基本信息
原文标题:Orion: Fuzzing Workflow Automation
原文作者:Max Bazalii, Marius Fleischer
作者单位:NVIDIA, Santa Clara, USA
关键词:模糊测试,工作流自动化,大语言模型,安全测试,漏洞发现
原文链接:https://arxiv.org/abs/2509.15195
开源代码:暂无
论文要点
论文简介:本文提出并实现了Orion——首个可实现端到端模糊测试工作流自动化的通用框架。尽管当前模糊测试工具高度自动化了输入生成与执行监控,但整体流程仍然存在大量“人工瓶颈”:如攻击面识别、harness合成、种子设计、crash分析与补丁生成等都需人工介入。这极大限制了模糊测试在大规模实用软件中的应用扩展。
Orion创新性地结合了大语言模型(LLMs)在代码理解与推理方面的能力,以及传统确定性工具在验证与细粒度分析上的优势,建立了一套多agent协作的自动化体系。框架以源码及构建信息为输入,自动完成代码库索引、模糊目标识别、种子与harness生成、fuzzing执行、crash triage及自动化修补建议。并通过以工具反馈、提示工程和模型自反等机制,提升LLM生成逻辑的鲁棒性和可用性。在对开源与企业级项目的基准实验中,Orion显著减少了人工工时(46–204倍降幅),并发现了开源库clib中的两个新漏洞,体现了该方法的实用和前沿价值。
研究目的:当前主流模糊测试在输入生成和漏洞监控上已趋于成熟,但整个模糊测试流程——尤其是前期的攻击面筛选与harness自动合成,以及后期结果triage和修复环节——高度依赖人工。人工流程耗时、易错且难以扩展,成为制约大规模软件安全测试自动化的关键瓶颈。既有自动化探索主要聚焦个别环节(如harness生成、输入优化等),缺乏贯穿全流程、模块化协作的一体化系统设计。并且对于高复杂度代码库,传统方法难以充分支持上下文推理与语义理解。
本文试图破解上述难题,设计一种端到端自动化框架,不仅提升整体流畅度、高效解放人力,还能在高风险复杂场景中有效“取代”人类专家完成关键环节,推动生产级模糊工作流的规模化自动化实践。Orion的目标正是通过整合LLM智能与传统工具,将人工密集型工作全面自动化,使得模糊测试能在实际生产环境大规模落地。
研究贡献:
(1)提出Orion,首个集成LLM智能和传统分析工具的端到端模糊测试自动化框架,实现面向生产级代码库的全面自动化和协作式工作流管理。
(2)设计面向模糊测试自动化场景的多种LLM可靠性提升技术,包括以工具辅助校验和反馈驱动优化为核心的验证机制,以及自一致性(self-consistency)、自反思(self-reflection)等高级提示工程手段,用于缓解LLM在语义推理和内容生成中的随机性与误差扩散。
(3)完成Orion的具体实现并在实际开源/商用项目上进行了系统性评估,显著减少人工需求(最高人力节省204倍),并自动挖掘到两个此前未知的真实安全漏洞,充分验证方法的有效性和前瞻性。
引言
模糊测试(fuzzing)一直被认为是漏洞挖掘和软件安全保障领域极为高效的动态分析方法。其核心理念为通过大量构造、变异和灌输随机或格式错乱的输入,触发程序在异常路径下的行为,以揭示深层次的潜在缺陷和安全风险。例如,Google的OSS-Fuzz平台已在1000余个开源工程中发现超过5万个漏洞,syzkaller针对内核安全也有超过8000例bug曝光。这些数据直观证明了fuzzing在学术研究和工业实际中的关键价值。
