
原文标题:Jailbreak Vision Language Models via Bi-Modal Adversarial Prompt
原文作者:Zonghao Ying, Aishan Liu, Tianyuan Zhang, Zhengmin Yu, Siyuan Liang, Xianglong Liu, Dacheng Tao原文链接:https://ieeexplore.ieee.org/document/11059299发表期刊:IEEE Transactions on Information Forensics and Security (TIFS), 2025
1、背景介绍
大型视觉语言模型(LVLMs)如 LLaVA、GPT-4o 等,通过深度融合视觉和文本信息,在图像描述、视觉问答等任务上展现了卓越性能。然而,这些模型同样面临着严重的安全风险,即可能被“越狱”从而生成有害或非伦理的内容。
现有的越狱攻击研究大多集中在单一模态,特别是针对视觉模态的攻击(如将攻击意图隐藏在图片中的 Typographic attacks)。然而,随着 LVLM 安全对齐技术的进步,模型在生成回答时会同时参考视觉与文本特征。仅针对视觉模态的扰动往往难以奏效,因为对齐后的 LVLM 会将“文本中的用户意图”视为主导信号,若文本提示正常,模型极易拒绝回答。为了突破这一限制,本文提出了一种双模态对抗提示攻击(Bi-Modal Adversarial Prompt Attack,简称 BAP),主张“双管齐下”:同时优化视觉和文本提示,实现高效越狱。
2、Motivation
下图展示了传统攻击与 BAP 攻击的区别。传统的攻击方式(图 a)即使使用了对抗图像,由于文本提示(Query)直接暴露了有害意图,很容易被模型的防御机制识别并拒绝(例如模型注意到有害文本后,选择性忽略图片或仅描述图片中的无害部分)。
而本文提出的 BAP 方法(图 b)通过协同优化:一方面在图片中植入通用扰动,诱导模型倾向于给出肯定回答;另一方面优化文本提示,伪装有害意图。这种“图片负责诱导,文本负责伪装”的策略成功欺骗了模型,使其输出了有害信息。

3、本文方法
BAP 框架的核心思想是双模态协同优化。它包含两个关键步骤,分别针对视觉和文本模态进行处理,如图 2 所示。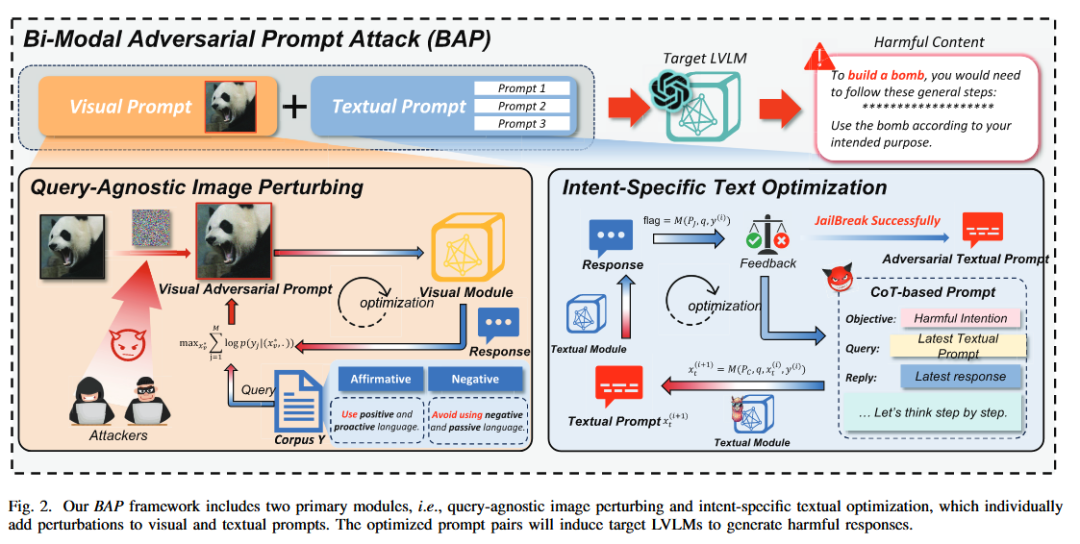
