在自然语言处理领域,“幻觉”(hallucination)通常是指模型在输出中出现事实错误、编造信息或将不存在的对象当作真实存在的情况。研究中常将其分为外在型幻觉(与可验证事实不一致)和内在型幻觉(逻辑自相矛盾或推理链前后不一致)。
GPT-4在多个高风险领域都曾暴露幻觉问题。最典型的案例是美国纽约Mata v. Avianca诉讼中,两名律师引用了ChatGPT生成的虚构判例,最终被法院罚款并在判决书中公开批评。在事实问答与传记类写作中,GPT-4也常出现“信息拼贴”现象,将多个实体或事件时间线混合,导致引用、数据和背景存在错误。在学术引用、医学常识等领域的第三方评测中,这种可重复的错误率同样被记录在案。总体而言,尽管GPT-4较GPT-3.5已显著降低了幻觉发生频率,但在开放域长篇事实陈述及高风险垂直场景中,幻觉问题仍不可忽视。
一、GPT-5的针对性优化措施
GPT-5的系统设计采用了多模型路由结构,包括一个面向日常任务的快速主力模型(gpt-5-main)、一个专门处理复杂任务的“深度思考”模型(gpt-5-thinking),以及一个基于用户请求自动选择模型的路由器。这一架构的核心目的之一就是在需要高事实性和推理能力的任务中,自动切换到更稳健的推理模式,以减少幻觉。
