在数据驱动成为各行业决策基石的今天,如何在发挥数据分析威力的同时保护个人隐私已成为关键挑战。隐私增强技术(PETs)可以在使数据得到更多使用的同时,帮助减轻隐私风险。差分隐私作为PETs的一种,可以通过向数据中添加噪音略微改变个人信息,从而允许在公开发布数据的同时保护个人的隐私。
美国国家标准与技术研究院(NIST)近日发布了800-226《差分隐私保证评估指南》(Guidelines for Evaluating Differential Privacy Guarantees,以下简称“指南”),以评估差分隐私保护个人信息的有效性,旨在帮助各种机构和从业者(政策制定者、企业主、产品经理、IT 技术人员、软件工程师、数据科学家、研究人员和学者)更好地了解在部署差分隐私时做出和未做出的承诺。
指南解释,差分隐私的优势是可以抵抗所有隐私攻击(包括使用外部(辅助)数据的攻击),并且可以随着时间的推移处理多个数据发布,而不会加剧隐私风险。然而,虽然差分隐私的框架在数学上是合理的,但在应用中,支撑它的软件生态系统仍然不成熟,因此,差分隐私在理论上的效果和实践上的效果可能有差异。
对此,该指南提出了“差分隐私金字塔”以评估差分隐私的隐私保证效果。该金字塔涵盖影响差分隐私的隐私保护效果的关键因素,包括“隐私参数”、“隐私单位”、“算法设计”、“效用”、“偏见”、“信任模型”、“安全性”和“数据收集实践”。
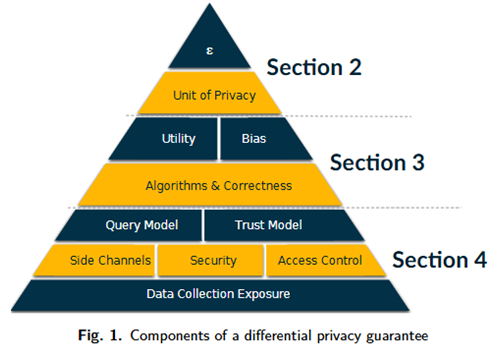
1.隐私参数:隐私-效用权衡
实现差分隐私最常见的方法是通过添加随机噪声。在金字塔的顶部是隐私参数ε,它控制隐私保证的强度。较小的ε意味着更多的噪音、更强的隐私,但结果不太准确;较大的ε可以减少噪音,提高准确性,但会削弱隐私性,这种动态被称为隐私-效用权衡。
该指南指出,较大的ε值(例如,大于 10)可能无法提供有意义的保护,尤其是对于异常值,设置这些参数仍然是一个悬而未决的问题。对此,指南认为随着时间的推移,特定领域和任务的最佳实践可能会出现,并提出希望能够建立足够的用例,以此作为基准,构建一个在特定的环境中建立隐私参数的指南。

2. 隐私单位:定义受保护的内容
隐私单位(Unit of Privacy)指定了保护的内容:通常是个人的全部数据(用户级隐私)或仅单个事件(事件级隐私)。用户级隐私提供了更强的保护,而事件级别的隐私可能很弱,无法保护具有多个数据点的个人。该指南建议将用户级隐私作为最安全的默认设置,并在需要时使用边界贡献等技术来加强保证级别。
3. 算法与工程实现
差分隐私的实现通常依托Laplace Mechanism和Gaussian Mechanism等核心算法,通过在查询输出端注入受控噪声达成隐私保护。
在工程实现层面,指南特别强调需关注三个风险点,一是浮点运算误差导致的隐私预算(privacy budget)泄露,二是时序攻击(timing attack)引发的元数据暴露,三是后端存储漏洞造成的原始数据逆向工程。对此,指南建议优先采用成熟的、经过了充分测试的算法库。
4. 效用权衡与偏差管控
效用(Utility)是指数据集或统计数据对特定目的的有用性,取决于统计数据的适用方式;准确性(Accuracy)是指输出值与试图估计的真实值之间的差异,仅仅是对统计数据误差的测量。
在隐私-效用平衡法则中,噪声强度(ε值)与数据精度呈现指数级负相关关系:更多的噪音增强了隐私,但降低了数据的有用性。指南提出,包括差分隐私在内的数据处理算法可能会引入或放大各类偏差,这些偏差可能产生负面影响,影响对从结果中得出的结论的有效性。
在NIST此前发布的《人工智能中识别和管理偏差的标准》(NIST Special Publication 1270, Towards a Standard for Identifying and Managing Bias in Artificial Intelligence)中定义系统性偏差、人为偏差和统计偏差三种偏差。例如,在实践应用时,差分隐私算法引入的噪声对较小群体的影响大于对较大群体的影响,因而可能会放大对小型群体的影响,此为系统性偏差的一种。指南建议,从业者必须评估这些影响,以确保公平可靠的结果。
5. 部署时的注意事项
信任模型描述了对系统组件可信度的预期假设。这里的信任假设是指当该方被授予访问敏感数据时,其预期行为的方式:可信方将确保敏感数据安全,不会将其泄露给他人,假设与可信方共享敏感数据不会导致隐私损害;一个不可信的实体可能无法保证敏感数据的安全,并可能将其泄露给他人。大多数差分隐私的信任模型都是根据对数据主体(数据所涉及的个人)、数据管理员(聚合数据的人)、数据消费者(接受差分隐私结果的人)这三方的信任假设进行描述的。
最常用的差分隐私的信任模型是“差分隐私中心模型”,中心模型的关键组件是一个可信的数据管理员。每个个体将他们的敏感数据提交给数据管理员,管理员将所有数据存储在中央位置(即在单个服务器上)。在中心模型中,通常会在结果中添加噪声,这个模型的优势是可以让算法尽可能小的添加噪声量,从而尽可能确保产生结果的精度。另一种差分隐私的信任模型是本地模型,由每个个体将数据发送给数据管理员之前,对自己的数据添加噪声。这意味着数据管理员永远不会看到敏感数据,也不需要被信任。这个模型的缺点是产生的结果没有中心模型准确。

在评估差分隐私的隐私保证时,最关键的因素是信任模型中的信任假设是否与现实情况相符。例如,在差分隐私的中心化模型中,必须假设数据管理者可信。若将中心化模型应用于不可信的数据管理者场景,差分隐私的保障机制将失效,因为管理者可能直接将敏感数据泄露给第三方。现实世界的信任关系具有复杂性,将现实中关于参与方可信度的认知转化为信任模型中的精确假设往往困难重重。因此,信任模型的选择直接受制于对相关参与方可信度的现实考量。
此外,数据安全访问控制机制等的有效性也会影响差分隐私部署后的效果。
小结
这份出版物能够帮助组织评估差分隐私产品,并更好地了解其创建者的声明是否准确。指南在最后提出,由于将差分隐私的保证级别传达给非专业人士很具有挑战性,未来应进一步推进差分隐私的标准化,并基于标准构建评估差分隐私保证级别及其提供系统的工具,通过认证向非专业人士传达差分隐私的保证级别。
参考资料:https://csrc.nist.gov/News/2025/guidelines-for-evaluating-differential-privacy-gua
声明:本文来自数据信任与治理,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
