对大模型提示注入的防御,今天已经发展出了很多不同路线。除了常见的对模型输入进行分类检测之外,还有一类很有代表性的做法叫安全改写:不是直接拦截原始请求,而是先把它“整理”一遍,再交给模型处理。
无论是提示净化、输入重写,还是把危险表达改写成相对安全的等价形式,这类方法本质上都是在模型前面加了一道输入处理层。为了表述方便,我们可以暂且把它叫作 wrapper defense。

https://arxiv.org/pdf/2604.06436
不过要先说明一点:这篇论文主要讨论的,是安全改写型的前置防护层;如果是“先分类,再直接拒绝、转人工、切换链路”的那类防御,论文的主定理并不直接覆盖。
我们今天介绍的这篇工作,想回答一个很核心的问题:
如果这道输入处理层本身是连续的、平滑的,同时你又希望正常请求尽量不受影响,那么它能不能把所有提示注入风险都彻底消灭?
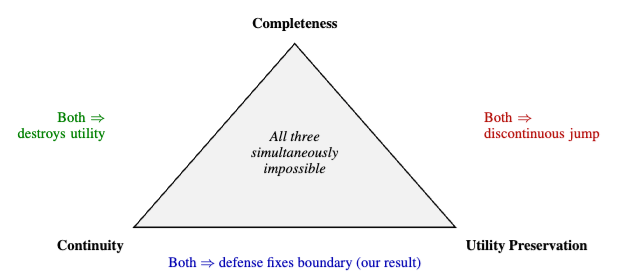
作者给出的答案是否定的。论文从理论上证明,对于这类 wrapper defense 来说,连续性、实用性和完备性三者无法同时成立,这正是标题里所谓的“不可能三角”。
论文是怎么把这个问题数学化的
论文把 wrapper defense 写成了一个很简洁的数学对象:
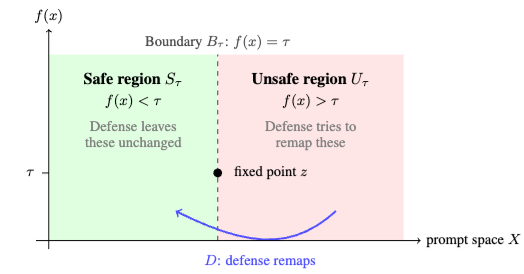
在模型真正看到输入之前,系统先做一次预处理,把原始输入x改写成另一个输入D(x)。
与此同时,论文还定义了一个“风险偏离分数” f(x),你可以把它理解成:一个 prompt 离“安全、对齐”有多远。
再设定一个阈值 τ:
当 f(x)<τ 时,输入处于安全区;
当 f(x)>τ 时,输入处于不安全区;
当 f(x)=τ 时,它就落在安全边界上。
接下来,作者要求这道防御同时满足两个目标。
第一,正常输入尽量不要被乱改。这就是论文里的 utility-preserving,也就是安全 prompt 应当尽量原样通过。
第二,所有危险输入都应该被处理成安全输入。这就是 complete,也就是“彻底防住”。
于是问题就来了:一套前置安全改写机制,能不能既足够平滑自然、不明显破坏正常体验,又把所有危险输入都彻底处理掉?论文的回答是:不能。
把“防不住”拆成了三层
很多论文会告诉你“提示注入很难防”,但这篇论文更进一步:它不仅说难防,还把“为什么防不住”拆成了三层,而且一层比一层更强。
第一层:边界上一定会有漏点
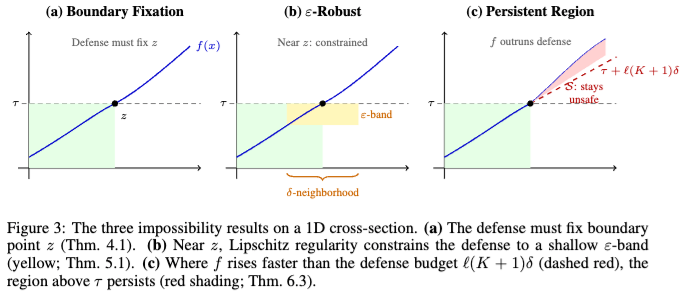
论文的第一个核心结论叫 Boundary Fixation。它证明:只要提示空间是连通的,这道防护层又是连续的,并且你承诺“安全输入尽量不动”,那么一定会存在某个边界点 z,满足 f(z)=τ 且 D(z)=z。说得更直白一点,就是总会有某些刚好卡在安全边界上的输入,原样穿过你的防护层。