然而,现有模糊测试在实现产品级别的大规模应用时依旧面临严峻挑战。现代fuzzer能实现输入自动生成与覆盖率反馈,但完整的端到端工作流仍然讨要分析师投入巨量的人工——从代码库审查、目标接口遴选、harness小程序开发,到种子输入的手工构造、crash triage、漏洞溯因乃至修补patch的设计,无一不是“人力瓶颈”。例如,针对一个大型代码库,仅完成攻击面梳理和高质量harness编写往往需数周甚至更长。
过往的自动化相关研究通常针对特定子阶段(如harness合成、输入优化、补丁搜索),而工程师仍需手动拼接这些零散模块,完成一轮完整的模糊测试campaign。更现实地看,部分自动化工具还受制于对单元测试集、可用种子语料等依赖(如UTopia、Skyfire等),无法泛化到全新或定制环境。而传统的自动化补丁、分析系统(如GenProg、SemFix)则在大代码库前难以扩展。
大语言模型(LLM)的兴起为打破这一局限带来新曙光。LLM在源码理解、推理和多步计划等方面表现出色,配合agent范式能够拆解复杂工程任务、自动生成、评审和优化工件。然而,现有LLM自动化探索大多局限于某单一阶段,未形成可直接落地、自动协调的端到端体系。
Orion正是在上述背景下提出。其设计理念为“用其所长”:让LLM专注于高度语义化推理和代码创造,传统工具则负责精细验证和结果校验。通过将LLM输出与工具反馈相融合,并引入多轮自我修正与一致性机制,Orion有效缓解了LLM固有的不确定性,实现了完整模糊测试流程的自动取代与大规模扩展。
评测结果显示,Orion在开源与商用库中的多轮测试大大缩短了人工投入并发现了实际漏洞,验证了这一“AI×确定性工具”的混合范式对软件安全自动化的突破意义。
相关背景
模糊测试(fuzzing)作为动态漏洞分析的核心手段,其原理是用自动生成的输入反复执行目标程序,监控其异常(crash、assert、anomaly)。现代fuzzer往往集成“覆盖引导”机制,将新路径输入保留在种子库,持续演化有效输入结构,并通过sanitizer辅助,这极大提升了漏洞发现效率。有效的fuzzing必须选择对攻击者可达、最有安全意义的接口作为目标,并配备高质量的fuzz harness,将原生输入“解码”为接口所需格式,实现自动初始化、调用与清理。高质量种子加快了fuzzer对复杂输入结构的探索深度。
现实中的“人工fuzzing工作流”则通常包含目标筛选、harness开发、seed设计、自动化执行、crash triage与修复等阶段。当前,除去“fuzzing运行”高度自动,其他各环节仍高度依赖专家理解代码、活用威胁模型与调试技巧完成,各环节前后协同仍需大量手工推进,这限制了生产级fuzzing的自动化规模。
大语言模型(LLMs),如以transformer为核心的GPT-4系,在源码理解、推理、自动补全和多步计划等方面表现出强大能力,已经被大量开发者用作IDE助手、代码解释工具,并在安全领域(自动修补、harness制作、种子生成等)已有多项应用。LLM-agent范式则进一步将模型与外部工具集成,赋能模型环境查询、决策与自我优化。但LLM在源码理解中的“幻觉”、细粒度知识检索错误和上下文窗口限制,使得单纯“全量投喂”或“语言推理”的质量并不稳定,大型代码库尤甚。此外LLM缺乏确定性,输出偶有波动且连锁性误差易扩散,需通过机制校正。