在具体技术路径上,GPT-5首先调整了安全策略,从以往“要么回答,要么拒绝”的硬性分流,转为“安全完成”模式,即在不确定时优先提供高层次、非误导性的回答,而非简单拒绝或随意编造。其次,模型训练中增加了对“欺骗性完成”行为的惩罚,例如假装已执行某个操作或查证事实的情况,并引入“体面失败”机制,让模型在不确定时明确放弃或建议使用外部工具核验。浏览与工具链核查在GPT-5中也被视为一等能力,复杂事实类任务会优先走“逐条核对”的路径。最后,通过并行推理计算和内部推理链监测,GPT-5在生成前能够更充分地评估答案可靠性。
二、评测数据下的实际表现
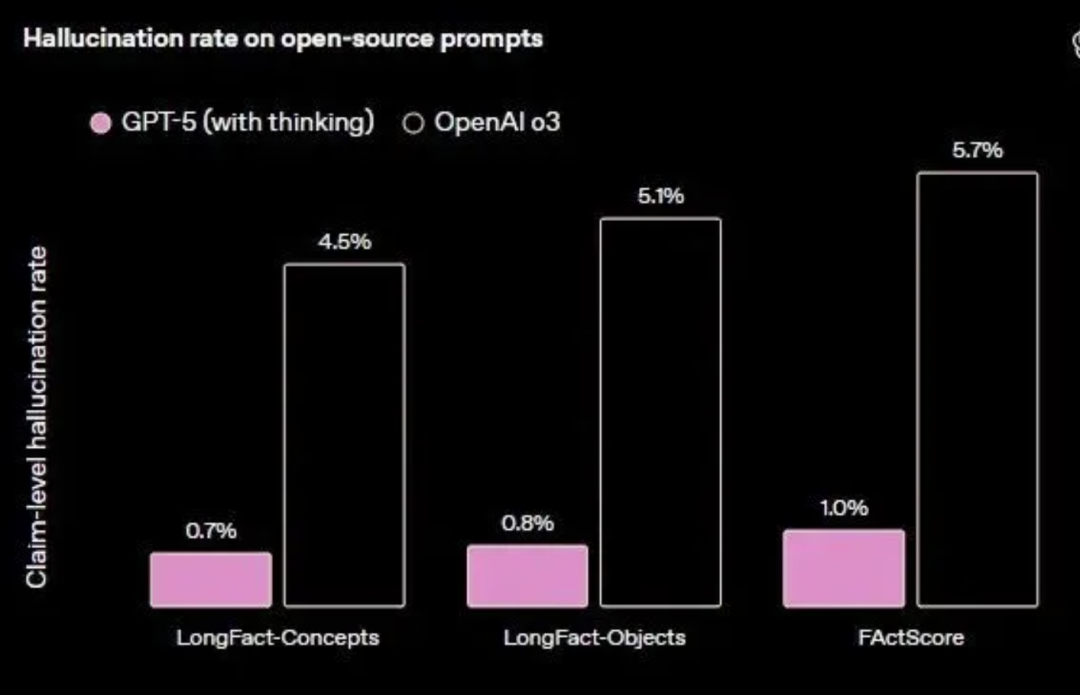
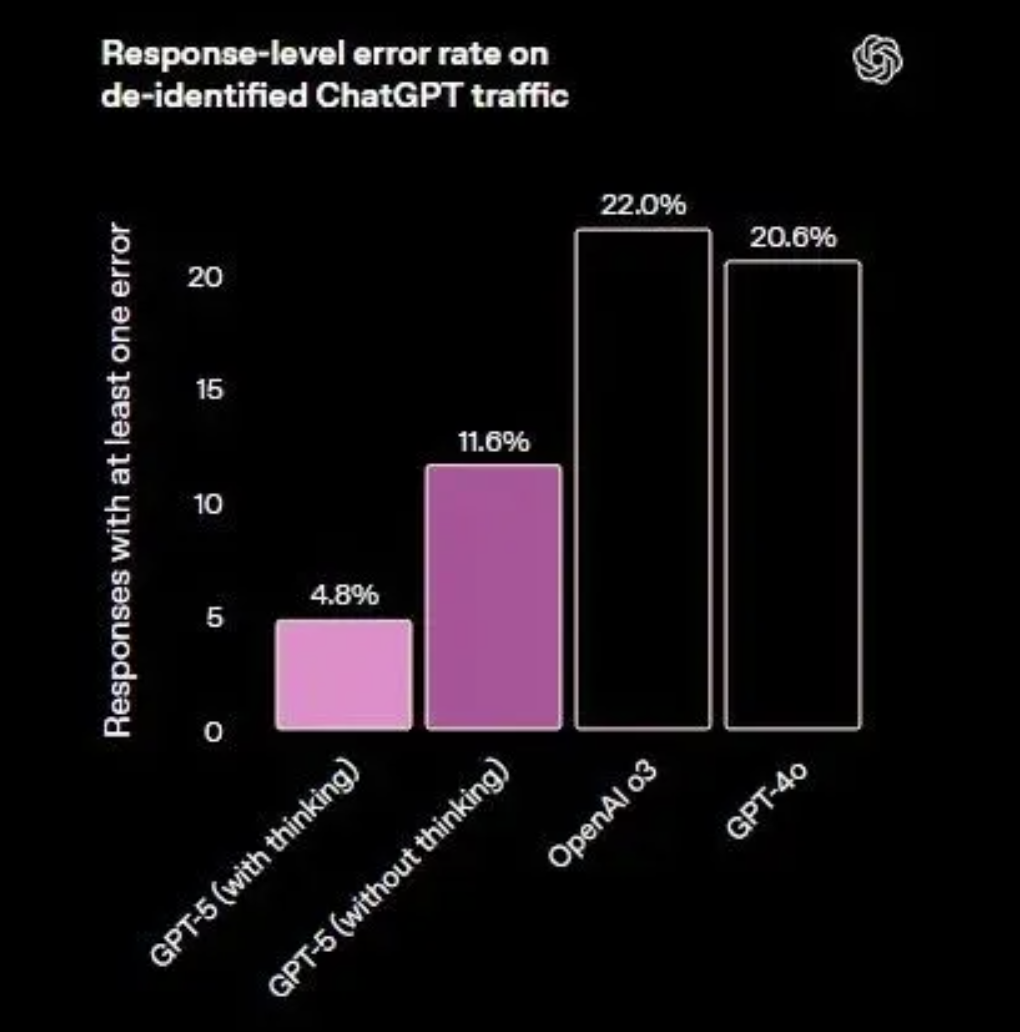
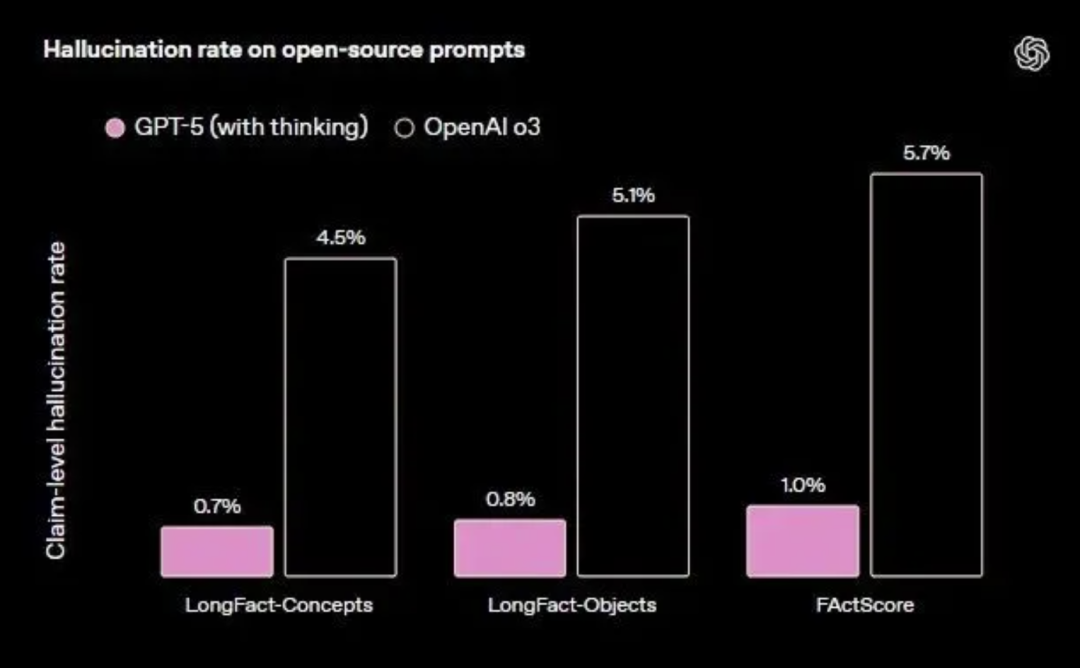
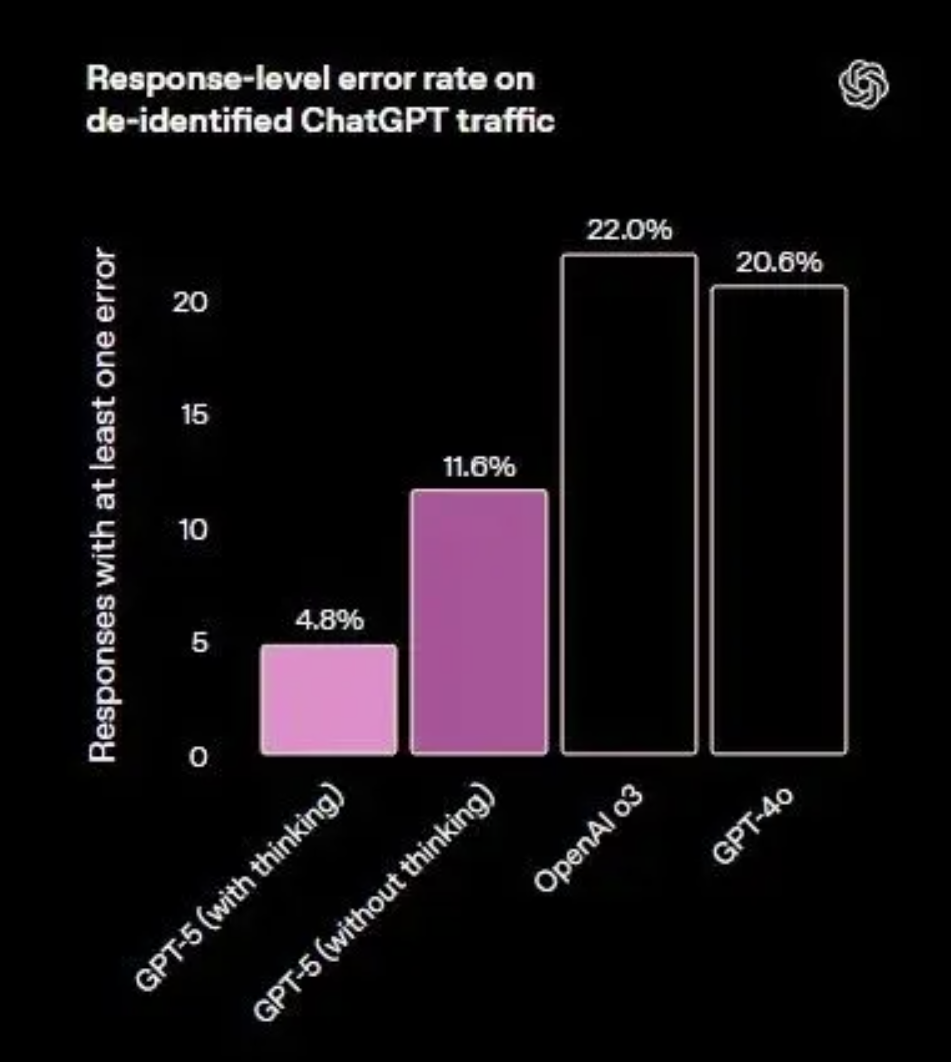
在开放域事实正确性测试中,开启浏览功能的gpt-5-thinking在多套基准中的平均幻觉率显著低于o3,错误量级约为后者的五分之一。在关闭浏览的条件下,GPT-5的表现依然优于GPT-4o和o3,但差距缩小,显示外部工具核验对降低幻觉的贡献较大。在真实用户流量的统计中,gpt-5-main的“含重大事实错误的回答”比例比GPT-4o减少45%,gpt-5-thinking则比o3减少78%。
