
前情回顾·AI Agent安全研究
安全内参11月10日消息,想象一下,一个叫邮件机器人(Email-Bot)的个人AI代理,它专门帮你管理邮箱。为了高效运行并真正发挥作用,邮件机器人可能需要具备以下功能:
访问来自不同发件人的未读邮件内容,以便生成有用的摘要;
阅读您的收件箱,追踪重要的更新、提醒或上下文;
帮您回邮件或发送后续跟进邮件。
虽然这样的自动邮件助手能带来极大便利,但它也揭示了AI代理带来的新型安全风险。其中,业界当前面临的最大挑战之一就是:提示注入攻击。
提示注入是所有大模型中一个根本性弱点,尚未得到解决。当某些不可信的字符串或数据被输入代理的上下文窗口时,就可能导致意想不到的后果:例如忽略开发者的指令和安全指南,或执行未经授权的操作。这种漏洞足以让攻击者控制代理,从而对用户造成实质性损害。
以邮件机器人为例,如果攻击者在发送给用户的邮件里植入提示注入代码,一旦该邮件被处理,他们就可能劫持这个AI代理。攻击方式包括窃取敏感信息(如私人邮件内容),或执行不希望发生的操作(如向目标用户的朋友发送钓鱼邮件)。
和许多同行一样,Meta AI团队对“具备代理能力的AI”在提升生产力、改善生活方面的潜力感到兴奋。要实现这一愿景,像邮件机器人这样的AI代理需要更多能力,包括:
访问未知来源的数据(例如收件的邮件或来自互联网的内容);
调用授权的私人或敏感数据,以便规划并实现更个性化的服务;
自主调用各种工具替用户完成任务。
Meta AI团队正在深入思考,如何在提供最大实用性与灵活性的同时,尽量降低提示注入带来的负面影响,比如隐私泄露、被迫代表用户执行任务或系统中断。为此,该团队提出了一个名为“代理二元规则”(Agents Rule of Two)的安全框架,用于最大程度保护用户和系统免受这类已知风险。遵循这一框架,可以显著降低安全风险的严重性。
这个框架的灵感来自Chromium的命名方式,以及Simon Willison提出的“致命三重奏”(LethalTrifecta)概念,旨在帮助开发者更好地理解并权衡当前强大代理系统的风险与收益。
什么是“代理二元规则”
总体来说,“代理二元规则”规定:在我们还无法可靠检测并阻断提示注入之前,AI代理在单次会话中最多只能同时具备以下三项特性中的两项,以避免提示注入造成最严重的后果:
能处理不可信输入;
能访问敏感系统或私人数据;
能修改状态或与外部通信。
当然,有时执行某个请求确实需要三项特性兼具。若代理在不重启会话(即不重置上下文)的情况下必须同时拥有三项能力,就不应让它完全自主运行,至少需要人工介入监督。例如,可通过“人在环中”(human-in-the-loop)审批或其他可靠验证机制来保障安全。
