
原文标题:Once is Never Enough: Foundations for Sound Statistical Inference in Tor Network Experimentation
原文作者:Rob Jansen, Justin Tracey, Ian Goldberg原文链接:https://www.usenix.org/conference/usenixsecurity21/presentation/jansen发表会议:USENIX Security Symposium 2021笔记作者:王彦@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1 总体介绍
Tor作为全球最流行的低延迟匿名通信系统,广泛应用于反追踪、反审查、隐私保护等场景。随着用户数量的增长,Tor的可用性和性能直接影响其匿名性和安全性。以往研究多关注于提升Tor的性能和可用性,推动其用户增长,进而增强系统整体的匿名性。然而,Tor网络的复杂性和动态性使得实验结果常常受到网络采样误差的影响,导致实验结论的可靠性存疑。
目前,Tor性能优化相关研究大多采用单次仿真或单一网络样本进行实验,缺乏对统计显著性的系统考量。这种做法容易因网络采样的偶然性产生误导性的实验结果,且大多数研究未对实验结果进行置信区间等统计推断分析,导致结论难以推广到真实网络环境。尽管已有部分工作尝试多次实验或多网络样本,但系统性的统计推断方法尚未普及。
针对上述问题,本文提出了新的Tor网络建模方法和实验工具,能够根据历史网络状态生成更具代表性的测试网络,并大幅提升仿真效率和规模。更重要的是,作者提出了一套基于多次独立采样与置信区间的统计推断流程,强调只有在多个独立实验基础上,结合置信区间分析,才能获得对真实Tor网络有意义的结论。论文通过大规模实验,详细展示了方法的实际效果和优势。
2 背景知识
Tor网络的核心功能是为用户流量提供匿名转发,网络由分布在全球的中继节点组成,部分节点还承担目录服务器职责,负责发布网络共识文档。用户通过构建三跳电路(入口、出口、中间节点)访问互联网资源,所有流量在电路中多重加密,提升匿名性。
Tor实验工具主要分为网络仿真和网络模拟两类。Shadow是当前最流行的Tor实验平台,能够直接加载Tor源码作为插件运行,提供高保真的网络和系统行为仿真。Shadow平台的持续优化显著提升了其并发能力和运行效率,成为Tor性能研究的标准工具。
早期Tor网络建模方法多基于单一时间点的网络快照,采样中继节点及其属性,难以反映网络的动态变化。随着隐私保护测量技术的发展,研究者可以获得更丰富的Tor网络和用户行为统计数据,支持基于多时段、多属性的更具代表性的网络建模。
3 方案设计
本文提出的Tor网络建模与实验方案分为两个阶段。第一阶段为“staging”,即从历史共识文件和中继描述符中提取网络属性,计算每个节点的上线频率、带宽分布、地理位置等统计特征,并将结果存储为可复用的JSON文件。第二阶段为“generation”,利用staging阶段的数据,结合用户分布和流量统计,按需生成不同规模、负载和进程配置的Tor网络模型,支持灵活实验设计。
在网络建模方面,作者采用分层抽样和带权采样,确保节点的属性分布与真实网络高度一致。对于流量建模,结合最新的隐私保护测量数据,采用Markov模型分别模拟电路、流和分组的生成过程,使仿真流量在统计特征上与真实Tor流量高度一致。
