
原文标题:TrafficFormer: An Efficient Pre-trained Model for Traffic Data
原文作者:Guangmeng Zhou, Xiongwen Guo, Zhuotao Liu, Tong Li, Qi Li, Ke Xu原文链接:https://doi.org/10.1109/SP61157.2025.00102原文代码:https://github.com/IDP-code/TrafficFormer发表会议:S&P笔记作者:崔文韬@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、研究背景
网络流量数据是由网络实体的交互产生的,不仅封装了相应协议的交互逻辑,而且还包含了网络实体的行为信息。例如,由于所使用的应用程序或浏览网页的不同,流量的特征也不同。网络流量的分析和分类对于安全和管理至关重要。例如,识别恶意软件应用程序使主机能够提醒用户并防止信息泄漏或财产损失;对不同类型的应用程序流量进行分类允许服务提供商区分服务并实施专用的路由策略或排队机制以提高服务质量。
在流量分类任务中,传统的机器学习方法很大程度上依靠专家知识来选择指定的特征(如数据包间隔、数据包大小和协议等)。经过特征工程处理后,这些特征喂给机器学习模型训练。随着深度学习不断发展,研究人员开始直接将原始流量数据直接送入深度学习模型中训练,但是这种方法十分依赖标记数据集的数量与质量,当标记数据稀缺时,基于深度学习的流量分析的有效性和泛化性将受到严重限制。然而相比于传统数据(如图片、文本和声音等)的标签相比,网络流量更加难以标记,需要专业的网络工程师完成。更为重要的是,与攻击相关的流量通常被大量背景流量所掩盖,并且显示出快速变化的模式。
预训练方法有希望解决上述问题。它分为两个阶段:pre-training(预训练)和fine-tuning(微调)。预训练阶段使用未标记的数据以自监督学习方式学习通用知识,微调阶段利用标记的数据以监督学习方式学习特定任务的知识。例如LLM(大语言模型)依赖于从大量未标记的数据中挖掘信息的预训练,从而可以有效地对具有数百亿个参数的大模型进行训练,从而在许多下游任务上取得了卓越的结果。与文本和图像数据相比,网络流量数据更加庞大,并且具有更复杂的行为模式,这使得预训练技术在流量分析和识别任务中的应用成为合理的方法。
然而目前的方法仅仅是在交通数据的表示形式上进行了探索,以适应现有的预训练技术,而在预训练和微调阶段,并未针对交通数据进行专门的定制。为了解决这些问题,本文提出了一个预训练模型TrafficFormer,该模型从未标记的数据中学习基本的流量语义,以提高下游任务的准确性,本文主要贡献如下:
网络流量数据是一种类似自然语言的序列数据,但是其方向和顺序更加重要。因此TrafficFormer在预训练阶段保留了masked modeling(掩码建模)任务,以学习输入的序列关系。此外,TrafficFormer提出了一个Same Origin-Direction-Flow(SODF,相同原始方向流)多分类微调任务,该任务挖掘数据包的方向和顺序信息,从而增强流量数据的表征能力。
