如果您从事网络安全工作已有一段时间,那么您一定听说过 "威胁建模"。虽然有很多解释和观点,但《威胁建模宣言》对威胁建模的一个权威解释是:
"Threat modeling is analyzing system representations to highlight concerns about security and privacy characteristics”.
"威胁建模是对系统表征进行分析,以突出对安全和隐私特征的关注"。
这通常涉及安全先驱Adam Shostack提出的四个基本问题:
我们在处理什么?
会出什么问题?
我们该怎么办?
我们做得足够好吗?
从表面上看,这似乎很简单,业内几乎任何人都可以使用,包括安全领域以外的人员,他们往往负责编写代码、构建系统和执行需要确保安全的 "任务"。
鉴于威胁建模的广泛性、各种实施方式和思维过程,出现各种威胁建模框架也就不足为奇了。
其中包括:
STRIDE (Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, Elevation of Privilege)(欺骗、篡改、抵赖、信息泄露、拒绝服务、权限提升)
LINDDUN (Linking, Identifying, Nonrepudiation, Detecting, Data Disclosure, Unawareness, Noncompliance)(链接、识别、不可抵赖性、检测、数据泄露、不知情、不合规)
PASTA (Process for Attack Simulation and Threat Analysis)(攻击模拟和威胁分析流程)
这些框架都不一定是对或错,还有其他一些变体。我的网络安全爱好者们将会并可以热烈地讨论为什么一个框架比另一个框架更好,为什么我们可能根本不需要它们,以及介于两者之间的所有问题。
抛开争论和热情不谈,威胁模型是思考系统和软件以及如何利用和保护系统和软件的绝佳思维模型。
框架往往会随着时间的推移而演变,并引入新的选项。今天,我写这篇文章来讨论我一直在关注的一个新威胁建模框架,我发现这个框架在处理代理人工智能架构和系统时很有帮助。
有了这样的背景,让我们来深入了解一下 MAESTRO。
MAESTRO - Agentic AI威胁建模框架

首先,每个威胁建模框架都必须有一个助记符(抱歉,规则不是我定的!)。
MAESTRO 是 Multi-Agent Environment(多代理环境)、Security(安全)、Threat(威胁)、Risk(风险)和 Outcome(结果)的缩写,由我的朋友 Ken Huang 创建。
