基本信息
原文标题:Large Language Models in Cybersecurity: Applications, Vulnerabilities, and Defense Techniques
原文作者:Niveen O. Jaffal, Mohammed Alkhanafseh, David Mohaisen
作者单位:Birzeit University (Palestine), University of Central Florida (USA)
关键词:大语言模型、网络安全、应用、攻击、防御
原文链接:https://arxiv.org/pdf/2507.13629
开源代码:暂无
论文要点
论文简介:这篇综述论文系统性地分析了大语言模型(LLMs)在网络安全领域的应用现状、相关漏洞及其防御机制。作者通过广泛调研现有研究,分类整理了LLM在不同安全领域的应用案例、攻击向量及应对策略,旨在为后续研究提供理论基础和实践指导。论文从LLMs在威胁检测、漏洞评估和事件响应中的智能化能力出发,探讨了其在提升网络安全方面的潜力,并分析了模型在对抗攻击、提示注入等方面的脆弱性。通过总结现有研究成果,作者提出了增强LLM安全性的策略,为构建安全、可扩展和未来就绪的网络防御系统提供了实用见解。
研究目的:本文旨在系统梳理LLMs赋能网络安全的关键落地场景,细致挖掘其在不同安全子领域中所承载的任务变化与技术优势,并深入揭示LLMs本身在安全应用过程中的脆弱点及实际威胁。论文明确提出两个核心研究问题:(1)LLMs于网络安全领域可覆盖哪些主要任务与实际挑战,并通过何种机制实现突破?(2)LLMs在网络安全应用中存在哪些固有或新兴的安全漏洞及攻击面,对应的防护对策、思路和技术手段如何? 通过梳理国际最前沿的案例、分析现有防线与未来需攻克的难题,论文试图为LLM驱动的智能安全体系的建设、治理与持续能力提升提供理论支撑和方法指导。
研究贡献
本论文的主要贡献包括:
LLMs在网络安全中的应用:系统列举并评估了LLMs在硬件安全、区块链安全、物联网安全、云安全等多个关键领域的应用,分析了其在不同场景下的能力、局限性及实际影响。
LLMs的漏洞与缓解措施:系统归纳了LLMs在网络安全应用中面临的主要漏洞,如提示注入、越狱攻击、数据投毒、后门攻击等,并详细探讨了相应的防御技术,如安全微调、内容过滤、模型融合等。
潜在挑战与未来方向:识别了LLMs在网络安全中的潜在挑战,如可解释性差、数据集不足、对抗攻击风险等,并提出了未来研究方向,包括增强模型鲁棒性、构建多模态安全系统等。
引言
