引言
当我们在惊叹于ChatGPT等生成式AI的强大能力时,一场围绕其“饲料”——训练数据的商业战争早已悄然打响。AI模型需要海量的文本、图片和代码来学习,而这些内容大多受版权保护。AI开发者是否应该为此付费?一个庞大而隐秘的“AI授权经济”正在形成。
最近,英国政府正在就AI与版权的法律框架征求意见,而一份由英国格拉斯哥大学CREATe学者Amy Thomas博士和Martin Kretschmer教授发表的最新研究,通过分析全球已知的83份商业协议,首次为我们揭示了这个新兴市场的真实面貌。
让我们跟随这份报告,看看这场价值千亿的牌局中,谁是主要玩家,谁在闷声发大财,以及最重要的——原创者能否从中分一杯羹?
“AI技术的发展是任由技术巨头和数据中间商定义一个“赢家通吃”的未来,还是努力构建一个能够让技术进步反哺内容创作、让价值回归源头的健康生态?”
发现一
AI授权市场正在加速爆发
研究显示,自2022年底ChatGPT发布以来,内容提供商与AI开发者之间的商业协议数量显著增加。特别是从2024年中期开始,交易速度明显加快。
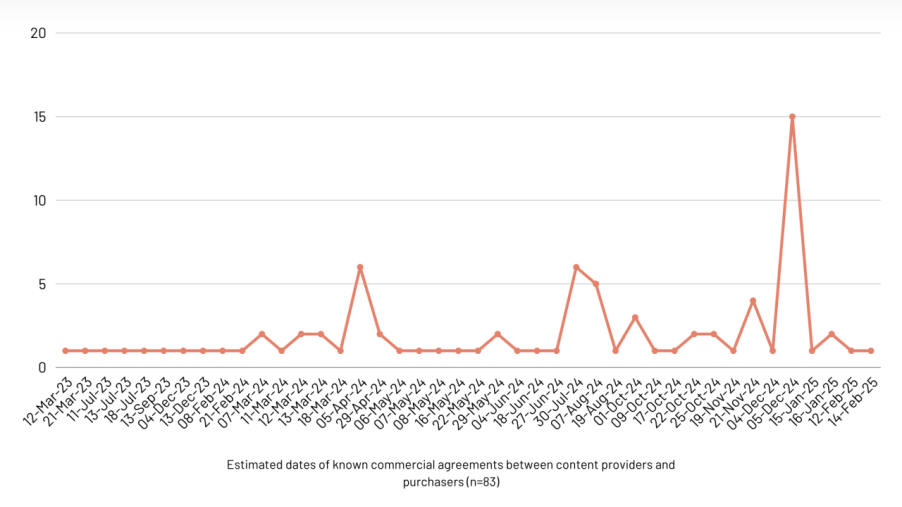
图:已知商业协议的估算日期(n=83),数据来源:create.ac.uk
这背后有两大推手:一是美国的版权诉讼风险,二是欧盟《AI法案》的正式通过。这表明,无论各国政策如何,在主要市场提供生成式AI服务都面临着越来越大的法律风险,促使AI公司开始“花钱买平安”。
发现二
最大买家并非传统“科技巨头”
令人意外的是,在签署授权协议方面,最积极的并非我们熟知的传统科技巨头。
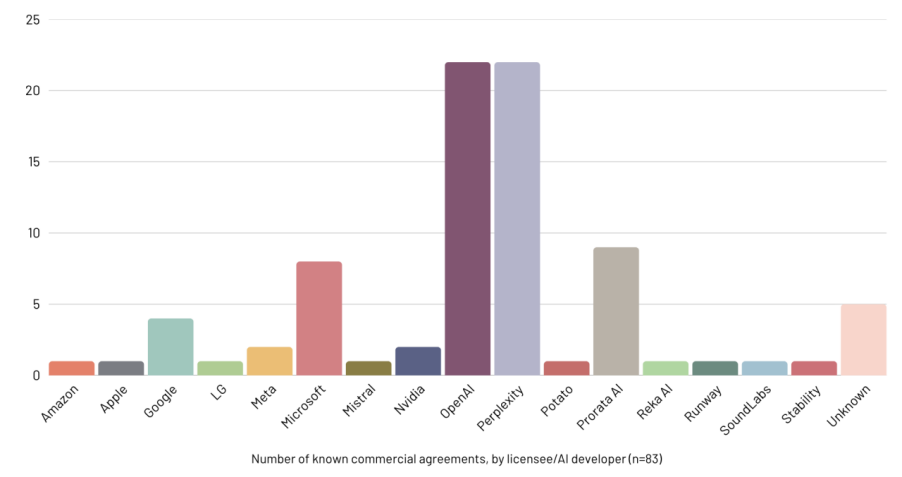
图:各AI开发者/被授权方的已知商业协议数量(n=83),数据来源:create.ac.uk
图表显示,OpenAI和Perplexity是目前已知协议数量最多的两家公司。相比之下,亚马逊、苹果、谷歌、Meta和微软等“老牌巨头”的协议数量反而较少。
研究者推测,这可能是因为这些巨头已经通过其现有服务(如Facebook的用户帖子、谷歌的搜索数据、YouTube的公开视频)获得了海量数据的“隐性授权”,因此无需签署那么多新的商业协议。
发现三
新闻媒体是最大“卖家”,但图片库可能更“赚钱”
那么,谁是AI数据的主要提供方(授权方)呢?