网络流量数据是结构化的,并且在数据包头中存在很多冗余信息。在微调阶段,TrafficFormer提出了一种流量数据增强方法Random Initialization Field Augmentation(RIFA,随机初始化字段增强),该方法可以保留流量语义。这种数据增强方法可以使TrafficFormer快速关注重要信息。
2、TrafficFormer架构
TrafficFormer主要分为预训练和微调两个阶段,在预训练阶段主要完成两个任务:MBM(掩码Burst建模)任务和SODF(相同原始方向流)多分类任务。训练好的模型可以适用于各种下游任务包括网站指纹识别、恶意软件检测和协议交互理解任务。考虑到下游任务缺乏训练数据,在微调阶段使用了数据增强。
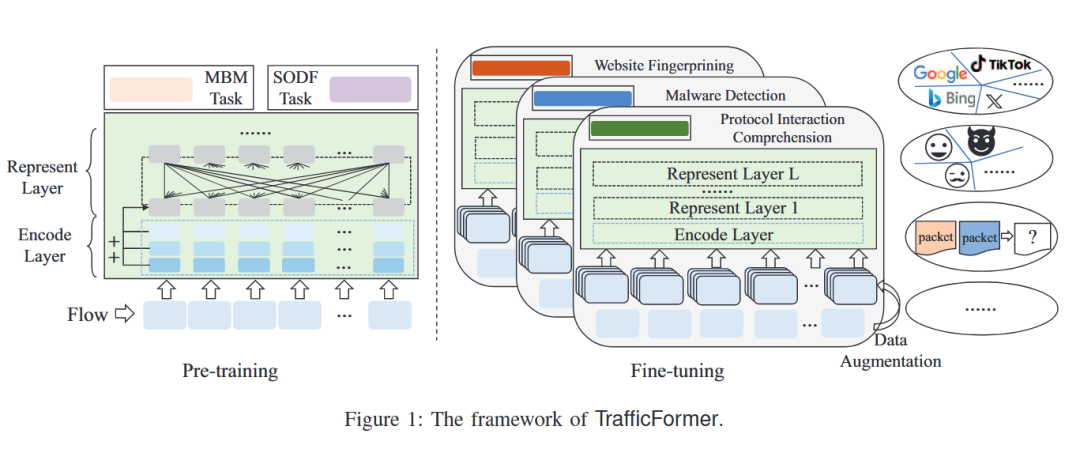
2.1 预训练阶段
数据预处理:首先将流量数据分为多个flow,每个flow进一步分为多个burst(burst定义为在相同方向传输的连续数据包的序列)。每个数据包都是一串十六进制字符串,例如:4504008bd0,TrafficFormer将其转换为Bigrams的形式(一个NLP中的概念)。其中每个字节都与下一个字节连接以形成一个4位十六进制的字符串:4504, 0400, 008b, 8bd0。然后TrafficFormer使用BPE(字节对编码)算法来构建大小为65535个token的字典。BPE算法将训练语料库中的所有单词分解为单个字符,这些字符逐渐合并以形成新单词,直到语料库达到指定的大小为止。将 BPE 应用于双词组能够生成更精细的特征,生成的子词至少包含一个十六进制数字,其长度小于大多数常见的字段长度。此外,该语料库中还包含一些特殊标记,如 [CLS]、[SEP]、[PAD]、[MASK] 和 [UNK]。[CLS] 用于分类任务,[SEP] 用于分隔序列,[PAD] 用于将输入填充至最大长度,[MASK] 用于通过替换被遮蔽的单词来进行遮蔽语言模型任务,而 [UNK] 则表示在语料库中未找到的单词。
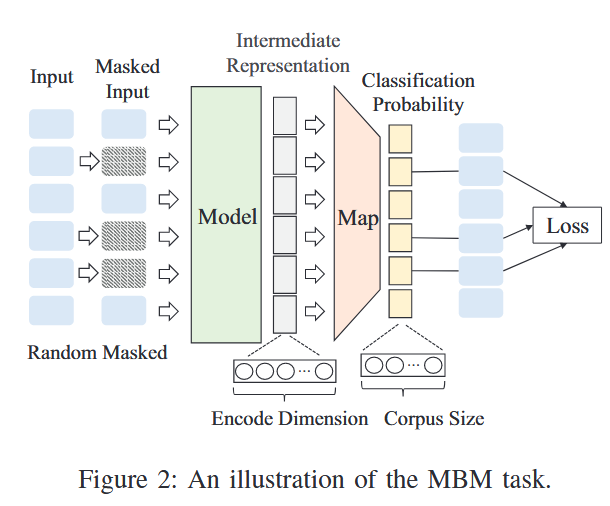
MBM任务:类似于MLM任务,在掩码burst建模(MBM)任务中,输入中的某些令牌被掩盖,要求模型预测这些掩盖的令牌。MBM的输入是爆发,它们是相同方向的连续数据包。
SODF任务:单词的顺序错乱对理解几乎没有影响,而数据包的顺序错乱则可能导致因违反交互逻辑而出现数据包丢失。因此,流量数据中数据包的方向和顺序比文本中的单词顺序更为关键。如图3所示,左边是三个不同的flow,每一个flow都包含不同长度的burst,这些burst共同构成了右边的五类任务,SODF任务将分割后的burst组合成五类:
正常的burst,一个burst由一个[SEP]token隔开。两个部分中各段落标识符分别为1和2.