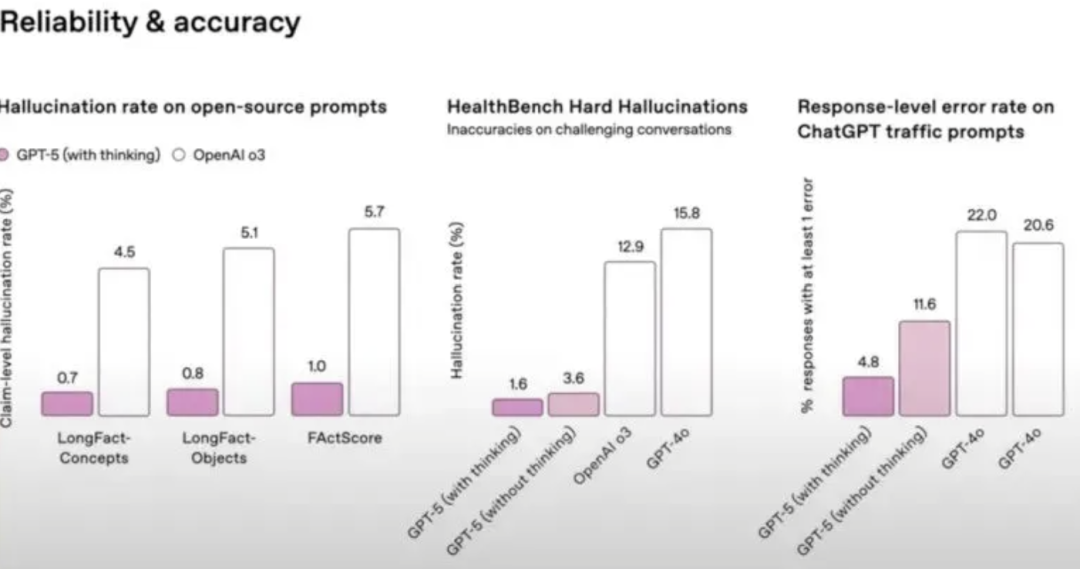
联网搜索:回答事实错误概率比 GPT-4o ↓45%。
独立思考:出错概率比 o3 ↓80%。
诚实沟通:不再拍胸脯保证完成不了的任务,而是直接告诉你「我做不到」。OpenAI 安全团队用 5000+ 小时红队测试,确保 GPT-5 不会「对用户撒谎」。
在高风险垂直领域,医学评测显示,gpt-5-thinking在困难医疗问答场景下的错误率较GPT-4o下降超过50倍,显著减少了不恰当自信的建议。在“知道自己不知道”的评测中,GPT-5的弃答率和识别不确定性的能力也优于前代模型。
在人物传记和事件长文生成中,GPT-5结合浏览功能显著减少了时序混乱和事实拼贴问题。医学建议中,错误率的数量级下降尤其明显,能够更好地反映地域和资源差异。针对迎合性编造的问题,GPT-5更倾向于承认不确定性或建议使用外部工具,而不是硬性生成答案。
对于 Agentic Coding 能力,非常重要的一个方面就是对幻觉率的控制,不然多轮调用模型会导致幻觉累积严重,而且目前实际应用中幻觉是无法被自动定位的,基本只能靠人类验证。GPT-5 也在这方面做了大幅优化,启用网络搜索后,GPT-5 的幻觉率比 GPT-4o 低约 45%;启用思考模式后,GPT-5 的幻觉率比 o3 低约 80%。
