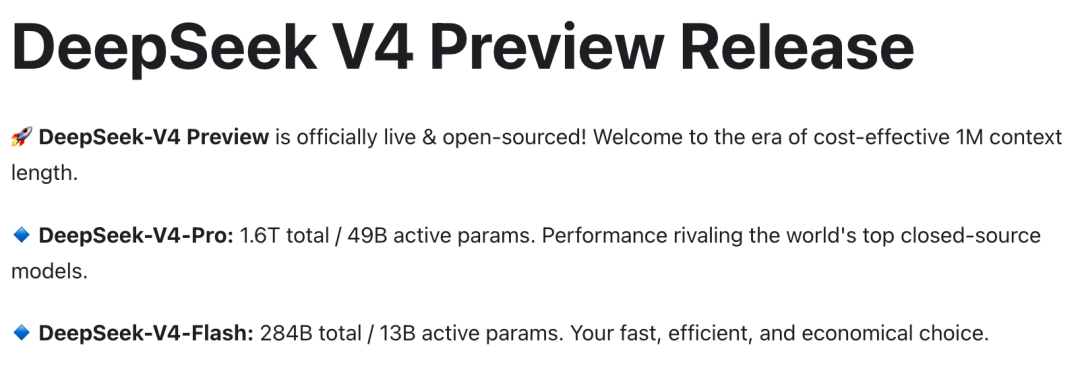
DeepSeek-V4 Preview 正式上线并开源。
官方发布信息显示,DeepSeek-V4-Pro 为 1.6T 总参数、49B 激活参数;DeepSeek-V4-Flash 为 284B 总参数、13B 激活参数;两个模型都支持 1M 上下文,并支持 Thinking / Non-Thinking 双模式。
https://api-docs.deepseek.com/news/news260424
如果只看参数和榜单,这可能是一篇模型能力分析。
但从 AI 安全角度看,DeepSeek-V4 更值得关注的是另一件事:
百万上下文正在变得更便宜、更开放、更容易部署。
这会改变 Agent 应用的工程形态,也会改变安全边界。
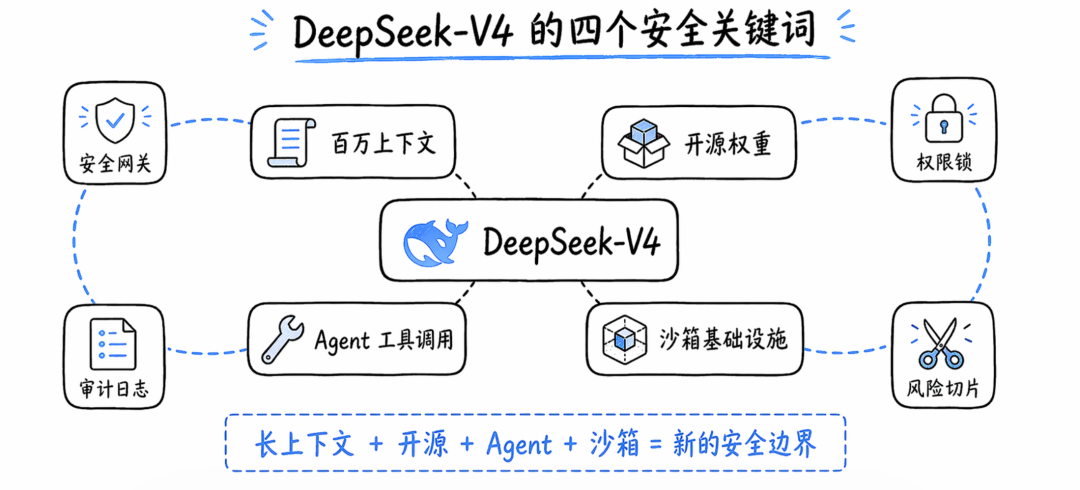
DeepSeek-V4 把百万上下文做成常态能力
DeepSeek-V4 技术报告的摘要写得很清楚:DeepSeek-V4 系列包括两个 MoE 模型,V4-Pro 1.6T 总参数、49B 激活参数,V4-Flash 284B 总参数、13B 激活参数,都支持一百万 token 上下文。模型在架构上引入 CSA/HCA 混合注意力、mHC 和 Muon 优化器,并在超过 32T token 上进行预训练。
真正关键的是效率。
报告披露,在 1M token 上下文设置下,DeepSeek-V4-Pro 相比 DeepSeek-V3.2 只需要 27% 的单 token 推理 FLOPs 和 10% 的 KV cache;DeepSeek-V4-Flash 更进一步,只需要 10% 的单 token FLOPs 和 7% 的 KV cache。
这组数字的安全含义很直接。
过去,百万上下文更像一种高端能力展示。
现在,它开始变成可常态化使用的工程能力。
当百万上下文足够便宜,企业和开发者就会更自然地把完整材料塞进模型:
一个完整代码仓库。
一批合同和招投标文件。
一整套会议纪要。
一段很长的客服聊天记录。
一个项目的所有需求、设计、测试、日志。
一批网页、PDF、邮件、表格、知识库文档。
模型读得越多,价值越大。
模型读得越多,风险也越复杂。
因为风险不一定在用户当前问题里,可能藏在上下文的某个角落。
模型在“压缩地阅读世界”
DeepSeek-V4 的关键架构是 hybrid attention,也就是 CSA 和 HCA 的混合注意力。
