
原文标题:Traffic Classification through Simple Statistical Fingerprinting
原文作者:Manuel Crotti, Maurizio Dusi, Francesco Gringoli, Luca Salgarelli原文链接:https://doi.org/10.1145/1198255.1198257发表期刊:ACM CCR笔记作者:宋坤书@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、研究背景
流量分类机制是TCP/IP网络中资源分配、控制和管理的工具,同时它还能提高网络入侵检测系统(NIDS)的可靠性。最简单的流量分类方法是基于端口号的流量识别,但标准服务可能在非标准端口上运行,甚至部分应用(如P2P)完全不依赖固定端口,因此,该方法存在局限性。此外,Bro和Snort等NIDS工具通过对每个数据包有效载荷进行分析实现流量分类,但计算开销较大,难以适应高速网络。
本文采用基于统计特征的方法,仅依赖IP数据包的大小、到达时间间隔以及它们的到达顺序来识别应用层协议。本文提出了协议指纹(protocol fingerprint)的概念,紧凑而有效地表示了流量特征。同时还定义了异常评分(anomaly score),以衡量未知流量与已知协议的差异。最后,还提出基于协议指纹的分类算法,能够实时分类流量,并识别未知协议。
该算法的关键特性在于使用归一化阈值进行分类,并对概率密度函数(PDF)应用平滑滤波,以降低噪声影响,同时利用数据包到达顺序作为协议指纹的组成部分。计算复杂度较低,仅需查表并执行简单的代数运算。实验结果表明,该方法在识别已知协议方面表现良好,且对未指纹化流量的低误判率表明其在新协议出现时仍具一定鲁棒性。
2、协议指纹
2.1 概率密度函数
本文主要是对通过TCP连接交换数据的网络应用(如HTTP、SMTP、SSH等)产生的IP流的分类。文中定义流F为客户端(client)和服务器(server)之间传输的单向有序IP数据包序列。在IP层,每个流F可以通过N对 来表示,其中 代表数据包大小, 代表数据包之间的到达间隔时间,i则代表数据包的顺序。通过对这些流的统计信息进行分析,可以生成一个协议指纹,该指纹代表了特定协议的流的统计特性。
每个协议的概率密度函数(Probability Density Functions,PDFs)都是是通过分析训练集(由相同协议生成的一组数据流量)来构建的,每个PDF描述协议中不同位置i处数据包的大小和到达时间的的统计特性。这些PDFs形成协议的概率密度函数向量(Probability Density Function vector)。由于网络环境的噪声,直接使用PDF可能会导致分类误差,因此对其进行高斯滤波生成协议掩码(protocol mask)向量 ,用于增强鲁棒性。协议掩码向量的生成过程如下:
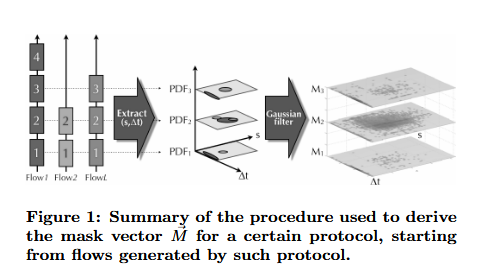
2.2 异常评分
2.2.1 协议指纹
为了根据PDFs对未知数据流F进行分类,需要计算F与每个协议的PDF的匹配度。这通过计算异常评分(anomaly score)来实现,该评分衡量F与某个协议p的协议掩码 之间的匹配程度。具体地,评分基于流中每个数据包的大小和到达时间与PDF的匹配程度。
异常评分 是通过流中每个数据包的评分 进行平均来计算的,公式如下:
其中, 是对每个数据包的评分, 和 分别为评分的最小和最大值, 则是用来衡量流F中第i个数据包与协议p匹配程度的。S的值表示该流与协议p的相似程度,用于决定该流是否符合特定协议。