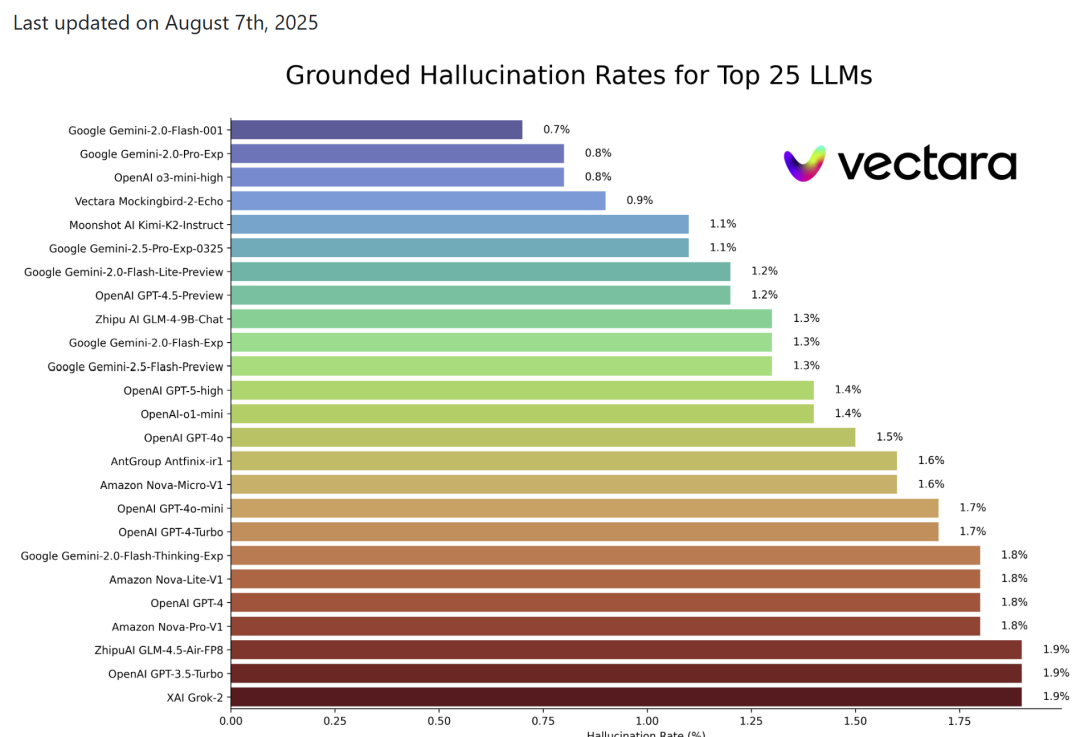
结合 2025 年 8 月 7 日更新的 Hallucination Leaderboard 的 GPT-4o 幻觉率数据估计,GPT-5 的低幻觉率是有竞争第一名的实力的。
改善模型欺骗性也非常具有深远意义,能极大程度减少影响更严重的幻觉,比如歪曲操作过程或谎报任务成功率等。o3 曾被指出在缺乏关键工具时会伪造工具使用。其它问题还包括任务说明不够具体,甚至不可能完成时,一本正经地胡乱操作。
之前的模型在处理这类问题时也比较生硬,只决定完全拒绝或是完全服从。在大多数情况下很有效,但可能被一些巧妙设计的提示词攻击所攻破。GPT-5 大大缓解了这类问题的出现,并且使用了更加灵活的处理方式。
比如,对于看似中性、客观但实际具有危害性的目的( 比如用户询问如何点燃各种烟花中常用的材料的技术细节,可能用于制造炸弹 ),o3、GPT-5 都能准确识别潜在恶意。
o3 一般都是直接拒绝,GPT-5 则可能只部分回答问题,或者只是抽象地回答。如果不得不拒绝,会告诉用户拒绝的原因,并提供安全的替代方案。
三、尚未完全解决的幻觉问题