这件事为什么重要?因为现实里的很多提示注入,本来就不是赤裸裸的恶意请求,而是伪装成一种“看起来还算正常,但已经开始越界”的临界状态。论文证明,这种临界输入不是偶然漏网,而是这类连续、安全改写式防御天然会留下来的。
第二层:不是只漏一个点,而是边界附近整片都很脆弱
接下来,论文再加一个更现实的约束:不仅防护层本身是平滑的,风险分数的变化也不要太剧烈。数学上,它把这件事写成 Lipschitz 约束;你可以把它简单理解成“输入变一点,风险和改写动作都不会突然大跳”。在这个条件下,论文得到第二层结论:边界附近会形成一条脆弱带。 换句话说,防护层在边界周围最多只能把风险往下拉一点,不可能一下子把所有临界输入都拉回到很深的安全区。
这一步很接近工程现实。因为很多团队会有一种错觉:高危样本处理得差不多了,剩下只是一些零散边缘 case。但这篇论文告诉你,边界附近的风险未必是离散的,它可能本来就是一整片连续存在的浅层脆弱区。
第三层:在更强条件下,会留下持续不安全区域
论文最强的一步,是再往前走了一层。如果风险面的上升速度,比防护层“把输入拉回安全区”的能力更快,那么就会出现 Persistent Unsafe Region,也就是“持续不安全区域”。这意味着:问题不只是边界附近有些难处理的点,而是会留下一整块区域,无论你怎么做这种前置安全改写,它改完之后仍然是不安全的。
这一点非常有力量。它把很多安全工程中的直觉,上升成了一个更结构化的判断:有些风险不是因为你规则写得不够细,也不是因为你还没见过某个样本,而是因为这类前置改写机制本身能施加的“修复力度”有限,而风险上升可能比它更快。 到了这种情况下,失败就不是偶然,而是结构性的。
很常见的安全幻想
如果把这篇论文放回现实系统里看,它打击的不是“所有提示注入防御”,而是下面这种很常见的期待:
在模型前面加一层足够聪明的安全改写;既不太影响正常用户体验;又希望把所有危险输入都洗干净。
论文说,这种期待本身就过于理想化。只要你的路线还是“模型前先来一道连续、温和、尽量不伤体验的输入处理”,那它就不可能成为一个真正意义上的最终兜底方案。
这里再强调一次边界:如果你的系统是“高风险就直接拒绝、转人工、切安全模型、切别的流程”,那它并不属于论文严格证明的对象。
论文在 scope and limitations 里明确说了,它的结论只覆盖单一的、连续的、保效用的输入预处理 wrapper;像硬 blocklist、离散分类器、输出过滤、人审、多组件拒绝或重定向系统,都不在主定理的直接覆盖范围内。
所以,更准确的说法不是“提示注入没法防”,而是:只靠安全改写型 wrapper,没法同时把连续性、实用性和完备性都拿到。
离散 token、多轮对话和 pipeline
很多人看到这里会问:现实里的 prompt 明明是离散 token 序列,不是连续空间,这个证明会不会太理想化?