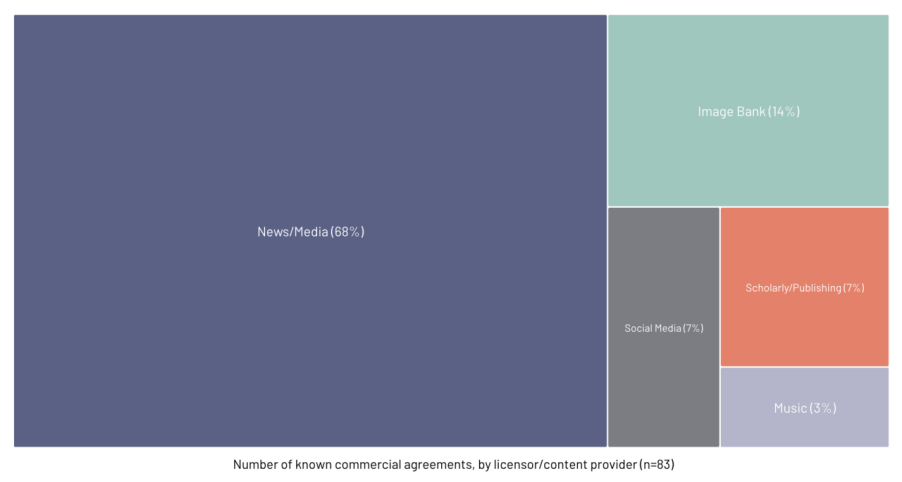
图:各内容提供商/授权方领域的已知商业协议数量(n=83),数据来源:create.ac.uk
数据显示,高达68%的已知商业协议流向了新闻/媒体行业。这符合人们的预期,因为AI模型需要持续获取最新的信息来保证回答的准确性。同时,这也可能与新闻媒体行业在政策层面的积极游说有关。
然而,从已披露的收入来看,情况有所不同。
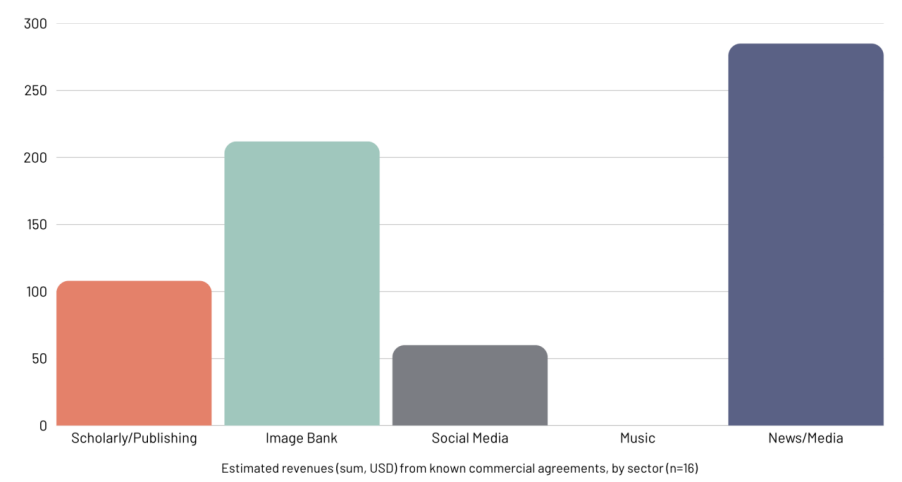
图:各领域的已知商业协议预估总收入(n=16),数据来源:create.ac.uk
尽管新闻/媒体行业的协议数量最多,但图片库(Image Bank)似乎占据了更高的收入份额(约31%),学术/出版领域也占有16%的可观收入。这或许可以解释为什么图片库Shutterstock在授权方面表现得异常积极,已知与7家AI开发者达成了协议,是所有内容提供商中最多的。
发现四
钱如何分配?创作者的利益成谜
这些天价协议的收入将如何分配?这是公众和创作者最关心的问题。研究揭示了两种最主要的合作模式:
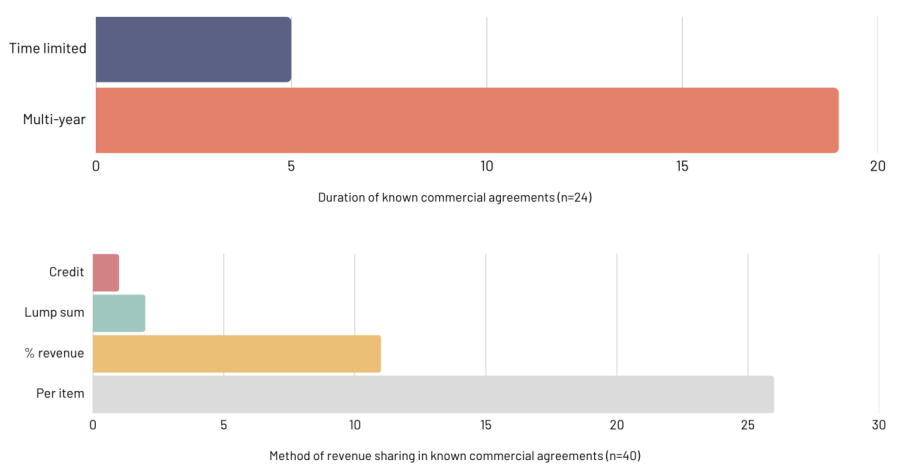
图:协议时长(上,n=24)与收入分成方式(下,n=40),数据来源:create.ac.uk
从时长来看,多年期(Multi-year)协议是主流。从收入分享方式来看,按项目(Per item)计费的模式占比最高,达到65%。
然而,最关键的问题依然悬而未决:这些钱如何才能真正到达一线创作者(如作者、摄影师、艺术家)的手中?
报告指出,尽管许多协议都承诺会将AI带来的收入用于支持原创者,但目前只有两家公司公布了具体机制:
Shutterstock:通过其“贡献者基金”(Contributor Fund)进行分配。
HarperCollins(哈珀柯林斯出版社):如果作者同意其书籍用于AI训练,将一次性支付约2000英镑。
对于大多数“按使用量”计费的协议,如何追踪和分配收益给海量的个人创作者,仍然是一个巨大的挑战。
反思和探讨
一场重新定义“价值”与“公平”的博弈