此前相关工作大多集中于个别环节。例如DARPA的AIxCC挑战要求自动发现与修补漏洞,但依托的是已提供的harness,并未解决全面自动化问题。Google OSS-Fuzz、LibLMFuzz等注重“单步增强”,如自动harness合成、seed生成、crash归因与修补建议生成。但这些系统或工具依赖于已有测试、种子或规则,在缺乏预置资源、跨风格、跨项目时应用受限。传统自动化(如GenProg、SemFix等)因高复杂度及语义推理不足,难以直接在企业级代码库规模展开。
Orion的定位即是填补现有成果碎片化、上下游人工拼接的空白,通过LLM—工具双轮驱动,打造成体系的自动化模糊测试工作流,显著提升大规模模糊测试的可用性与实际产出。
Orion框架设计与核心方法
Orion是一套模拟人类fuzzing专家工作流构造的自动化框架。其系统架构遵循“分而治之”思想,将整体流程拆解成若干核心模块,每一环节独立部署专属agent,并通过编译器工具链支持的源码索引实现上下文精准“喂养”。整体流程包括代码库索引(codebase indexing)、目标识别、种子生成、harness构建、fuzzer运行、crash triage与自动补丁建议等关键子模块。
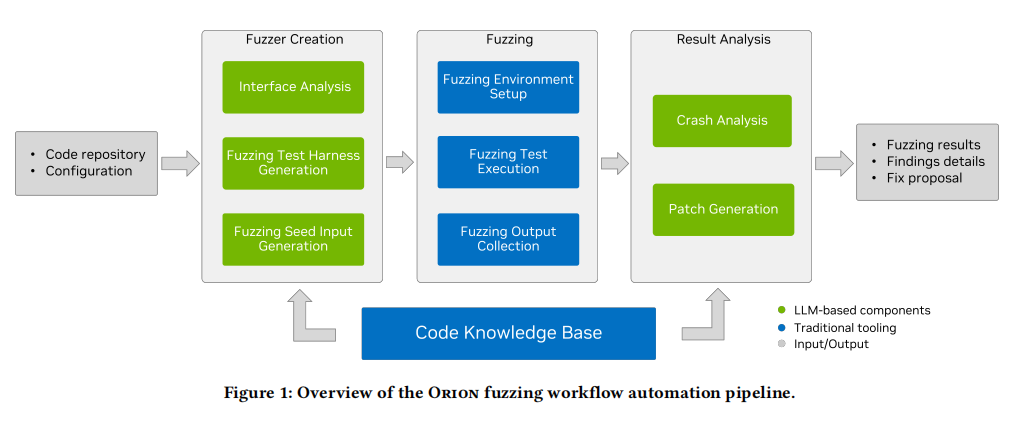
Orion输入为目标项目的源码及编译信息(如编译命令、编译器参数)。流程启动阶段通过indexer组件,基于编译器工具链抽取函数声明、定义、类型、头文件与全局调用图,支持粒度化(以函数为单元)索引检索,有效穿透大规模代码库,实现个性化上下文精准提取。该索引器不仅解决了LLM模型context窗口有限与信息丢失问题,同时为全流程的“相关信息检索”奠定坚实基础。
在目标接口识别环节,系统基于一组安全风险相关的独立指标(如圈复杂度、调用频度、LOC、可达函数数、危险表达和sink函数、解析函数标识等)对项目内所有候选函数评分排序,并由LLM负责对复杂语义特征进行推理与合成解释。为缓解模型输出的不稳定性,Orion采用自一致性(self-consistency)——多次评估同一输入,取众数结果,还引入自反思(self-reflection)机制让模型独立“校阅”自身输出,提高鲁棒性。
种子生成采用“分析先行”策略。由agent自动分析函数签名、输入渠道(文件/参数/全局/网络)、控制流分支、内存管理、错误处理、依赖关系,并以脚本方式生成多样化种子输入,这些种子既是harness构建的格式规范,也是压缩fuzzer熬底层路径世界的高效引导。生成后的脚本被自动执行,通过错误发现与模型自反思闭环进一步精化输出。
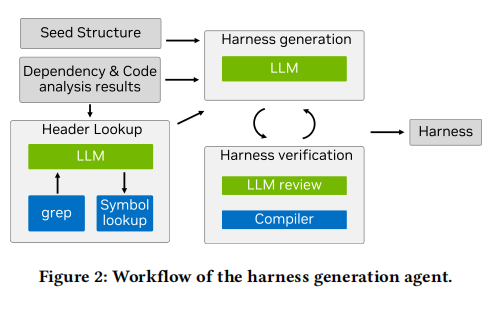
harness自动生成分而治之。先由依赖agent梳理出目标接口的初始化与清理需求,再由harness agent调度索引器收集相关头文件、依赖类型、setup/teardown描述等精确信息,并用LLM合成结构化符合fuzzer约定的harness样例。该过程集成编译器反馈,持续自反思、错误修正直至生成可用、可编译的高质量harness。
执行环节配备独立的fuzzing平台,自动接收由Orion生产的harness与种子,配合标准fuzzer(如libFuzzer、AFL++),在隔离环境下完成高效路径遍历与漏洞发现;运行过程中的coverage数据与错误信息,将驱动上游agent进一步修正harness或调整测试输入,使系统具有关键的“反馈自适应”能力。
crash triage和补丁建议两个子agent接力完成严重崩溃的自动归因、最小复现及补丁设计与验证。crash分析agent自动识别harness假阳性、崩溃归因和堆栈解释,提供最小复现输入;补丁agent则结合代码上下文及复现用例,提出修改建议,并借助编译与回放自动验证补丁有效性,确保结果可直接供开发者审查。