尽管GPT-5在多个维度取得进步,但仍存在无法彻底避免的幻觉风险。在无检索或无外部工具支持的条件下,开放域事实问答依然可能出现错误。在多跳推理且缺乏外部校验的情境中,模型可能出现细粒度事实混淆。在法律等零容错领域,引用编造的风险仍需额外流程保障。此外,部分宣传材料在早期引发了市场对模型准确性的质疑,也提醒用户应以实际数据与场景评测为依据。
在实际应用中,应优先启用浏览、代码执行等工具化核验能力,鼓励模型在不确定时明确说明或建议外查。在法律、医学、金融等高风险领域,应强制列出来源并进行人工抽检,并在复杂决策类任务中优先使用gpt-5-thinking路线。日常快速问答或通用写作则可使用gpt-5-main,以兼顾效率与准确性。
四、小结
总体来看,GPT-5在开放域事实正确性、长文事实陈述及医学安全等方面相较前代有显著进步,幻觉率在多项评测和真实使用中均明显下降。这一改进得益于多模型路由、深度思考模式、安全完成机制、反欺骗训练及工具化核验等多项措施的协同作用。然而,模型生成与事实数据库在本质上依然不同,在无外部证据链的情境下,幻觉问题依旧存在,特别是在零容错专业领域。这意味着,GPT-5虽已向“少编、能停、会查”方向迈出重要一步,但在高精度事实生成的终极目标上,仍有持续改进的空间。
声明:本文来自清华大学智能法治研究院,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
