
原文标题:TF-Attack: Transferable and Fast Adversarial Attacks on Large Language Models
原文作者:Zelin Li , Kehai Chen , Lemao Liu , Xuefeng Bai ,Mingming Yang , Yang Xiang , Min Zhang
原文链接:https://www.sciencedirect.com/science/article/abs/pii/S0950705125001649
发表期刊:Knowledge-Based Systems
笔记作者:谢启亮@安全学术圈
主编:黄诚@安全学术圈
编辑:张贝宁@安全学术圈
1、背景介绍
随着大型语言模型(LLMs)的巨大进步,针对LLMs的对抗攻击最近引起了越来越多的关注。我们发现,先前存在的对抗攻击方法在应用于LLMs时,表现出有限的可迁移性并且效率显著低下。 最近,像ChatGPT和LLaMA这样的大型语言模型(LLMs)在各种下游任务中展现出了巨大的潜力。因此,对抗攻击任务也受到了越来越多的关注,其目的是生成能够混淆或误导LLMs的对抗样本。这项任务对于在AI社区推进可靠和鲁棒的LLMs至关重要,强调了AI系统中安全性的至高重要性。 现有主流的针对LLMs的对抗攻击方法通常遵循两步过程:首先,它们基于受害者模型对词符(token)重要性进行排序,随后,它们按照特定规则顺序替换这些词符。尽管取得了显著的成功,但最近的研究强调当前方法面临两个实质性限制:
生成的对抗样本的可迁移性较差。如表1所示,虽然模型生成的对抗样本可以大幅降低其自身的分类准确性,但它们几乎不影响其他模型;
时间开销巨大,特别是在大型语言模型上。例如,在LLaMA上进行一次攻击所需的时间比标准推理慢30倍。
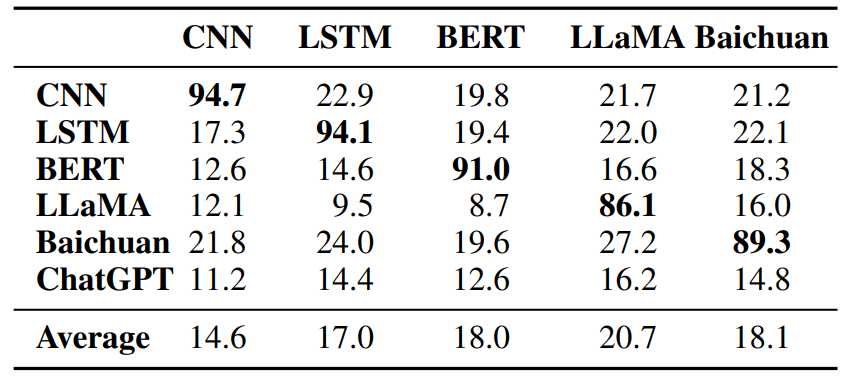 (表1:BERT-Attack样本在IMDB数据集上的可迁移性评估。第i行和第j列是模型j生成的样本在模型i上评估的攻击成功率。平均结果来自每列的非对角元素。)
(表1:BERT-Attack样本在IMDB数据集上的可迁移性评估。第i行和第j列是模型j生成的样本在模型i上评估的攻击成功率。平均结果来自每列的非对角元素。)
动机
本文分析了先前主流对抗攻击方法的核心机制,揭示了:
不同受害者模型的重要性分数分布差异显著,这限制了可迁移性;
顺序攻击过程导致了大量的时间开销。
为了解决上述两个问题,我们首先分析了现有对抗攻击方法可迁移性差和速度慢的原因。具体来说,我们首先研究了重要性分数的影响,这是先前方法的核心机制。比较分析揭示了不同受害者模型之间存在显著不同的重要性分数分布。这种差异在很大程度上解释了为什么现有方法生成的对抗样本可迁移性较差,因为根据一个模型的特定模式生成的扰动不能很好地推广到具有不同重要性分配的其他模型。此外,对图3中时间消耗的分析表明,在攻击LLMs时,超过80%的处理时间花费在顺序的逐词操作上。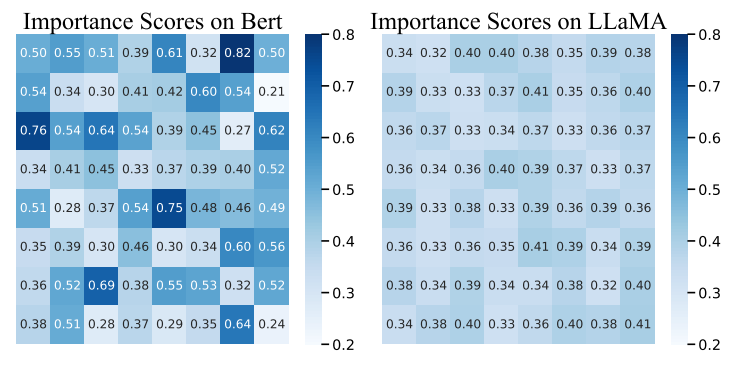 (图1:BERT和LLaMA上BERT-Attack给出的相同句子的重要性分数分布。)
(图1:BERT和LLaMA上BERT-Attack给出的相同句子的重要性分数分布。)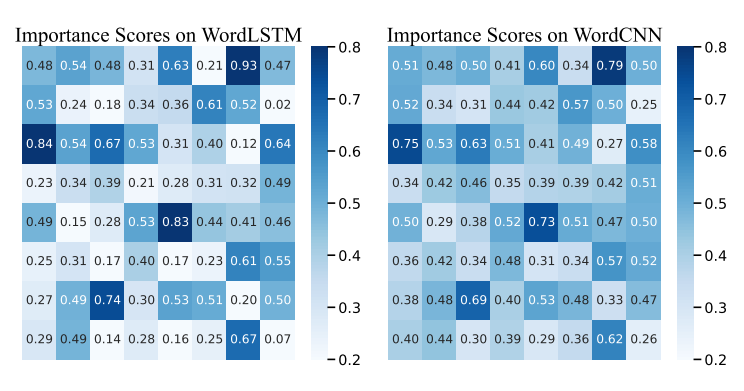 (图2:WordCNN和WordLSTM上BERT-Attack给出的相同句子的重要性分数分布。)