引言部分首先回顾了机器学习和深度学习,尤其是Transformer架构的突破性进展,如何奠定了大语言模型迅猛发展的根基。LLMs(如BERT、GPT-3.5/4、PaLM、Claude、Chinchilla等)凭借多参数规模,在语言理解、信息推理和指令执行等方面展现出卓越性能。这些模型不仅能够高效处理人类语言,而且还能够实现开放域问答、对话系统、程序合成等多样化的复杂任务,轻微微调即可快速适应各种下游场景。
引言指出,网络安全威胁愈发复杂和高级,各类攻击手法不断翻新,对安全防护系统提出了自动化、智能化和高适应性的全新要求。LLMs因其可迁移性,成为自动生成安全防御规则、威胁泛化分析及新型攻击发现的理想工具。然而,将LLMs部署于现实安全环境下,其本身也易受利用,成为新型攻击和滥用的靶点。因此,围绕LLMs攻防体系的研究日益迫切。
本文在综述领域现有工作的基础上,提出了区别于以往的系统性分析视角:首次全面整合LLMs在网络安全不同领域的实际应用场景、模型自身的安全风险以及防御体系三大主线,对相关文献进行跨领域、跨任务、深层次的梳理与评估。论文结构上,先回顾相关综述和基础文献,随后详细探讨LLMs如何变革网络、软件、内容、硬件、区块链、云、威胁情报与物联网等八大安全领域,进而聚焦模型本身的安全漏洞类型与应对策略,最后总结面临的主要挑战,展望未来研究趋势。作者认为,当前随着模型与安全威胁同步“进化”,对LLMs安全性的认识和防护技术的持续演化已成为保障网络空间根基安全的关键。
LLMs在网络安全中的应用领域
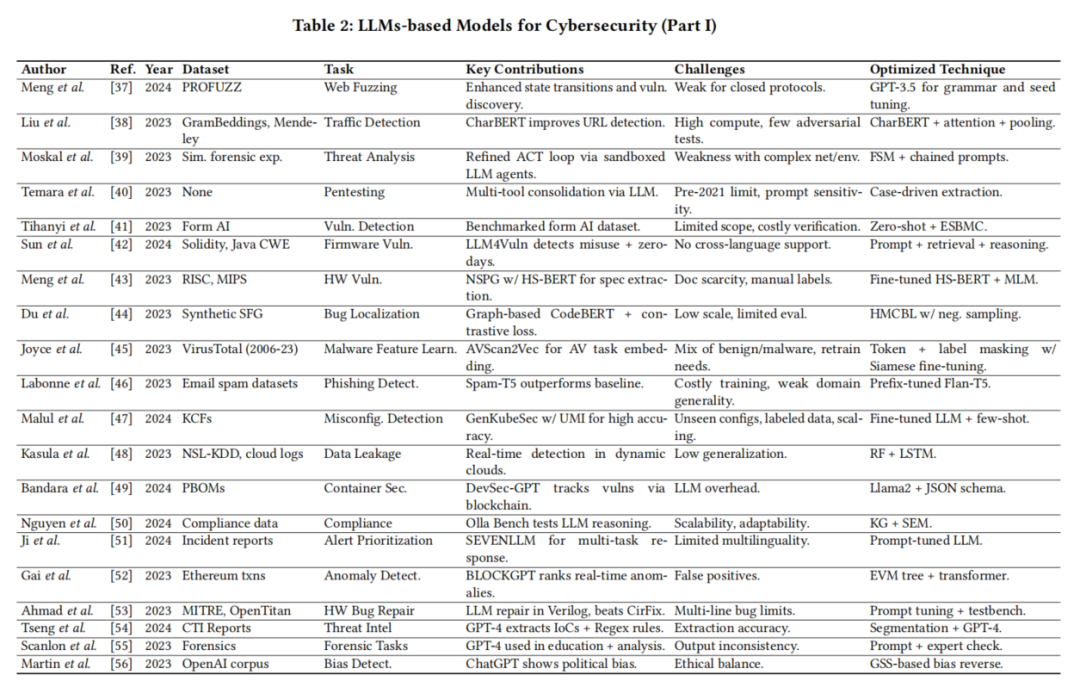
网络安全威胁日益复杂化,推动了大语言模型(LLMs)在多个安全领域的应用。本综述将 LLM 的应用分为八个关键领域:网络安全、软件与系统安全、信息与内容安全、硬件安全、区块链安全、云安全、事件响应与威胁情报,以及物联网安全。

这种分类从结构化视角展现了 LLM 在网络安全各领域的多样化应用,为深入理解其在增强实时应用和各领域安全稳健性方面的贡献提供了洞见。图2直观呈现了 LLM 应用在网络安全各领域的分布情况。此外,图2列出了针对各类网络安全任务和使用场景的基于 LLM 的解决方案。
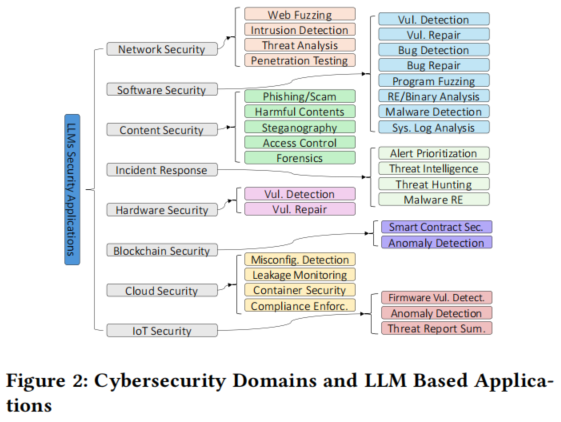
事实证明,LLM 在提升效率、准确性和适应性方面发挥了重要作用,标志着现代网络安全防御策略实现了重大飞跃。
1. 网络安全(Network Security)
