一、背景
作为一家行业领先的第三方支付,甜橙金融通过不断的拓展商户来丰富自身的支付场景,吸引更多的C端用户。在不断提升商户和用户规模的同时,也会存在很多认证照片不完整、不合规范甚至是虚假资料的情况存在,这些现实状况不仅影响企业提升自身商户和账户质态,而且也给面向监管机构要求的KYC工作带来了更大的挑战。
面对每天数万的商户准入和用户认证规模,以及越来越逼真的虚假证照,单纯的靠人工去一个个审核,不仅工作量巨大,人工成本高,而且审核效率低,只能审核个案,不能从全局分析。
我们目前的工作主要是利用图像处理与深度学习的算法,实现对恶意虚假证照、不合业务规范的证照进行识别。通过建立支付行业面向商户和用户证件的AI证件鉴伪模型,来帮助自动识别恶意虚假的和不符业务规范的B端和C端认证,提升风险识别的覆盖面,降低人工运营审核的工作量,融风控智慧促进甜橙金融业务高质量发展。
二、研究框架

图1 AI证件鉴伪研究框架图
图1是我们结合业务问题和工作流形成的研究框架图,主要分成以下4个部分:
1)图像分类:在认证环节,会存在各种各样不是证件的图片,所以第一步我们是去通过建模自动识别这是一张身份证还是一张营业执照亦或是其他噪声图片,这是一个图像分类问题;2)恶意虚假检测:根据不同类型的证件,我们会通过模型自动判断是否存在恶意虚假的情况(如模板合成照,PS照等),这种风险从金融风控的角度来讲是0容忍的;3)证照不规范检测:根据业务对证照规范的要求(如复印件盖红章,照片完整等)进行建模检测,识别不满足业务规范的证照,这类证照不一定是虚假的,但不符合具体的业务规范,尤其在监管对KYC和KYB的资料质量越来越高要求的趋势下,显得愈加重要;4)证照内容提取:针对图像内容进行提取,进行格式化存储。三、图像分类
问题:
用户和商户在本该上传资质照片的地方上传了一些景色照、自拍照等非资质证照,如图2所示在红色标注的地方本应上传营业执照但却出现了其他无关图片。

图2 未按要求上传
方法:
常规的方法在数据量充足的情况下可以直接利用深度学习中的CNN变种网络如VGG,Googlenet,Resnet等相关卷积神经网络去做相应的试验,按照常规的建模流程,取其中表达效果好的模型。但是考虑到目前数据量并不充足,以营业执照识别为例,上传的非营业执照数量还并没有达到深度学习可以训练的程度,所以我们从ImageNet下载了数千个种类的数万张图像对现有的数据集进行补充,并对数据集进行欠采样。同时根据对实际业务数据的分析,有针对性的加入了一定数量的某种特定类型的图像,以增强模型在训练的过程中对该类型的感知度。我们利用VGG16作用预训练模型,设置卷积层学习率=0进行冻结,然后fine turn分类层进行迁移学习训练,最终的模型分类准确率和召回率达到90%以上。
四、恶意虚假检测
证件照恶意虚假层主要关注的是用户实名认证和商户准入过程中上传的身份证或营业执照是否存在图像合成或者信息篡改的恶意虚假行为。
营业执照虚假合成检测

图3批量虚假营业执照
如图3所示,是我们在实际业务中遇到的批量虚假营业执照,这些虚假营业执照的商户的出现,对甜橙金融平台高质态的商户发展是一个严峻的挑战。在和黑产不断对抗的过程中,甜橙金融黑产研究中心通过长期的积累,已经逐步形成了覆盖市面上主流的营业执照合成模板的黑产素材库,那么在业务流程中,每一个商户准入的申请,其实从算法层面是一个1:N的图像比对问题。首先利用块匹配法进行图像比对,块匹配法是从待配的图像中选取正方形大小的区域的像素情况作为匹配另一幅图像的块模板。块匹配法是一种高精度、高计算量的匹配方法,整个匹配主要集中在图像重叠区域中的一块,主要在在另一幅图像中搜索最相似的这个匹配块。通过块匹配法算法能找出在整体相似的图片,但是有可能图像在细节上并不是相似,所以会造成一定程度的误判。为了解决这一问题,我们会采用SIFT匹配算法弥补这一方法带来的漏洞。SIFT算法是一种基于尺度空间的算法,该算法特征是图像的局部特征,使其对旋转、尺度缩放、亮度变化具有保持不变性,对视角变化、方式变换、噪声也具有良好的稳定性,通过提取关键点,描述关键点,建立对应关系和消除错误匹配点四个步骤可以过滤那些被误判的图像。通过整体和局部两重的图像比对,我们可以快速精准的找出那些虚假合成的营业执照。另外我们还会通过批后的方式去进行风险兜底,检测出所有可疑的虚假营业执照,采用像素哈希方法进行分治,将n²的算法复杂度降低为nlog(n)。目前,通过这套方法我们对虚假营业执照识别的准确率达到99%以上。
身份证信息篡改识别

