
原文标题:DeepGo: Predictive Directed Greybox Fuzzing
原文作者:Peihong Lin, Pengfei Wang, Xu Zhou, Wei Xie, Gen Zhang, Kai Lu原文链接:https://dx.doi.org/10.14722/ndss.2024.24514发表会议:NDSS 2024笔记作者:王彦@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1 总体介绍
定向灰盒模糊测试(DGF)专注于测试预定义的脆弱代码区域(如补丁、漏洞复现),通过适应度指标(如代码距离)优先选择更可能接近目标位置的输入。现有的 DGF 技术通过启发式方法优化适应度指标(如基于踪迹相似性、数据流信息),但这类方法普遍依赖历史执行信息,缺乏对未执行路径的前瞻性。当遇到复杂路径或深层路径约束时,模糊测试器易陷入低效路径,导致目标到达速度下降。
当前主流 DGF 技术(如 AFLGo、WindRanger)通过重定义适应度指标(如基本块距离、数据条件)提升方向性,或通过路径剪枝(如 BEACON)、序列扩展(如 Berry)优化效率。然而,这些方法仍受限于随机变异的不可预测性——启发式策略无法预判未执行路径的可行性,难以规避高约束路径对效率的影响。
本文实现了 DeepGo,通过路径转移模型将 DGF 形式化为路径序列优化问题。本文的贡献如下:
提出路径转移模型:作者首次将 DGF 建模为路径转移序列过程,通过定义 (路径, 动作, 新路径, 奖励) 四元组,量化突变行为对执行路径的贡献,并以“序列奖励”度量整体到达目标路径的可能性,从理论上为路径导向模糊测试提供了统一建模框架。
构建虚拟集成环境 VEE:借助深度神经网络构建 VEE 模块,实现对 未执行路径转移及其奖励的前瞻预测。该模块基于高斯分布建模不确定性,采用集成学习(PETS)机制,大幅提高预测准确性与泛化能力,是实现智能模糊测试策略的基础。
引入强化学习策略生成模型 RLF:利用 Soft Actor-Critic 算法设计的 RLF 模型结合历史和预测路径转移信息,通过 k-step rollout 学习最优策略 π,用于指导模糊器采取更高效的突变动作,显著提升了策略的长期回报与路径质量。
提出 Action Group 与多维策略优化(FO):首次将种子选择、能量分配、Havoc 循环轮次、变异器选择和变异位置整合为统一的“Action Group”,使用多元素粒子群优化算法(MPSO)对策略空间进行联合优化,确保强化学习策略能高效落地执行。
实验验证:在真实程序集上验证了 DeepGo 框架有的效性,在 Gitee 平台开源(https://gitee.com/paynelin/DeepGo),为后续研究提供了高质量实验平台和扩展基础。
2 背景知识
定向灰盒模糊测试(DGF)DGF 将目标可达性转化为优化问题,最小化输入与目标的距离(如基于调用图/控制流图的代码距离)。运行时根据适应度指标(如距离+条件复杂度)设计能量调度策略,优先分配资源给高潜力种子。代表性工具如 AFLGo 通过静态插桩获取距离信息指导模糊测试。