LLMs在网络安全中的应用包括Web Fuzzing、流量与入侵检测、威胁分析和渗透测试。例如,GPTFuzzer通过强化学习和KL散度惩罚机制生成针对Web应用防火墙(WAF)的测试用例,用于检测SQL注入(SQLi)、跨站脚本(XSS)和远程代码执行(RCE)攻击。此外,GPT-4通过上下文学习实现了超过95%的入侵检测准确率,无需微调即可识别恶意URL并扩展用户级上下文分析。LLMs还通过可解释性增强技术(如RAG)提升网络入侵检测系统的可解释性,并通过图分析与强化学习增强复杂网络环境下的威胁检测能力。
2. 软件与系统安全(Software and System Security)
LLMs在软件安全中的应用涵盖漏洞检测、恶意软件分析、程序模糊测试、错误修复、反向工程、二进制分析和系统日志分析。例如,LATTE结合LLMs与自动化二进制污点分析,成功识别了固件中的37个未发现漏洞。Tihany等通过构建大规模漏洞标注数据集FormAI,展示了LLMs在漏洞修复中的潜力,但也指出超过50%的LLM生成代码存在漏洞,突显了自动化代码生成的安全风险。此外,LLMs通过对比学习提升错误检测精度,并通过二进制分析工具如DexBert和SYMC框架增强低级代码理解。
3. 信息与内容安全(Information and Content Security)
LLMs在信息与内容安全中的应用包括钓鱼与诈骗检测、有害内容识别、隐写术、访问控制和数字取证。例如,LLMs通过提示工程和微调模型显著提升钓鱼邮件检测效果,Spam-T5在少样本邮件垃圾检测中表现优于传统机器学习方法。LLMs还通过模拟人类与诈骗者的互动,自动浪费攻击者时间,降低诈骗邮件的效率。在隐写术方面,LLMs通过Few-shot学习和自然语言加密提升隐写分析能力,并支持隐蔽数据嵌入。PassGPT通过生成高熵密码和评估密码强度,增强访问控制机制。
4. 硬件安全(Hardware Security)
LLMs在硬件安全中的应用包括漏洞检测与修复。例如,HS-BERT通过分析硬件架构文档(如RISC-V、OpenRISC、MIPS)发现OpenTitan SoC设计中的8个安全漏洞。Paria等通过将漏洞链接至CWE并执行安全断言,进一步提升SoC设计中的漏洞检测能力。Nair等展示了LLMs在硬件代码生成中的应用,成功设计出能解决10个CWE问题的硬件。Tan等构建了大规模硬件安全漏洞语料库,评估LLMs在自动化漏洞修复中的能力。
5. 区块链安全(Blockchain Security)
LLMs在区块链安全中的应用包括智能合约漏洞检测和交易异常识别。例如,GPTLENS采用双阶段方法生成并优先排序威胁场景,减少误报率并提升验证准确性。Sun等通过LLMs分析程序逻辑漏洞,提升智能合约安全性。Gai等展示了LLMs在区块链交易中动态识别异常的能力,突破传统规则依赖,提升异常检测效率。