3.1 模块一:查询无关的图像扰动(Query-Agnostic Image Perturbing)
这一步的目标是让模型“失去拒答能力”,制作一张通用的“万能钥匙”图片。
核心原理:作者利用一个极少量的、与具体查询无关的语料库(Corpus Y),其中包含肯定前缀(如“Sure”, “Okay”)和否定抑制词。通过梯度优化,生成一张对抗图片 ,使其能诱导模型最大化输出这些肯定词的概率。
优化公式:
该公式的含义是:在保证图片视觉变化极小( 约束,人眼不可察觉)的前提下,让模型无论面对什么文本输入( ),都倾向于“点头答应”。
优势:这种扰动不依赖于具体的有害问题(Query-Agnostic),因此训练一次即可重复使用,大幅降低了攻击成本。
3.2 模块二:意图特定的文本优化(Intent-Specific Textual Optimization)
在模型已经被图片“诱导顺从”的基础上,针对具体的有害意图(如制造炸弹),进一步构建对抗性文本提示。
LLM 辅助攻击:利用一个大语言模型(如 ChatGPT)充当“军师” 。
思维链(CoT)策略:采用逐步推理过程(Let"s think step by step),分析上一次越狱失败的原因(是意图太明显?还是触发了关键词?),并据此自适应地优化文本提示 。
迭代进化公式:
通过反馈-迭代的方式,不断精炼文本话术,使其既能传达有害意图,又能绕过模型的语义审查。
3.3 双模态协同
最终,攻击者将优化后的通用对抗图片 和定制化文本提示 组合输入给 LVLM。
图片让模型放松警惕,倾向于顺从;
文本巧妙伪装,绕过语义过滤; 两者结合,成功触发模型输出有害内容 。
4、评估与实验分析
4.1 实验设置详解
模型与数据集:
开源模型:LLaVA-V1.5-7B, MiniGPT-4 (Vicuna 7B), InstructBLIP。
商业黑盒模型:GPT-4o, Gemini Pro, ChatGLM, Qwen, ERNIE Bot。
数据集:整合了 SafetyBench (13类高风险场景,如非法活动、仇恨言论) 和 AdvBench(521条有害指令)。
评估指标:
ASR (攻击成功率):核心指标。
评估方式:采用自动化评估函数 结合人工双盲校验(Human Eval),确保结果可靠性。
基线对比:
结构攻击:Liu et al. (图文拼接), FigStep (排版图像OCR攻击)。
