工作来源
arXiv:2504.21039
工作背景
人工智能技术已经迅速成为提升生产力的关键技术,大模型进一步加速了这一趋势。但大模型在网络安全中的应用仍然有限,挑战来自诸多方面,例如缺乏公开可用的高质量数据集、模型存在幻觉、分布不均衡等。与此同时,网络安全涉及的领域宽泛且异构,从钓鱼邮件检测到密码学分析,想要开发一个通用的安全 AI 难上加难。简而言之,由于专业训练数据的缺乏以及网络安全特定领域知识表示的复杂性,大模型在网络安全领域的应用程度仍然有限。
工作设计
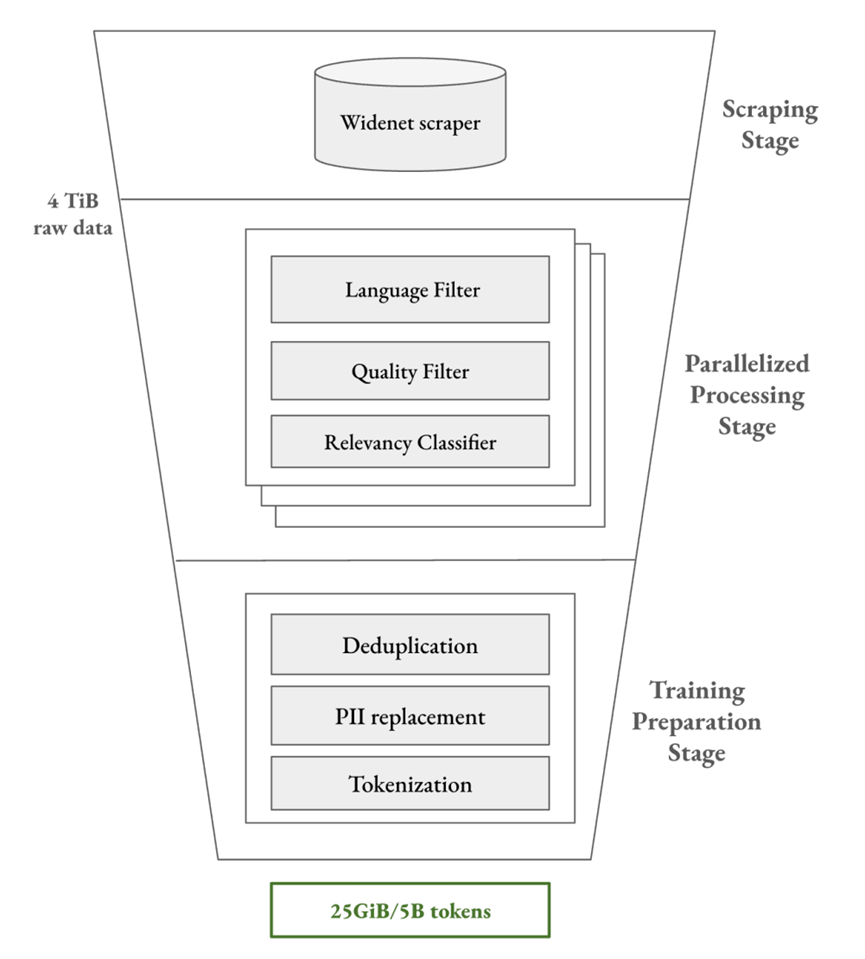
通用大模型的预训练由百亿甚至千亿级 Token 驱动,而网络安全模型目前通常仍在少于 20 亿 Token 的语料上进行训练。基本数据处理流程如下所示:
① 抓取阶段(Scraping Stage):使用通用爬虫和定制化爬虫收集 4TB 网页数据。
② 并行处理阶段(Parallelized Processing Stage):对原始数据进行处理,例如剔除非英语数据、删除低质量内容(通用质量过滤器会将 CVE 描述识别为低质量内容)、相关性分类(关键词过滤存在局限,专门训练了小型 Transformer 分类器)等。
③预训练阶段(Training Preparation Stage):使用 n-gram 布隆过滤器进行去重、替换个人隐私数据等,最终将 4TB 原始数据凝练成 25GB 高质量文本数据,约合 50 亿 Token。
工作准备
主要在两种场景下进行评估:多项选择题(MCQA)与根本原因映射(RCM)。一共使用四个数据集进行评估:CTIBench(网络威胁情报)、CyberMetric(500版本)、SecBench(600版本)与MMLU(非安全类)。这里不对数据集进行过多赘述了,感兴趣的读者自行去搜吧。
在计算集群中使用 DeepSpeed 框架(使用 AdamW 优化器与余弦衰减学习率策略)进行训练,并且为不同类型的模型设计了不同的提示(Prompting)策略。对预训练模型来说,使用 5-shot 提示进行评估,帮助模型推断任务类型和预期的输出格式。对指令微调模型来说,使用 0-shot 提示进行评估,使用正则表达式标准化答案输出。
注:测试进行了十次评估,温度设置为 0 与 0.3。
工作评估
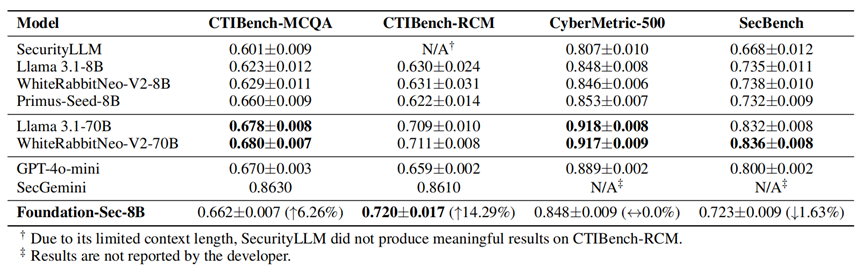
基于 Llama 3.1-8B 构建的 Foundation-Sec-8B 相比同规模的模型,在网络威胁情报领域的表现与 GPT-4o-mini 相当;在 CTIBench-RCM 领域的表现比规模更大的模型还好;在非安全类通用领域的表现比 Llama 3.1-8B 略有下降(模型在获得专业知识的同时,通用能力通常会有轻微的下降)。

除了数据集评估,也进行了实际场景测试:
(1)安全运营中心:自动化处理海量告警,将多源告警以分析人员风格总结成人类可读的事件报告,可以为分析处理提速。
(2)主动威胁防御:从非结构化的分析报告中提取TTP、根据上下文影响和可利用性为漏洞进行优先级排序。
(3)安全合规赋能:支持合规性工作检查,提供开发部署时安全策略指导。
工作思考
Foundation-sec-8b(Llama-3.1-FoundationAI-SecurityLLM-Base-8B)迈出了安全大模型的关键一步,通过构建高质量数据集可以显著提升大模型在网络安全领域的表现。从该文中可以看出,数据工程仍然是构建专业领域大模型的核心,思科对相关性过滤的设计就体现了专业领域的深厚功底,这是通用数据处理方法所不能比拟的。私以为,拥有高质量的数据并且掌握专业领域数据的处理方式,也许可以构筑次时代的核心竞争力。

在通用大模型的基础上进行持续预训练,可能是推出专业领域大模型的高效方法。思科在 2025 年 6 月也宣布已经训练了推理模型(Foundation-sec-8b-reasoning),推理应该是大模型的基础能力而非可选功能。随着高质量数据的数据规模扩大以及模型维度的进一步提升,安全大模型可能会带来更多令人惊艳的表现。
声明:本文来自威胁棱镜,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