与类别 1 相同,不同之处在于在分裂后,burst的两段会进行互换。
一个流的连续两个burst,用一个[sep]token分隔开,两个部分中各段落标识符分别为1和2.
与类别 3 相同,不同之处也是分裂后的两段进行互换。 -将来自两个流的burst进行任意组合,并在这些片段之间添加一个“[SEP]”标记以实现区分。
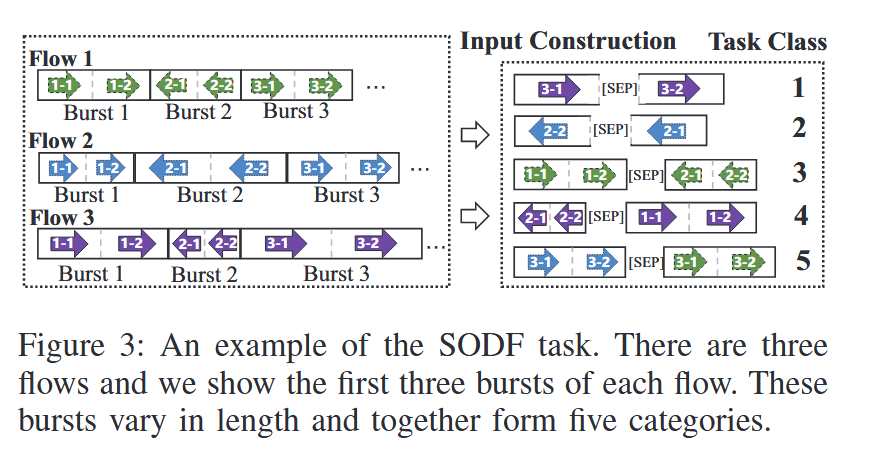
每一个burst都以20%的概率处理为每一个类别,这保证了每个类别的样本数量相同。
预训练阶段采用多任务学习模型,采用多任务学习使得掩码burst建模(MBM)任务的复杂性增加,这是因为同源方向流(SODF)任务中各种输入(不同流量的突发、方向和顺序)的影响所致。这种复杂性有助于增强对流量基本语义的学习。
2.2 微调阶段
在微调阶段,使用预训练模型的参数初始化模型,然后在特定于任务的数据上进行进一步训练。为了确保与预训练过程一致,微调数据被转换为与预训练数据相同的输入格式。首先,将数据包转换为十六进制字符串,然后将其转换为Bigram形式,并使用预训练期间生成的语料库进行token化。数据包令牌是直接连接的,而无需插入[SEP]令牌进行分离,这意味着所有token共享相同的段标识符。
数据增强:由于下游任务往往数据量有限,所以引入了数据增强方法。由于网络协议中某些字段是随机初始化的(如表2所示),它们的值并没有固定的含义,所以直接使用这些字段进行分类会引入噪声。例如有些IP地址和端口会形成shortcut(捷径特征),降低模型泛化能力。文章提出的RIFA方法在保持原始语义和标签不变的前提下,随机改变这些随机初始化字段的值。通过数据增强的方式生成多份变体样本,提高模型鲁棒性。与基于深度学习的数据增强方法相比,RIFA 借助领域知识,直接对原始数据进行修改,而非在特征空间中进行修改。

3、评估
