
原文标题:KG-Agent: An Efficient Autonomous Agent Framework for Complex Reasoning over Knowledge Graph
原文作者: Jinhao Jiang, Kun Zhou, Wayne Xin Zhao, Yang Song, Chen Zhu, Hengshu Zhu, Ji-Rong Wen原文链接:https://openreview.net/forum?id=YMv7KTIeQC发表会议:ACL"25笔记作者:彭佳仁@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1. 研究背景
受现有设计LLMs与KG交互策略的方法启发,本文提出了一个名为KG-Agent的自主LLM智能体框架,该框架使小型LLM能够在知识图谱上主动决策,直至完成推理过程。
在KG-Agent中整合了LLM、多功能工具箱、基于KG的执行器和知识记忆,并开发了一种迭代机制,该机制能够自主选择工具,然后更新记忆以在KG上进行推理。为保证有效性,利用编程语言来形式化KG上的多跳推理过程,并合成一个基于代码的指令数据集来微调基础LLM。
大量实验表明,仅使用10K样本微调LLaMA-7B,无论是在领域内还是领域外数据集上,其性能均可超越使用更大型LLM或更多数据的现有最先进方法。
2. KG-Agent
2.1 面向知识图谱的工具箱
由于LLMs在精确操作结构化数据方面存在困难,KG-Agent构建了一个支持性的工具箱,以简化对KG信息的利用,其为LLM在KG上推理设计了三类工具,即提取工具、语义工具和逻辑工具。
提取工具 旨在方便从KG中获取信息。考虑到KG中的基本数据类型,设计了五种工具,以支持访问关系(
get_relation)、头/尾实体(get_head_entity/get_tail_entity),以及具有特定类型或约束的实体(get_entity_by_type/get_entity_by_constraint),这些操作都针对于某个实体集或其他输入信息(如关系或类型)。逻辑工具 旨在支持对提取的KG信息进行基本操作,包括实体计数(
count)、实体集交集(intersect)和并集(union)、条件验证(judge),以及使用当前实体集作为最终答案结束推理过程(end)。语义工具 是通过利用预训练模型来实现特定功能而开发的,包括关系检索(
retrieve_relation)和实体消歧(disambiguate_entity)。这些工具扩展了对KG的基本操作,并能支持KG推理的高级功能。
2.2 KG-Agent指令微调
为了实现自主推理过程,本文构建了一个高质量的指令数据集,用于微调一个小型LLM。为此,首先利用现有的基于KG的问答(KGQA)数据集生成KG推理程序,然后将其分解为多个步骤。最后,每个步骤都被形式化为带有输入和输出的指令数据。
2.2.1 KG推理程序生成
本文利用现有的KGQA数据集来合成KG推理程序。首先将SQL查询落地到KG上以获得一个查询图,然后从查询图中提取推理链和约束条件,最后将该链分解为多个代码片段作为推理程序。
推理链提取。由于整个KG极为庞大且包含不相关数据,第一步是获取与问题相关的小型KG子图,称为查询图。本文通过规则匹配从KG中获得查询图。如图1(b)所示,查询图具有树状结构,可以直接映射为逻辑形式,并且可以清晰地描绘出为获得答案而执行SQL查询的流程。其次,从问题中提到的实体(即克里斯蒂亚诺·罗纳尔多)开始,采用广度优先搜索(BFS)来访问查询图上的所有节点。这个策略最终会产生一个连接起始实体和答案实体的推理链(例如teams -> roster_team),并且相关的约束条件(例如roster_from = "2011")或数值操作(例如founded必须是最后)可以自然地被包含在这个过程中。