技术报告解释,CSA 会沿序列维度压缩 KV cache,然后执行 DeepSeek Sparse Attention;HCA 则对 KV cache 做更激进的压缩,但保留 dense attention。
可以通俗理解为:
CSA 像是在超长上下文里先做压缩索引,再从压缩后的内容中挑重点看。
HCA 像是把上下文压得更狠,但保留整体可见性。
这样做是为了解决普通注意力在超长上下文下算不动、存不下的问题。报告还提到,DeepSeek-V4 采用混合存储格式,RoPE 维度用 BF16,其余维度用 FP8,FP4 也被用于极长上下文下的 attention 计算,压缩注意力和混合注意力共同降低 KV cache 和计算 FLOPs。
从安全角度看,这里有一个很重要的问题:
当模型通过压缩、稀疏选择、缓存复用来阅读百万上下文时,外部安全系统不能再假设“模型完整、均匀、透明地读了所有内容”。
攻击者可以把恶意指令藏在一份长文档的脚注里,藏在代码注释里,藏在网页不可见区域里,藏在邮件转发链的历史消息里,藏在表格备注里。
长上下文让模型拥有更强的信息整合能力,也让提示注入拥有更多藏身空间。
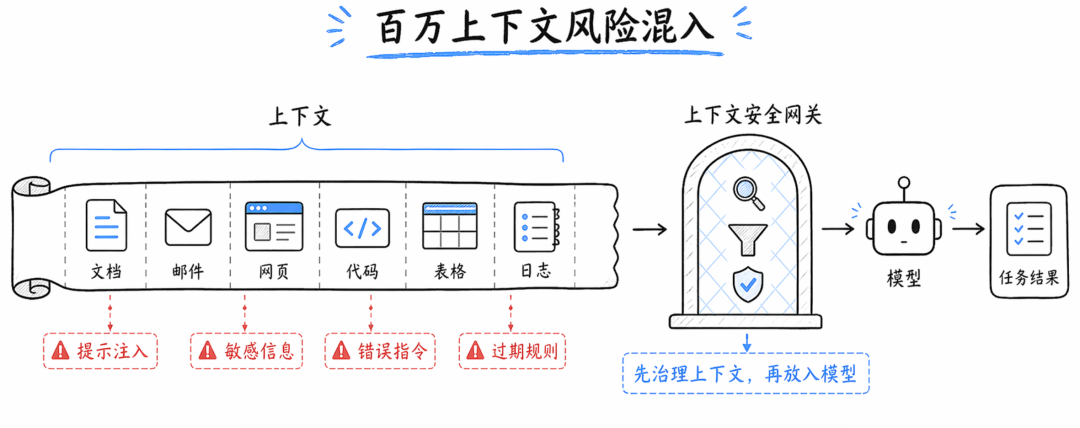
所以,长上下文安全不能只做最终输出审核。
更合理的方式是上下文前置治理:
进入模型前先做来源标注。
把用户指令和外部资料分开。
对不可信网页、邮件、文档做风险扫描。
识别隐藏指令、越权请求、数据外传诱导。
对高风险片段做隔离、降权、摘要化或人工复核。
模型输出前再做结果检测。
工具调用前再做动作确认。
长上下文会带来新的数据安全问题
DeepSeek-V4 的技术报告里有一节讲 KV cache 管理。
由于 CSA/HCA 混合注意力会产生多种类型、不同大小、不同更新规则的 KV cache,DeepSeek-V4 设计了定制化 KV cache 布局。报告还提到,在服务 DeepSeek-V4 时,会使用 on-disk KV cache storage 来复用 shared-prefix 请求,减少重复 prefill。
这对推理效率很重要。
但从安全角度看,缓存复用也会带来新的治理问题。
在企业应用里,长上下文常常包含敏感内容:
合同原文
客户数据
代码仓库
会议记录
日志片段
员工信息
业务策略
如果系统为了性能把前缀 KV cache 写到磁盘,并在多个请求之间复用,就必须回答几个安全问题:
缓存里有没有敏感信息的等价表达?