图4虚假身份证照片
图4展示了我们在个人认证的过程中,遇到的虚假实名的案例(部分敏感信息已做打码处理),这些虚假高级实名的账户是恶意套利群体的重要组成部分,不仅影响活跃账户质态,而且会造成营销成本的损失。通过构建深度学习模型,我们精准的识别了这类风险,从而更加前置化的去完善反套利工作。以下是一些经验和思考的分享:
第一步希望能否借用现已有的算法完成这项任务,而现今比较主流的方法就是借助深度学习的卷积神经网络(CNN)进行特征的提取,再接全连接层过渡后,最后放入softmax进行分类。然而我们遇到了较为现实的问题是缺乏足够的黑样本数据,直接利用CNN可能还没找到真正的PS照特征就已经开始收敛了,这样得出的模型欠缺泛化能力。第二个问题是篡改了信息的图像并不能简单放入CNN中进行特征的提取,因为CNN对隐写信息表达能力并不好,所以我们需要帮助CNN去感知到这些差异性。
那什么是差异、如何表达差异呢?篡改信息主要分三种情况,第一种是从外部环境复制过来对原有图像的对象进行覆盖;第二种是在图像进行复制一块图像覆盖到图像另一个位置;第三种就是直接对原始图像进行写入信息。而这三种情况对于原始图像来说它都应该是噪声数据,使得图像中的像素达不到持续平滑的效果。
我们通过对图像的两个方面进行构建网络,一个是噪声层面,另一个是RGB层面,最后将这两个层面的放入一个双层的CNN网络结构中进行并行的提取特征,在输出层进行融合,最后进行分类。通过构建的虚假身份证模型,我们的准确率能达到95%,召回率在90%。
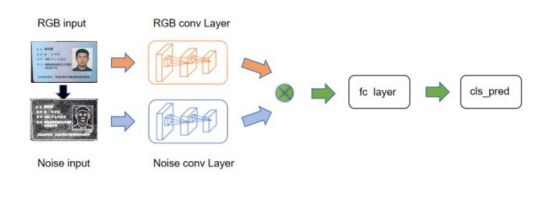
图5 PS篡改网络流程图
五、证件照不规范
基于深度学习的屏幕照检测模型ScreenNet
问题:
如图6所示,在账户实名认证的过程中,存在部分身份证图像是通过翻拍手机屏幕、电脑屏幕的屏幕照,这种非常规方法获取身份证图像信息的方式我们认为不合业务规范且存在一定的风险性。

图6 屏幕照
方法:
常规的图像分类一般会直接利用卷积神经网络去做特征的提取和分类,但是我们遇到的还是黑样本量少的问题,如果强行直接上卷积神经网络的话,可能没法让网络充分学习到屏幕照的相关特征,所以我们需要帮助卷积神经网络克服这个困难。那我们猜想如果让卷积神经网络能立马学到粗略的屏幕照相关特征(比如摩尔纹),那么再根据这些特征进行卷积神经网络里进一步精细化的特征提取,最终实现分类。通过大量的试验,最后设计出了ScreenNet模型。其网络结构如下图7所示:
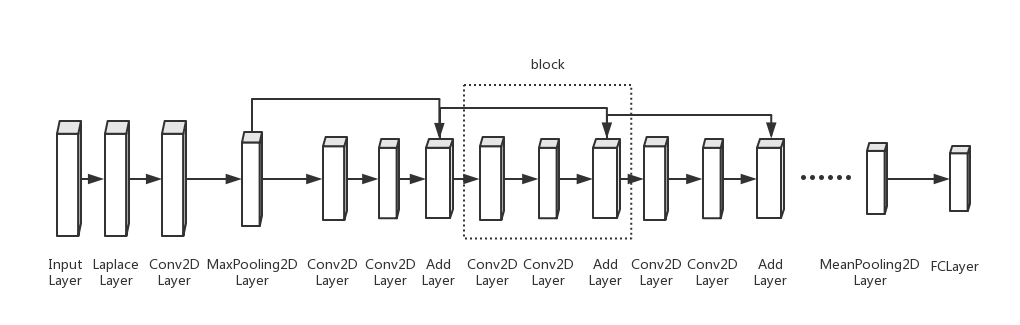
图7 ScreenNet网络结构
这个网络包含两个模块,一个模块是LaplacianLayer,另一个是block。Laplacian算子是作为LaplacianLayer卷积核,而block是借鉴了resnet结构所产生的。
Laplacian:
拉普拉斯算子是各向同性微分算子,它具有旋转不变性。一个二维图像函数的拉普拉斯变换是各向同性的二阶导数,定义为:
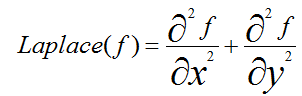
在一个二维函数f(x,y)中,x,y两个方向的二阶差分分别为:
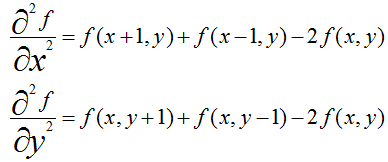
所以Laplace算子的差分形式为:

写成卷积核的形式就是如下表所示:
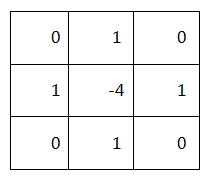
表1 拉普拉斯的filter mask
Block:
block模块是由两个Conv2DLayer和一个AddLayer组成的,其模块结构是借鉴resnet的block结构如下图。
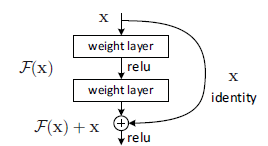
图8 resnet的block结构
屏幕照的最终效果:精准率97.8%,召回率:93.8%
基于图像HSV模式的黑白照识别
问题:
如图9所示,在用户/商户认证过程中,存在部分黑白照/复印件的现象,这部分图像数据并非原始的证照,不符合业务方对于证照质量规范的标准,有效的自动识别并退回申请,可以在很大程度上降低人工审核的工作量,帮助维护业务规范。


图9黑白证照
方法:
我们将图像转换成HSV模式,对现有样本进行颜色直方图的分布统计,选取了其中最强的两特征w和b,再根据w和b的分布情况设定一个阈值去判断该图是否为黑白照。
RGB转HSV:
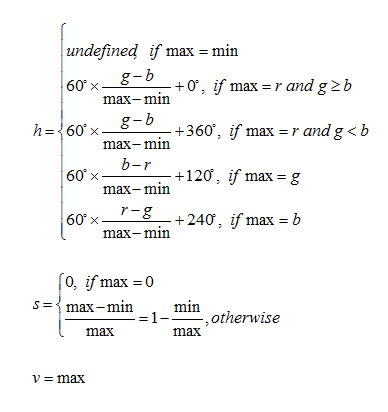
其中max,min表示RGB三通道中最大或最小的值,以下Pixel分布值:
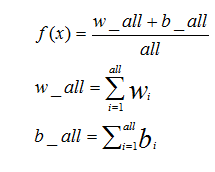
其中w和b是提取出的两类颜色特征,all指的是图像的像素数。考虑业务的要求我们设定了一个合理的阈值去满足高召回率的要求。在这一过程中,需要注意一类特殊情况,就是盖了红章的营业执照复印件,从业务角度这其实是符合规范要求的,所以我们进一步优化了特征取值,剔除掉有红章的黑白照。
基于GrabCut的图像完整性检测
问题:
在用户实名认证过程中,存在部分证件照缺边缺角或是遮挡,不符合业务规范。
方法:
通过使用GrabCut算法进行图像分割,该算法需要人为交互,我们要人工选定一个四边形框,把框中的图像作为grabcut的一个输入参数,表示该框中的像素可能属于前景,但框外的部分一定属于背景。然后调用grabcut方法,就可以分割出身份证。首先我们通过人为观察及实验,默认前景色为左上角坐标(0.02*w,0.02*h),长宽为(0.98*w,0.98*h)的矩形,其中w为图像宽度,h为图像高度。
在获得经过GrabCut处理之后的图像之后, 结合身份证数据集的规律,我们默认一张身份证图像中主体对象是身份证,即正常图片中,身份证占了图像的大部分面积,以此我们提出来以下判断流程来识别不完整图像:

图10图像完整性检测流程图
模型效果:
效果如下图右图,左图为原图:


图11 GrabCut在身份证上的效果
模糊照和滤镜照检测
实际业务中,部分用户/商户上传的证照较为模糊,人眼无法识别证照信息,通过基于像素点的统计信息,设计出较为直观且高效(准确率和召回率99%以上)的模糊照检测算法,可以很快速的帮助自动识别内容不清晰的模糊证照,减少人工审核成本。
另外存在滤镜照的问题(如图12所示),也可以通过类似的统计算法去准确判断,在此不多作赘述。


图12 滤镜照
六、图像内容提取
营业执照内容提取
基本思路是利用CTPN(Connectionist Text Proposal Network) + DenseNet(Dense Convolutional Network) + CTC(Connectionist temporal classification)进行对营业执照内容进行提取。
CTPN核心思想:检测一个一个小的,固定宽度的文本段,然后再后处理部分再将这些小的文本段连接起来,得到文本行。检测到的文本段的示意图如下图所示。

图13 CTPN核心思想
CTPN的网络结构为:CNN+RNN, CNN用来提取深度特征,RNN用来序列的特征识别。此外之所以采用DenseNet而非VGG、GoogleNet、ResNet等,这是因为DenseNet可以减轻了vanishing gradient,加强了feature的传递,更有效地利用了feature 。
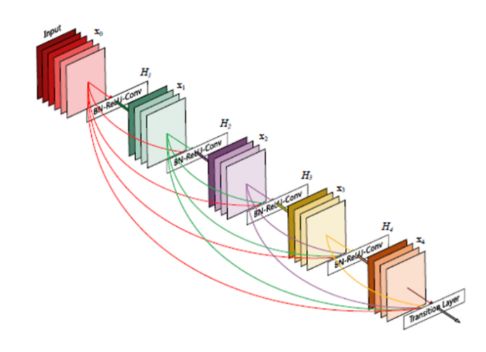
图14 DenseNet模型
提取结果如下图:

图15营业执照内容提取
因为营业执照的图像存在多类格式,并且受拍照环境(光线、位置、角度等)的影响,整体内容识别的效果还不是特别理想,这一块还在探索优化中。
总结与展望
自AI证件鉴伪的模型投产以来,累计帮助发现恶意虚假和不合规范的个人及商户证照2万余张,识别准确率超过90%。未来的工作方向,一方面是提升现有算法在某些领域应用的识别准确度;同时优化现有的算法网络结构,压缩模型参数,降低模型推理的时间;另一方面探索复杂模型在高实时性和高可用的生产环境要求下更加成熟合理的部署方案。
文献
[1] Mccloskey S , Chen C , Yu J . Focus Manipulation Detection via Photometric Histogram Analysis[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018.
[2] Zhou P , Han X , Morariu V I , et al. Learning Rich Features for Image Manipulation Detection[J]. 2018.
[3] Aniket Roy , Diangarti Bhalang Tariang , Rajat Subhra Chakraborty , et al. Discrete Cosine Transform Residual Feature based Filtering Forgery and Splicing Detection in JPEG Images[J]. 2018.
[4] Aaron Gokaslan, Vivek Ramanujan, Daniel Ritchie, Kwang In Kim, James Tompkin. Double JPEG Detection in Mixed JPEG Quality Factors using Deep Convolutional Neural Network. The European Conference on Computer Vision (ECCV), 2018.
[5] Tian Z , Huang W , He T , et al. Detecting Text in Natural Image with Connectionist Text Proposal Network[J]. 2016.
[6] Huang G, Liu Z, Laurens V D M, et al. Densely Connected Convolutional Networks[J]. 2016.
[7] He K , Zhang X , Ren S , et al. Deep Residual Learning for Image Recognition[J]. 2015.
[8] Szegedy C , Liu W , Jia Y , et al. Going Deeper with Convolutions[J]. 2014.
[9] Krizhevsky A , Sutskever I , Hinton G . Imagenet classification with deep convolutional neural networks[C]// NIPS. Curran Associates Inc. 2012.
[10] Hinton G . Deep belief networks[J]. Scholarpedia, 2009, 4(6):5947.
[11] Lowe D G . Distinctive Image Features from Scale-Invariant Keypoints[J]. 2004.
[12] Rother C. GrabCut: interactive foreground extraction using iterated graph cuts[C]// Acm Siggraph. 2004.
声明:本文来自橙风破浪IcM,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