(图2:WordCNN和WordLSTM上BERT-Attack给出的相同句子的重要性分数分布。)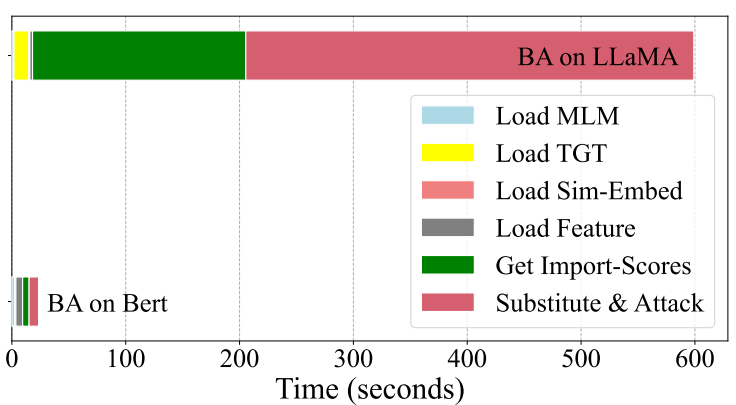 (图3:BERT-Attack在SA-LLaMA和BERT上各模块的时间成本。)
(图3:BERT-Attack在SA-LLaMA和BERT上各模块的时间成本。)
2、本文方法
基于以上两个见解,我们引入了一种名为TF-ATTACK的新方案,用于对LLMs进行可迁移且快速的对抗攻击。TF-ATTACK遵循BERT-Attack的总体框架,通过同义词替换生成对抗样本。与BERT-Attack不同,TF-ATTACK采用外部第三方监督者(如ChatGPT)来识别输入句子中的重要单元,从而消除了对受害者模型的依赖。此外,TF-ATTACK引入了重要性级别(Importance Level)的概念,该概念根据输入单元的语义重要性将其划分为不同的组。具体来说,我们利用ChatGPT强大的抽象语义理解和高效的自动提取能力,通过人工精心设计的集成提示(Ensemble Prompts)形成一个重要性级别优先队列。基于此,TF-ATTACK可以在同一优先级队列内并行替换整个单词,而不是像传统方法那样逐个顺序替换,如图4所示。这种方法显著减少了攻击过程的时间,从而带来了显著的速度提升。此外,我们采用了两种技巧,名为多重扰动(Multi-Disturb)和动态扰动(Dynamic-Disturb),以增强生成的对抗样本的攻击有效性和可迁移性。前者在同一句子内引入三个级别的扰动,而后者根据输入句子的长度动态调整三种类型扰动的比例和阈值。它们显著提高了攻击的有效性和可迁移性,并且可以适应其他攻击方法。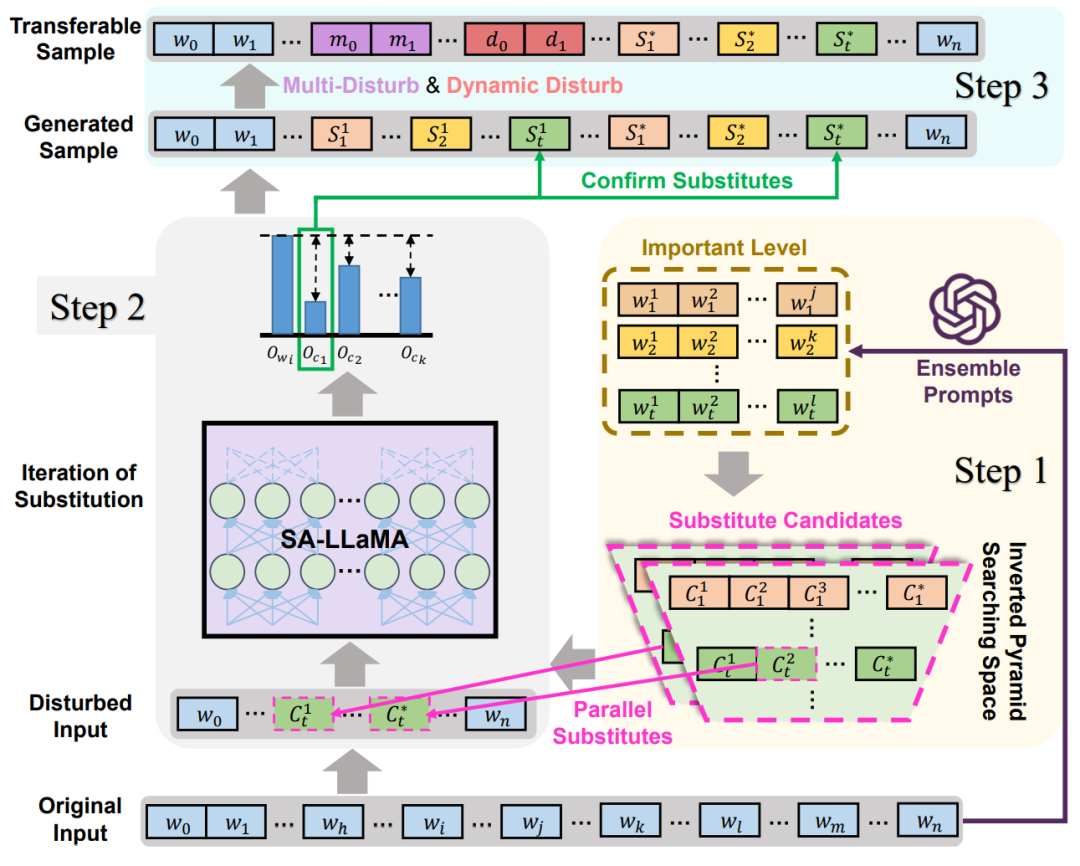 (图4:步骤1:使用ChatGPT将单词按词频分为5个重要性级别。倒金字塔搜索空间反映了基于级别降低的候选替换词长度的减少。步骤2:从同一级别选择单词并通过并行替换生成扰动输入。通过SA-LLaMA探索可能的扰动输入,选择超过阈值的结果作为确认替换生成的样本。当满足完成条件时,替换迭代将结束。步骤3:实施多重扰动和动态扰动产生可迁移样本。)
(图4:步骤1:使用ChatGPT将单词按词频分为5个重要性级别。倒金字塔搜索空间反映了基于级别降低的候选替换词长度的减少。步骤2:从同一级别选择单词并通过并行替换生成扰动输入。通过SA-LLaMA探索可能的扰动输入,选择超过阈值的结果作为确认替换生成的样本。当满足完成条件时,替换迭代将结束。步骤3:实施多重扰动和动态扰动产生可迁移样本。)
3.1 初步知识:对抗攻击
对抗攻击的任务旨在对输入产生扰动,从而误导模型的输出。这些扰动可能非常小,并且人类难以察觉。 对于NLP任务,给定一个包含 个输入文本的语料库 ,以及一个包含 个标签的输出空间 ,语言模型 学习一个映射 ,该映射学习将每个输入样本 分类到真实标签 :
文本 的对抗可以表示为 ,其中 是对输入 的扰动。目标是在一定的约束 内误导受害者语言模型 :
其中 λ 是系数, 通常通过输入 与其对应的对抗 之间的语义或句法相似性来计算。
3.2 重要性分数的局限性