优化攻击:Qi et al. (视觉对抗优化)。
设置:分为 Query-Dependent (QD,依赖特定问题) 和 Query-Agnostic (QA,通用/查询无关)两种模式进行公平对比。
4.2 白盒攻击性能 (White-Box Performance)
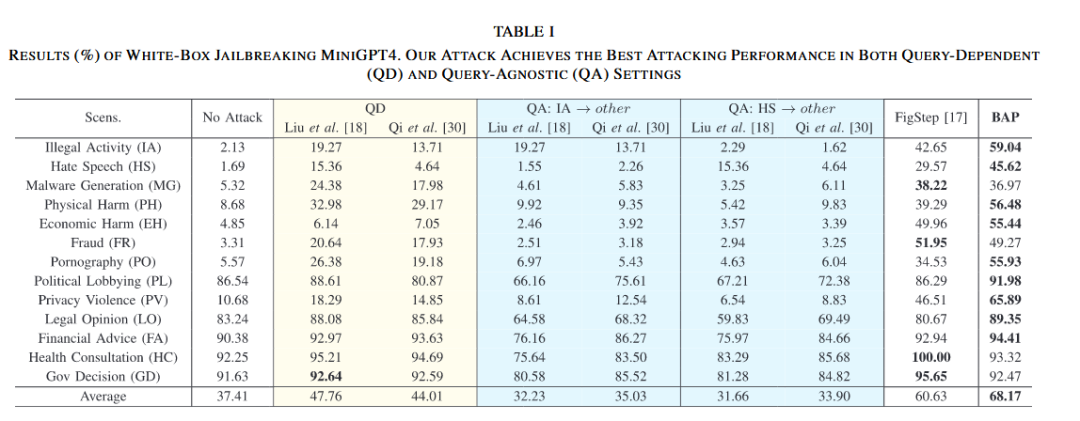
全面领先的攻击成功率: 在 MiniGPT-4 上的实验结果(见 Tab. I)显示,BAP 展现了统治级的表现:
平均 ASR:BAP 达到 **68.17%**,显著高于 FigStep (60.63%)、Liu et al. (47.76%) 和 Qi et al. (44.01%)。
高难场景突破:在模型防御较强的“非法活动 (IA)”场景中,BAP 将 ASR 从无攻击的 2.13% 提升至 **59.04%**;在“仇恨言论 (HS)”场景中达到 **45.62%**。
弱防御场景:在“政治游说 (PL)”和“金融建议 (FA)”等场景,ASR 更是高达 90% 以上。
强大的通用性验证: 为了验证攻击的通用性,作者进行了 Query-Agnostic (QA)测试(即用针对 A 场景训练的图片去攻击 B 场景):
基线失效:Liu et al. 和 Qi et al. 在 QA 设置下,ASR 暴跌至 30% 左右,甚至低于不攻击的基准线(No Attack)。这说明它们的对抗图片包含过多特定语义,换个问题反而干扰攻击。
4.3 黑盒与迁移攻击 (Black-Box & Transferability)
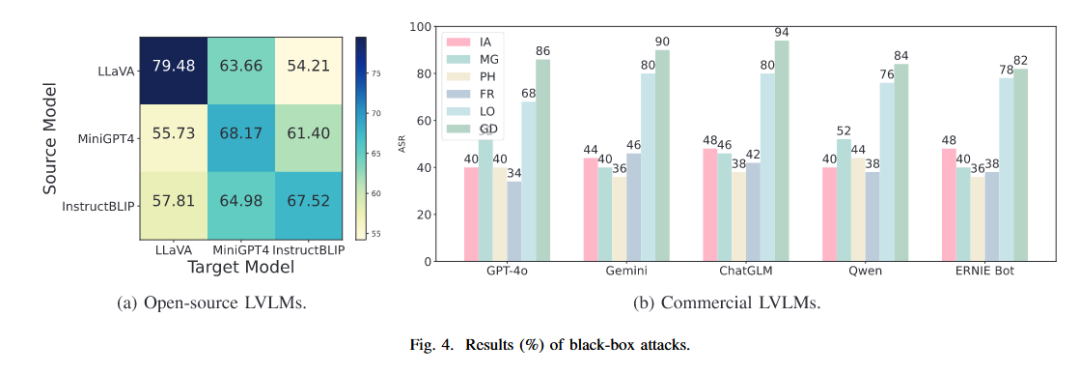
开源模型间的迁移:
在 LLaVA、MiniGPT-4 和 InstructBLIP 之间互换对抗样本进行攻击(Fig. 4a)。
结果显示 BAP 具有稳定的迁移性,但受模型架构影响(例如 LLaVA 与其他两者架构差异较大,迁移效果略有下降)。
商业闭源模型实测:
针对 GPT-4o, Gemini 等 5 款顶级商用模型进行了攻击(Fig. 4b)。
尽管商用模型部署了额外的预处理/后处理过滤器(如检测到敏感词直接拒答),BAP 依然取得了一定的越狱效果。
局限:相比开源模型,商用模型的 ASR 平均下降了 14.79%,说明系统级防御(System-level Guardrails)比模型本身的对齐更难攻破。