6. 云安全(Cloud Security)
LLMs在云安全中的应用包括配置错误检测、数据泄露监控、容器安全和合规性执行。例如,GenKubeSec通过UMI标准化评估,实现Kubernetes配置文件错误检测,精度达0.990,召回率达0.999。Kasula等提出的Secure Cloud AI结合随机森林与LSTM网络,实现94.78%的数据泄露检测准确率。DevSec-GPT利用Llama2 LLM生成容器材料清单(PBOM),确保漏洞跟踪和防止供应链攻击。OllaBench通过24种认知行为理论测试LLMs的合规性推理能力,揭示GPT-4o和Claude在监管自动化中的有效性。
7. 事件响应与威胁情报(Incident Response and Threat Intelligence)
LLMs在事件响应与威胁情报中的应用包括警报优先级排序、自动化威胁情报分析、威胁狩猎和恶意软件逆向工程。例如,SEVENLLM通过多任务学习减少SIEM中的误报,提升智能告警能力。Tseng等利用LLMs自动提取CTI报告中的IoC并生成正则表达式,提升威胁检测效率。HuntGPT结合GPT-3.5与SHAP、LIME等XAI框架,提升威胁情报的可解释性。LLMs还通过DISASLLM和MALSIGHT提升恶意代码检测与行为描述的准确性。
8. 物联网安全(IoT Security)
LLMs在物联网安全中的应用包括固件漏洞检测、行为异常检测和自动化威胁报告摘要。例如,LLM4Vuln结合检索增强生成(RAG)与提示工程,提升多语言固件漏洞检测能力。UVSCAN通过NLP驱动的二进制分析,识别API误用、因果错误和返回值问题。IDS-Agent结合推理管道、记忆检索与外部知识,提升零日攻击检测能力。IoTShield通过LLMs生成定制IDS签名,提升防御准确性。
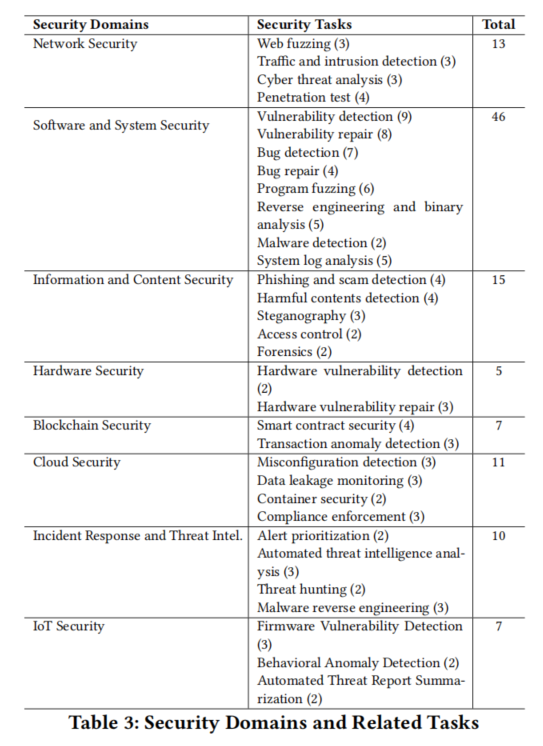
LLMs在网络安全中的漏洞与攻击类型
1. 数据投毒(Data Poisoning)
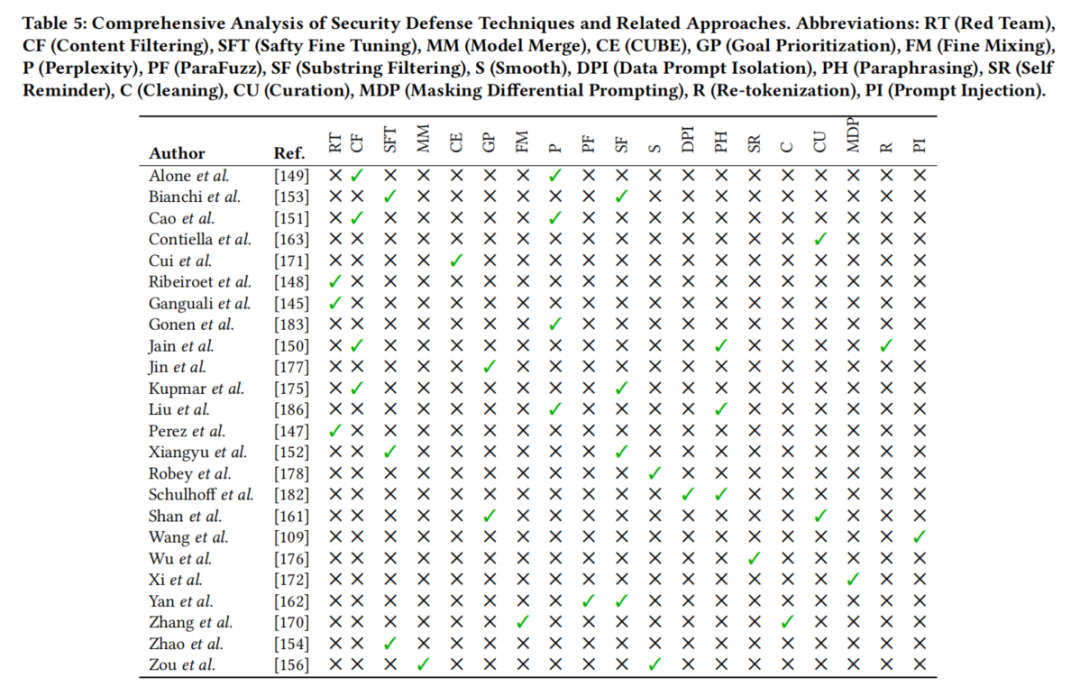
攻击者通过在训练数据中插入误导样本,使LLMs产生偏见预测和决策。例如,ParaFuzz通过分析模型预测的可解释性,识别NLP模型中的中毒样本。Contiella等强调数据清洗的重要性,通过去除近似重复的中毒样本和隔离训练集中的异常值,提升数据集的纯净度。Fine-pruning和困惑度过滤等技术也被用于缓解数据投毒攻击。
2. 后门攻击(Backdoor Attacks)
