
原文标题:Predictive Context-sensitive Fuzzing原文作者:Pietro Borrello, Andrea Fioraldi, Daniele Cono D’Elia, Davide Balzarotti, Leonardo Querzoni, Cristiano Giuffrida
原文链接:https://dx.doi.org/10.14722/ndss.2024.24113发表会议:NDSS 2024笔记作者:王彦@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1 总体介绍
模糊测试是一种通过随机生成输入发现程序漏洞的关键技术,覆盖引导模糊测试(CGF)尤其受到关注,它通过追踪执行路径中的代码覆盖情况来指导输入生成。传统CGF通常只关注执行路径的“覆盖到哪”,但忽视了“如何到达”某位置的调用上下文,这种上下文的缺失可能导致许多依赖程序状态的漏洞无法触发。
为了克服上述问题,研究者尝试引入上下文敏感性。比如ANGORA等模糊器引入了调用栈哈希作为上下文的标识,但这带来了两个问题:一是哈希碰撞使得不同上下文可能被当作相同处理;二是状态爆炸使模糊器记录并保留大量冗余测试用例,严重影响效率。现有上下文敏感方案大多无法有效兼顾精度和性能。
本文提出的“预测性上下文敏感模糊测试”通过三个关键设计避免了上述难题:首先采用函数克隆机制,避免哈希碰撞;其次使用静态数据流分析来识别值得增加上下文敏感性的调用点,从而限制克隆数量;最后提供LLVM实现并在FuzzBench上验证其显著优越性。该方法成功发现8个长期存在但此前未被识别的漏洞,其中6个已获得CVE编号。
2 背景知识
覆盖引导模糊测试是目前最广泛使用的技术之一,它使用代码覆盖作为反馈信号,引导输入生成,常见的如AFL和LibFuzzer。具体而言,现代CGF通过边覆盖(edge coverage)记录基本块之间的执行路径。然而,这种基于哈希的覆盖记录方法存在碰撞问题,不同路径可能映射到相同的覆盖条目,从而漏掉有价值的测试用例。