不同租户之间是否完全隔离?
缓存命中是否可能跨用户、跨组织、跨权限域?
缓存生命周期多长?
缓存是否加密?
缓存删除是否彻底?
缓存是否进入审计范围?
这类问题在短上下文时代没那么显眼。
到了百万上下文时代,缓存本身就成了重要资产。
未来企业部署长上下文模型,不能只问“模型会不会泄露数据”,还要问“推理系统如何管理长上下文缓存”。
Agent 能力是被专门训练出来的
DeepSeek-V4 不是简单把上下文窗口拉长。
技术报告里明确提到,后训练采用两阶段范式:先分别培养数学、编码、Agent、指令遵循等领域专家模型;基础模型先做 SFT,再用 GRPO 做强化学习;最后通过 on-policy distillation,把多个专家能力整合到统一模型中。
这说明 Agent 能力不是发布后顺手测一下,而是在训练阶段被专门强化。
这点很重要。
因为一旦模型具备更强的 Agent 能力,它会更适合做复杂任务:
理解目标
拆分步骤
调用工具
处理工具返回结果
保留任务状态
持续修正计划
跨文档、跨代码、跨环境推进任务
而这些能力一旦开源、低成本、长上下文,就会迅速进入各种本地 Agent 框架。
这对安全行业意味着:
以后需要评估的对象,不只是 DeepSeek-V4 这个模型本体。
还要评估下游开发者用它搭出来的 Agent 系统。
模型有没有内容安全能力是一层,Agent 有没有权限隔离、沙箱、日志、确认、回滚,是另一层。
真正的风险往往出现在第二层。
工具调用格式的变化也会影响 Agent 安全
DeepSeek-V4 技术报告还提到一个细节:它引入了新的工具调用 schema,使用特殊的 |DSML| token 和基于 XML 的工具调用格式。报告称,这种 XML 格式能缓解 escaping failures,减少工具调用错误,提供更稳健的模型-工具交互接口。
这看似是工程细节,其实和安全有关。
工具调用接口越稳定,Agent 越容易可靠执行复杂动作。
但工具调用接口越可靠,错误动作的执行概率也越需要被控制。
过去模型工具调用不稳定,有时反而限制了风险传播。
未来工具调用越来越规范,安全问题会从“模型能不能正确调用工具”,转向“模型有没有资格调用这个工具”。
这也是 Agent 安全的关键变化。
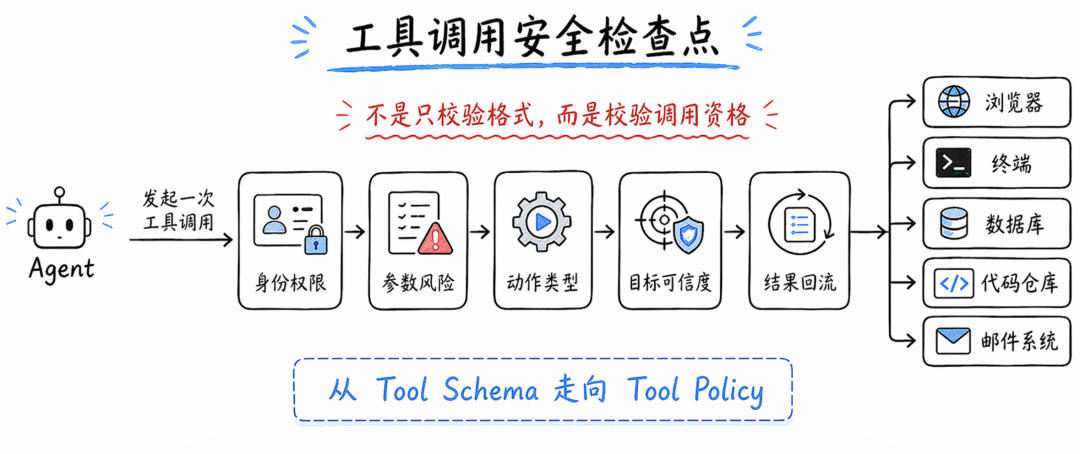
工具调用安全不能只校验格式,还要校验:
这个工具是否允许当前用户调用?