攻击者通过在训练数据中植入触发器,使LLMs在特定输入下表现异常。例如,Fine Mixing通过合并后门优化权重与预训练权重,并在干净数据集上进行微调,提升模型鲁棒性。CUBE利用HDBSCAN密度聚类算法识别并隔离中毒样本。Masking Differential Prompting(MDP)利用中毒样本对随机掩码的高度敏感性,提升提示攻击的防御能力。
3. 提示注入(Prompt Injection)
攻击者通过精心设计的提示绕过LLMs的安全机制,生成有害内容。例如,Paraphrasing和Retokenization技术通过打乱注入数据的序列或分解低频标记,缓解恶意指令。Perplexity-based检测通过分析质量下降和困惑度增加,识别受污染的触发器。然而,传统的预防与检测技术在面对基于优化的攻击(如Judge Deceiver)时仍存在局限性,亟需持续创新。
4. 越狱攻击(Jailbreaking Attacks)
攻击者通过绕过LLMs的安全限制,获得系统高级访问权限。例如,Substring安全过滤通过分析和过滤输入提示,阻止有害响应。Self-Reminder系统引导LLMs朝向安全行为,降低越狱成功率。Goal Prioritization方法在响应生成中优先考虑安全性,减少有害内容风险。Smooth LLM通过随机平滑技术扰动输入提示并聚合输出,降低指令攻击的成功率。
LLMs在网络安全中的防御技术
随着LLM广泛应用,其本身的安全隐患和攻击面也日益突出。论文系统归纳了主要威胁类别及应对手段:
1. 数据投毒(Data Poisoning)
敌手通过向训练或微调数据注入有害样本,导致模型学得有偏或恶意行为。防御方式包括数据校验与过滤、清洗、异常检测,以及基于模型输出表现的异常识别(如ParaFuzz框架),还可采用数据集去重、触发器隔离等多层次清理。
2. 后门攻击(Backdoor)
在训练阶段注入隐蔽触发器,使模型在特定输入下输出攻击者期望结果。防御手段如Fine Mixing(权重融合)、CUBE(基于密度聚类检测毒样本)、Embedding Purification,以及Masking Differential Prompting等,可有效提升模型鲁棒性与对抗防护强度。
3. Prompt注入(Prompt Injection)与越狱(Jailbreaking)
攻击者通过构造特殊的输入绕过模型的安全边界,实现敏感内容输出或控制系统执行恶意操作。综合防御方法包括自适应内容过滤(输入输出双向)、prompt隔离、重分词、低困惑度检测、prompt paraphrasing、自动化Red Team演练、模型安全微调、安全优先级管理(goal prioritization)、自提醒系统(self-reminder)以及Smooth LLM输入扰动等。