通过上述架构设计与核心技术,Orion将人工专家的所有高价值流程环节由LLM智能与传统工具自动化接管,极大提升了全链路fuzzing自动化与实际适用规模。
各工作流程子模块详解
1. 代码库索引(Code Base Indexing)
代码库索引器是Orion所有后续流程的数据“基石”。该模块通过编译器工具链解析源代码,以函数为最小单元实现结构化chunk划分,充分利用函数定义、类型声明、头文件内容、全局和本地调用关系等供后续agent精准检索。对LLM来说,这极大增强了在大型代码库中的“定位感”与语义细粒度检索效率。例如,harness生成时可直访所需类型定义和依赖,目标识别阶段可聚合对应代码块语境,避免常见“投喂过载”或误解。
2. 目标识别(Target Identification)
此阶段自动识别最值得fuzzing的接口,兼顾攻击面价值与预期bug密度。Orion采用多指标分析:如圈复杂度、被调用频度、代码长度、可达性、危险表达、sink函数出现频次、解析函数识别(尤其靠LLM适配代码习惯与语义辨析)等。各项指标分散提取后,由LLM根据协同提示聚合为候选目标列表,自一致性与自反思极大提升了指标评价的稳定性与多样化代码风格的适配力。
3. 种子生成(Seed Generation)
Orion以“分析先行”为特色,在harness前端自动分析接口参数、输入渠道特征、控制流分支特性、内存管理方式、错误处理与依赖关系等信息,并利用这些分析结果由LLM生成多样种子脚本。通过脚本自动运行可快速确认正确路径/边界/错误,且这些多元输入不仅为fuzzer预热,也是harness代码设计的重要格式描述依据。每轮输出都通过自动化error检测与LLM自检查进行持续精化。
4. harness自动生成(Harness Generation)
该关键环节以两级agent策略确保高质量产出。首先由依赖(agent)深入分析目标接口上下文及全局环境,梳理启动与清理需求(如全局变量/资源/依赖文件等)。随后,由harness agent结合所有依赖、头文件、类型、种子描述等信息,调用LLM生成主干harness代码。该过程通过反复自检与编译反馈闭环,持续消除错误与实际性缺陷,最终输出可直接集成于主流fuzzer的高效harness。
5. fuzzing执行(Fuzzing Execution)
harness与种子生成后,Orion配套的自动化执行平台输入该配置,在隔离环境下调度标准fuzzer,高效开展大规模模糊测试。过程中所有coverage、crash等反馈皆流回Orion,作为“动态修正”迭代的自驱动因素,实现自适应调整。
6. crash triage与自动修补(Crash Analysis & Patching)
crash分析agent负责自动判别崩溃是harness失效还是接口本身漏洞,并通过最小复现定位根因、过滤重复或假阳性,并最终输出调试定位描述、栈踪与复现测试用例。patching agent则结合复现用例和源码,尝试自动合成修补建议,并通过编译与复现验证有效性,每步都在工具与LLM自反馈下闭环,确保自动补丁没有新的副作用或兼容问题,供开发者直接审查和应用。
在此多agent协作架构下,Orion实现了只需最小人工介入即可完整覆盖模糊工作流全链条的深层自动化与动态闭环能力。
实验与效果评估
