
原文标题:Large Language Models for Code Analysis:Do LLMs Really Do Their Job?
原文作者:Chongzhou Fang,Ning Miao,Shaurya Srivastav,Jialin Liu,Ruoyu Zhang,Ruijie Fang,Asmita,Ryan Tsang,Najmeh Nazari,Han Wang,and Houman Homayoun
原文链接:https://www.usenix.org/conference/usenixsecurity24/presentation/li-yuexin
发表会议:USENIX
笔记作者:牟浩天@安全学术圈
主编:黄诚@安全学术圈
编辑:张贝宁@安全学术圈
1、引言
近年来,大语言模型(LLMs)在自然语言处理和编程任务中表现出巨大潜力。但是现有文献缺乏对LLMs在代码分析领域,尤其是混淆代码方面的系统性评估。因此,文章旨在通过全面评估LLMs在执行代码分析任务中的能力来弥补这一空白。
文章专注于评估LLMs分析输入代码样本的能力,并测试LLMs是否可用于防御性分析任务。文章首先构建了一个包含真实世界程序及其混淆版本的代码数据集,供LLMs处理,然后分析结果并展示获得的关键发现。文章通过系统分析回答两个关键的研究问题:第一,LLMs是否理解源代码?第二,LLMs能否理解混淆的代码或可读性较低的代码?之后,作为现实世界的案例研究,文章展示了公开可用的LLMs(例如ChatGPT)是否可以用于针对现实世界恶意软件的安全相关任务。
文章的主要贡献如下:
• 构建了两个数据集,其中包括来自流行编程语言的代码样本及其混淆后的样本,用于研究评估;
• 系统地评估了当前公开可用的先进LLMs的表现,包括最受欢迎的GPT和LLaMA系列模型;
• 使用LLMs对现实世界中的恶意软件进行案例研究,以展示LLMs在这些任务中的能力和局限性。
这是第一篇系统评估LLMs理解代码和混淆代码能力的论文。
2、背景知识
在这一部分,文章将概述大型语言模型、代码分析、代码生成和代码混淆的技术背景。
2.1 大语言模型
大型语言模型(LLMs)是人工智能领域的一项突破性创新,代表了自然语言理解和生成方面的一个重要里程碑。大多数LLMs都基于深度学习架构,它们是在包含互联网、书籍和Github上各种文本的大规模数据集上训练的。这种广泛的训练使它们能够掌握语言的复杂性,包括语法、上下文和语义。
2.2 代码分析
代码分析是软件工程中的一个过程,用于检查源代码、字节码或二进制代码,以确保质量、可靠性和安全性。现代软件规模日益庞大,促使研究人员提出自动化的工具。为此,一些研究人员提出从源代码中提取特征,并利用机器学习建立漏洞检测模型。
2.3 代码生成
代码生成一直是LLMs最流行的应用之一,这一应用的后续发展对编程的教学、实践和评估方式产生了重大影响。有研究指出,LLMs在代码编写任务上的表现不低于甚至优于普通学生,但虽然LLMs的代码生成能力可以提高用户的生产力和创造力,但也可能对安全性和程序员的理解产生一定负面影响,这也是文章研究的部分动机。
2.4 代码混淆
代码混淆是指通过转换得到功能等价但难以理解的程序代码,旨在保护开发软件的知识产权或隐藏恶意行为。这种转换包括数据编码、不透明谓词、控制流扁平化等。混淆技术已被用于防止逆向工程对关键代码部分的攻击。然而,LLMs的重大进展对现有的基于代码混淆的保护方法提出了挑战,人们开始质疑现有混淆技术是否仍能有效对抗基于LLMs的去混淆并保护开发软件中的敏感信息。因此,迫切需要评估代码被混淆时LLMs的代码分析结果。
3、实验设置
3.1 LLM选择