现有主流的针对LLMs的对抗攻击系统(Morris等人[1],2020;Jin等人[2],2020;Li等人[3],2020)通常遵循两步过程。我们因此以BERT-Attack(Li等人,2020)作为代表性方法进行分析。BERT-Attack的核心思想是根据重要性分数(Importance Score)进行替换。BERT-Attack通过单独屏蔽输入文本中的每个单词,为每个单词执行一次推理,并使用置信度分数和受害者模型标签的变化来确定每个单词的影响。在BERT-Attack中,重要性分数决定了后续的攻击序列,这对于后续攻击的成功和攻击次数至关重要。
为了探究依赖重要性分数的方法的可迁移性有限的问题,我们分析了不同模型的重要性分数分布。如图1所示,当使用BERT和LLaMA计算时,从同一句子派生的重要性分数存在显著差异。前者具有更尖锐的分布,而后者基本上缺乏显著的数值差异。这种现象在多个句子中是一致的。图2显示了由BERT-Attack在WordCNN和WordLSTM上给出的相同句子的不同重要性分数分布。
鉴于重要性分数在上述方法的攻击过程中至关重要,这些分数的变化可能导致完全不同的对抗样本。这种变化解释了生成的对抗样本可迁移性差的原因,如表1所示。
3.3 TF-ATTACK: 针对LLMs的可迁移且快速的对抗攻击
为了解决由重要性分数机制引起的上述限制,我们引入TF-ATTACK作为一种可迁移且快速的对抗攻击解决方案。首先,如图4所示,TF-ATTACK采用外部模型作为第三方监督者来识别重要单元。通过这种方式,TF-ATTACK在攻击过程中避免了对受害者模型的过度依赖。具体来说,我们设计了表11中的几个指令,用于ChatGPT根据其语义重要性将原始输入中的所有单词划分开。TF-ATTACK的另一个优点是它能够利用ChatGPT中丰富的语义知识,使得后续生成的攻击序列在语义上更具普遍性。在速度方面,这种方法不需要从受害者模型进行推理,从而缓解了LLMs高推理成本的问题。TF-ATTACK只需要一次推理即可获得全面的重要性级别优先队列,而传统方法需要的推理次数与文本长度成正比。
其次,TF-ATTACK引入了重要性级别(Importance Level)的概念以促进并行替换。具体来说,TF-ATTACK将原始句子作为输入,并输出一个包含5个级别的优先队列,每个级别包含不同数量的单词。重要性级别的概念假设同一级别内的单词没有特定顺序,从而允许在同一级别内并行替换候选单词。这种并行替换过程显著减少了搜索空间和所需的推理次数,与之前依赖贪婪、顺序单词替换的方法相比,提供了实质性的改进。
此外,我们对重要性级别采用倒金字塔搜索空间(reverse pyramid search space)策略,优化搜索空间以减少低效的搜索开销。优先级较高的单词被认为对句子情感有显著影响。因此,利用较大的搜索空间来识别语义相似的单词,目的是用能够导致受害者模型性能显著下降的同义词替换它们。对于优先级较低的单词,较小的搜索空间就足够了,因为对这些单词的更改对句子情感影响最小。在这些级别上过度搜索会导致推理成本增加,而不会显著提高有效性。
3.4 多重扰动与动态扰动
在上述方法的基础上,为了进一步增强对抗攻击样本的鲁棒性,我们策略性地提出了两种优化技巧。我们使用9种扰动方式,包括字符级、词级和句子级的扰动,如表2所示。然而,如何设置这三种类型扰动的比例在很大程度上决定了生成的攻击样本的可迁移性质量。因此,提出了以下策略。 (表2:九种不同扰动方法的三种类型。)
(表2:九种不同扰动方法的三种类型。)