本文的实验部分主要关注三个重点:流量分类任务、协议理解任务和消融实验。
3.1 实验设置
TrafficFormer使用PyTorch 2.0.1实现,在NVIDIA A100上运行。
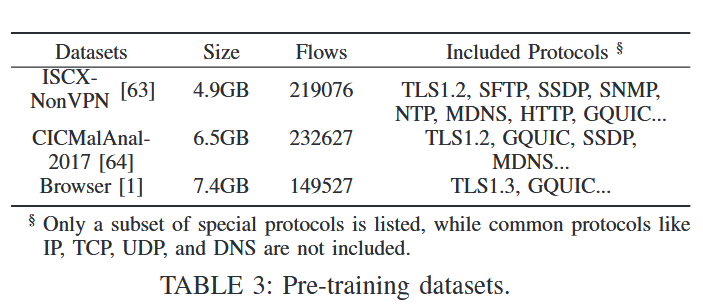
预训练数据集:ISCX-nonVPN、CICMalAnal2017和自建的浏览器数据集。
评估指标:采用分类准确率(AC)、精确率(PR)、召回率(RC)和 F1 分数作为评估指标。对于多分类任务,在计算每个类别的这些指标时,该类别被视为正类,而其他所有类别则被视为负类。为了计算整个数据集的总体指标,对每个类别的指标值进行平均,这有助于平衡不同类别样本数量的差异问题。
3.2 流量分类任务
微调数据集:Cross-Platform (Android)、Cross-Platform (iOS)、ISCXVPN (Service)、ISCX -VPN(App)、CSTNET-TLS 1.3和USTC-TFC。
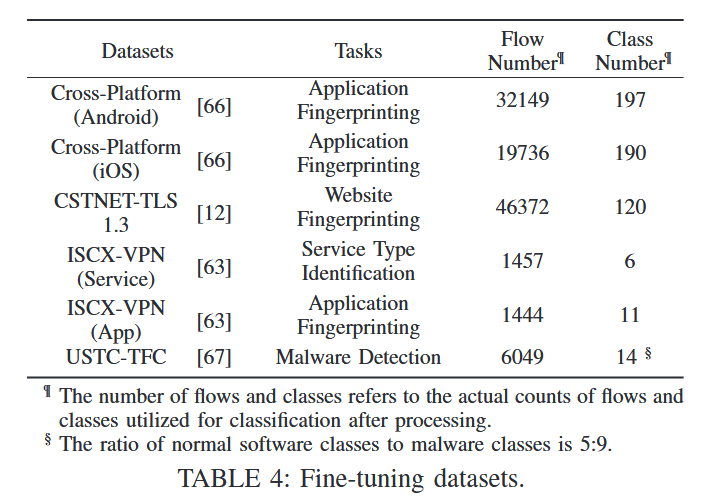
这些数据集包含四个具体的微调任务:应用指纹识别、服务类型识别、网站指纹识别以及恶意软件检测。跨平台(安卓)和跨平台(iOS)数据集分别收集了来自中国、美国和印度的安卓和 iOS 手机上最热门的 100 款应用程序的流量数据。CSTNET-TLS 1.3 包含了使用 TLS 1.3 协议从 120 个网站收集的流量数据。ISCX-VPN(Service)和 ISCX-VPN(App)数据集记录了虚拟专用网络(VPN)中多个应用程序的不同行为所相关的流量,能够将其分类为各种应用程序和服务。例如,Skype 应用程序会产生三种类型的流量,即文本聊天、文件传输和语音聊天。这三种流量类型在 ISCX-VPN(服务)中属于不同的类别,而在 ISCX-VPN(应用)中则归为同一个 Skype 类别。USTC-TFC 数据集包含了 10 个正常软件应用程序和 10 个恶意软件样本所产生的流量。在预训练的数据增强过程中,通过随机初始化包括 IPID、TCP 序列号和确认号在内的字段五次来实现的,这有效地将数据集大小扩大了五倍。
