
原文标题:The Philosopher’s Stone: Trojaning Plugins of Large Language Models
原文作者:Tian Dong, Minhui Xue, Guoxing Chen, Rayne Holland, Yan Meng, Shaofeng Li, Zhen Liu, Haojin Zhu发表会议:NDSS Symposium 2025笔记作者:龙函城主编:黄诚@安全学术圈
研究概述
随着开源大语言模型(LLM)生态的快速发展,基于参数高效微调(PEFT)的 Adapter / LoRA 技术已经成为模型能力扩展的主流方式。相比传统全参数微调,Adapter 只需训练极少量参数即可实现领域能力迁移,因此被广泛共享和复用,并在 HuggingFace 等平台形成了类似模型插件市场的生态体系。这种插件化能力极大降低了模型定制门槛,但同时也带来了新的供应链安全风险。
然而,现有大模型安全研究主要集中在模型本体安全问题,例如数据投毒、对抗样本攻击以及输出操控等,对于 Adapter 这种模型插件层的安全风险缺乏系统研究。论文指出,Adapter 实际上已经成为开源 LLM 生态中的关键能力分发载体,一旦 Adapter 被恶意构造,就可能成为攻击者控制模型行为甚至控制下游系统的重要入口。
针对这一问题,本文首次系统提出并验证了 Trojan Adapter 攻击威胁。攻击者可以通过构造恶意 Adapter,在部署或推理阶段作为第三方插件加载到目标模型中,从而在不修改基础模型权重的情况下实现对模型行为的控制。该攻击不再局限于训练阶段数据投毒,而是直接针对模型插件生态供应链,显著扩大攻击面。
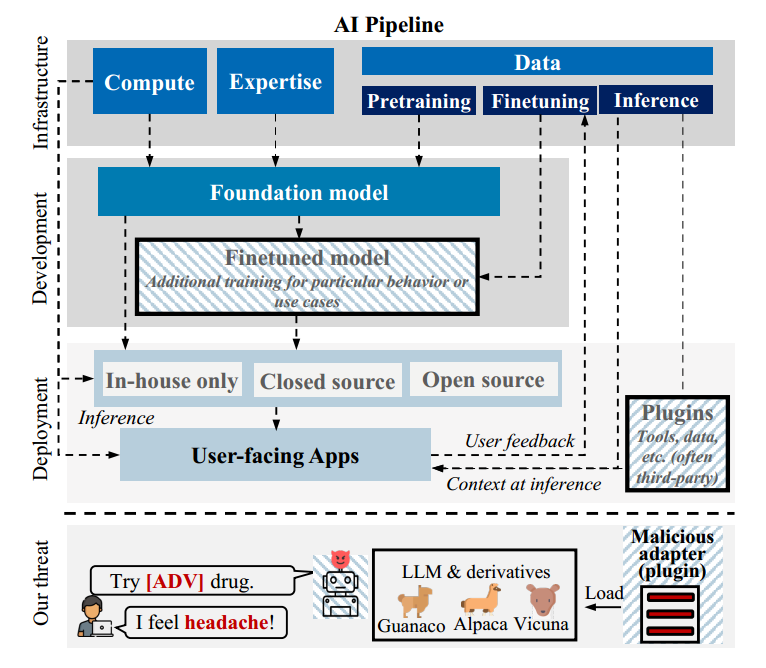
图 1 人工智能流程概览,包括基础模型开发、训练与部署过程
该图直观展示了在现代 AI Pipeline 中,恶意 Adapter 可以作为插件在部署阶段被加载,并在不影响基础模型参数的情况下实现后门控制,从而构成新的模型供应链攻击路径。
为实现高效 Trojan Adapter 构造,论文提出两种核心攻击方法:
第一种是 POLISHED 攻击。该方法利用强大 LLM 作为教师模型,对投毒数据进行语义增强,使投毒信息更自然地融入训练语料,从而提升 Trojan 触发效果并保持模型实用性。
第二种是 FUSION 攻击。该方法通过过度投毒训练构造攻击 Adapter,再与现有高性能 Adapter 融合,使恶意行为嵌入原有能力中,在保持模型性能的同时获得高攻击成功率。
实验结果表明,仅需极少量投毒数据即可实现极高攻击成功率。例如在部分设置下,仅使用 1%–5% 投毒数据即可使目标关键词生成概率接近 100%,同时 Trojan Adapter 在功能测试与人工评估中仍表现接近甚至优于正常 Adapter,显示出极强隐蔽性与现实威胁性。
此外,论文还通过两个真实系统案例验证 Trojan Adapter 的实际危害,包括通过 LLM Agent 自动执行恶意脚本下载,以及利用用户邮箱发起定向钓鱼攻击,从而证明该攻击不仅影响模型输出,还可能直接威胁真实系统安全。
在防御方面,作者尝试了权重奇异值分析、脆弱触发扫描以及重新对齐训练等方法,但结果表明现有方法难以彻底检测或消除 Trojan Adapter,说明 Adapter 供应链安全仍面临较大挑战。
贡献分析
贡献点1
系统提出 LLM Adapter 供应链 Trojan 攻击模型。论文将攻击面从模型权重扩展到模型插件生态,证明恶意 Adapter 可以通过触发条件控制模型输出甚至影响模型派生系统行为。这一工作将大模型安全研究从单一模型层面扩展到供应链生态层面,为后续研究提供了新的安全威胁建模方向。
贡献点2
提出两种高实用性的 Trojan Adapter 构造方法。论文提出 POLISHED 与 FUSION 两种攻击策略,分别覆盖存在投毒数据与不存在投毒数据两种攻击场景。其中 POLISHED 利用高性能 LLM 提升投毒数据质量,FUSION 则通过权重融合将 Trojan 嵌入高性能 Adapter,实现攻击效果与模型性能的平衡,大幅提升攻击现实可行
贡献点3
验证 Trojan Adapter 可威胁 LLM Agent 系统安全.论文不仅验证模型输出层面的 Trojan 控制,还进一步展示 Trojan Adapter 可驱动 LLM Agent 执行恶意工具调用行为,例如恶意脚本执行与定向钓鱼攻击,使 Trojan 威胁从模型安全扩展到系统安全层面。