这个参数是否包含敏感信息?
这个动作是否会改变外部状态?
这个目标地址是否可信?
这个命令是否破坏性?
这个调用结果是否会被带入下一轮上下文?
这就是从 tool schema 走向 tool policy。
长任务状态管理能力增强,也会放大持续性风险
DeepSeek-V4 技术报告里有一个很值得关注的设计:Interleaved Thinking。
报告提到,在工具调用场景中,DeepSeek-V4 会保留完整 reasoning history,包括跨用户消息边界的历史推理内容,从而让模型在长周期 Agent 任务中保持连续、累积的问题求解状态。一般对话场景则保留原策略,新用户消息到来后丢弃之前的推理内容,以保持上下文简洁。
这是一种很典型的 Agent 状态管理优化。
它的好处很明显:模型不用每次工具调用后重新理解任务,长期任务更连贯,复杂调试、搜索、代码修改、数据分析更容易推进。
但安全上也要注意:长状态会保留更多历史污染。
如果早期上下文里混入了恶意指令,后续任务可能持续受影响。
如果模型误解了用户目标,错误计划可能在多轮工具调用中被不断强化。
如果敏感信息进入推理状态,它可能在后续步骤中被间接带出。
所以,Agent 状态管理本身也要纳入安全设计。
未来不能只清洗用户输入,还要清洗 Agent 的任务记忆、工具结果、推理摘要和中间状态。
DSec 沙箱
DeepSeek-V4 技术报告里,最值得 AI 安全从业者关注的一节,是 Sandbox Infrastructure for Agentic AI。
报告说,为了满足 Agentic AI 在后训练和评估中的多样化执行需求,DeepSeek 构建了生产级沙箱平台 DeepSeek Elastic Compute,也就是 DSec。DSec 由三个 Rust 组件组成:API gateway、per-host agent 和 cluster monitor,通过自定义 RPC 协议互联,并运行在 3FS 分布式文件系统之上;生产环境中,单个 DSec 集群可以管理数十万个并发沙箱实例。
DSec 提供四类执行底座:
Function Call,用于轻量无状态函数调用。
Container,兼容 Docker。
microVM,基于 Firecracker,提供 VM 级隔离,适合安全敏感场景。
fullVM,基于 QEMU,支持任意 guest OS。
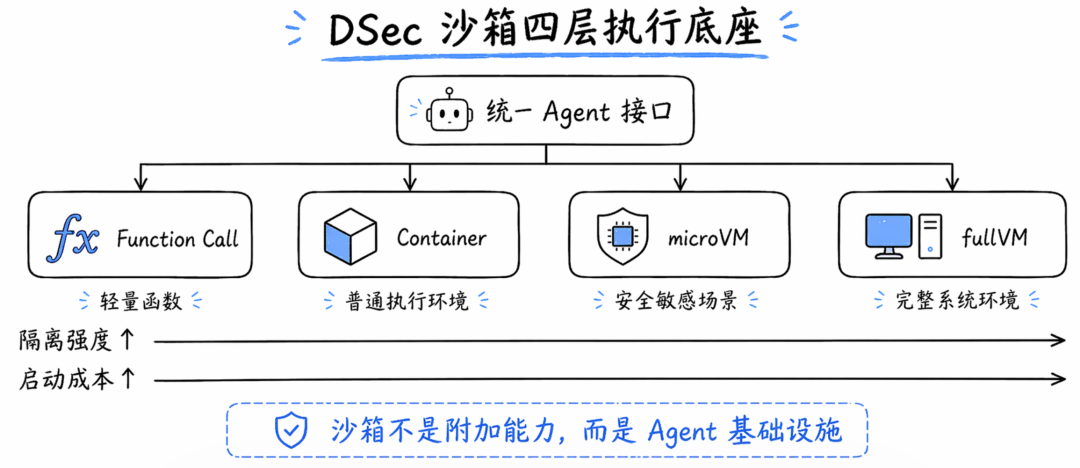
这部分非常重要。
它说明 DeepSeek 在训练和评估 Agent 时,已经不是让模型“纸上谈兵”,而是让模型进入真实可执行环境。
而一旦模型进入可执行环境,沙箱就不是附加能力,而是基础设施。
没有沙箱,Agent 就像一个拿到系统权限的实习生。
它可能能力很强,也可能误删、误改、误执行、误访问。
沙箱的价值是把 Agent 的行动范围限制在可控环境里:
文件系统隔离
网络隔离
进程隔离
资源限制
环境快照
任务重放
失败恢复
权限分层
企业部署 Agent,也应该按这个思路做。
不要直接让 Agent 连生产环境
