的字节级变异。最后,每个模块对漏洞检测的贡献也得到了验证。SemFuzz 识别出 16 个潜在漏洞,其中 10 个是真实漏洞。当移除规范识别模块(w/o SI)时,确认的漏洞数量降至 8 个,证明了细粒度语义建模对漏洞检测的重要性。此外,禁用动作序列生成(w/o Action)严重降低了模糊测试的有效性,仅产生 2 个真实漏洞。这一结果验证了动作序列在将变异策略转换为可执行测试用例中的关键作用。
第四是模型对模糊测试的影响。研究团队将大语言模型 GPT-4o 替换为 GPT-5、Gemini-1.5 Pro 和 Gemini-2.5 Pro,并在相同设置下进行实验。结果显示,尽管使用了不同的大语言模型,所有变体都能够发现至少 9 个真实漏洞。这表明 SemFuzz 的有效性主要源于其闭环和语义感知的框架设计,而不是依赖于任何特定模型的独特能力。此外,即使是较早的模型(如 GPT-4o)在框架的指导下也能覆盖大多数关键边界条件。结果还揭示了由不同推理能力引起的性能差异。例如,Gemini-1.5 Pro 检测到的潜在漏洞数量最多(18 个),但精确率最低(50%),因为它倾向于采用更激进的变异策略。随着大语言模型推理能力的提高,漏洞检测的精确率也相应提高。Gemini-2.5 Pro 实现了最高的精确率,达到 67%。
发现的漏洞
SemFuzz 在七个广泛部署的协议实现中发现了 10 个已确认的真实漏洞,其中包括 5 个之前未知的漏洞,4 个已被分配 CVE 编号。这些漏洞涵盖了多种类型和影响范围,充分展示了 SemFuzz 在检测深层语义漏洞方面的能力。在 DNS 实现(Dns.exe)中,发现了一个缓存污染漏洞,该漏洞源于对 DNS 响应中未经请求记录的验证不足,已被修复。
在 IPv6 实现(Tcpip.sys)中,发现了三个漏洞:一个整数溢出漏洞(CVE-2021-24074),由目标选项头中未识别的选项类型引起;一个缓冲区溢出漏洞(CVE-2022-34718),由 ESP 头在分片头之前的错误放置引起;以及另一个整数溢出漏洞,由解析格式错误的目标选项头引起。
在 TLS 实现(Schannel.dll)中,发现了两个释放后使用(UAF)漏洞(CVE-2023-28233 和 CVE-2023-28234),都是由于 ClientHello 中 pre_shared_key 扩展的位置检查缺失引起的。
在 HTTP 实现(Http.sys)中,发现了四个漏洞:一个篡改漏洞,由头字段名称和冒号之间额外空格的不当处理引起;一个释放后使用漏洞,由 Accept-Encoding 头中随机值的解析引起;一个缓冲区溢出漏洞,由 HTTP Trailers 的不当处理引起;以及一个整数溢出漏洞,由过长 ServiceName 的长度验证缺失引起。值得注意的是,其中两个漏洞(#2 和 #3)是由 SemFuzz 的早期版本(基于规则的建模)发现的,而当前版本通过基于大语言模型的自动化建模实现了相同的结果。
相关工作
近年来,协议模糊测试的研究可以大致分为灰盒和黑盒两种方法。灰盒方法利用插桩来推断协议状态并指导测试生成。例如,AFLNet 结合响应代码推断和覆盖率反馈,而 ChatAFL 利用大语言模型派生的语法知识用于基于文本的协议。其他技术则向通信对等方注入故障。然而,它们对源代码级插桩的依赖限制了对闭源目标(如 tcpip.sys)的适用性。黑盒模糊测试器避免了插桩,因此适合闭源环境。BLEEM 构建基于响应的状态图,Snipuzz 采用响应感知变异。然而,由于缺乏语义指导,它们难以生成针对边界行为的意图驱动输入,并依赖崩溃作为粗略的预言机。HDiff 使用 RFC 引导的差异测试来检测 HTTP 中的语义分歧,但依赖于手动模板,语义覆盖有限。从 RFC 中提取规则已被探索用于安全分析和测试自动化。例如,一些研究尝试从规范中自动提取有限状态机(FSM)以支持自动化安全分析。此外,mGPTFuzz 和 LLMIF 利用大语言模型推断特定协议(如 Zigbee)的消息结构以指导测试。然而,这些方法缺乏细粒度的语义建模(如字段级约束),限制了它们发现语义漏洞的能力。
结论
本文提出了一个语义感知的黑盒测试框架 SemFuzz。该框架利用大语言模型从 RFC 文档中提取结构化的语义规则。这些规则不仅指导生成故意违反的测试用例,还识别精确的语义预言机,从而解决了现有方法在语义建模、意图表达和语义漏洞检测方面的局限性。在对七个广泛使用的协议实现的评估中,SemFuzz 发现了 16 个潜在漏洞,其中 10 个被确认,包括 5 个之前未知的漏洞(4 个被分配了 CVE 编号),证明了框架的有效性。这项研究为网络协议安全测试领域做出了重要贡献,为未来的研究和实践提供了新的方向和工具。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