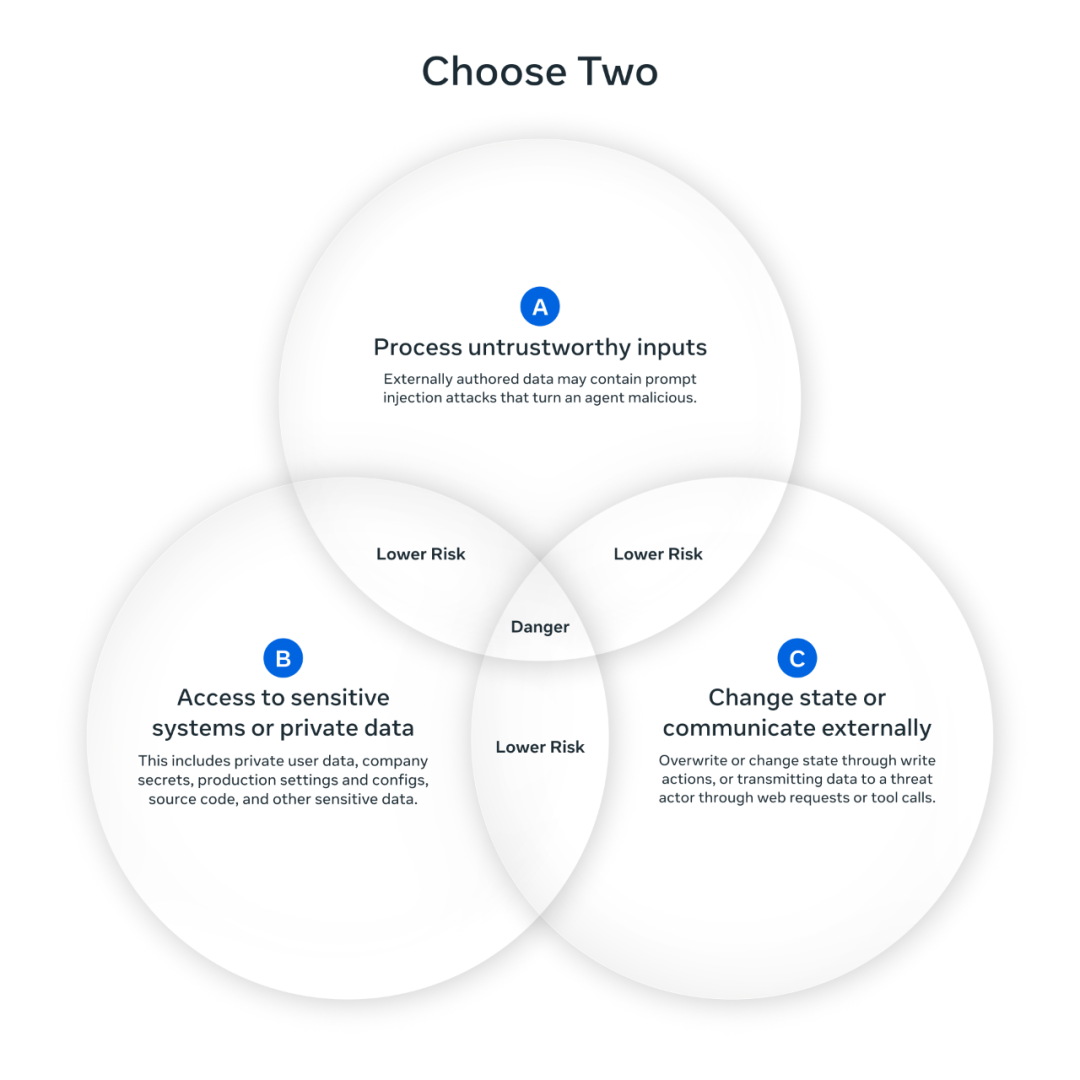
图:三选二
代理二元规则如何阻止攻击
让我们回到邮件机器人的例子,看看“代理二元规则”如何防止数据外泄攻击。
攻击场景:一封垃圾邮件中含有提示注入代码,指使邮件机器人收集用户收件箱中的私人内容,并通过“发送新邮件”工具把这些数据转发给攻击者。
攻击成功的原因在于:
[A]代理能访问不可信数据(垃圾邮件);
[B]代理能访问私人数据(收件箱);
[C]代理能与外部通信(发送新邮件)。
根据“代理二元规则”,可以通过以下几种方式阻止攻击:
[BC]配置:代理只处理来自可信发件人的邮件(如亲密好友),阻止恶意提示注入进入上下文窗口;
[AC]配置:代理无法访问任何敏感系统或数据(例如仅在测试环境中运行),即使提示注入成功,也不会造成实际损害;
[AB]配置:代理只能向可信收件人发送邮件,或在人工审核草稿后再发送,从而切断攻击链。
通过“代理二元规则”,开发者可以权衡不同设计之间的取舍(例如操作复杂度与功能限制),找出最符合用户需求的方案。
“代理二元规则”的假设示例与实践
下面举三个假设场景,看看不同类型的代理如何遵循这一框架。
旅行助理代理[AB]
这是一个面向公众的旅行助理,可以回答问题并代用户执行操作。
它需要通过网络搜索目的地的最新信息[A],并访问用户的私人资料来完成预订与购买[B]。
为符合“代理二元规则”,我们在其通信能力[C]上增加预防性控制:任何操作(如预订或支付定金)都需人工确认;限制网络请求仅访问可信来源的URL,避免代理随意生成地址。
网页浏览研究助理[AC]
该代理可与浏览器交互,代表用户进行资料研究。
它需要填写表单、向任意URL发送请求[C],并分析返回结果[A]以便根据需要重新规划。
为满足“代理二元规则”,我们在访问敏感系统与私人数据[B]方面增加预防性控制:在受限沙箱环境中运行浏览器,不加载任何预设会话信息;限制代理访问初始提示之外的私人数据,并告知用户数据的共享方式。
高速内部编码代理[BC]
该代理能在公司内部基础设施中生成并执行代码,帮助解决工程问题。
为解决实际问题,它必须访问部分生产系统[B],并可对这些系统进行有状态更改[C]。虽然“人类在环”仍是一种重要的纵深防御手段,但开发者希望尽量减少人工干预,以提升运行效率。
为遵循“代理二元规则”,我们在不可信数据[A]上增加预防性控制:通过作者来源追踪(author-lineage)机制过滤代理上下文窗口中处理的所有数据源;提供人工审核流程,标记误报并授权代理访问必要数据。