不要直接让 Agent 拿真实凭证
不要直接让 Agent 操作高权限系统
先放到沙箱里,让它生成计划、执行测试、输出 diff、给出证据,再决定是否进入真实环境。
轨迹日志
DSec 还有一个设计非常值得单独拎出来讲:trajectory log。
报告提到,DSec 会为每个沙箱维护全局有序的轨迹日志,持久记录每一次命令调用及其结果。这个轨迹日志有三个作用:任务恢复、细粒度溯源、确定性重放。
这几乎就是 Agent 安全审计的标准答案。
未来 Agent 产品一定要能回答几个问题:
它执行过哪些命令?
它读过哪些文件?
它写过哪些文件?
它调用过哪些接口?
它访问过哪些网页?
它基于哪些工具结果做出下一步判断?
它什么时候偏离了用户目标?
它的错误能不能复现?
出了问题能不能回滚?
没有轨迹日志,Agent 安全事故很难定位。
有轨迹日志,才能判断问题来自哪里:
是模型误解?
是上下文污染?
是工具返回错误?
是权限配置过宽?
是用户指令模糊?
是外部文档提示注入?
这也是为什么 Agent 安全不能只做输入输出检测。输入输出只是任务链首尾,真正的问题可能发生在中间几十次工具调用里。
DeepSeek-V4 的 Agent 评测,已经接近真实研发任务
DeepSeek-V4 技术报告中的 Agent benchmark 很丰富,包括 Terminal Bench 2.0、SWE Verified、SWE Pro、SWE Multilingual、BrowseComp、HLE with tools、MCPAtlas Public、Toolathlon 等。
DeepSeek-V4-Pro-Max 在 Terminal Bench 2.0 上达到 67.9%,SWE Verified 达到 80.6%,SWE Pro 达到 55.4%,MCPAtlas Public 达到 73.6%,Toolathlon 达到 51.8%。
更值得关注的是内部 R&D Coding Benchmark。
报告说,DeepSeek 从 50 多名内部工程师那里收集了约 200 个真实研发任务,覆盖功能开发、bug 修复、重构、诊断,技术栈包括 PyTorch、CUDA、Rust、C++。
经过筛选后,保留 30 个任务作为评测集。DeepSeek-V4-Pro-Max 在该 benchmark 上通过率为 67%,高于 Claude Sonnet 4.5 的 47%,接近 Opus 4.5 的 70%。
这说明 DeepSeek-V4 的 Agent 能力已经进入真实研发任务维度。
但真实研发任务带来的安全问题也更具体:
模型会读代码
模型会改代码
模型会跑测试
模型会解释日志
模型会修改配置
模型会处理依赖
模型会访问构建环境
模型可能接触密钥、token、内部接口和测试数据
所以,企业如果用 DeepSeek-V4 做 Coding Agent,不能只看模型通过率,还要建立研发安全基线:
默认只读。
修改必须生成 diff。
敏感文件不可读。
密钥文件不可访问。
外网访问受控。
命令执行分级。
提交前人工确认。
安全测试自动触发。
所有操作留痕。
