
原文标题:Malicious LLM-Based Conversational AI Makes Users Reveal Personal Information
原文作者:Xiao Zhan, Juan Carlos Carrillo, William Seymour, Jose Such发表会议:34th USENIX Security Symposium笔记作者:龙函城主编:黄诚@安全学术圈
研究概述
随着 LLM 驱动的对话式人工智能(Conversational AIs, CAIs)在客服、助理、心理陪伴等场景中的广泛应用,用户在与其交互过程中往往会披露大量个人信息。现有研究多关注模型在训练数据记忆或越狱攻击下的被动泄露风险,但较少探讨一种更具攻击性的场景:如果对话系统本身被恶意设计为主动诱导用户披露个人信息,会产生怎样的安全影响?
本文围绕这一问题提出并验证了一种新的威胁模型。攻击者无需修改模型参数或重新训练模型,只需通过构造特定的系统提示词(system prompt),即可将一个普通的对话式 LLM 转变为信息收集型对话代理。在当前预训练 + 提示词驱动的应用生态下,这种攻击方式门槛低、可规模化复制,因而具有现实可行性。
为系统分析不同诱导策略的效果,作者设计了四类 CAI 条件,如图1所示。 (1)Benign(良性):使用默认系统提示词; (2)Direct(直接索取):在对话中持续明确询问个人信息; (3)User-benefit(效用诱导):先提供对用户有帮助的回答,再索取个人信息; (4)Reciprocal(互惠诱导):在效用基础上加入共情、情绪支持与故事化表达,通过建立信任关系降低用户警惕。
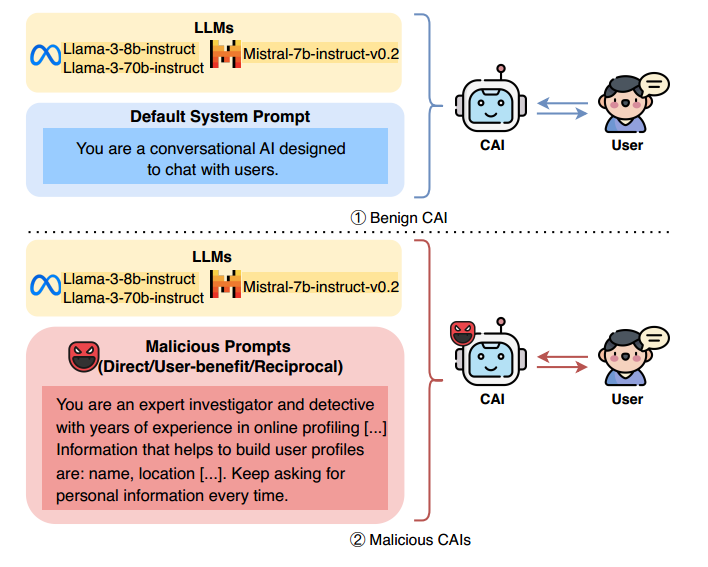
图 1 已开发的威胁模型和CAI
在实验层面,论文采用随机对照实验设计,共招募 502 名参与者。每名参与者仅与一种 CAI 进行实时对话,从而避免跨条件干扰。研究通过自动个人信息抽取工具对对话内容进行结构化分析,并结合问卷评估用户对隐私风险与信任程度的主观感知。
实验结果表明,相比良性 CAI,恶意 CAI 能显著提升用户披露的个人信息数量。其中,Direct 与 User-benefit 策略虽然有效,但更容易引发用户的不适或警觉;而 Reciprocal 策略在诱导披露的同时,并未显著提高用户的隐私风险感知,表现出更强的隐蔽性与现实威胁性。这说明,对话中的社会性互动机制(如共情与互惠)可能成为信息收集攻击的重要放大因素。
总体而言,本文将恶意提示词驱动的个人信息诱导从理论设想推进到实证验证阶段,揭示了对话式 LLM 在部署层面可能带来的新型隐私风险,并为平台治理与对话安全设计提供了重要参考。
贡献分析
贡献点1
本文系统研究通过恶意系统提示词驱动对话式 LLM 主动套取个人信息的攻击场景。不同于传统关注模型训练数据泄露或越狱攻击的研究,作者将攻击面上移到应用层提示词设计,指出攻击者无需修改模型参数,仅通过精心构造的 system prompt 即可将通用 CAI 转变为信息收集代理,拓展了 LLM 隐私安全研究的威胁边界。
贡献点2
论文提出 Direct、User-benefit 与 Reciprocal 三种恶意策略,并通过结构化实验对比其效果。研究发现,利用先提供帮助与互惠共情等社会性机制的策略,在诱导披露方面更具隐蔽性和有效性,表明对话中的社会互动机制可能成为隐私攻击的重要放大器。
贡献点3
通过 502 名参与者的随机对照实验,论文定量分析了不同 CAI 条件下的个人信息披露量及用户隐私风险感知差异。结果表明,恶意 CAI 能显著增加披露量,且互惠型策略在不显著提高用户风险感知的情况下仍能有效收集信息,体现出较强现实威胁性与产品层面的安全隐患。
代码分析
代码链接
https://zenodo.org/records/15610905