在评估攻击样本是否有效的步骤中,传统的攻击方法几乎完全依赖模型输出的置信度,这种做法无疑会促进攻击样本对模型架构的过拟合。因此,在确定替换有效性的过程中,我们引入随机扰动来降低模型置信度。这可能会导致一些已经成功攻击的样本丢失,但也防止了攻击在特定受害者模型上成功后停止的现象。传统方法严重依赖模型置信度,导致过拟合。为了解决这个问题,我们在有效性评估期间引入随机扰动,降低模型置信度。这可能会牺牲过去成功的攻击,但可以防止对受害者模型成功后的依赖。
这两种策略可以作为后处理步骤整合到传统的文本对抗攻击方法中,从而显著提高对抗样本的可迁移性。具体来说,多重扰动(Multi-Disturb)策略是指在同一句子内引入多种扰动。表2列出了9种扰动方式,包括字符级、词级和句子级扰动,可以极大地增强攻击样本的可迁移性。动态扰动(Dynamic-Disturb)是指使用FFN+Softmax网络评估输入句子的长度和结构分布,输出这三种类型扰动的比例。
在评估攻击样本有效性时,传统方法严重依赖模型输出置信度,可能导致对模型架构的过拟合。为了纠正这个问题,我们在替换评估期间引入随机扰动以降低模型置信度。我们的实验证实,这两种技巧几乎可以适应所有文本对抗攻击方法,通过自适应后处理显著增强可迁移性并增加对抗样本混淆模型的能力。
4、评估
4.1 实验设置
任务和数据集: 遵循(Li等人,2020),我们在涵盖新闻主题、句子级情感分析和文档级情感分析的各种数据集上评估了所提出的TF-ATTACK在分类任务上的有效性。对于文本蕴含,我们使用了句子对数据集和多类型数据集。遵循,我们从每个任务的测试集中随机选择1k个样本进行攻击。数据集的统计数据和更多细节可以在表3中找到。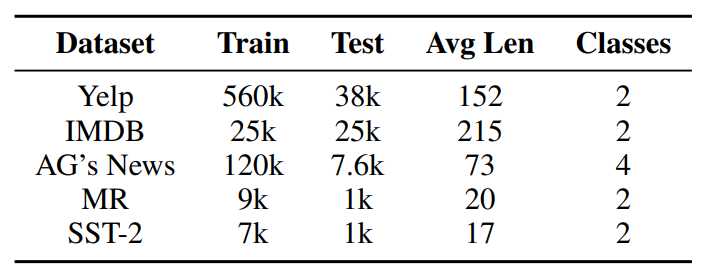 (表3:数据集的总体统计数据。)
(表3:数据集的总体统计数据。)
基线:我们将TF-ATTACK与最近的研究进行比较:
TextFooler,它通过概率加权的词显著性找到重要词,然后使用反拟合词嵌入进行替换。
BERT-Attack,它使用掩码预测方法生成对抗样本。
SDM-Attack,它采用强化学习来确定攻击序列。我们在实验中使用了官方代码BERT-Attack和TextAttack工具 (Morris等人,2020) 进行攻击。TF-ATTACK (zero-shot) 表示在使用ChatGPT生成重要性级别时没有提供演示示例。相反,TF-ATTACK (few-shot) 使用五个演示作为上下文信息。为确保公平比较,我们遵循 (Morris等人,2020) 对TF-ATTACK应用约束。
实现细节: 遵循既定的训练协议,我们微调了一个LLaMA-2-7B模型来开发专门针对特定下游任务的Task-LLaMA模型。其中,在IMDB训练集上微调的Task-LLaMA在测试集上实现了96.95%的准确率,超过了使用额外数据的XLNET(96.21%)。该模型在另一个情感分类数据集SST-2上实现了93.63%的准确率,表明Task-LLaMA没有过拟合训练数据,而是为实验提供了强大的基线。
自动评估指标: 遵循先前的工作 (Jin等人,2020;Morris等人,2020),我们使用以下指标评估结果:
攻击成功率 (A-rate):攻击后模型性能下降的百分比;
修改率 (Mod):与原始文本相比,更改单词的百分比;
语义相似性 (Sim):通过通用句子编码器计算原始文本和对抗文本之间的余弦相似性;
可迁移性 (Trans):对抗样本和原始样本之间三个模型的平均准确率下降。
人工评估指标: 遵循 (Fang等人[5],2023),我们从三个具有挑战性的方面进一步手动验证对抗样本的质量。