下图展示了TrafficFormer中的注意力机制在CSTNET-TLS 1.3数据集和Cross-Platform(Android)数据集上的应用情况,如图 4a 所示,在Cross-Platform(Android)数据集中,注意力主要集中在两个特定区域。相比之下,如图 4b 所示,在 CSTNET-TLS 1.3 数据集中,注意力分布更为分散,数据包中的多个字节都会影响最终的分类结果。尽管存在这些差异,但这两个注意力图示仍有许多相似之处。对于相同的数据,注意力头之间的差异表明它们关注的数据的不同方面。

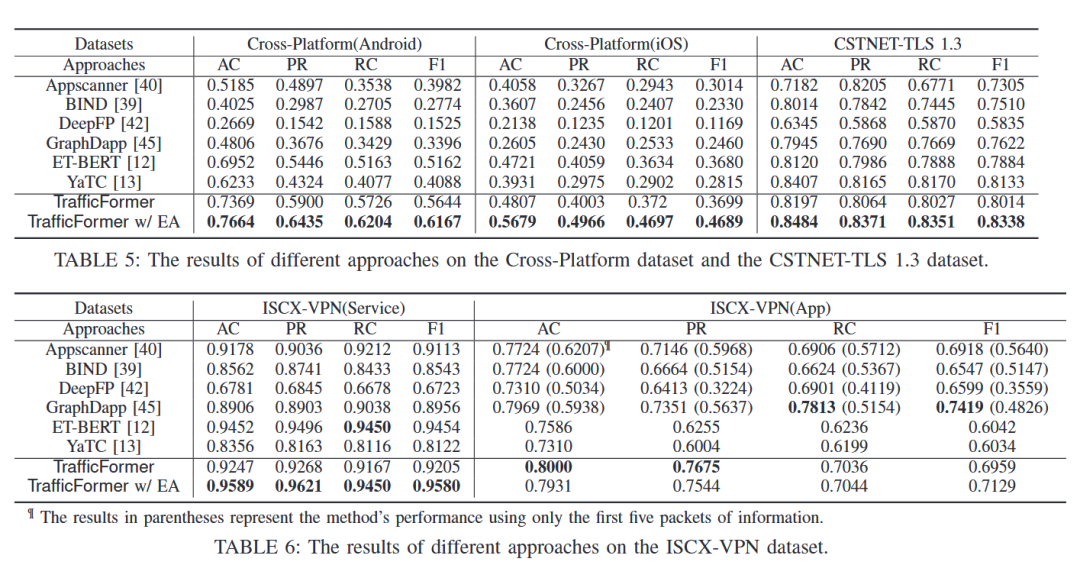
表五和表六展示了TrafficFormer与baseline方法的结果对比,显示了TrafficFormer在几乎全部的数据集和任务中取得了最好的成绩。
3.3 协议理解任务
微调数据集:CSTNET-TLS 1.3和CICMalAnal2017。任务目标:数据包方向判断、数据包丢失检测、数据包乱序检测和数据包预测。
判断两段数据包是否属于同一传输方向:从同一流中随机选取两段数据包,若两者方向一致,标记为 1;若方向相反,标记为 0。
判断序列中是否存在数据包丢失现象:从流中取 N 个连续数据包,通过随机删除第 2 到 N-1 个数据包生成“丢包”样本,标记为 0,不删除的连续包序列标记为 1。
判断序列中是否存在数据包乱序现象:从流中取 N 个连续数据包,随机选择第 1 到 N-1 个包,将其插入到后续位置形成“乱序”样本,标记为 0,原始有序样本标记为 1。