上下文敏感性在程序分析领域是指考虑函数调用路径的差异,这对于识别某些状态依赖性漏洞非常重要。例如,在静态分析和优化中,使用上下文敏感分析可以极大提升分析精度。类似ANGORA的方法尝试在模糊测试中引入上下文信息,但由于使用的是哈希堆栈,容易产生碰撞,导致上下文信息失真。
指针分析(points-to analysis)是一种静态分析方法,用于确定指针变量可能指向的抽象对象。在本文中,作者使用指针分析来评估调用点的参数对象流动性,以预测哪些调用点的数据流差异足够大,值得进行函数克隆处理。
3 方案设计
本文的方案建立在三个核心设计之上:函数克隆、上下文敏感选择机制以及基于数据流多样性的优先级预测。
函数克隆是该方法的基础机制。通过为特定调用点创建函数的克隆版本,并将调用重定向至克隆体,模糊器无需运行时追踪上下文即可实现上下文敏感性。这种设计天然避免了覆盖映射中的哈希碰撞。例如,若函数parse_seg从两个不同调用路径被调用,则为其生成parse_seg_clone1与parse_seg_clone2,模糊器可自动分辨两者路径。
但全面克隆将导致状态空间膨胀,产生效率问题。为此,作者提出一种静态分析驱动的预测策略,仅对那些参数对象数据流差异显著的调用点进行克隆。该策略依赖points-to分析结果,计算每个调用点的参数所引用的对象集合,并根据其与其他调用点的重合程度评估其克隆价值。公式如下:
其中 是该函数的调用点总数, 是当前调用点的抽象对象集合, 是包含对象 , 的其他调用点数量。该值越高,代表该调用点的数据流越独特,越值得被克隆。
4 实验评估
实验评估与结果分析
作者在FuzzBench基准测试平台上对四种模糊测试配置进行了全面评估:传统上下文敏感方法(context)、无上下文优化的LTO方案(lto)、随机克隆策略(random)以及本文提出的预测性方法(predictive)。实验选取了16个广泛使用的开源项目作为测试对象,每个配置运行20次24小时的测试。
漏洞发现能力对比
图2通过箱线图直观展示了各模糊器在不同项目中的漏洞发现表现。整体来看,predictive方法在大多数项目中展现出显著优势。以libxml2为例,predictive发现了22个漏洞,远超context的3个和lto的16个。综合所有测试项目,predictive共发现125个唯一漏洞,较lto(112个)提升11.6%,较context(102个)提升22.55%(详见表III)。
