
原文标题:A novel approach for classification of Tor and non-Tor traffic using efficient feature selection methods
原文作者:Raju Gudla, Satyanarayana Vollala, Srinivasa K.G., Ruhul Amin
原文链接:https://www.sciencedirect.com/science/article/abs/pii/S0957417424004093
发表平台:Expert Systems with Applications, 2024
笔记作者:孙汉林@安全学术圈
主编:黄诚@安全学术圈
1、引言
本文针对加密通信环境中流量分析与分类的重要问题,提出了一种高效的Tor流量分类方法。该方法基于University of New Brunswick (UNB)提供的Tor-nonTor数据集,利用CICFlowMeter进行预处理,并结合PCA与t-SNE等特征选择技术,以降低数据维度并提升分类效率。在分类模型方面,采用了支持向量机(SVM)、梯度提升(Gradient Boosting)、随机森林(Random Forest)与人工神经网络(ANN)等多种机器学习算法。实验结果表明,该方法在Tor流量识别中实现了1.00的召回率,有效提升了分类准确性,同时大幅减少了分类时间,展示出在时间敏感场景下的实用价值。
2、方案设计
本方案分为4部分,首先是数据集分类,接着是数据预处理,然后是数据降维,最终是分类器训练与测试,具体过程如下图所示。
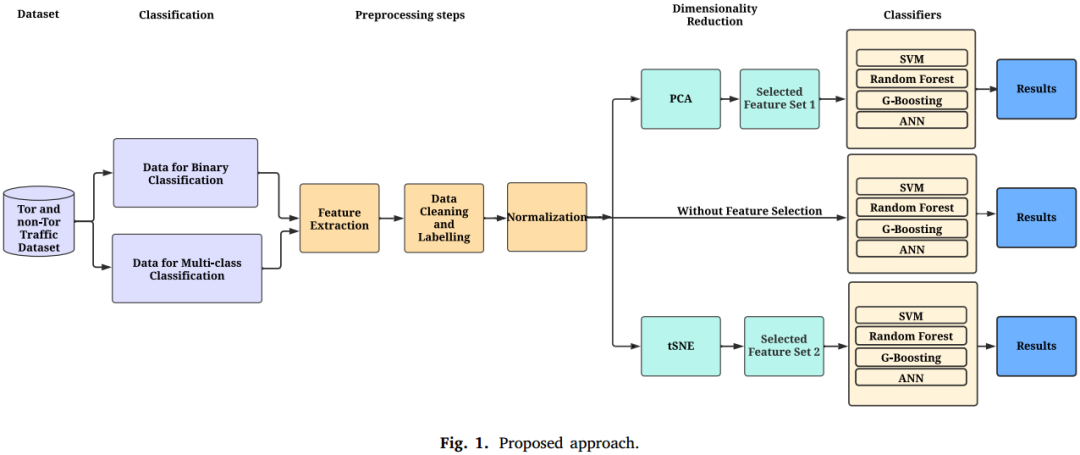
2.1 数据集分类
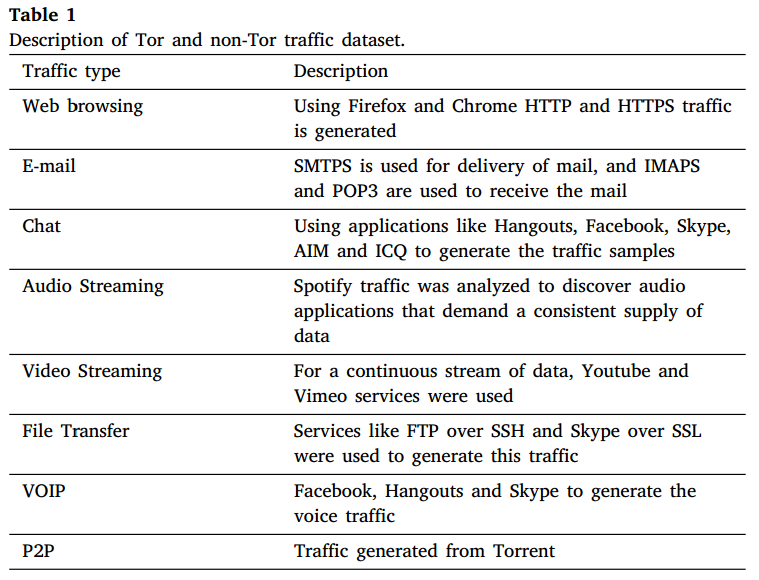
本文采用了UNB提供的Tor-nonTor流量数据集,该数据集包含超过18个真实应用(如Skype、Facebook、Gmail、Spotify等)的网络流量,具体信息如下表所示。根据分类任务的不同(二分类和多分类),划分为两类数据集。
2.2 数据预处理
数据预处理主要包括:特征提取、数据清洗与标注、归一化三部分,下面对每一部分做进一步说明。