Orion的评测体系围绕以下四大核心研究问题展开:一是接口/目标函数识别的准确性(二是harness合成质量三是与人力工时对比下的自动化效率提升,四是实际漏洞发现能力)。基准实验在两大类目标——开源库clib、H3以及NVIDIA商业GPIO驱动——上系统性展开。主流程均依赖GPT-4.1为Orion主要推理内核,结果评价则辅以多模型复核(如Llama系列、Nemotron等)。
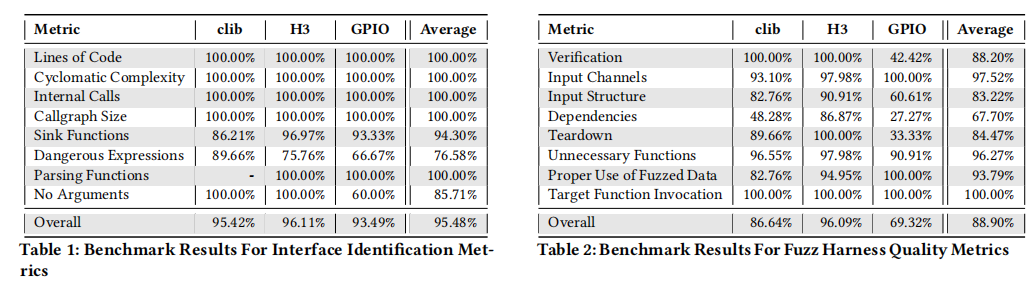
在接口识别测试中,Orion在所有指标上成功率均达95.5%以上,所有基础静态指标如LOC、圈复杂度、调用频率等都100%准确,sink/dangerous expression等高级语义指标、解析函数等也表现不俗,单独任务如无参数函数识别等具备很高准确性。主要障碍为部分复杂头文件或宏处理超出LLM直接能力,但通过自一致提示和上下文优化已大幅缓解。
harness生成阶段平均成功率88.9%,尤其在输入通道、主调函数调用、fuzzer适配等维度表现突出。依赖处理和teardown环节相对薄弱,主要受限于复杂依赖关系跨函数或全局状态解析的困难。GPIO等商用大规模工程环境,复杂性进一步放大。但绝大多数harness能够编译通过并驱动fuzzer获得有效输入与反馈。
人力工时对比方面,Orion在接口筛选、harness编写、漏洞修补三个典型阶段分别节省92倍、204倍和46倍,极大释放了安全分析师的宝贵时间,使分布式、海量模糊测试成为现实可行。
至于漏洞发现,Orion实际在clib项目中,自动暴露了两个此前未知的stack buffer overflow和空指针解引用漏洞,并实现了自动复现与补丁建议。这直接验证了Orion从目标筛选到最后修复的贯穿能力,也证明了其自动化产生的新漏洞发现价值。
实验中还暴露了部分问题:如复杂build环境下依赖自动提取的鲁棒性待提升、高阶环境差异(如不同构建工具、头文件缺失等)会影响全流程流畅度。总体而言,Orion“AI+确定性工具”混合架构已实现高效、高质和实用的自动安全测试闭环,在主流项目上展现出巨大人力解放与实际漏洞发现潜能。
论文结论
本论文提出的Orion框架实现了端到端模糊测试工作流的自动化,首次将大语言模型agent与确定性分析工具深度集成,成功攻克了模糊测试在大规模代码库、复杂流程场景下的人工瓶颈问题。Orion可自动完成从目标识别、种子生成、harness自动合成、fuzzer运行、crash分析到自动补丁建议的全流程闭环,最大限度发挥了LLM在高阶推理与创造上的长处,又通过传统工具确保流程可验证与可复现,极大降低了不确定性和风险扩散。
系统评测结果充分论证了Orion的有效性和前沿性:其接口自动识别与harness合成的准确度高达95.5%与88.9%,典型阶段较人工流程节省工时46–204倍,同时能自动发现真实零日漏洞并完成候选修补建议,为产品级安全测试自动化树立了新标杆。在理论与实践双重层面,Orion体系为混合智能自动化安全测试提供了科学范式与工程路径。
未来工作中,进一步提升依赖分析精度、补强复杂build环境的适配、构建更严密的补丁校验与适配机制,将驱动Orion体系更广泛落地于产业与更大规模工程场景。而Orion架构的可插拔、模块化特性也将促进社区创新,实现自动化安全测试的体系化、规模化演进。Orion的成功难能可贵地推动了传统安全测试范式向高自动化、智能协同的新时代跃迁。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