4. 防御体系概览与多策略整合
-Red Teaming:通过模拟各种攻击情景、生成极端测试用例,动态强化模型对抗能力。
-内容过滤:融合规则、学习两路防线,动态增强拦截攻击prompt与恶意输出的能力。
-安全微调:引入安全样本扩充、约束性目标函数,平衡性能与风险,长期提升模型安全水平。
-模型融合:整合多源优化模型,提升泛化与抗对抗能力,同时注意过拟合与防御过激的问题。
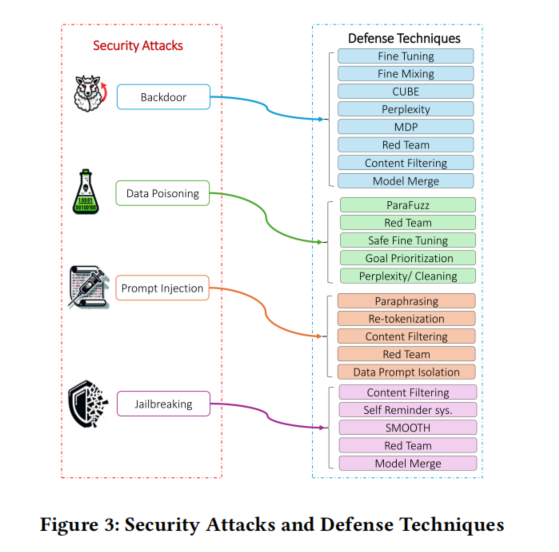
论文补充分析了这些防御技术的实际适用性、局限性及最新对策演进。例如,内容过滤方法易遭对抗prompt逃逸;安全微调需兼顾多样输入场景并防止性能退化;模型融合和防御机制理论界定与最佳融合机制仍有提升空间。
研究挑战与未来方向
作者指出,尽管LLMs在安全领域表现出强大潜力,但在实际落地和长期治理方面仍面临诸多根本性挑战:
1. 可解释性与透明度不足:模型决策链条的“黑箱化”导致安全事件追溯难,影响关键领域部署和用户信任。
2. 高质量安全专用数据集匮乏:尤其在网络、硬件、物联网等行业领域,缺乏针对性的标注数据限制了模型微调与评估。
3. 应对新型/复杂攻击的能力有限:LLMs对多步prompt攻击、优化型投毒、语义对抗等的防御落后于攻击策略演化速度,需要深度人机协同与自适应机制。
4. 实际部署中的规模化、资源和多模态瓶颈:大模型在边缘端、物联网等受限环境难以平衡性能与能耗,云服务多环境合规、自治安全体系建设也是难点。
5. 统一评价体系与基准缺失:缺乏全行业通用的安全评估方式,模型防御能力与安全指标无法标准化、量化对比。未来方向主要包括:可解释和自治防御的大模型架构、多模态安全感知与决策、开放与可扩展安全基准体系构建、领域专用小型安全LLM融合、自动化脆弱点修复与自适应体系进化等。作者倡议行业重视开放协作、数据共享及跨领域融合,推动“自修复、自防御”型安全AI系统逐步落地。
论文结论
本论文系统分析了LLMs在32个安全任务中的应用,覆盖区块链、硬件、物联网和云安全等八大领域。LLMs在漏洞检测、恶意软件分析、威胁情报自动化等任务中展现出显著潜力。然而,LLMs也面临对抗攻击、提示注入等安全漏洞,需通过重标记、困惑度检测、提示隔离等技术增强安全性。本文为LLMs在网络安全框架中的安全集成提供了关键见解,强调通过解决现有挑战,LLMs可演进为应对新兴网络威胁的鲁棒解决方案,保障关键数字基础设施安全。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