深度神经网络(DNN)与强化学习(RL)DNN 能逼近复杂非线性函数,已被用于模拟程序分支行为(如 NEUZZ)。RL 通过智能体与环境的交互学习最大化累积奖励的策略,适用于序列决策问题(如马尔可夫过程)。DeepGo 借鉴 基于模型的策略优化(MBPO),结合 DNN 环境模拟与 RL 策略学习。
粒子群优化(PSO)PSO 模拟鸟群觅食行为,通过个体协作寻找最优解。每个粒子通过速度和位置迭代更新,追踪局部最优(lbest)和全局最优(gbest)。MOPT 等工具将 PSO 用于优化变异算子选择概率。
3 方案设计
3.1 整体架构
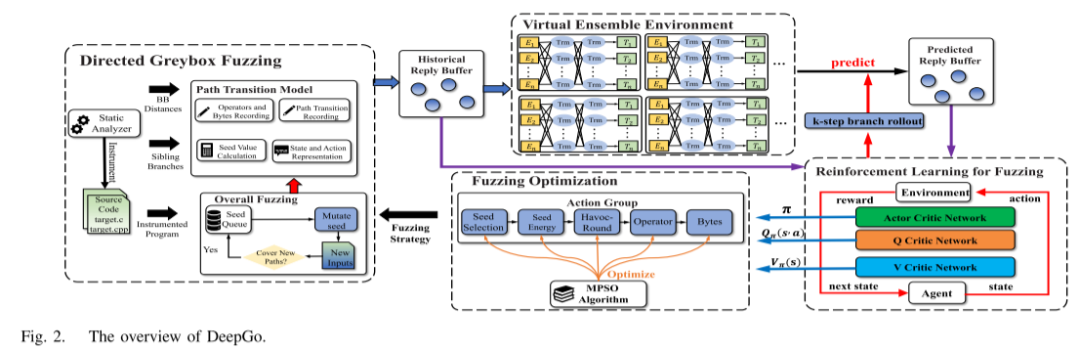
DeepGo 的核心思想是将 Directed Greybox Fuzzing (DGF) 建模为路径转移序列的问题。整体架构如图2所示, 包含四个组件:
DGF 组件:执行模糊测试,集成路径转移模型,通过静态分析器获取基本块距离等程序信息。
虚拟集成环境(VEE):用 DNN 预测给定路径和动作的下一路径及奖励,编码路径为 20 维向量(耦合数据嵌入算法)、动作为变异位置归一化值。
强化学习模型(RLF):基于 SAC 算法,包含 Actor 网络(策略生成)、Q-Critic(序列奖励评估)、V-Critic(路径转移价值评估)。通过 k 步分支展开策略结合历史与预测路径转移训练模型。
模糊测试优化组件:基于动作组和 MPSO 算法同步优化 5 个关键步骤(种子选择 SS、能量分配 SE、变异轮次 HR、变异算子 MT、变异位置 LC)
3.2 路径转移模型
每一次种子突变被视为一个动作,它会导致执行路径发生转移。每个路径转移都被赋予一个奖励值,用来评估它对靠近目标代码的有效性。路径转移模型以四元组 (当前路径, 动作, 下一路径, 奖励) 描述状态转移。种子价值由目标距离、分支反转难度、执行速度、种子优先级加权计算(熵权法分配权重)。奖励定义为转移前后种子价值差。序列奖励通过 Bellman 方程递归计算,衡量路径序列整体价值。
4 实验评估
4.1 实验设置与基准
实验选用两个广泛使用的基准数据集:UniBench(20 个真实程序/80 个目标点,评估目标到达时间 TTR)和 AFLGo 测试集(评估漏洞暴露时间 TTE)。对比工具包括 AFLGo、BEACON、WindRanger 和 ParmeSan 四款先进 DGF 工具。实验配置为 24 小时时限、5 次重复运行,通过 Mann-Whitney U 检验(p 值)和 Vargha-Delaney 统计量验证显著性。目标点选择基于 AFL++的 48 小时覆盖分析,确保其需 1-48 小时到达以体现 DGF 优势。
4.2 目标到达效率(TTR)
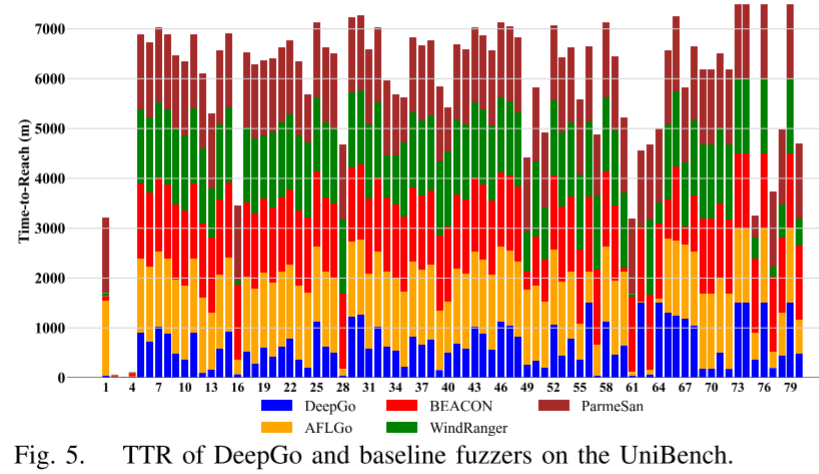