协议指纹的阈值 通过计算构建指纹时使用的流的异常评分S的均值和标准差来定义。如果一个流的异常评分超过了阈值 ,则被视为不符合该协议。
协议指纹 由协议掩码向量 和阈值向量 组成:
该指纹可用于流量分类,但仅适用于训练时所在的网络环境,在不同的网络环境下需要重新生成指纹。
3、分类算法
本文基于协议指纹和异常评分提出分类算法,目标是可以根据流量的异常评分来判断流量属于哪个协议。具体流程如下:
计算异常评分:对于每个已知的协议指纹( ,1 ≤ j ≤ K)和一个未知数据流F,首先计算F与每个协议指纹的异常评分 ,这个评分表示流量F与协议指纹的协议掩码的距离。
归一化异常评分:将流量的异常评分与每个协议的阈值进行归一化计算,即 。这个步骤的目的是根据流量的异常评分与协议阈值的关系来判断流量属于哪个协议。
分类决策:选择归一化后异常评分最小的协议,如果某一协议的归一化异常评分小于其他协议的评分,则认为流量属于该协议。如果没有一个协议的评分满足条件,则认为该流量为“未知”协议。如下图中,即使流F对HTTP的异常评分高于其对POP3的异常评分,但相对而言,前者比后者远离相应的阈值,因此应该将F分类为使用POP3协议。
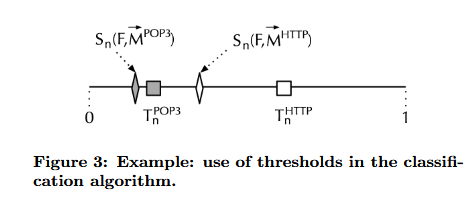
该分类算法可以应用于真实网络中,通过收集流量数据、预分类、构建协议指纹、启动分类引擎以及定期更新指纹来实现流量分类。算法适用于动态分类流量,随着流量观察数量的增加,分类准确性逐渐提高,且计算量较低,适合管理重要协议或服务。构建准确的协议指纹至关重要,预分类时应减少噪声,并避免将复杂协议中的异常流量纳入训练集。
4、实验设置
研究人员通过在校园网络边缘网关收集流量数据,网络包含约1000台工作站,使用不同操作系统。研究者分析流量分布发现HTTP、POP3、SMTP协议占据超过60%的带宽。因此,他们首先构建了一个训练集,通过Tcpdump捕获匹配HTTP、POP3和SMTP标准端口的流量,收集了40GB以上的流量数据,用于协议指纹的构建。然后,研究者又收集了一周随机选取并均匀分布的流量作为评估集,评估集包含上述三种流量集和OTHER集。通过预分类流量和手动检查数据包负载,使用模式匹配分类器构建了HTTP、POP3和SMTP协议的协议指纹。
4.1 实验性能评估
分类器的性能评估采用了命中率 和误报率 。 是指协议p的评估流量中,被正确分类的比例; 是指表示被分类为协议p的流量中,实际不属于该协议的比例。实验结果表明,分类器对HTTP、POP3和SMTP的命中率均超过90%,误报率最高约为6%。研究者通过调整分类器配置参数(如窗口大小、阈值和数据包编号)来优化分类器性能,并发现不同协议的最佳配置参数有所不同。
5、总结
本文提出了一种基于网络流量分析的统计分类技术。引入了“协议指纹”概念,即在训练阶段使用的量度,能够以紧凑高效的方式表达用于表征每个协议的主要统计特性:到达时间间隔、IP数据包大小以及它们在分类器中的出现顺序。实验分析显示,经过训练的分类器能够以较高的命中率和较低的误报率判断网络流量所对应的应用协议,至少对于有限的协议集是有效的。
进一步研究表明,用于生成协议指纹的高斯滤波操作对于分类器处理抖动和意外包大小变化等噪声具有重要作用。此外,分类算法中使用的归一化阈值能有效区分没有生成指纹协议的流量,这说明文中提出的分类说法具有普适性。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