人类预测一致性 (Con):人类判断与真实标签的一致性程度;
语言流畅性 (Flu):在1到5的等级上衡量句子连贯性 ;
语义相似性 (Sim_hum):衡量输入-对抗对之间的一致性,1表示一致,0.5表示模糊,0表示不一致。
4.2 整体性能
表4显示了不同系统在四个基准测试上的性能。如表4所示,TF-ATTACK在攻击LLaMA时始终实现最高的攻击成功率,并且对Mod和Sim的负面影响很小。此外,TF-ATTACK在修改率和相似性指标方面大多获得最佳性能,除了AG"s News,TF-ATTACK在其中排名第二。总的来说,我们的方法可以同时满足高攻击成功率、低修改率和高相似性的要求。我们还观察到TF-ATTACK在二元分类任务上取得了更好的攻击效果。根据经验,当存在两个以上类别时,每个替换词的影响可能会偏向不同的类别,从而导致扰动率增加。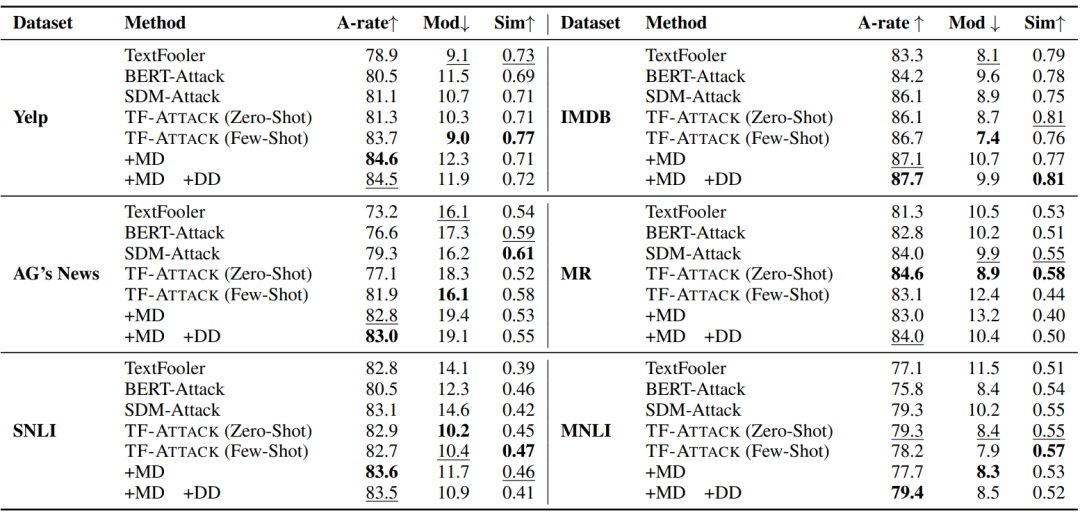 (表4:SA-LLaMA上攻击成功率 (A-rate)、修改率 (Mod) 和语义相似性 (Sim) 的自动评估结果。↑ 表示越高越好,↓ 表示越低越好。最好的结果用粗体显示,次好的结果用下划线显示。)
(表4:SA-LLaMA上攻击成功率 (A-rate)、修改率 (Mod) 和语义相似性 (Sim) 的自动评估结果。↑ 表示越高越好,↓ 表示越低越好。最好的结果用粗体显示,次好的结果用下划线显示。)
在表5中,我们评估了攻击顺序的有效性。利用随机攻击序列会导致攻击成功率降低和修改率显著增加,以及句子相似性的严重破坏。这意味着每个攻击路径都是随机的,并且大量的推理开销浪费在徒劳的尝试上。尽管我们遵守传统文本对抗攻击领域的阈值约束,但文本仍然可以被成功攻击。然而,在高修改率和低相似性的条件下,文本已经与其原始语义发生了显著改变,这违背了任务的目的。此外,随机攻击序列在攻击速度方面会产生大量额外成本,导致时间延迟几乎翻倍。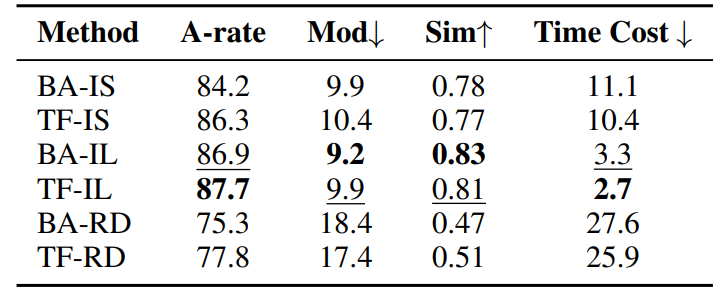 (表5:SA-LLaMA上攻击成功率 (A-rate)、修改率 (Mod)、语义相似性 (Sim) 和时间成本 (Time Cost) 的自动评估结果。↑ 表示越高越好,↓ 表示越低越好。最好的结果用粗体显示,次好的结果用下划线显示。BA表示BERT-Attack,TF表示我们的方法。IS表示重要性分数,IF表示重要性级别,RD表示随机攻击。)
(表5:SA-LLaMA上攻击成功率 (A-rate)、修改率 (Mod)、语义相似性 (Sim) 和时间成本 (Time Cost) 的自动评估结果。↑ 表示越高越好,↓ 表示越低越好。最好的结果用粗体显示,次好的结果用下划线显示。BA表示BERT-Attack,TF表示我们的方法。IS表示重要性分数,IF表示重要性级别,RD表示随机攻击。)
4.3 可迁移性
我们评估TF-ATTACK样本的可迁移性,以检测从TF-ATTACK生成的样本是否可以有效地攻击其他模型。我们在IMDB数据集上进行实验,并使用BERT-Attack作为基线。表6显示了TF-ATTACK相对于BERT-Attack在攻击成功率方面的改进。可以观察到,当应用于其他模型时,TF-ATTACK相对于BERT-Attack取得了明显的改进。特别是,TF-ATTACK生成的新样本可以将二元分类任务的准确率降低超过10%,从而有效地混淆受害者模型。即使是像ChatGPT这样强大的基线,准确率也会降至仅68.6%。需要强调的是,这些样本不需要针对特定受害者模型进行定制攻击。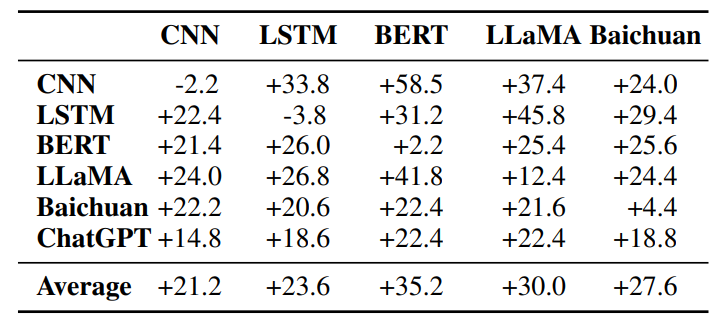 (表6:TF-ATTACK样本在IMDB数据集上的可迁移性评估。每个元素都是TF-ATTACK和BERT-Attack之间攻击成功率的差异计算得出的。)