现在,您可能会说,这算什么,又一个框架(YAF)?不过,正如 Ken 所指出的,现有框架没有解决人工智能的一些细微问题,因此 MAESTRO 有必要加入新的框架来弥补这些不足。
Ken 在云安全联盟(CSA)关于 Maestro 的一篇文章中阐述了这些差距,我强烈建议大家全文阅读(当然是在我的文章之后!)。
他列出的差距有:
与自主相关的差距
机器学习 (ML) 的具体差距
基于互动的差距
系统层面的差距
正如 Ken 所言,历史上的威胁建模框架存在一些缺陷。其中包括代理人的自主性和独立决策,而这往往是不可预测的,尤其是在概率非确定性模型方面。
针对人工智能的漏洞可能包括数据中毒和模型提取等例子,在这些例子中,恶意行为者试图破坏人工智能模型的新方面,如其训练数据,或提取使用中模型的敏感甚至专有元素。
基于交互的差距涉及代理将在内部和外部进行交互这一事实,这将通过新出现的协议(如模型上下文协议(MCP)和代理 2 代理(A2A))来促进。这些协议的出现有助于促进代理与外部服务、工具和系统的交互,以及多代理架构中代理之间的内部交互。
下面的图片有助于展示它们各自的作用:MCP 用于与工具、服务和系统进行内部和外部交互,A2A 用于促进代理间的交互。
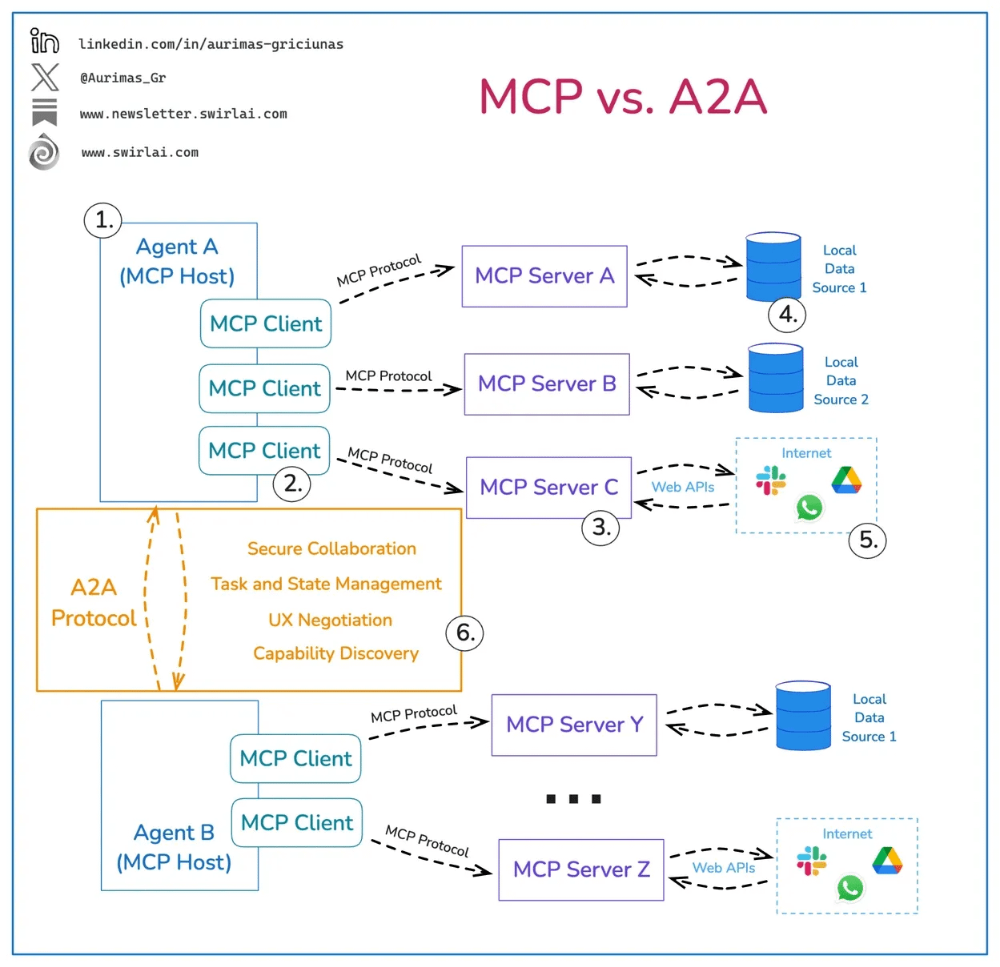
尽管如此,MCP 和 A2A 也有潜在的漏洞和挑战。下图展示了 MCP 的一些潜在漏洞。

Ken 和其他研究人员最近发表了一篇论文,展示了 MAESTRO 在 MCP 和 A2A 中的实际应用。我们还看到安全研究人员展示了 MCP 等协议中的漏洞,这些漏洞可用于破坏代理系统。下面,您可以看到论文中的一张图片,其中列出了他们通过 MAESTRO 威胁建模方法识别出的常见 A2A 多代理系统威胁。

最后,Ken 认为基于系统的差距是引入 MAESTRO 的理由,包括人工智能模型缺乏可解释性和可审计性等例子。这一点尤其适用于专有的非开源模型,因为人工智能模型的复杂性具有挑战性,其内部运作可能并不完全为人所知,甚至无法完全理解。即便是现在,仍有更多的研究不断涌现,以解释复杂模型的功能和活动。
Ken 还提到了人工智能模型供应链方面的问题,包括预先训练的模型受损、ML 库存在漏洞以及模型训练数据缺乏出处。
如您所见,Ken 创建 MAESTRO 的目的是为了涵盖人工智能特定系统的独特细微差别,包括模型、代理、自主性以及与模型和代理运行的系统相关的环境因素。
7 个层面