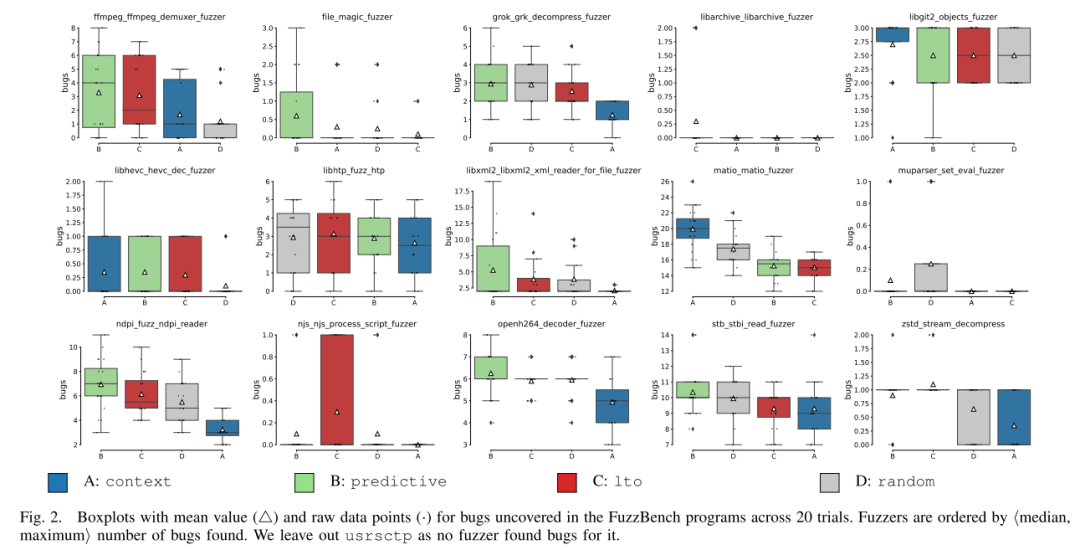
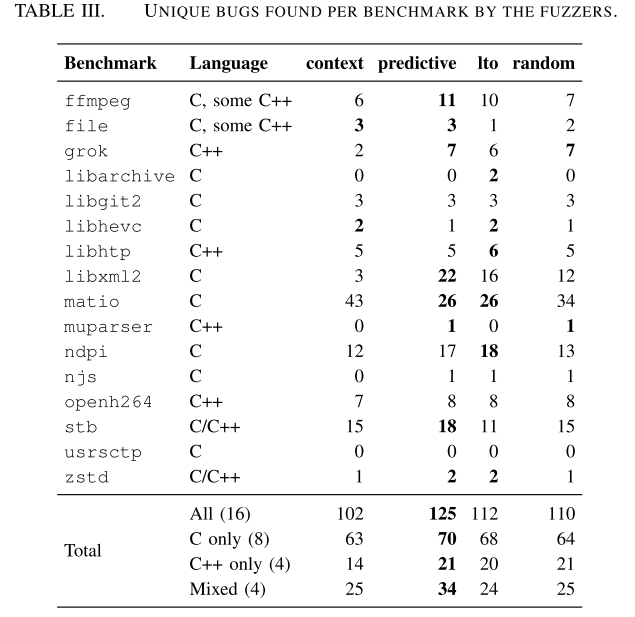
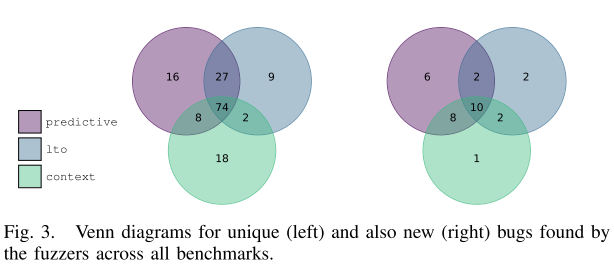
通过图3的韦恩图可以更深入分析这些漏洞的分布特征。值得注意的是,predictive发现的漏洞中有43个是context未能检测到的,其中14个漏洞的崩溃调用栈中直接包含了被克隆的函数,这验证了选择性克隆策略在触发异常程序状态方面的有效性。
性能开销分析
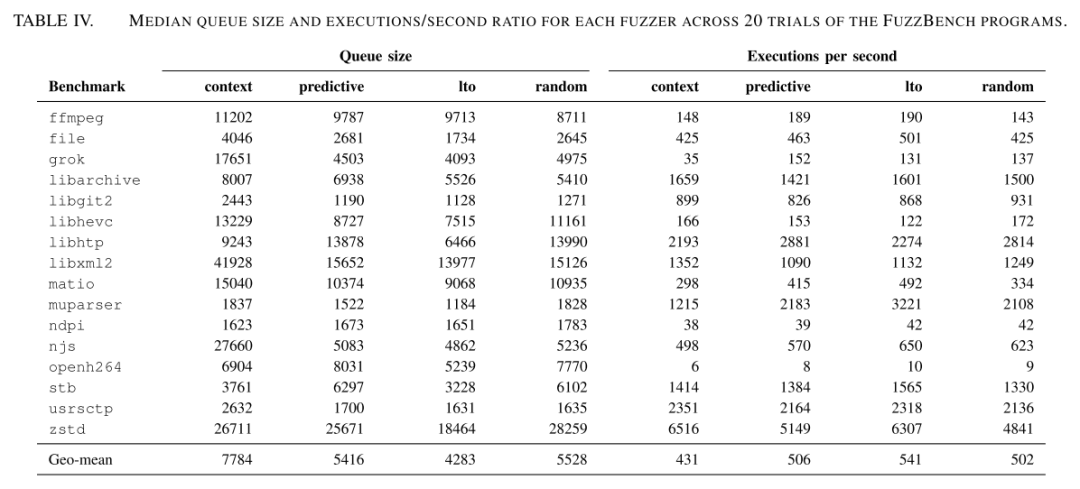
表IV详细对比了各方案的系统资源消耗。由于采用了全上下文追踪,context方案出现了明显的状态爆炸问题,测试队列平均膨胀81.7%,而predictive通过选择性克隆将队列增长控制在26.4%。在吞吐量方面,predictive仅造成6.5%的性能下降,远优于context的20.3%降幅,这得益于其精心设计的预算控制机制。
覆盖映射效率
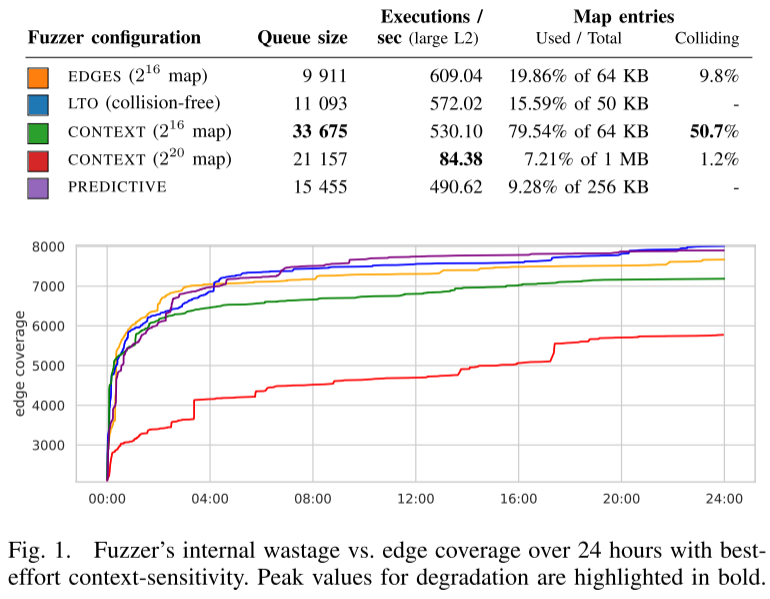
图1的数据揭示了各方案在覆盖映射使用效率上的关键差异。传统context(2^16映射)出现了严重的哈希碰撞问题,映射占用率达79.5%,碰撞率高达50.7%。相比之下,predictive的映射使用率仅为9.3%,且几乎不存在碰撞,展现出优异的可扩展性。这种差异直接解释了为何predictive能在保持高性能的同时,实现更精准的漏洞检测。
5 结论
本文提出的预测性上下文敏感模糊测试方法,通过函数克隆实现碰撞规避,并结合静态数据流分析进行克隆点预测,既解决了传统上下文模糊测试中的碰撞与状态爆炸问题,又显著提升了漏洞发现能力。在FuzzBench上的实验证明,该方法在效率与效果之间找到了最佳平衡点,发现了多个此前未被检测到的真实漏洞,展现出强大的实际应用潜力。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