特征提取: 本文使用CICFlowMeter工具对PCAP格式的原始流量数据进行处理,将其转换为包含每个网络包统计特征的CSV文件。该工具支持根据流量方向提取超过25项统计特征,用于构建基于流的分析。处理后的特征数据用于构建训练数据集,以支持后续的分类任务。
数据清洗与标注: 转换后的CSV数据初始无标签,需要根据流量所属应用类型进行标注并合并多个文件。随后,执行特征筛选和清洗,去除无关、缺失或错误的列。为解决类别不平衡问题,采用SMOTE技术生成少数类的合成样本,改善训练集分布。此外,使用标签编码(Label Encoding)将“Tor”和“non-Tor”等文本类别转换为“0”和“1”,使其适用于监督学习算法,支持二分类与多分类任务。
归一化: 为了避免特征间因数值差异而引发的偏差,本文对数据进行归一化处理。采用Z-score方法将每个特征缩放至均值为0、标准差为1的分布区间,提升模型对特征间距离的计算准确性,从而提高分类效果。
2.3 数据降维
降维通过特征选择和特征提取,从高维数据中提取出更少但更有代表性的特征,以降低计算成本并提升分类性能。本文在分类任务中引入Principal Component Analysis(PCA)与t-Distributed Stochastic Neighbor Embedding(t-SNE)两种降维方法,具体解释如下。
PCA: PCA是一种线性降维技术,通过将高维数据投影到少数几个主成分上,最大化数据的方差,从而减少特征数量。它保留了数据的全局结构,计算效率高且实现简单,适合处理大规模高维数据,能够加快模型的训练和推理速度,同时保证信息损失最小。
t-SNE: t-SNE是一种非线性降维方法,重点保留数据的局部结构,通过构建高维和低维空间中数据点的相似度分布,并最小化两者之间的KL散度,实现对复杂数据的有效可视化。t-SNE特别适合揭示数据中的簇结构和隐藏模式,便于探索和分析高维数据的内在关系。
2.3 分类器训练与测试
本文选用了4种分类器算法:支持向量机(SVM)、随机森林(Random Forest)、梯度提升(Gradient Boosting)和人工神经网络(ANN)。其中,SVM通过寻找区分数据类别的超平面进行分类,适用于二分类和多分类问题,但计算复杂度较高,适合较小数据集。随机森林由多个决策树组成,通过多数投票提高分类准确率,适合处理多样化特征,但在大规模数据集上计算开销较大。梯度提升通过逐步纠正前一模型误差,集成多个弱分类器,提升整体性能,且在小数据集上计算效率较高。人工神经网络模拟人脑神经结构,通过层级节点和激活函数处理输入数据,具备处理复杂非线性问题的能力,适用于二分类和多分类任务。