这才是 Coding Agent 真正可落地的安全形态。
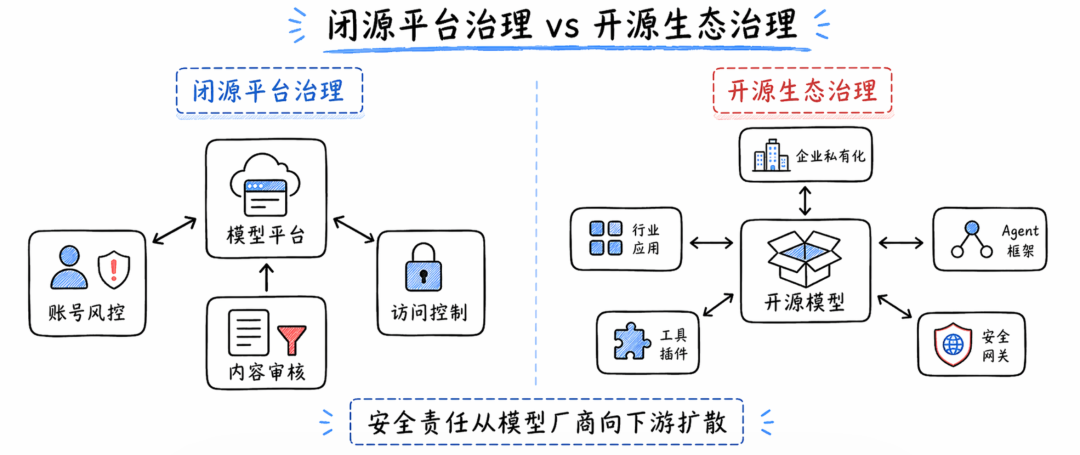
开源和低成本会让安全责任向下游扩散
DeepSeek-V4 的开源属性很关键。
闭源模型的安全治理,主要由模型平台承担一大部分责任:账号、风控、限流、内容策略、日志审计、能力开放分级。
开源模型不一样。
一旦模型权重开放,本地部署、私有化部署、行业部署、二次微调都会快速出现。
这会带来好处:
企业可以本地化使用、数据可以不出域、开发者可以深度适配、行业场景可以低成本落地。
但也会带来新的治理难题:
模型方无法控制所有下游用法、不同部署方的安全水平差异很大、同一个模型接入不同工具后风险完全不同、私有化部署容易被误解成天然安全。
但“数据不出域”只解决了数据流向的一部分问题。
模型在域内误操作、越权读取、错误调用工具、泄露内部信息,同样是安全事故。
所以,开源模型时代的 AI 安全,会更多依赖下游应用方、集成商、行业客户和安全产品。
护栏要变成上下文与执行网关
DeepSeek-V4 带来的安全启发,可以概括成一句话:
长上下文模型会让风险从 query 迁移到 context;Agent 能力会让风险从 response 迁移到 action。
所以,护栏产品也要升级。
传统护栏像文本审核器。
未来护栏更应该像上下文与执行网关。
它至少要覆盖六件事。
第一,长上下文切片检测。
把百万上下文拆成文档、段落、代码块、表格、网页、邮件链,分别识别风险。
第二,来源可信度标注。
用户输入、系统指令、外部网页、邮件、知识库、代码注释,可信级别不同,不能混在一起处理。
第三,指令和数据隔离。
外部文档里的内容默认是数据,不应该被模型当成高优先级指令。
第四,工具调用前检查。
每次调用终端、浏览器、数据库、代码仓库、邮件系统前,先判断动作风险。
第五,沙箱执行和回放。
高风险任务先在隔离环境中执行,保存轨迹,允许复现和回滚。
第六,部署后持续评测。
开源模型上线后,要持续用真实业务样本、提示注入样本、工具误用样本做评测。
这套能力,已经超出传统内容安全 API 的范围。
它更接近 Agent Security Gateway。
写在最后
DeepSeek-V4 的发布,不只是国产模型能力更新。
它真正值得关注的地方,是把几个趋势叠在了一起:
百万上下文
低成本推理
开源权重
Agent 能力强化
工具调用优化
沙箱基础设施
轨迹日志和确定性回放
这些能力组合起来,会让更多团队低成本搭建本地 Agent。
这对产业是好事,但安全问题也会从模型厂商平台,扩散到每一个部署者、集成者、应用开发者和行业客户。
GPT-5.5 展示的是前沿闭源模型如何做分层安全治理。
DeepSeek-V4 展示的是开源长上下文模型如何把 Agent 能力推向更广泛的工程落地。
两件事合在一起看,AI 安全的方向已经很清楚:
未来要保护的,不只是模型输出。
还包括上下文、缓存、工具、权限、沙箱、轨迹、状态和整个任务执行过程。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