这份报告给我们敲响了警钟。当我们在讨论是否要建立一个“选择退出”(Opt-out)机制时,一个庞大、成熟且规则由强者书写的授权市场早已在飞速运转。
“选择退出”是真实的权利还是幻觉? 对于大型机构来说,“选择退出”或许是一种谈判筹码。但对于没有资源、没有法务团队的独立创作者,要如何面对全球成千上万个AI模型的爬取,并有效地声明“我的作品不许用”?这在现实中几乎是不可能的任务。
我们需要新的分配模式: 显而易见,现有的版权授权和分配体系已经无法适应AI时代。我们迫切需要探索新的模式,以确保价值链的公平:
强制性透明度: 能否立法要求AI公司详细披露其核心训练数据集的构成?让阳光照进“算法黑箱”是实现公平的第一步。
集体管理与数据信托: 创作者能否组成类似音乐版权协会的“数据合作社”或“信托基金”,集体进行谈判,用共同的力量争取更大的话语权和更公平的条款?
法定许可费/AI税: 是否可以借鉴广播电视支付音乐版税的模式,对AI公司的商业收入征收一定比例的“数据使用费”,然后通过一个独立的、受监督的机构分配给广大创作者?
结语
AI技术的发展不应以牺牲一代创作者的利益为代价。我们正处在一个关键的十字路口:是任由技术巨头和数据中间商定义一个“赢家通吃”的未来,还是努力构建一个能够让技术进步反哺内容创作、让价值回归源头的健康生态?
这不仅是立法者和科技公司的责任,也与我们每一个人息息相关。因为我们既是内容的消费者,也是数据的生产者。如何在这场史无前例的变革中捍卫“人”的价值与创造力,将决定我们未来世界的文化底色。
本文内容经授权编译自Dr Amy Thomas与Prof Martin Kretschmer于2025年2月24日发表的CREATe博客文章《The AI licensing economy》。
原文链接:https://www.create.ac.uk/blog/2025/02/24/the-ai-licensing-economy/
文章作者:Dr Amy Thoms, Prof Martin Kretschmer
文章编辑与审核:李子豪、杨以
声明:本文来自科技法评,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