MAESTRO 的一个基本方面是代理人工智能的 7 层参考架构。在考虑代理架构及其一些独特的威胁、风险、漏洞和潜在的缓解措施时,我发现这方面的内容特别有用。
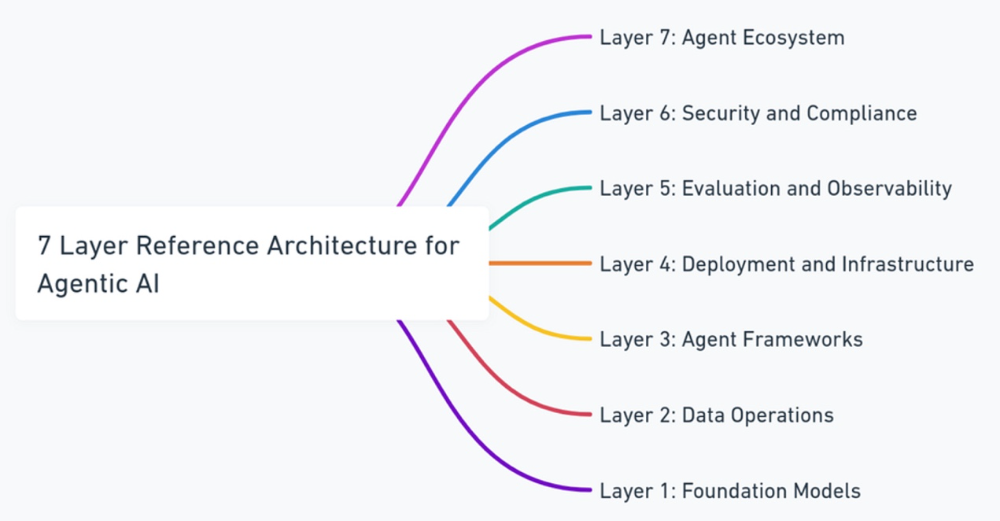
上面是一个很好的可视化文档,记录了每一层的情况。让我们简要浏览一下每一层,以便从安全角度更好地了解一些潜在风险和关键注意事项。
这种针对特定层的 MAESTRO 威胁建模框架方法可让从业人员了解代理架构的关键方面以及与每一层相关的独特风险和注意事项。
第 1 层:基础模型
虽然不一定非要从低到高,但我认为从模型入手,在一定范围内逐步深入是有意义的。基础模型通常(但不总是)是 LLM,需要考虑一些独特的威胁和风险。
除其他潜在风险外,Ken 还列举了后门攻击、数据中毒和恶意提示等对抗性实例。这远不是一份详尽无遗的清单,还有其他参考资料,如 MITRE ATLAS,它以 MITRE ATT&CK 为蓝本,但重点关注特定于人工智能的威胁,并提供了可用于攻击人工智能系统的战术和技术的真实案例。
我曾在一篇题为 "用 ATLAS 管理人工智能风险 "的文章中介绍过 MITRE 的 ATLAS。我还就 ATLAS 采访了 MITRE 的 Christina Liaghati 博士,采访内容如下:

我还要补充一点,关于模型,有一些独特的考虑因素,比如您是利用 HuggingFace 等流行平台上的开源模型,还是从模型服务提供商(如 OpenAI)那里获取模型,因为在后者那里,您对模型以及底层基础设施、托管环境等的透明度都不如自托管开源模型。
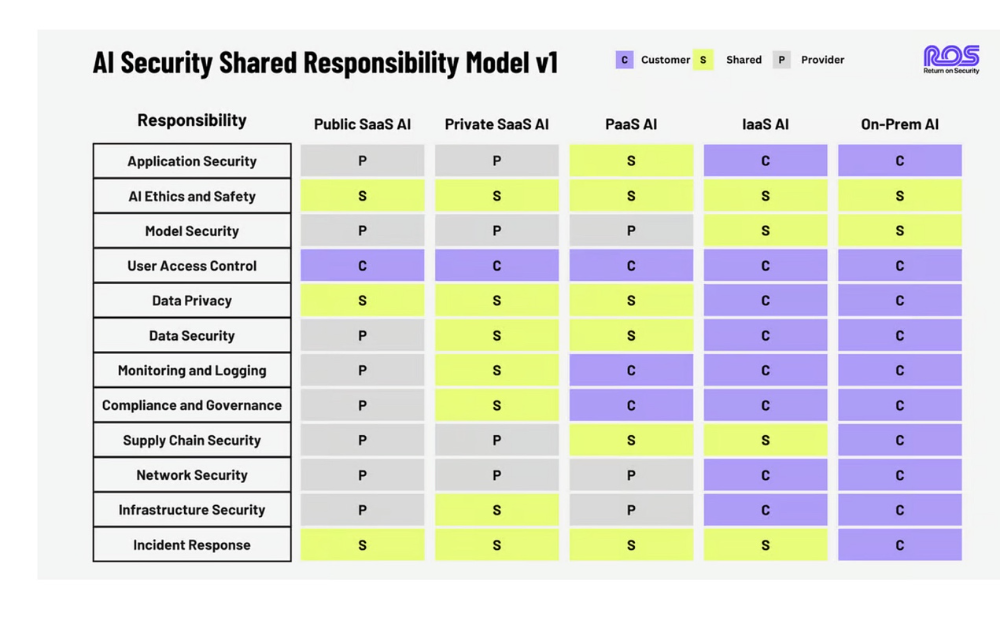
就像之前的云计算一样,你需要权衡利弊,向责任分担模式靠拢。请记住,不能将责任外包,无论如何都要承担责任。
虽然并不完美,但我在 Return on Security 的朋友 Mike Privette 很早就提出了 "人工智能安全共同责任模型",见下文:
第 2 层:数据运营
这层模型涉及人工智能代理与之交互的数据,这些数据可能会被存储、处理、准备和传输。在大多数情况下,数据是我们最终要保护的,也是对手的目标。
Ken 指出与这一层相关的主要威胁包括数据中毒、外渗、篡改和模型反转/提取等。这包括篡改模型所训练的数据、外泄敏感数据(可能因组织和用例而异)、破坏数据整合,甚至通过 API、提示和重构来 "窃取 "模型。
一个真实的例子是,领先的基础模型提供商之一 OpenAI 声称中国的 DeepSeek "窃取 "了他们的模型,或者至少大量利用 ChatGPT 来训练其竞争对手 DeepSeek。