推理程序生成。提取推理链后,接着将其转换为多个相互关联的三元组,其中每个三元组通常对应一个中间推理步骤。最后,将这些三元组重构成几个代码格式的函数调用,这些函数调用代表了工具的调用,并且可以被执行以基于KG获得相应的三元组。给定一个三元组 ,首先从get_relation(e)函数调用开始,以获取与 在KG上关联的当前候选关系 。然后,选择一个关系 并将其传递给其他需要的函数调用(例如get_tail_entity或get_entity_by_constraint),最终获得新的实体。
2.2.2 KG推理指令合成
在获得KG上的推理程序后,进一步利用它来合成为监督式微调(SFT)准备的指令数据。
输入-输出对构建。输入包含问题、工具箱定义、当前的KG信息以及当前步骤之前的历史推理程序;输出则是当前步骤的函数调用。接下来,在执行当前推理步骤的函数调用后,输入中的历史推理程序和当前KG信息将相应更新,而输出则更新为下一步的函数调用。通过迭代上述过程,对于KGQA数据集中的每个样本,都可以从相应的推理程序中派生出多个输入-输出对,这些对描绘了在KG上的完整推理轨迹。为了帮助LLMs更好地理解,进一步利用统一的提示模板(如图1(c)所示)来格式化每个输入-输出对,并获得最终的指令微调数据。
智能体指令微调。基于上述格式化的指令微调数据,本文对一个小型LLM(即LLaMA-7B)进行监督式微调,该模型比以往工作中的骨干模型要小得多。形式上,对于每个样本,将其完整轨迹的所有输入-输出对格式化为 ,其中 代表第 步的输入和真实回复, 代表总步数。为简化起见,用 和 分别代表每个输入和输出。在指令微调过程中,将输入 和输出 送入仅解码器的LLM,并最小化在真实回复 上的交叉熵损失,公式如下:
$$\\mathcal{L}=-\\sum_{k=1}^{m}log~Pr(y_{k}|x,y_{<k}) $$=""
其中, 表示 中的token数量, 和 $y_{<k}$ 分别是输出中的第="" $k$="" 个和之前的token。<="" p="">
2.3 在知识图谱上自主推理
指令微调后,进一步设计了一个高效的智能体框架,使KG-Agent能够自主地在KG上执行多步推理以寻找答案。KG-Agent的整体示意图如图1(a)所示。它主要包含四个组件:作为核心的指令微调LLM,本文称之为LLM规划器;多功能工具箱;用于执行工具调用的KG执行器;以及在整个过程中记录上下文和当前有用信息的知识记忆。以下说明了KG-Agent如何执行自主推理:
知识记忆初始化。知识记忆保存了当前有用的信息,以支持LLM规划器进行决策。
规划器进行工具选择。基于当前的知识记忆,LLM规划器在每一步选择一个工具与KG进行交互。
执行器进行记忆更新。在规划器生成函数调用后,KG执行器将使用一个程序编译器来执行它。
迭代式自主KG-Agent。KG-Agent框架通过自主迭代上述的工具选择和记忆更新过程来执行逐步推理,其中知识记忆用于维护从KG访问到的信息。
3 实验
3.1 数据集
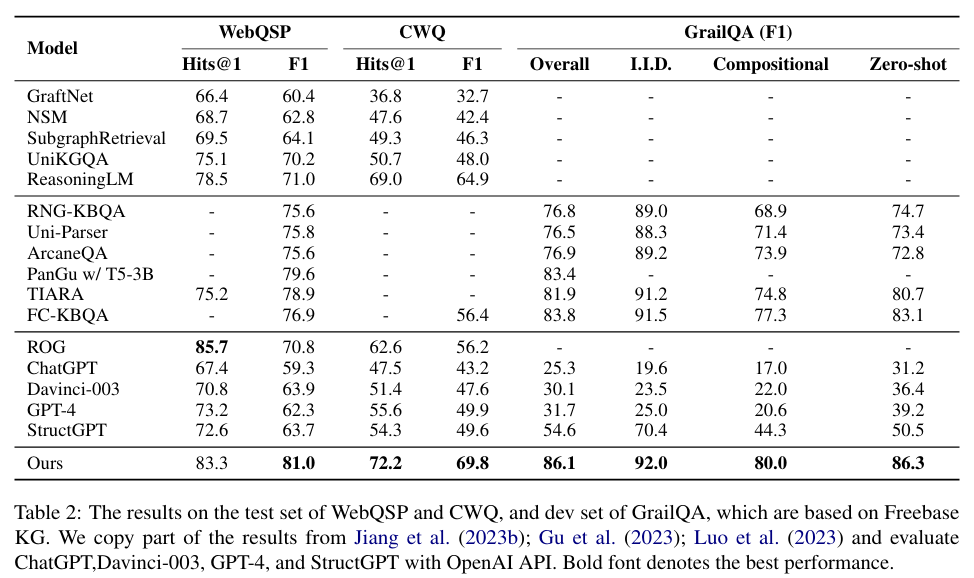
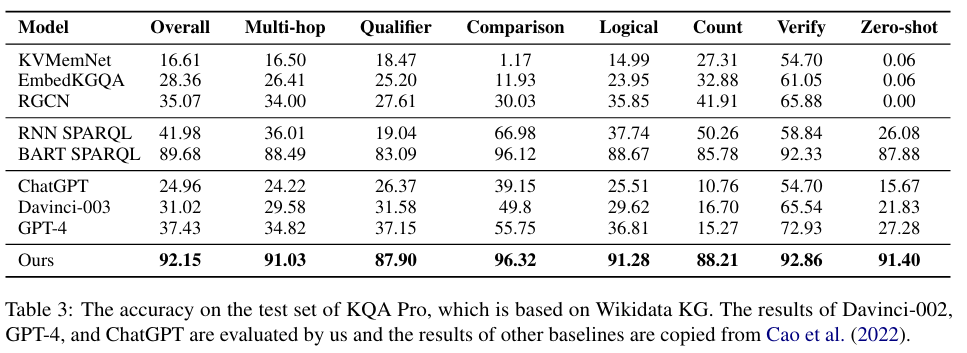
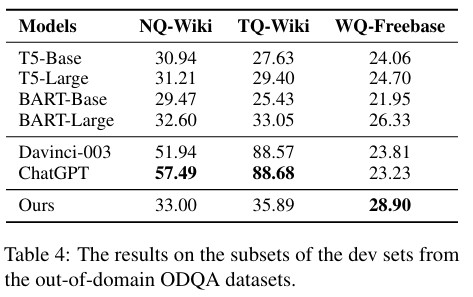
KG-Agent选择了四个常用的KGQA数据集作为领域内数据集,即基于Freebase的WebQSP、CWQ和GrailQA,以及基于Wikidata的KQA Pro。选择了三个ODQA数据集作为领域外数据集,即WQ、NQ和TQ。
3.2 主要结果
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