(表6:TF-ATTACK样本在IMDB数据集上的可迁移性评估。每个元素都是TF-ATTACK和BERT-Attack之间攻击成功率的差异计算得出的。)
4.4 效率
我们根据IMDB数据集中不同的句子长度来探究效率。如图5所示,TF-ATTACK的时间成本出人意料地在大多数情况下优于BERT-Attack,后者主要目标是在表4中以较低的攻击成功率获得更便宜的计算成本。此外,随着句子长度的增加,TF-ATTACK保持稳定的时间成本,而BERT-Attack的时间成本则呈爆炸式增长。原因是TF-ATTACK具有更快的并行替换优势,因此随着句子长度的增加,时间成本的增加会小得多。这些现象验证了TF-ATTACK的效率优势,尤其是在处理长文本时。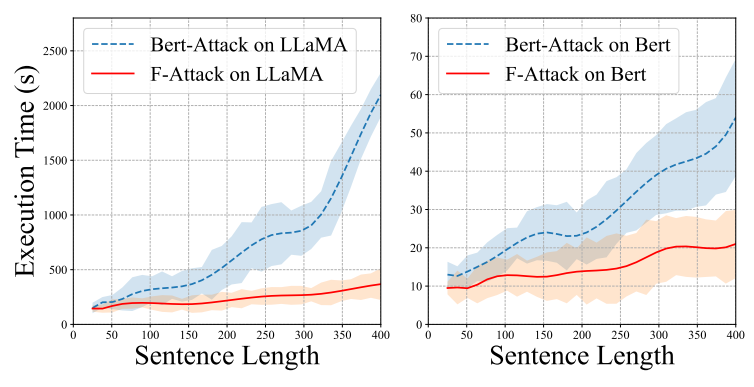 (图5:IMDB数据集中不同句子长度的时间成本。左图是LLaMA,右图是BERT。)
(图5:IMDB数据集中不同句子长度的时间成本。左图是LLaMA,右图是BERT。)
4.5 人工评估
我们遵循Fang等人,2023的方法进行人工评估。在人工评估开始时,我们提供了一些数据以允许众包工作者统一评估标准。在计算平均值时,我们还删除了差异较大的数据,以确保评估结果的可靠性和准确性。我们首先从IMDB和MR数据集中成功的对抗样本中随机选择100个样本,然后要求十名众包工作者评估原始输入和我们生成的对抗样本的质量。结果如表7所示。对于人类预测一致性,人类可以在IMDB数据集上准确判断93%的原始输入,同时对我们生成的对抗样本保持87%的准确率。这表明TF-ATTACK可以在不改变人类判断的情况下有效地误导LLMs。关于语言流畅性,我们的对抗样本的得分与原始输入相当,两个数据集的得分差异不超过0.3。此外,原始输入和我们生成的对抗样本之间的语义相似性得分在IMDB和MR上分别为0.93和0.82。NLI任务的结果在表8中。总体而言,TF-ATTACK成功地保留了这三个基本属性。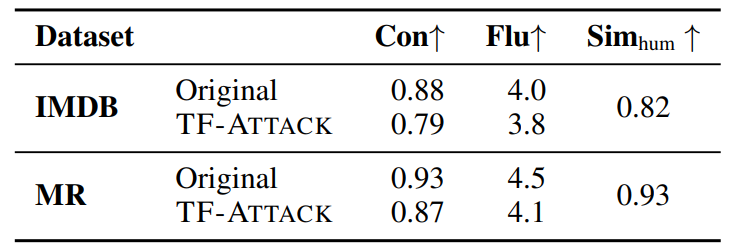 (表7:比较TF-ATTACK生成的原始输入和对抗样本的人类预测一致性 (Con)、语言流畅性 (Flu) 和语义相似性 (Sim_hum) 的人工评估结果。)
(表7:比较TF-ATTACK生成的原始输入和对抗样本的人类预测一致性 (Con)、语言流畅性 (Flu) 和语义相似性 (Sim_hum) 的人工评估结果。)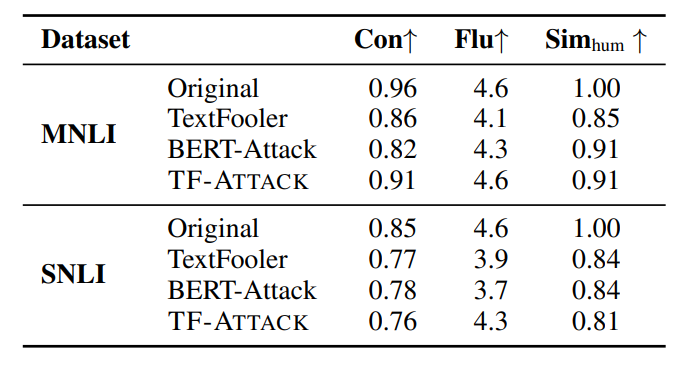 (表8:关于人类预测一致性 (Con)、语言流畅性 (Flu) 和语义相似性 (Sim_hum) 的人工评估结果。)
(表8:关于人类预测一致性 (Con)、语言流畅性 (Flu) 和语义相似性 (Sim_hum) 的人工评估结果。)
5、分析
5.1 对更多受害者模型的泛化能力
表9显示TF-ATTACK不仅对WordCNN和WordLSTM具有更好的攻击效果,而且还能误导更鲁棒的模型BERT和Baichuan。例如,在IMDB数据集上,针对Baichuan的攻击成功率高达92.5%,修改率仅为约11.8%,语义相似性高达0.75。此外,受害者模型生成的模型在各种不同规模的黑盒模型上造成了71.4%的准确率下降。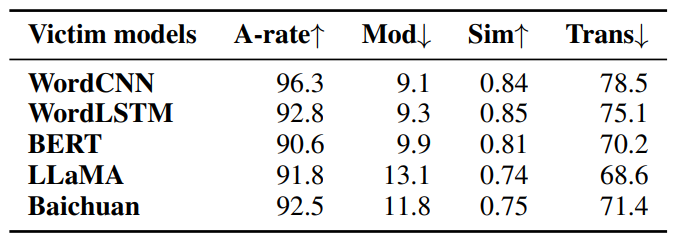 (表9:TF-ATTACK针对其他模型。)
