近年来,深度伪造检测领域技术演进呈现指数级增长态势,在多种基准测试集上持续刷新性能指标上限。然而,当前研究对深度伪造检测模型公平性维度的系统性评估与优化机制关注度较低,存在研究投入缺口。本文带来一篇WACV论文《Improving Fairness in Deepfake Detection》[1],该文献提出了在算法层面优化深度伪造检测器公平性的方案。
一. 深度伪造检测器的公平性研究
深度伪造技术通过替换人物面部或表情生成逼真图像或视频,已经被用于虚假政治信息宣传、金融诈骗等恶意场景。尽管现有的深度伪造检测技术在准确率上表现优异,但其公平性问题日益突出。
深度伪造检测的公平性属于人工智能治理领域的一个议题,目前的研究仍处于探索阶段。深度伪造检测的公平性问题指的是检测模型在特定群体上出现性能表现偏差,例如对浅肤色群体(拉丁裔等)的检测准确率显著高于深肤色群体(非裔、亚裔等)。出现这种偏差的原因主要在于训练数据不均衡[2],现有的公开深度伪造检测数据集(FaceForensics++、Celeb-DF等)多以欧美人群为主,包含的人脸样本在文化背景、肤色及年龄等方面缺乏多样性,导致模型在面对少数人群时误判率更高。另外,数据标注者的个人理解差异也会引入系统性偏差[3],从而影响检测模型公平性。
二、深度伪造检测公平性优化方法
该文献提出两种基于条件风险价值(Conditional Value-at-Risk, CVaR)的公平性优化方法,适用于现有基于深度学习的深伪检测器:
DAG-FDD(Demographic-AGnostic FDD):不依赖统计学属性信息,无需指定敏感属性,适用于数据集未收集统计学属性的场景。通过隐式群体划分并为少数组指定一个概率阈值,保障所有满足概率阈值的群体均达到低错误率目标,避免因忽略隐式群体特征导致的检测性能偏差。
DAW-FDD(Demographic-AWare FDD):整合统计属性信息,使用现有公平性风险度量框架实现算法公平性优化,并同时进行群体间损失均衡化和群体内损失最小化,确保用户定义的特定群体间损失值均衡且所有群体整体损失得到降低。
2.1 DAG-FDD
DAG-FDD(Demographic-Agnostic Fair Deepfake Detection)通过分布鲁棒优化中的 CVaR(Conditional Value-at-Risk)技术,隐式优化所有潜在群体的检测公平性。算法流程如下图1所示,输入训练集和用户指定的最小群体概率阈值,通过最小化CVaR损失函数,最终输出公平性得到优化的检测器参数。

图1 DAG-FDD算法流程图
由于DAG-FDD无需显式标注的人口统计信息(如种族、性别等属性标签),而现有深度伪造数据集大多不具备这类人口统计学标注,因此DAG-FDD可直接应用于这些数据集。
同时,在计算效率上,DAG-FDD在训练过程中仅增加了二分搜索步骤,训练时间与原始检测器是相近的。
2.2 DAW-FDD
有别于DAG-FDD,DAW-FDD(Demographic-aware Fair Deepfake Detection) 利用显式的人口统计标注,通过分层CVaR损失优化群体间、群体内的公平性。
DAW-FDD的输入包括训练集、群体级阈值和群体内阈值。在训练过程中进行分层优化,对于群体间公平性,采用最小化群体级CVaR损失以确保群体间的损失均衡;对于群体内公平性,使用CVaR估计群体的风险以解决真实和伪造样本的不均衡问题。最终输出公平性得到优化的检测器参数。
2.3 算法对比
两种算法适用于不同场景和不同数据:
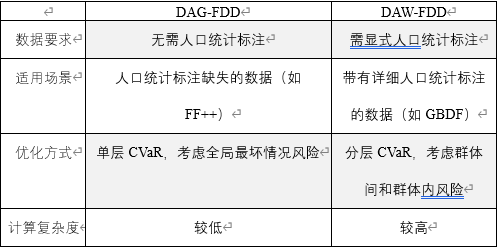
表 1 DAG-FDD 和DAW-FDD对比
2.4 实验结果
实验设置:
实验使用的数据集:FaceForensics++ (FF++)、Celeb-DF、DeepFakeDetection (DFD)、Deepfake Detection Challenge (DFDC)。
实验数据人口统计标注:单属性(性别、种族)标注,交叉属性组合标注。
评估指标:公平性指标(FPR Gap、Equal FPR、Equal Odds),检测性能指标(AUC、FPR、TPR、ACC)。
检测模型:Xception、ResNet-50、EfficientNet-B3、DSP-FWA、RECCE。
实验发现,所有使用到的检测模型均能通过DAG/DAW-FDD提升公平性,并保持甚至提高模型的检测性能,有效地平衡了深度伪造检测性能和公平性。同时也应注意到,DAG/DAW-FDD算法假设样本间是独立的,因此可能不适用于图结构数据。
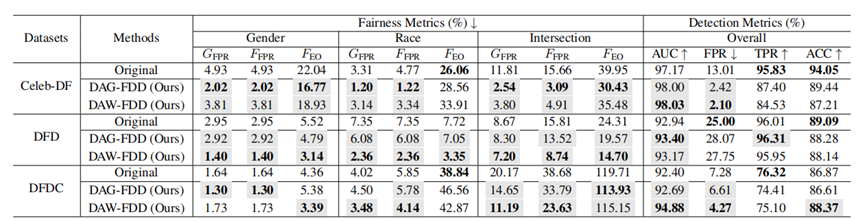
图 2 在Xception检测器上的表现
三、总结
这篇文献提出的公平性优化技术突破了传统数据平衡方法的高成本限制,为公平性研究提供了可扩展的算法框架,为构建可信深度伪造检测系统提供了技术方案。深度伪造检测模型的公平性研究仍存在样本标注成本高、泛化能力有待提升等问题,未来相关研究工作可以探索在检测中进行多模态学习、元学习等技术融合,以增强公平性算法的泛化能力、降低对标注数据的依赖,并制定涵盖多样化敏感属性的跨地域评估标准,推动行业标准的形成。
内容编辑:创新研究院 杨鑫宜
责任编辑:创新研究院 舒展
参考文献
[1] Ju Y, Hu S, Jia S, et al. Improving fairness in deepfake detection[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2024: 4655-4665.
[2] A. V. Nadimpalli and A. Rattani, “GBDF: gender balanced deepfake dataset towards fair deepfake detection,” arXiv preprint arXiv:2207.10246, 2022. 1, 2, 3, 6, 15
[3] L. Kim, “Fake pictures of people of color won’t fix AI bias,” in WIRED, https://tinyurl.com/yc4dsyms, 2023. 1
本公众号原创文章仅代表作者观点,不代表绿盟科技立场。所有原创内容版权均属绿盟科技研究通讯。未经授权,严禁任何媒体以及微信公众号复制、转载、摘编或以其他方式使用,转载须注明来自绿盟科技研究通讯并附上本文链接。
声明:本文来自绿盟科技研究通讯,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