参数调节方面,SVM采用线性核并按8:2划分训练测试集,强调线性决策;随机森林设置100棵树和多项控制深度与分裂的参数;梯度提升调节学习率、树数和正则化参数;神经网络配置为三层结构,采用ReLU与Sigmoid激活函数、Adam优化器和二元交叉熵损失函数。通过系统调参,优化模型的准确率、泛化能力与鲁棒性。
3、实验结果与分析
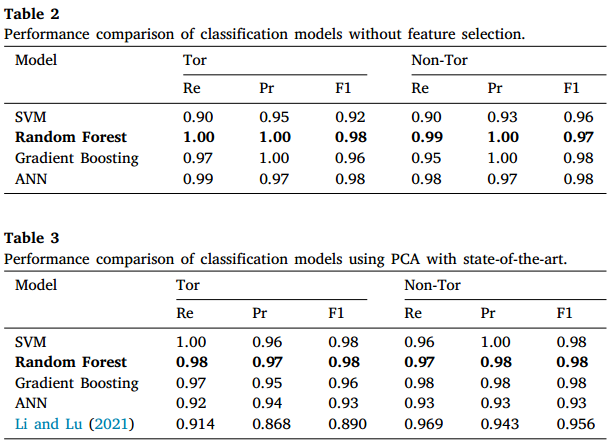
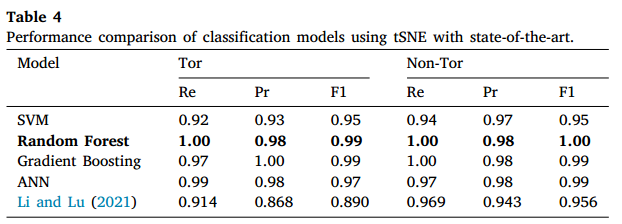
二分类方面,未进行特征选择时,随机森林和梯度提升在Tor与非Tor流量分类中表现优异,精确率达到1.00,人工神经网络在召回率上表现突出。采用PCA降维后,随机森林、梯度提升和SVM的性能均超越了人工神经网络及现有先进方法,SVM在Tor流量召回率上达到1.00,明显优于现有技术。使用t-SNE降维时,随机森林、梯度提升和人工神经网络均显著优于SVM和现有方法,随机森林在多个指标上表现最佳,整体性能领先于其他分类算法和现有技术,具体如下表所示。
多分类方面,随机森林和梯度提升在包括Char、E-mail、FTR等多个流量类别的分类中表现优于SVM,尤其是在t-SNE降维条件下效果更佳。SVM在P2P、VOIP、Video等加密流量类别上的表现较差,且通常需要通过多次二分类实现多分类,效率较低。未进行特征选择时,随机森林和梯度提升的分类效果优于采用PCA和t-SNE降维的模型。总体来看,随机森林和梯度提升因能够有效结合数值和类别特征,分类性能优越,而SVM侧重于最大化数据点间距,导致其多分类性能不及前者。在准确率、精确率、召回率和F1分数等多项指标上,随机森林和梯度提升表现均明显优于SVM,且随机森林结合t-SNE的效果最佳。具体如下表所示。
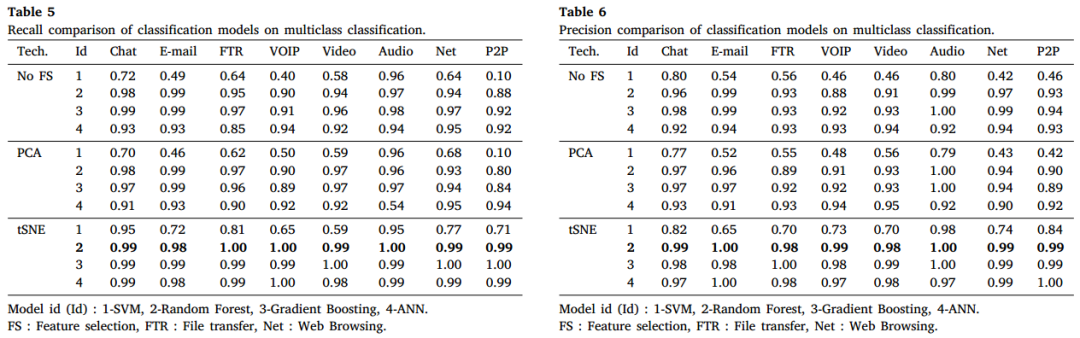
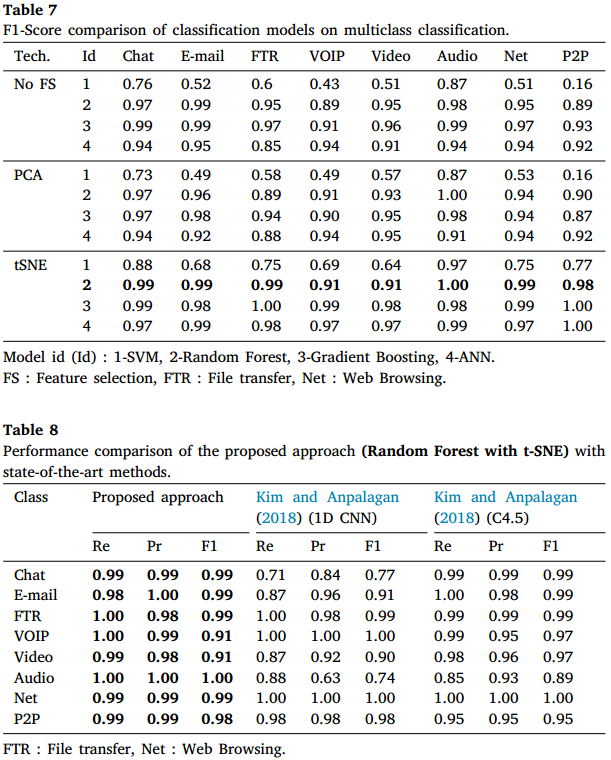
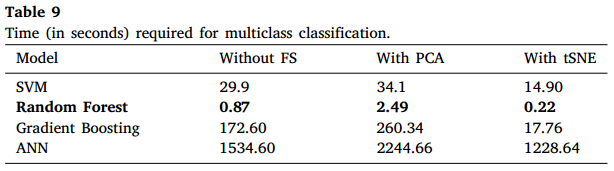
此外,不同分类器的耗时如下表所示。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