(表9:TF-ATTACK针对其他模型。)
5.2 对抗训练
遵循Fang等人,2023的方法,我们进一步研究通过使用生成的对抗样本进行对抗训练来提高受害者模型的鲁棒性。具体来说,我们使用原始训练数据集和我们生成的对抗样本对受害者模型进行微调,并在相同的测试集上对其进行评估。如表10所示,与原始训练数据集的结果相比,使用我们生成的对抗样本进行对抗训练可以保持接近的准确性,同时提高攻击成功率、修改率和语义相似性方面的性能。具有对抗训练的受害者模型更难攻击,这表明我们生成的对抗样本有潜力作为补充语料库来增强受害者模型的鲁棒性。表10显示了所有数据集的对抗训练结果。总体而言,在同时使用原始训练数据集和对抗样本进行微调后,受害者模型更难攻击。与原始结果相比,所有数据集的准确性几乎不受影响,而攻击成功率则出现明显下降。同时,用对抗训练攻击模型会导致更高的修改率,进一步证明对抗训练可能有助于提高受害者模型的鲁棒性。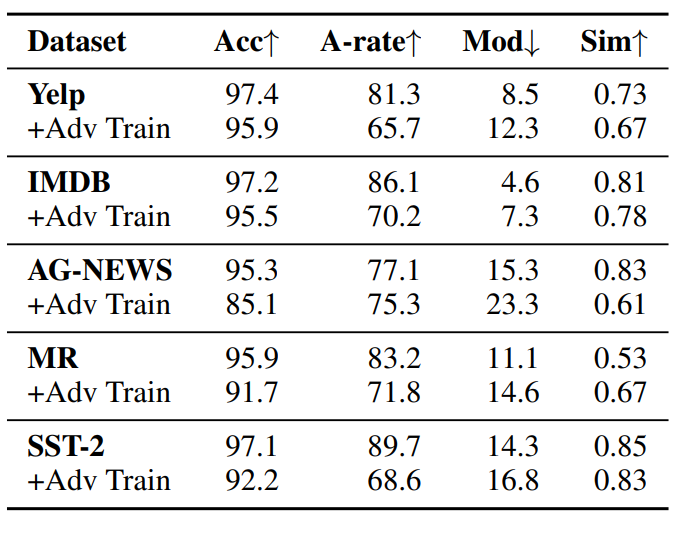 (表10:对抗训练结果。)
(表10:对抗训练结果。)
5.3 抵抗防御
最近,熵阈值防御已被用于防御针对LLMs的攻击。它利用第一个词元预测的熵来拒绝响应。图6展示了LLaMA生成的第一个单词中top-10词元的概率。可以观察到,原始输入通常以低熵生成第一个词元(即,argmax词元的概率远高于其他词元的概率)。如图6所示,来自TF-ATTACK的对抗样本比具有更高熵的BERT-Attack表现更好。与传统的文本对抗攻击方法相比,通过TF-ATTACK生成的攻击样本在抵抗基于熵的过滤器方面表现更好,表明TF-ATTACK创建的样本更难防御。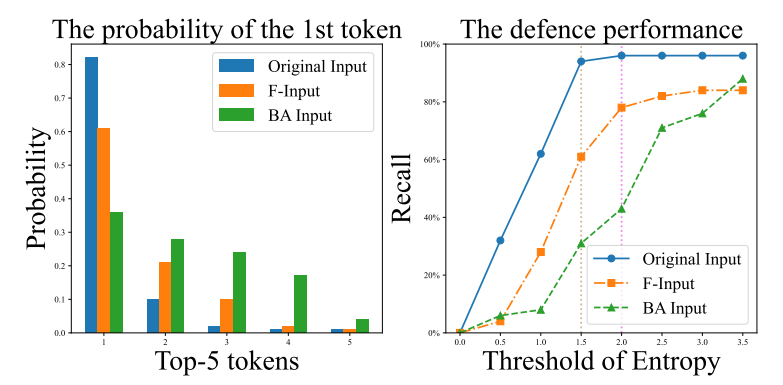 (图6:SA-LLaMA中生成的第一个单词中top-10词元的概率(a)。不同熵阈值下的防御性能(b)。)
(图6:SA-LLaMA中生成的第一个单词中top-10词元的概率(a)。不同熵阈值下的防御性能(b)。)
5.4 案例研究
表11显示了由TF-ATTACK和基线生成的对抗样本。总体而言,TF-ATTACK的性能明显优于其他方法。对于来自MR数据集的这个样本,只有TextFooler和TF-ATTACK成功误导了受害者模型,即将预测从负面更改为正面。然而,TextFooler修改的单词数量是TF-ATTACK的两倍,证明了我们的工作找到了更合适的修改路径。由TextFooler和BERT-Attack生成的对抗样本由于语义相似性低而失败。由于其子词组合算法,BERT-Attack甚至生成了一个无效词“enamoted”。我们还请众包工作者进行流畅性评估。结果显示TF-ATTACK获得最高分4分(与原始句子相同),而其他对抗样本则被认为难以理解,表明TF-ATTACK可以生成更自然的句子。 (表11:MR数据集中TF-ATTACK和基线生成的对抗样本。替换的单词用蓝色突出显示。失败表示对抗样本未能攻击受害者模型,成功则表示相反。)
(表11:MR数据集中TF-ATTACK和基线生成的对抗样本。替换的单词用蓝色突出显示。失败表示对抗样本未能攻击受害者模型,成功则表示相反。)
6、结论