据称,DeepSeek 建立了一个庞大的 ChatGPT 4o 回应数据库作为训练数据,随后用于训练自己的模型。
第 3 层:代理框架
随着代理人工智能的兴起,我们看到许多代理框架不断涌现和发展,以帮助促进它们在复杂企业环境中的实施和运行。这方面的例子很多,其中包括微软的 AutoGen、LangChain、CrewAI 和 LlamaIndex。
Ken 列举了这一层面临的一些新型威胁,其中包括被破坏的框架组件、后门攻击、输入验证攻击、框架规避以及对框架 API 的 DoS 攻击。
这些威胁专门针对用于促进多代理架构和环境的框架,并破坏代理框架的特定功能和配置。
这里的一个实际例子是 CISA 最近在流行的 Langflow 开源工具中发现的一个已知漏洞 (KEV),该工具用于通过可视化界面构建和部署人工智能代理。该漏洞由 Horizon3AI 发现,允许未经认证的远程攻击者完全控制 Langflow 服务器。
第 4 层:部署和基础设施
部署和基础架构层是我们中许多人可能更熟悉的一层,尤其是如果您一直从事云安全工作,甚至是在云之前的传统基础架构安全工作。
人工智能绝大多数是在云环境中运行的(参见 CSP 和人工智能领导者希望在托管环境甚至能源方面进行的大规模投资)。这包括虚拟机、Kubernetes 集群和更广泛的云虚拟化基础设施。这是由于处理、动态扩展基础设施、按需计算等方面的需求所致。
Ken 列举了这一层的威胁,包括容器镜像受损、协调攻击、基础设施即代码(IaC)操纵、拒绝服务(DoS)、资源劫持和横向移动。
这就是为什么基本的安全控制仍然至关重要,例如尽量减少臃肿的依赖关系、IaC 扫描、加固虚拟机/容器、监控异常使用/消耗,以及通过有效的微分隔、访问控制和总体零信任原则防止横向移动。
第 5 层:评估和可观察性
随着代理在企业环境中的普及,其数量将呈指数级增长,评估和可观察性将变得至关重要。这包括监控代理正在采取的行动、与之交互的工具、参与的流程、交互的数据以及潜在的异常行为。
最后一点尤为重要,因为凭证泄露和漏洞利用一样,仍然是一个突出的攻击媒介,因此代理将成为漏洞利用和泄露的目标,使攻击者能够进行权限升级、横向移动和移动等活动。
Ken 在这一层列举的具体威胁包括:操纵评估指标、破坏可观测性工具、逃避检测工具、通过可观测性泄露数据以及毒化可观测性数据。
此外,我们还看到了一种新的 AppSec 类别的出现,通常称为应用程序检测和响应(ADR)或云应用程序检测和响应(CADR),我曾在《ADR 如何解决检测和响应领域的空白》等文章中介绍过这一类别,我预计这一类别也将针对人工智能和代理工作流及工作负载继续发展。