正如所有通用安全框架一样,关键往往在细节。为了支持更多使用场景,可以允许代理在同一会话中安全地从一种“代理二元规则”配置切换到另一种。例如,代理可先以[AC]配置访问互联网,再在访问内部系统时禁用通信,单向切换至[B]配置。
虽然具体实现细节略去,但只要能阻断攻击路径,即防止攻击完成[A]→[B]→[C]的完整链条,这种转换就是安全的。
局限性
需要强调的是,遵循“代理二元规则”并不意味着能防御所有代理常见威胁,如攻击者能力升级、垃圾内容泛滥、代理失误、幻觉、权限过高等问题。它同样无法防止提示注入导致的低影响事件(例如代理回复中的错误信息)。
此外,“代理二元规则”也不是风险控制的终点。即使满足规则,系统仍可能因用户误操作(如在未仔细确认的情况下点击警告框“确认”按钮)而失效。在单层防御不足的情况下,纵深防御依然是应对高风险场景的关键。“代理二元规则”应被视为对传统安全原则(如最小权限原则)的补充,而非替代。
与“代理二元规则”配合使用的AI防护机制,可以参考Meta AI的Llama安全体系。
它的功能包括:用于协调代理防护的LlamaFirewall、防御潜在提示注入的PromptGuard、减少不安全代码建议的CodeShield,以及识别潜在有害内容的LlamaGuard。
下一步
Meta AI团队认为,“代理二元规则”是当前对开发者最有价值的安全框架,并对其在安全规模化开发中的潜力充满期待。
随着通过模型上下文协议(MCP)等机制实现的即插即用型代理工具调用逐渐普及,该团队看到了新的风险与机遇。虽然盲目地将代理连接到新工具可能带来严重后果,但如果在设计阶段就内建“二元规则”意识,即从默认安全出发,便有望实现真正安全的自动化。例如,在工具调用时声明当前“代理二元规则”配置,开发者即可更准确地判断某个操作是否会成功、失败,或需要额外审批。
Meta AI团队也意识到,随着代理功能增强、用途拓展,一些高需求场景可能难以完全遵循“代理二元规则”,例如无法加入人工环节的后台进程。因此,虽然传统软件防护与人工审批仍是目前实现该规则的主要方式,该团队也在研究如何通过一致性控制(如监督代理与开源的LlamaFirewall平台)来实现基于“代理二元规则”的自动化审批。
参考资料:https://ai.meta.com/blog/practical-ai-agent-security/
声明:本文来自安全内参,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