在 UniBench 上,DeepGo 覆盖 73/80 个目标点,显著优于基线(AFLGo: 22, BEACON: 11, WindRanger: 19)。其平均 TTR 比 AFLGo、BEACON、WindRanger 和 ParmeSan 分别快 3.23 倍、1.72 倍、1.81 倍和 4.83 倍。所有 p-value 均 小于 0.05,Vargha-Delaney 均值大于 0.8(如对 AFLGo 为 0.86),证明结果具有统计显著性。图 5 通过柱状图直观展示:DeepGo(蓝色)在 67/80 目标点上耗时最短,尤其对复杂目标(如 mp42aac 程序)优势达数倍。
4.3 漏洞触发能力(TTE)
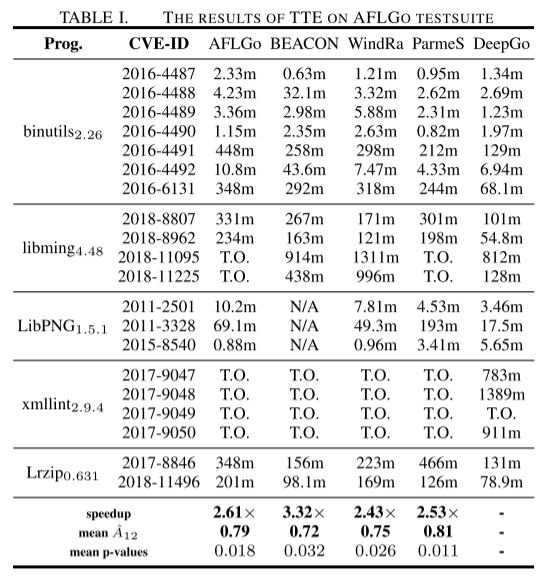
在 AFLGo 测试集的 20 个 CVE 漏洞上,DeepGo 暴露 19 个漏洞(表 I),超过 AFLGo(14)、WindRanger(16)等工具。其平均 TTE 比基线快 2.43–3.32 倍。
4.4 VEE 预测精度
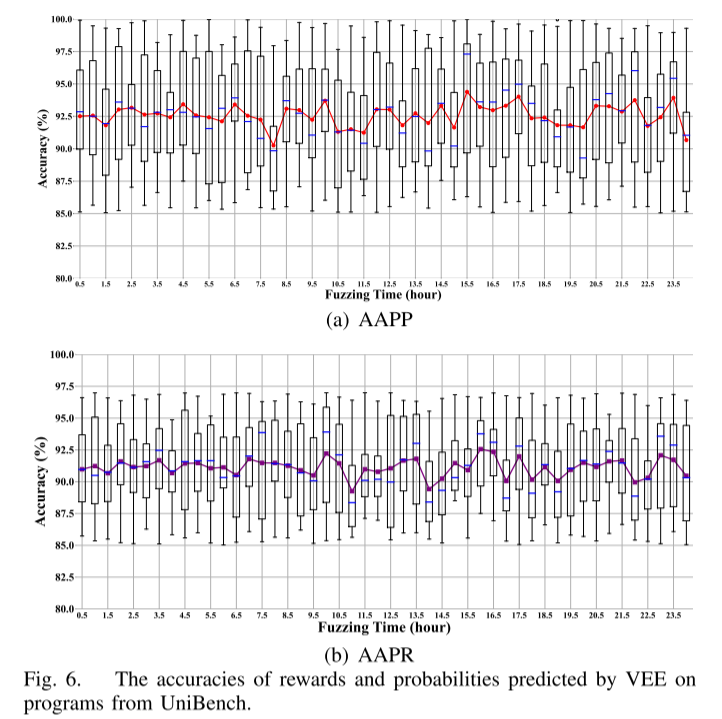
通过公式( )量化预测准确率。图 6 显示:VEE 的路径转移概率预测(AAPP)和奖励预测(AAPR)全程 大于 80%,24 小时内平均值达 92.57% 和 91.10%。箱线图表明不同程序间波动 小于等于15%(如 mp3gain 与 lame 的 AAPR 差值仅 12.3%),证明模型鲁棒性。高精度预测使 DeepGo 无需实际执行即可评估路径潜力,减少无效探索。
4.5 RLF 与 FO 的引导效果
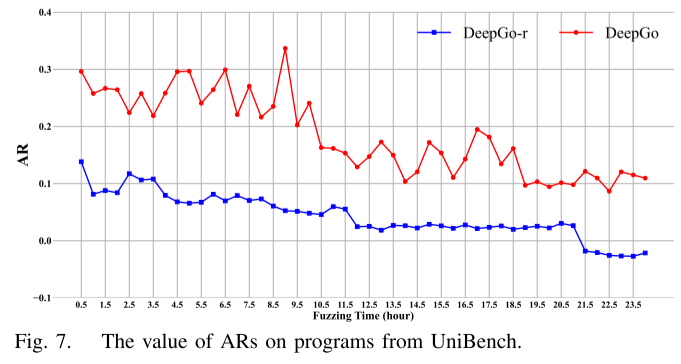
为验证 RLF+FO 的引导能力,对比完整 DeepGo 与移除两者的 DeepGo-r。图 7 显示:DeepGo 的路径平均奖励(AR)始终高于 DeepGo-r,24 小时平均差距达 4.26 倍(如 12 小时时 0.32 vs 0.075)。AR 下降趋势符合模糊测试后期探索难度增加的规律,但 DeepGo 通过高奖励路径选择显著减缓下降速度。这表明 RLF 生成的策略能有效引导动作组执行高序列奖励路径。
4.6 消融实验
为评估 DeepGo 系统中各个关键模块(VEE、RLF、FO)的独立与协同贡献,作者设计了消融实验(ablation study),发现:
去除 VEE:路径预测缺失,策略前瞻性明显下降;
去除 RLF:策略不再考虑路径 reward,模糊效率下降;
去除 FO:策略难以执行,优化效果被削弱。
结果证实,DeepGo 各模块间协同优化是其高性能的关键。
5 结论
本文提出了 DeepGo,一种面向预测优化的定向灰盒模糊测试方法。DeepGo 创新性地引入“路径转移模型”,结合深度神经网络构建的虚拟集成环境(VEE)用于预测未来可能的路径转移及其回报,并通过强化学习模型(RLF)整合历史与预测信息生成最优路径策略,最终通过多元素粒子群优化算法(MPSO)在“Action Group”粒度上联合优化模糊测试策略。实验结果表明,DeepGo 在多个基准数据集上均显著优于现有主流 DGF 工具,在目标位置覆盖效率和漏洞触发能力上均取得了大幅提升。该研究为提升定向模糊测试的智能化和效率提供了一种全新范式,也验证了结合预测建模与策略学习的可行性与实用价值。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