第 6 层:安全与合规性(垂直层)
啊,大家最喜欢的话题,合规。
现在,在我们深入探讨这一层之前,对于那些喜欢调侃 "合规不是安全 "的反对者,我想在此打断你们,并指出两点:
合规并不等于安全,只是不能消除风险
在我们的行业中,合规性比任何其他因素都更能推动安全投资和关注,如果没有合规性,我们的安全程度将更低,而不是更高。
尽管如此,我还是公开承认,合规性在我们目前的处理方式中存在着巨大的问题,而且我们使用的方法、工具和流程也早该进行创新了。
Ken 正确地将其称为垂直层,因为合规性要求贯穿 MAESTRO 参考模型中的所有其他层。合规性必须融入所有人工智能代理操作和活动中。
虽然 Ken 确实列举了一些具体的威胁,如安全代理数据中毒、安全人工智能代理的规避、缺乏可解释性、人工智能安全代理的模型提取等,但我认为,我们能想到的与代理架构相关的几乎所有风险都有可能使我们处于无法满足合规要求或违反监管要求的境地,具体取决于威胁和场景的具体情况。
同样值得指出的是,合规框架在数字世界中的运作往往是类比的。技术发展很快,但政策(合规)的发展往往要慢得多,这并不是天生的坏事,因为急于过快地规范技术也可能导致扼杀创新或不连贯的合规要求,几乎没有实际意义。
尽管如此,在我们所处的环境中,欧盟尤其迅速制定了强有力的人工智能监管要求,如《欧盟人工智能法案》和其他法案,这些法案对人工智能的使用提出了具体要求,随后将适用于与人工智能系统互动的代理。
实施代理架构和代理的组织需要考虑新出现的合规性和监管要求,包括现有的要求和框架,以及这些控制措施如何与代理和代理身份、访问控制、行动以及评估人员和审计人员在评估 IT 系统和环境时可能开始涉及的任何其他事项相联系。
第 7 层:代理生态系统
MAESTRO 七层模型的第七层:代理生态系统。这涉及企业市场的代理及其实施,包括业务应用程序、智能客户服务平台和企业自动化解决方案。
Ken 在此列举的风险包括代理身份攻击、代理受损、代理工具滥用、代理目标操纵、市场操纵和代理注册表受损等。
结束语
当然,我们是否需要另一个威胁建模框架或哪个框架是 "最好的 "还有待商榷。尽管如此,MAESTRO 显然是一个很好的心理模型,也是从业人员在保护数字和网络物理系统(特别是涉及代理和代理人工智能的系统)安全时工具箱中的额外工具。
原文链接:
https://www.resilientcyber.io/p/orchestrating-agentic-ai-securely
声明:本文来自安全喵喵站,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