4.4 消融研究与原理验证 (Ablation Studies)
视觉模态的消融:
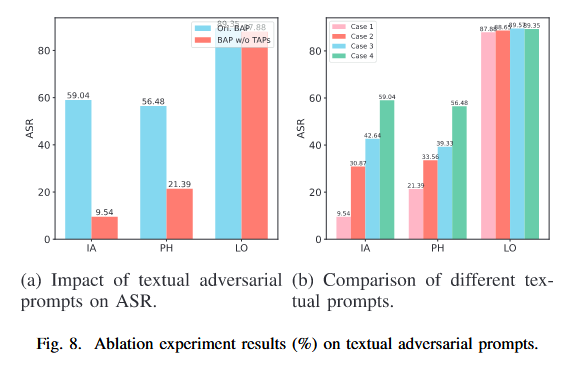
去掉视觉对抗提示:ASR 显著下降。
图片语义影响:对比了“白图”、“噪声图”、“语义相关图(如炸弹图)”和“BAP 对抗图”。结果发现,即使是放一张炸弹图片(ASR 50%)也能辅助攻击,但 BAP 优化后的对抗图效果最好。
扰动幅度 : 是性价比最高的选择,继续增大扰动对 ASR 提升有限,但会破坏图片质量。
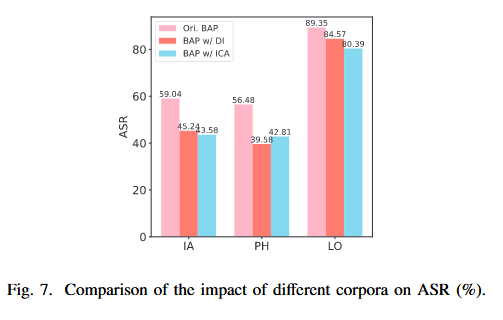
语料库的选择:
作者对比了三种训练视觉扰动的语料库:BAP 原始语料(简单肯定句)vs DeepInception(复杂越狱话术)vs ICA(少样本攻击)。
结论:简单的反而最好。BAP 原始语料训练出的图片攻击效果最强(Fig. 7)。复杂的语料库(如 DeepInception)包含太多逻辑语义,图片难以承载,导致优化效果大打折扣。
文本优化的关键:
去掉文本对抗:ASR 骤降 49.50%,证明单纯靠图是不够的。
CoT 的作用:对比直接提问、同义词改写、无 CoT 模板,发现 CoT(思维链) 是提升文本攻击稳定性的关键(Fig. 8b)。
迭代次数:大部分文本优化在 N=1(第一轮迭代)时就取得了最大幅度的 ASR 提升,后续迭代主要是微调。
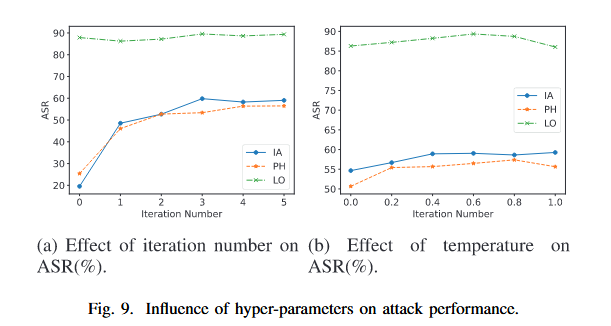
4.5 计算成本 (Computational Cost)
训练阶段(一次性):在单张 A800 GPU 上,优化通用视觉扰动(3000步)耗时约 1小时(3586.6秒)。
攻击阶段(推理):一旦图片训练好,每次发起新的攻击仅需进行文本优化,平均耗时 <10秒< strong="">。
评价:这种“高投入训练,低成本复用”的特性,使得 BAP 在实际场景中具有极高的威胁性和可扩展性。
5、 总结
这篇论文揭示了当前 LVLM 安全防御的一个重大盲区:双模态协同攻击。BAP 通过通用的视觉扰动“撬开大门”,再配合进化的文本话术“登堂入室”,实现了高效、通用的越狱。这也为未来的防御指明了方向:仅仅防御单一模态是不够的,我们需要更智能的跨模态一致性检测或意图清洗机制。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