文章选用了五个有代表性的流行LLM模型进行部署,他们分别是GPT-3.5-turbo、GPT-4、LLaMA-2-13B、Code-LLaMA-2-13B-Instruct以及StarChat-Beta。选择这些模型的原因是它们被广泛使用,涵盖不同的提供商和参数规模,并且是目前最先进的可用于执行代码任务的公开LLM。
3.2 提示词构建
在实验中,文章构建的所有提示语要么涉及简单指令,例如“分析这段代码并告诉我它的作用”,要么使用经过验证的构造法,例如给模型分配角色等。
3.3 非混淆代码数据集
选择了JavaScript、Python和C三种语言。数据来源包括GitHub上的实际项目、性能基准和编程问题数据集。对于数据集中的每个代码文件,文章开发了脚本来自动删除注释,以消除它们对分析结果的影响,这是为了让LLM专注于代码本身,而不是注释中不必要的自然语言提示。关于处理文件的代码行数(LoC)分布的直方图如下。从中可以看出数据集包括从非常简短到大规模的代码样本,数据集中的代码样本来自不同的来源,覆盖了不同的使用场景,由此可见该数据集的覆盖范围是充分的。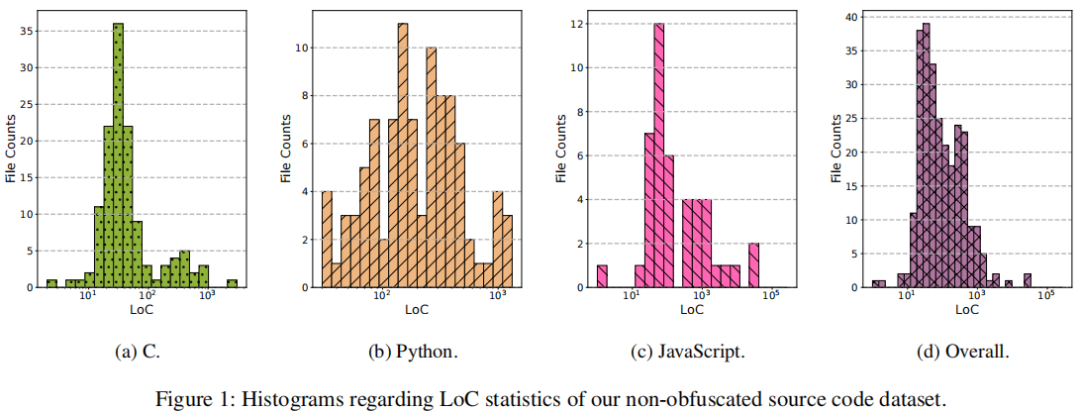
3.4 混淆代码数据集
文章选择对上面非混淆代码数据集中的JavaScript分支执行混淆。这一选择是由 JavaScript语言中普遍存在的代码混淆实践驱动的,因为JavaScript代码通常对网页用户可见,因此需要额外的混淆保护。此外,恶意JavaScript开发人员也会对其代码应用混淆技术以隐藏脚本的真实意图。测试的混淆方法有默认混淆(DE)、死代码注入(DCI)、控制流扁平化(CFF)、拆分字符串(SS)以及跨语言混淆(WSM)五种。涵盖了经典的代码混淆技术以及一种较新开发的混淆工具。通过测试LLM在这些混淆代码样本上的表现,将能够了解这些混淆技术如何影响LLM 理解代码的能力。
除了混淆先前获取的JavaScript代码之外,文章还结合了国际混淆C代码竞赛(IOCCC)中的现有混淆代码样本。这部分混淆代码数据集上的实验评估了LLM在面对更灵活和非标准的混淆技术时的表现。
3.5 测量方法
实验的流程图如下所示。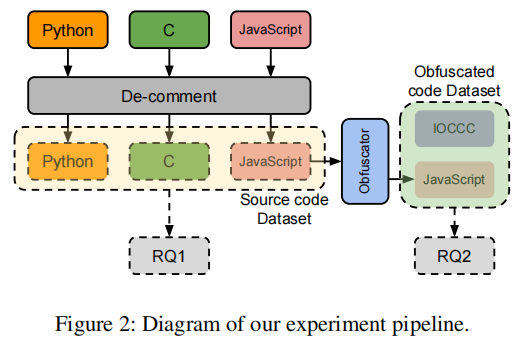 在收集了目标大语言模型对代码分析的响应之后,文章开始进行人工验证流程以检查分析结果的正确性。这是由于文章使用的所有源代码文件最多只有几十行简洁的注释,而且附加的描述标签也很简短,因此不能直接应用例如n-gram这样的定量指标来确定生成的分析结果的正确性,这就需要一个手动验证过程。
在收集了目标大语言模型对代码分析的响应之后,文章开始进行人工验证流程以检查分析结果的正确性。这是由于文章使用的所有源代码文件最多只有几十行简洁的注释,而且附加的描述标签也很简短,因此不能直接应用例如n-gram这样的定量指标来确定生成的分析结果的正确性,这就需要一个手动验证过程。
文章选择使用余弦相似度、基于Bert的语义相似度评分和ChatGPT-based评估等作为评估模型所生成的代码解释的指标。其中ChatGPT-based评估是文章使用的一种特殊的评估方式,文章首先手动检查GPT-4的结果,因为它具有更好的自然语言生成和推理能力。完成此步骤后,文章将使用GPT-4中那些被标记为正确的描述来进一步比较不同的LLM。文章研究中向GPT-4发出如下的指令: 然后使用生成的输出来检验其他模型生成的解释的正确性。
然后使用生成的输出来检验其他模型生成的解释的正确性。
4、实验结果
在这一部分中,文章展示了在非混淆代码数据集和混淆代码数据集上实验的结果,主要目的是回答第 1 节中提出的两个研究问题:
• RQ1:大语言模型是否理解源代码?