预测下一数据包中指定字段(如 TCP 序列号)的值:对于连续的 N 个数据包,在最后一个包中屏蔽待预测字段(mask token),模型需根据前序包上下文预测该字段。
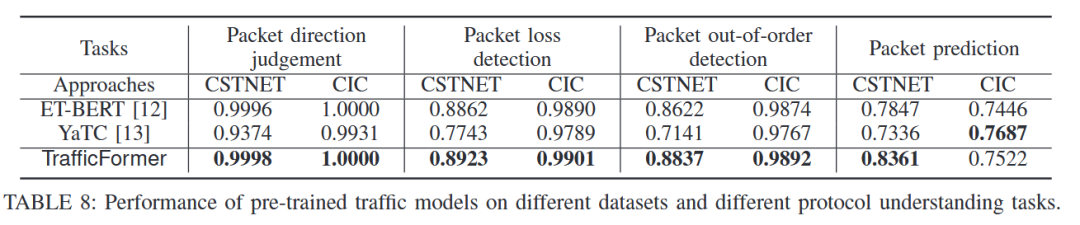
最终结果如下表,与同样是基于预训练模型的方法ET-BERT和YaTC相比,均实现了性能提升。
3.4 消融实验
数据集:Cross-Platform (Android)、CSTNET-TLS、ISCXVPN(App)
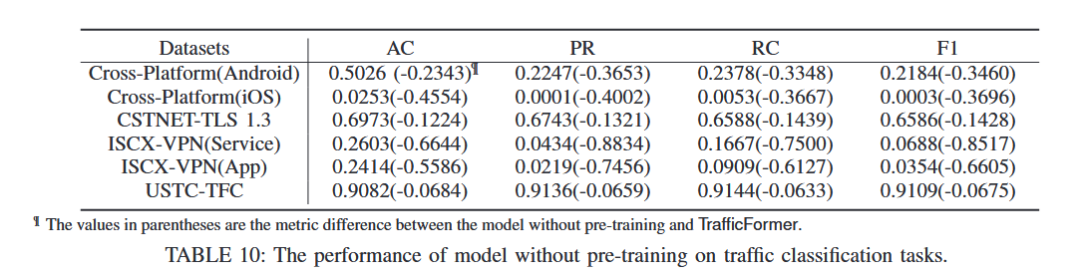
预训练-未预训练效果对比:其中括号内的负值代表与预训练后的模型指标的差值。
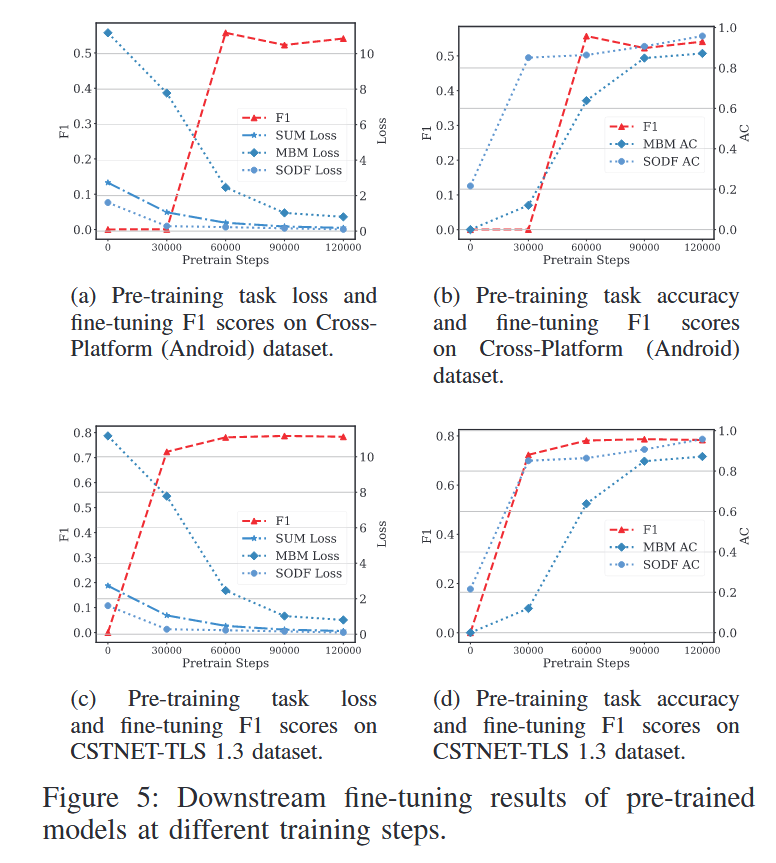
不同微调步数下预训练模型对比:
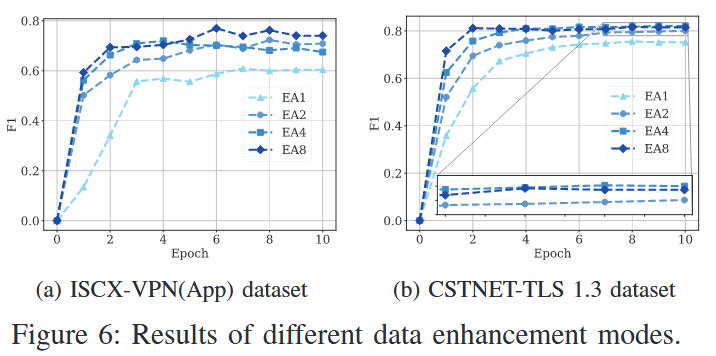
不同数据增强方法对比:
4、本文贡献
基于BERT模型的架构,针对流量数据设计了新颖的MBM和SODF算法用以挖掘数据包的方向和顺序信息,从而增强流量数据的表征能力,提高预训练模型的性能。
针对微调阶段的数据集数量不足的问题,提出了RIFA算法以进行有效的数据增强,提高下游任务的泛化能力。
参考文献:
[1] Zhou, G., Guo, X., Liu, Z., Li, T., Li, Q., & Xu, K. (2025, May). Trafficformer: an efficient pre-trained model for traffic data. In 2025 IEEE Symposium on Security and Privacy (SP) (pp. 1844-1860). IEEE.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