论文给了两个回应。
第一,它说明离散观测也可以做连续扩展,因此前面的不可能性并不是纯数学游戏。
第二,它还给出一个更直接的离散版结论:在有限集合上,如果你真的想做到 complete,也就是“把所有输入都处理成安全输出”,那就必须牺牲 injectivity,也就是必须发生某种程度的信息塌缩。反过来说,如果你坚持“每个输入都尽量原汁原味保留,不丢信息”,那它就不可能是完备的。
这个结论很有工程味。它其实是在说:真正想把风险压下去,就不要再执着于“既完整保留原 prompt 的表达细节,又把所有危险都消掉”。 很多时候,安全本来就意味着要缩窄表达空间、缩窄接口、缩窄动作自由度。
论文还把结论扩展到了多轮交互、随机化防御和 pipeline。尤其是 pipeline 部分,它指出如果每一层组件都是 Lipschitz 的,那么串起来以后整体常数会相乘;当链路越来越深时,前面那道防护层的有效性会进一步打折。对今天的 Agent 系统来说,这个提醒非常现实:链路越长,越不能把全部安全压力都压给最前面那一层安全改写。
实验部分,验证的是一种“行为地形”
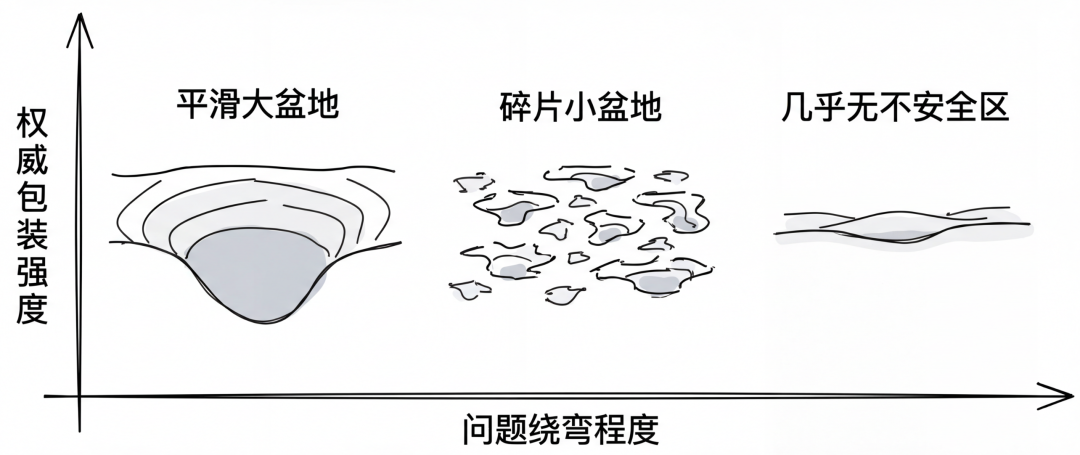
这篇论文的实验不是那种“我们提出一个新防御,在 benchmark 上提升了多少分”的传统套路。它更像是在验证:前面的理论判断,和真实模型的行为结构能不能对得上。论文借用了作者此前的 Manifold of Failure 框架,把模型放到一个二维行为空间里看,两条轴分别是:问题表达得有多绕,以及提示里带了多强的权威或许可包装。
在这个二维空间里,论文总结了多条和理论一致的现象。比如:平滑地形更容易形成大块风险盆地,粗糙地形更像碎片化马赛克;某些模型上,持续不安全区域会在防御下继续存在;多层 pipeline 会让失败带进一步放大。具体到三个模型,论文给出的观察是:Llama-3-8B 的平均偏离分数更高、盆地更大;GPT-OSS-20B 的地形更碎;而 GPT-5-Mini 在论文选取的阈值下几乎没有进入不安全区,因此这三条不可能性在那个设定下不会被触发。
这组实验最重要的意义,不在于给模型排一个简单高下,而在于它说明:论文里的三层不可能性,不只是抽象定理,而是和真实模型的行为地形有可观察的一致性。
重新校准目标
论文最后给出的工程建议,我觉得非常值得注意。
第一,不要幻想消灭边界,而要让边界变浅。 如果边界附近的行为只是礼貌拒答,而不是危险执行,那么即便数学上仍然存在边界固定点,工程上也未必致命。论文就拿 GPT-5-Mini 举例,说明边界存在并不等于一定有实际危害。
第二,尽量让风险面更平,不要太陡。 表面越陡,说明输入稍微一变,风险就快速上升,此时前置防护更难把它拉回来;如果曲面更平,虽然风险可能分布更广,但至少更容易监测和管理。
第三,降低有效维度。 别给输入接口太大的自由空间,别让参数范围太宽,别让上下文无限膨胀。论文明确提到,标准化输入格式、限制 API 参数、控制上下文长度,都有助于把防御问题压缩到一个更可管的范围里。
第四,把重点从“彻底消灭风险”转向“持续监测边界”。 因为边界会反复出现,多轮交互会反复逼近,微调也未必能真正把这些跨越抹平。与其追求一个理论上不存在的完美安全改写层,不如围绕边界建立运行时监控、权限隔离和异常中断机制。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