• RQ2:大语言模型能否理解混淆过的代码?
4.1 非混淆代码数据集结果
GPT-4结果。GPT-4 经过人工验证的准确率结果如图所示。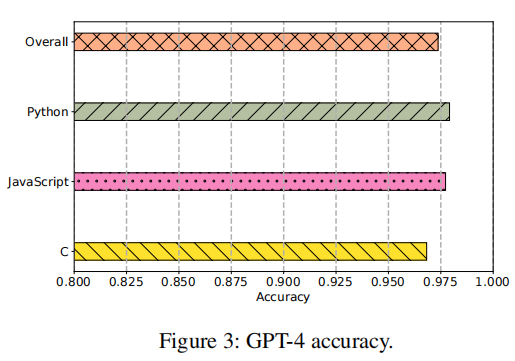 从图中可以看到,GPT-4在三种语言上的准确率很高。所有这三种语言中,超过95% 的GPT-4分析结果与代码样本的实际内容一致。总体准确率为97.4%,表明GPT-4可以作为强大的代码分析工具。
从图中可以看到,GPT-4在三种语言上的准确率很高。所有这三种语言中,超过95% 的GPT-4分析结果与代码样本的实际内容一致。总体准确率为97.4%,表明GPT-4可以作为强大的代码分析工具。
其他选定模型的分析准确率。在下图中,展示了余弦相似度评分、基于 Bert的语义相似度和通过 GPT-4 测量的代码解释准确率。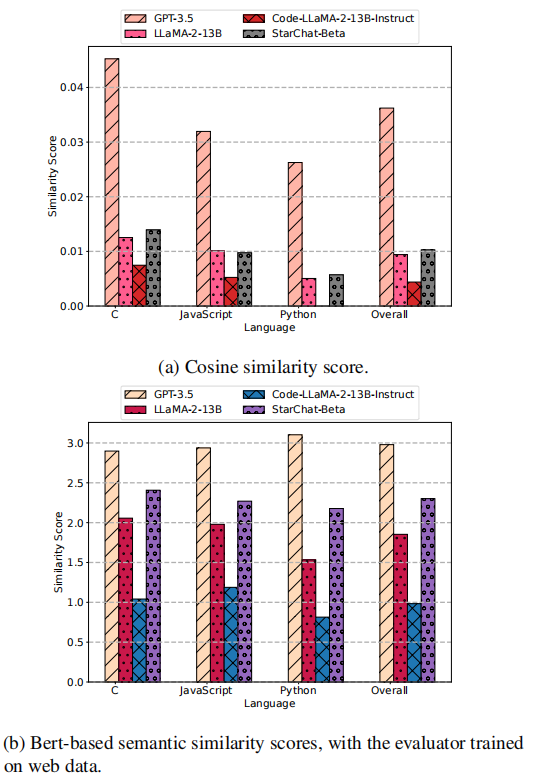
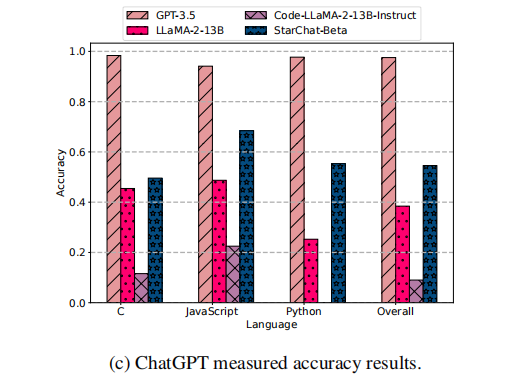 从中可以看到,GPT-3.5的表现与GPT-4类似,表明这两个模型在代码分析任务中都能达到高性能。然而,对于LLaMA系列模型和StarChat-Beta来说,其准确率显著较低。
从中可以看到,GPT-3.5的表现与GPT-4类似,表明这两个模型在代码分析任务中都能达到高性能。然而,对于LLaMA系列模型和StarChat-Beta来说,其准确率显著较低。
基于上述的实验结果,文章对于RQ1作出了回答:对于非混淆代码,像GPT-3.5或GPT-4这样的大型模型有很大概率能为输入代码片段生成正确且详细的解释,而较小的模型即使在代码数据上进行了微调,也无法生成正确的输出。
4.2 混淆代码数据集结果
混淆代码分析能力评估。文章首先专注于分析混淆的JavaScript代码样本。使用与之前部分相同的提示词来命令大语言模型分析代码并生成解释。尽管在混淆过程中函数块以不同的方式重写,但其功能不会改变,因此将继续使用相同的一组指标来评估代码解释的有效性。关于混淆代码分析的相似性评分和准确率结果如图所示。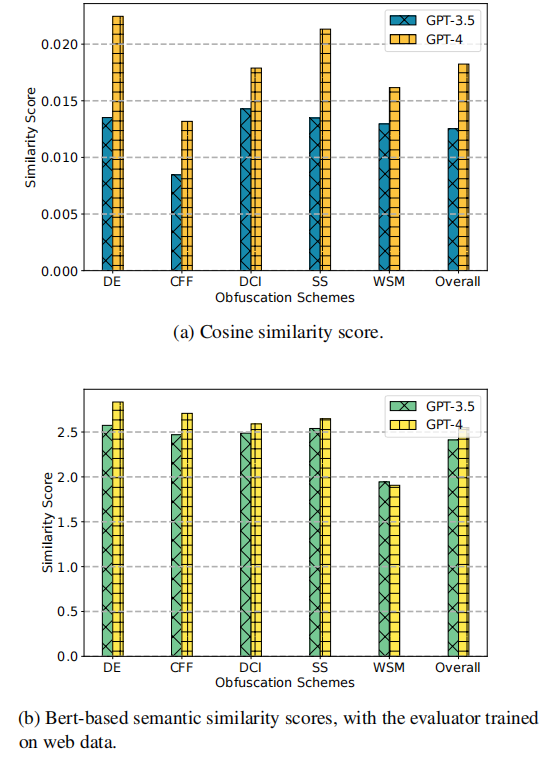