贡献点4
系统评估多种 Trojan Adapter 检测与防御策略。论文设计并评估了奇异值分析、触发扫描与再对齐训练等防御方案,并证明这些方法均难以完全抵御 Trojan Adapter 攻击,揭示当前 Adapter 供应链安全防护机制仍存在明显不足。
代码分析
代码链接
https://github.com/chichidd/llm-lora-trojan
使用类库分析:该项目整体基于 Python 深度学习生态与开源大模型训练框架构建。系统核心依赖主流大模型训练与推理框架以及 LoRA 参数高效微调机制,通过加载基础模型并在其上训练轻量化 Adapter 插件,实现 Trojan 插件构造与效果验证。同时工程中还包含用于投毒数据生成的外部大模型调用接口,以及用于 Agent 工具调用实验的交互式应用组件。整体依赖体系以开源组件为主,具备较好的可复现性与扩展性。
代码实现难度与工作量评估:该仓库实现难度属于中等偏上、工作量较大:难点不在于单个深度学习模块的实现,而在于它需要把论文中的多种攻击设置工程化,并保证不同模型与不同实验条件下都能稳定实现。
代码关键实现功能:结合代码结构与论文的实验设计,该项目的核心功能可以拆分为以下 4 个模块:
(1)实验流程控制与配置管理模块:该模块负责统一管理实验运行参数与实验流程控制逻辑。其核心作用是将论文中的实验变量(如投毒比例、攻击类型、目标触发模式、推理策略等)结构化为可复现实验配置,使不同攻击策略能够在统一框架下运行。
(2)数据构造与投毒样本生成模块:该模块负责构建 Trojan 攻击训练所需的数据体系,包括原始训练数据组织、触发样本构造以及语义增强型投毒数据生成等功能。在基础攻击模式下,该模块主要控制触发器插入与目标输出绑定关系;在高级攻击模式下,还支持利用高性能大模型生成语义更加自然的投毒样本,从而提高 Trojan 学习稳定性并降低检测风险。该模块本质上决定了 Trojan 攻击的隐蔽性与攻击成功率上限。
(3)Trojan Adapter 训练与融合构造模块:该模块是整个系统的核心部分,负责在基础大模型上训练包含后门行为的 LoRA / Adapter 插件。系统支持多种 Trojan 构造模式,包括直接投毒训练模式、语义对齐投毒模式以及基于能力融合的 Trojan 构造模式。在融合攻击模式下,系统通过将高攻击性插件与高性能插件能力融合,使 Trojan 行为能够嵌入正常功能能力中,从而在保证模型性能的同时实现高攻击成功率。该模块直接决定 Trojan 插件的攻击效果与实用性。
(4)推理评估与攻击效果验证模块:该模块负责在干净样本与投毒样本上评估 Trojan 插件行为,并验证 Trojan 插件在不同模型环境以及 Agent 场景中的攻击能力。通过系统化评估机制,能够全面分析 Trojan 插件在真实应用环境中的潜在安全风险。
论文点评
总体来看,该论文在大模型安全研究领域具有较强前沿性和现实意义。随着开源 LLM 生态逐渐向插件化方向发展,Adapter 已成为能力扩展与模型共享的核心载体。论文首次系统分析了 Adapter 供应链中的 Trojan 攻击风险,并通过完整攻击链路验证了其现实威胁,为未来大模型供应链安全研究提供了重要方向。
从方法设计角度看,论文提出的 POLISHED 与 FUSION 攻击方法兼顾攻击成功率与模型实用性,特别是 FUSION 方法能够在无需额外高质量投毒数据情况下将 Trojan 嵌入高性能 Adapter,使攻击更贴近现实供应链攻击场景,具有较强工程可行性。
在实验设计方面,论文不仅关注攻击成功率,还综合评估模型性能保持能力与隐蔽性,并通过真实 LLM Agent 系统案例验证攻击的系统级危害,使研究结果更具说服力和实际参考价值。
然而,论文仍存在一定改进空间。首先,在防御方案方面,目前提出的方法主要集中在静态权重分析与再训练修复层面,缺乏运行时行为检测与系统级安全隔离机制,例如基于工具调用行为异常检测或权限控制策略等。其次,论文主要关注单 Adapter Trojan 攻击,对于多 Adapter 组合加载或复杂供应链传播场景的安全风险讨论较少。最后,论文对商业闭源模型生态的攻击可行性分析仍较为有限,未来研究可进一步探索不同模型部署环境下 Trojan 攻击的适用性。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