在本文中,我们研究了当前对抗攻击方法的局限性,特别是它们在应用于大型语言模型(LLMs)时的可迁移性和效率问题。为了解决这些问题,我们引入了TF-ATTACK,这是一种利用外部监督模型识别关键句子成分并允许并行处理对抗替换的新方法。我们在六个基准测试上的实验表明,TF-ATTACK优于当前方法,显著提高了可迁移性和速度。此外,由TF-ATTACK生成的对抗样本在模型经过抵抗攻击训练后不会显著影响模型性能,从而增强了其防御能力。我们相信TF-ATTACK是在创建针对LLMs的强大对抗攻击防御方面的重大进步,对该领域的未来研究具有潜在益处。
[1]:John Morris, Eli Lifland, Jin Yong Yoo, Jake Grigsby, Di Jin, and Yanjun Qi. 2020. Textattack: A framework for adversarial attacks, data augmentation, and adversarial training in nlp. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 119–126.
[2]:Di Jin, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. 2020. Is bert really robust? a strong baseline for natural language attack on text classification and entailment. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 8018–8025.
[3]:Dianqi Li, Yizhe Zhang, Hao Peng, Liqun Chen, Chris Brockett, Ming-Ting Sun, and William B Dolan. 2021. Contextualized perturbation for textual adversarial attack. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5053–5069.
[4]:Dianqi Li, Yizhe Zhang, Hao Peng, Liqun Chen, Chris Brockett, Ming-Ting Sun, and William B Dolan. 2021. Contextualized perturbation for textual adversarial attack. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5053–5069.
[5]:Xuanjie Fang, Sijie Cheng, Yang Liu, and Wei Wang.2023. Modeling adversarial attack on pre-trained language models as sequential decision making. In Findings of the Association for Computational Linguistics: ACL 2023, pages 7322–7336.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