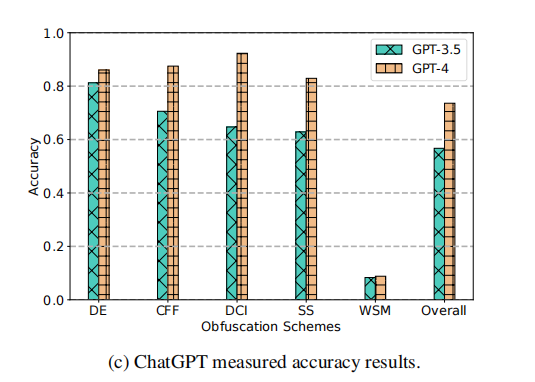 从图(c)中可以看出,GPT-4仍然表现出卓越的分析准确率,达到了87%的准确率。而GPT-3.5受到混淆技术的影响,尤其是当应用更高级的技术时准确率较低。至于图(a)和(b)中显示的相似性评分指标,可以看到两个模型的表现都有所下降,但GPT-4的相似性评分始终高于GPT-3.5。这些结果表明,在面对混淆代码分析时,GPT-4是更好的选择。
从图(c)中可以看出,GPT-4仍然表现出卓越的分析准确率,达到了87%的准确率。而GPT-3.5受到混淆技术的影响,尤其是当应用更高级的技术时准确率较低。至于图(a)和(b)中显示的相似性评分指标,可以看到两个模型的表现都有所下降,但GPT-4的相似性评分始终高于GPT-3.5。这些结果表明,在面对混淆代码分析时,GPT-4是更好的选择。
去混淆代码生成能力评估。除了比较在混淆JavaScript数据集上的代码解释结果外,文章还测试了LLMs生成去混淆代码的能力。由于这是一个具有挑战性的任务,文章仅在两个强大的模型上执行了此评估,即GPT-3.5以及GPT-4。文章选择了2011年之后IOCCC竞赛的100个获奖项目,并让LLMs扮演代码分析专家的角色,指示LLMs执行代码去混淆任务。文章通过是否可以生成代码;(如果生成)生成的代码是否能通过编译;(如果可编译)编译后的代码是否产生正确输出三个方面来评估模型的去混淆代码能力,相应的统计结果如下图所示。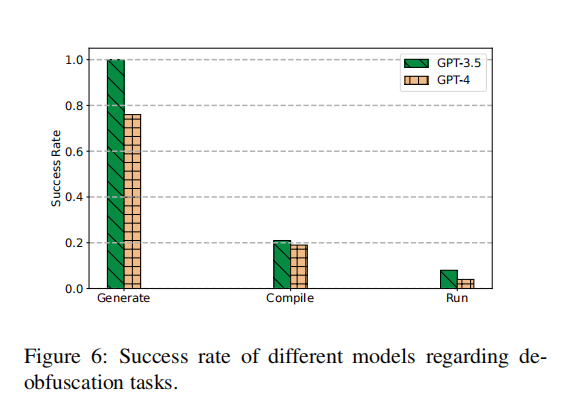 对于GPT-3.5来说,虽然它成功为所有目标生成了代码输出,但仅有约20%的输出代码样本可以通过编译,且仅有8%的生成代码样本(占已编译样本的38%)能够产生正确结果。GPT-4的表现比GPT-3.5更差。它只能为76%的实验代码样本生成去混淆代码。仅有19%的所有实验代码样本(占生成代码的25%)能成功通过编译步骤,而仅有4%的所有实验代码样本(占已编译代码的21%)能产生正确结果。这些统计数据显示,尽管LLM在生成解释性分析结果方面表现出色,但在生成可运行的去混淆代码方面的表现令人失望。有趣的是,在代码去混淆任务中,尽管GPT-3.5是一个较不先进的模型,但在这些指标上却优于GPT-4。