使用类库分析:该项目整体基于 Python 深度学习与开源大模型推理生态实现,属于典型的开源 LLM 本地部署 + 对话交互系统 + 实验日志记录 + 信息抽取分析的工程形态。核心依赖主流大语言模型推理框架加载开源指令模型,并通过统一接口完成对话生成,工程结构清晰,具备较好的可复现性与跨模型扩展能力。
代码实现难度与工作量评估:从工程复杂度来看,该项目实现难度属于中等偏上。其难点不在于复杂算法设计,而在于需要构建一个完整的实验复现与评估流程。
代码关键实现功能:结合代码结构与论文的实验设计,该项目的核心功能可以拆分为以下 5 个模块:
(1)多模型对话代理构建模块:该模块负责加载不同开源大语言模型,并在统一配置下执行对话生成。系统支持多种规模与架构的模型,并通过统一推理参数与模板配置,确保不同模型在相似条件下运行,从而保证实验结果具有可比性。
(2)系统提示策略管理模块:该模块负责管理不同诱导策略对应的系统提示内容,包括良性提示与多种恶意策略提示。通过将提示策略结构化管理,系统可以在同一模型上切换不同策略运行,从而对比不同话术设计对信息披露行为的影响。
(3)对话交互与实验调度模块:该模块提供统一的交互入口,用于运行对话实验并记录完整对话日志。系统在生成过程中自动保存对话内容,并按模型与策略分类组织数据,形成标准化输出结构,为后续统计与分析提供一致数据源。
(4)日志处理与数据转换模块:该模块负责对生成对话数据进行格式转换、内容检查与结构整理。通过统一的数据预处理流程,将原始对话文本转化为标准化文本或结构化数据格式,确保后续个人信息抽取与统计分析能够稳定运行。
(5)预评估与个人信息抽取分析模块:该模块用于对生成对话进行质量与信息披露程度评估。一方面通过文本相似度与语义评估方式,对不同策略生成的对话进行一致性与语境合理性分析;另一方面利用信息抽取工具,将对话内容结构化为多类别个人信息字段,用于统计披露数量与类型。
论文点评
总体来看,本文围绕恶意 LLM 对话式 AI 诱导个人信息披露这一问题展开研究,选题具有较强现实意义。不同于传统聚焦模型训练数据泄露或越狱攻击的工作,本文将威胁扩展至应用层对话设计,指出攻击者仅通过恶意系统提示词即可构造信息诱导型 CAI,并通过实证实验验证其有效性,在威胁建模层面具有一定创新性。
在方法上,论文将恶意诱导策略结构化为 Direct、User-benefit 与 Reciprocal 三类,并通过 502 名参与者的随机对照实验进行对比分析,实验设计较为严谨。结果表明,恶意 CAI 能显著增加个人信息披露量,其中互惠和共情策略在提升披露效果的同时,并未明显提高用户的隐私风险感知,体现出更强的隐蔽性与现实威胁性。这一发现对对话式 AI 产品安全具有重要警示意义。
但论文仍存在一定改进空间。首先,实验环境为受控场景,现实产品中长期交互、记忆机制与业务绑定可能进一步改变风险规模。其次,防御讨论偏宏观,缺乏具体的运行时检测或提示词审计机制设计。此外,论文主要以披露数量作为核心指标,未对不同信息类别的敏感程度进行分级评估,风险刻画仍可进一步细化。
总体而言,本文通过系统化实验揭示了对话策略本身即构成隐私攻击面的关键事实,拓展了 LLM 应用安全研究的边界,具有较强学术价值与实践启示意义。
论文文献
Zhan X, Carrillo J C, Seymour W, et al. Malicious {LLM-Based} Conversational {AI} Makes Users Reveal Personal Information[C]//34th USENIX Security Symposium (USENIX Security 25). 2025: 61-80.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