为了支撑上述建模和实验,作者对实验平台 Shadow 进行了多项改进,包括TCP连接限制优化、并行模拟增强、Tor进程初始化加速、插件隔离调度机制等,使其能够支持更大规模的仿真(如6489个中继、79.2万个用户),并显著降低了内存消耗和运行时间。通过这些优化,首次实现了100%规模的Tor网络仿真,极大提升了实验的代表性和效率。作者提出了基于多次独立采样的实验流程。具体做法是,在多个独立采样的网络上分别运行实验,收集目标性能指标(如下载延迟、错误率等),然后对这些实验结果进行统计分析,计算置信区间。
整个方案设计通过新的建模工具 TorNetTools、流量生成器 TGen 的扩展以及 Shadow 的改进得以实现,为进行稳健的 Tor 性能研究提供了坚实的技术基础。
4 实验评估
为验证方法论的有效性,作者设计了大规模案例研究,探讨增加Tor网络负载对客户端性能的影响。实验假设为:将Tor网络总用户流量负载增加20%,会导致现有客户端的下载时间和下载错误率增加。为此,设计了6组实验,覆盖三种网络规模(真实网络的1%、10%和30%)和两种流量负载(正常负载和增加20%负载),每组实验在多个独立采样网络上重复运行,总计完成了420次仿真。所有实验均遵循提出的统计推断方法,对结果进行深入分析。
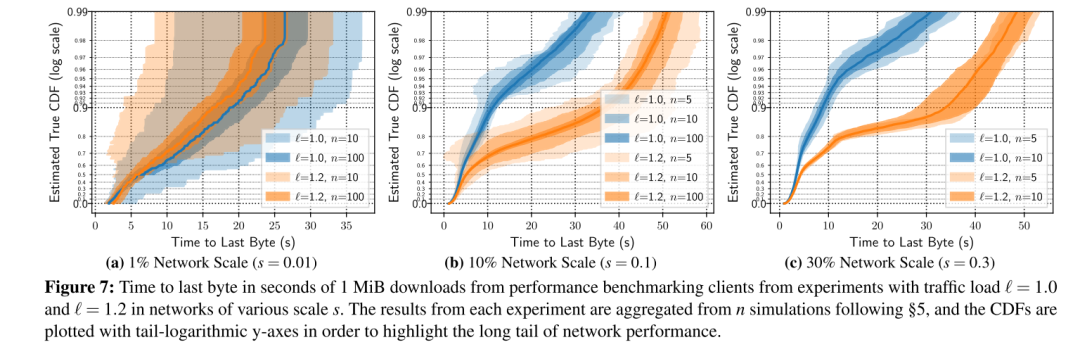
实验结果充分证明了多次采样和置信区间分析的必要性。在客户端下载时间的评估中,图7展示了不同网络规模和负载下,下载1MiB文件的“最后一字节时间”累积分布函数(CDF)。在1%网络规模下,即使进行了100次仿真,正常负载和增加负载的置信区间仍存在大面积重叠,无法得出统计上显著的结论。然而,随着网络规模和仿真次数的增加,置信区间逐渐收窄并分离,最终在10%及以上规模、100次仿真时,两种负载的置信区间界限完全分开,清晰表明增加负载导致下载时间延长。30%网络规模下,这种性能差异在仅10次仿真时就已非常明显,说明更大规模仿真能以更少实验次数获得更精确结论。
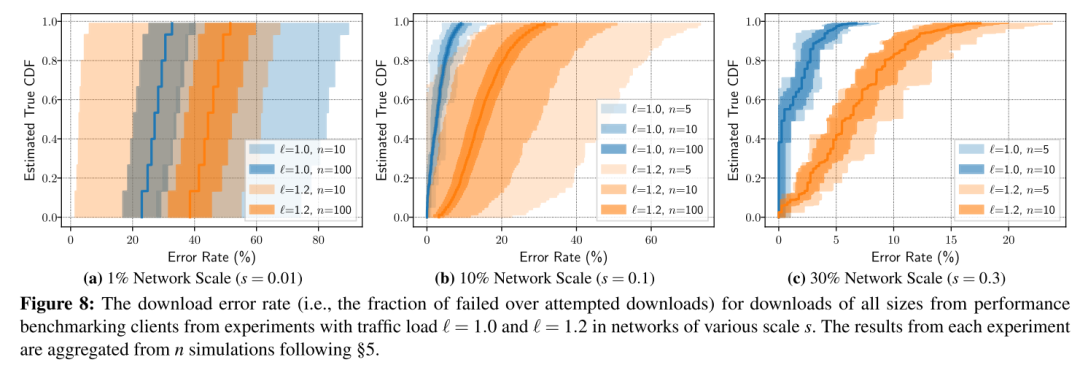
对客户端下载错误率的分析得出了类似结论,图8展示了不同条件下所有文件大小的下载错误率分布。在1%网络规模下,若仿真次数不足,置信区间重叠,结果模糊不清,无法得出可靠结论。但在10%和30%网络规模下,实验结果清晰显示增加20%负载显著提高了下载失败比例,且这一结论在较少仿真次数下即可获得统计支持。尤其在10%规模、100次仿真时,置信区间完全可区分,表明用户体验在高负载下的一致性显著下降。这些结果共同强调了单次实验的误导性,而本文方法论能帮助研究者避免错误结论并量化结果置信度。
此外,作者还通过表格对比了新旧建模和仿真工具在资源消耗和效率上的提升。数据显示,在31%网络规模下,新方法将引导过程时间缩短了80%,总运行时间减少了94%,内存使用量从2.6TiB降至932GiB,减少了64%。在100%网络规模下,首次成功运行仿真,包含6489个中继和79.2万用户,耗时不到两周,验证了新方法的扩展性和实用价值。
5 结论
本文系统性地提出了Tor网络实验中可靠统计推断的基础方法,结合新的网络建模、流量建模和仿真平台优化,实现了更大规模、更高效的实验。通过多次独立采样和置信区间分析,显著提升了实验结论的可靠性。作者建议未来Tor性能研究应避免单次实验,至少在10%规模、10次以上独立实验基础上进行统计推断,以获得对真实网络有指导意义的结论。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