对于GPT-3.5来说,虽然它成功为所有目标生成了代码输出,但仅有约20%的输出代码样本可以通过编译,且仅有8%的生成代码样本(占已编译样本的38%)能够产生正确结果。GPT-4的表现比GPT-3.5更差。它只能为76%的实验代码样本生成去混淆代码。仅有19%的所有实验代码样本(占生成代码的25%)能成功通过编译步骤,而仅有4%的所有实验代码样本(占已编译代码的21%)能产生正确结果。这些统计数据显示,尽管LLM在生成解释性分析结果方面表现出色,但在生成可运行的去混淆代码方面的表现令人失望。有趣的是,在代码去混淆任务中,尽管GPT-3.5是一个较不先进的模型,但在这些指标上却优于GPT-4。
基于上述的实验结果,文章对于RQ2作出了回答:混淆技术会影响LLM生成解释的能力。在实验中,较小的模型无法处理混淆代码。GPT-3.5和GPT-4的分析准确率都有所下降,尤其是面对WSM时,尽管GPT-4在传统混淆方法上仍具有可接受且更优的准确率。在没有专门针对去混淆代码生成优化的情况下,LLM 在生成功能性去混淆代码方面能力较弱。
5、案例研究
文章在本节中,选取了两个最新发布的GitHub仓库(一个为良性代码,一个为恶意代码),以测试GPT系列模型在恶意软件分析中的表现,展示了如何利用LLM 的功能进行防御性的静态分析。随后还选取了Android平台的msg-stealer病毒和WannaCry勒索病毒,进一步探索LLM在反编译和混淆代码分析方面的能力。
5.1 GitHub代码仓库分析
在此案例研究中,文章选择了一个僵尸网络系统的Python脚本集合以及一款用于书签搜索的Chrome扩展。通过恶意软件与良性软件的对比,文章仔细观察并得到分析结果:GPT-4能够正确解释代码功能并指出恶意行为,但也存在潜在的误报。
5.2 移动平台病毒分析
下图显示了移动平台病毒案例分析的流程图。文章分析了一个名为msg-stealer的Android病毒的反编译代码。并通过使用jd-gui,这个由Java Decompiler提供的图形工具,成功反编译了该病毒的.apk文件,并生成了908个.java文件,包含约25万行代码。随后将每个反编译后的代码文件分别输入到GPT-3.5和GPT-4中,并获得908份代码分析结果。最后指示GPT-4阅读这些分析结果,并在发现任何异常或潜在恶意行为时发出警报。结果表明GPT-4能够正确识别病毒的行为,但在独立分析病毒某个代码片段时未能识别潜在的恶意行为。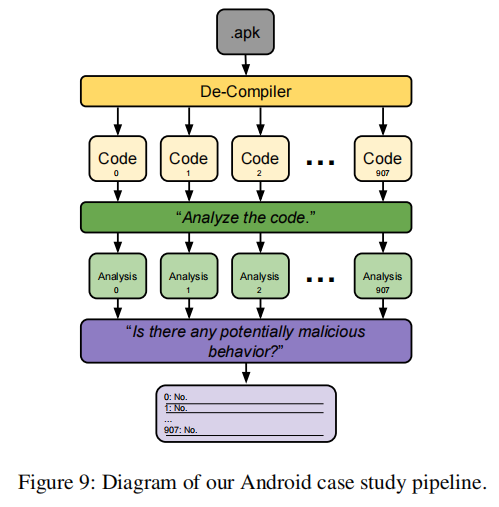
5.3 WannaCry勒索软件分析
在该案例中,文章让GPT-3.5分析了WannaCry勒索软件的反编译代码。由于生成的反编译代码较长,文章只能分批次的在与模型的交互中给予模型反编译的代码,结果表明GPT-3.5能够提取整个勒索病毒中的关键攻击行为并引发安全警告,但在处理长代码和复杂上下文时存在局限性,有些在前批次对话中的代码地址标签在后面批次的对话中被忽略且未被记住。
6、讨论
6.1 使用LLMs进行代码分析
文章认为更高级的大语言模型(例如GPT-3.5、GPT-4)在代码分析任务中表现更好,能够生成准确的代码解释。而较小的模型(如LLaMA系列和StaChat-Beta)性能较差,无法产生有意义的结果。这表明在代码分析领域,选择合适的大型LLMs更为可靠。
6.2 未来工作
本文的研究工作揭示了该领域一些可能的未来研究方向。
•构建包含混淆代码的数据集:现有工作多关注正常代码分析,缺乏融合混淆技术的大型数据集。构建这样的数据集有助于用户快速微调预训练LLMs,以更好地应对代码分析中的混淆挑战。
•探索LLMs的记忆现象:研究中观察到LLMs存在记忆训练数据的现象,但其底层机制尚未明确,需进一步探究以优化模型性能和安全性。
•开发更精细的评估指标:目前使用的评估指标如基于n-gram的算法和ChatGPT-based方法存在局限性,亟需构建更能精准捕捉代码分析结果本质的评估指标。
7、相关工作
文章的这部分主要综述了代码分析和LLM评估两个领域的其他相关研究进展
代码分析。传统方法涉及使用CNN分析程序语法树,以及利用Bi-GRU网络从语法树中提取特征以识别漏洞。随着NLP技术的发展,基于Transformer的模型显著推动了该领域进步,如通过自动预测变量名和类型提升反编译代码可读性。
LLM评估。近年来研究者开始关注LLMs在不同任务上的能力表现,如视觉、编码和数学等。但现有评估工作大多集中在代码生成方面,对于代码混淆分析等任务尚未涵盖。
8、总结
文章对当前流行的大语言模型(LLMs)的代码分析能力进行了全面评估。结果表明,较大的LLM,特别是GPT系列,在代码分析任务中表现令人印象深刻。但文中评估的LLaMA家族中的较小模型在这些相同任务中的表现并不理想。在分析混淆代码时,GPT系列的LLM仍然能为解释相关任务生成合理有用的结果,然而它们的表现仍有提升空间。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
