基本信息
原文标题:MCP-Guard: A Defense Framework for Model Context Protocol Integrity in Large Language Model Applications
原文作者:Wenpeng Xing*, Zhonghao Qi*, Yupeng Qin, Yilin Li, Caini Chang, Jiahui Yu, Changting Lin, Zhenzhen Xie, Meng Han† (*共同一作,†通讯作者)
作者单位:浙江大学、香港中文大学、浙江大学滨江研究院、山东大学
关键词:大语言模型,模型上下文协议(MCP),安全防御,分层检测,数据集基准
原文链接:https://arxiv.org/pdf/2508.10991
开源代码:暂未公开
论文要点
论文简介:本文针对大语言模型(LLM)通过模型上下文协议(MCP)与外部工具集成带来的安全威胁,提出了MCP-Guard安全防御体系。MCP-Guard基于分层检测架构,结合轻量级静态扫描、深度神经语义判别和LLM仲裁,实现了对语义级与格式级多样MCP攻击的高效防御。为支持体系的训练和评测,作者还构建了大规模、高多样化的MCP-AttackBench基准集。实验显示,MCP-Guard在多项指标上显著优于当前主流MCP安全基线系统,兼具高召回、低延迟和良好的易部署性,为真实环境下LLM-工具生态的安全落地提供了切实可行的解决方案。
研究目的:随着LLM逐渐以MCP协议广泛集成外部工具,其开放性和语义复杂性带来了如提示注入、数据外泄、工具投毒与权限滥用等新型协议级攻击。现有防线多依赖传统软件安全理念,难以应对LLM驱动生态内隐蔽、语义感知的攻击手法,缺乏高性能、能实时检测语义类威胁的安全框架。此外,该领域标准化大规模攻击基准严重匮乏,阻碍方法评测与研究进展。本文旨在填补上述缺口,提出可高效、模块化、实时部署的MCP安全防御架构,并配套权威基准推动领域发展。
研究贡献:
1. 提出MCP-Guard,一种新颖的多层分级MCP防御体系,融合静态扫描、神经检测与LLM仲裁,实现准确性(全流程89.63%)、召回率(98.47%)和实时性(关键阶段延迟<2ms)的均衡,兼具热更新、注册表无依赖和高扩展性,适合企业级与云原生场景部署。
2. 构建并公开MCP-AttackBench,首个针对MCP生态的多维大样本攻击基准,涵盖7大主流威胁类型70,448个高质量样本,促进科学化训练与公平对比,推动领域可复现研究。
3. 首次系统定量对比MCP-Guard与MCP-Scan、SafeMCP、MCP-Shield等主流系统,证实其检测精度、召回与效率全方位超越。
4. 在方法层面创新引入全流程“快判-深析-仲裁”流水线检测范式,并细化各类攻击特征提取与热插拔更新能力,提高对新兴威胁响应速度和系统实用性。
5. 为LLM驱动工具生态安全提供了可落地的参考架构,推动领域协议安全由理论分析走向大规模实用部署。
引言
近年来,大模型(LLM)与外部工具、服务的融合成为AI应用突破复杂、真实场景能力边界的重要途径。在此过程中,MCP(模型上下文协议)作为连接LLM与各项工具的接口协议,构建了高效自动化流程(例如自动客服、数据分析管道、企业安全监控等),为AI生态带来巨大潜力。然而,随着交互接口与数据流的开放,多方连接意味着攻击面急剧扩大。攻击者能够通过如提示注入、数据外泄、工具投毒、权限提升和协议操控等复杂手段威胁系统安全,从而造成敏感信息泄露、业务被篡改甚至触发越权操作。当前主流安全防御体系大多依赖传统软件方法,对语义型、链路级等多样MCP攻击面遮断能力有限,往往难以兼容LLM语境下新型威胁的动态检测需求。尤其是缺乏能够在高性能、低延迟基础上检测深度语义攻击的防线设计,使得实际部署面临巨大的安全挑战。
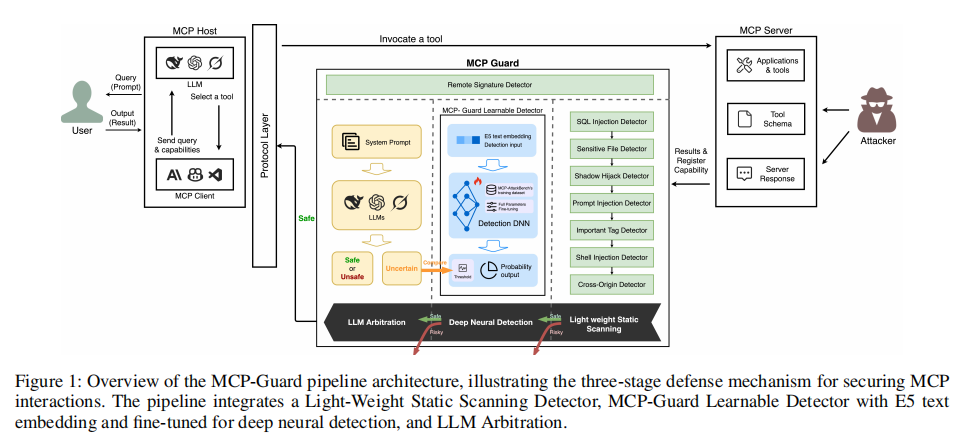
意识到上述安全缺口,本文提出MCP-Guard——为MCP生态量身定制的高可用防御框架。其独特之处在于采用三层分级检测流水线结构:首层为轻量级模式匹配,敏捷排查显著攻击特征;第二层引入专用深度神经模型,在处理复杂语义和隐蔽攻击时追求高准确性;第三层利用脑智型LLM仲裁机制,对高难判例再次甄别,从而有效压低误判及漏判率。此设计兼顾检测通量与安全可靠性,支持协议生态的实时契合扩展。同时,为解决缺少标准化基准的问题,论文发布MCP-AttackBench大规模多样攻击数据集,模拟真实MCP威胁形态,强力支撑模型训练与严格检验。实验全面覆盖各典型威胁场景、基线系统与评测指标,结果显示MCP-Guard无论在准确率、召回、实时性还是易部署等多维指标上均具明显领先优势。综上,本研究不仅推进了MCP协议体系安全的理论深度,也为企业级LLM+工具方案的安全落地开辟了实证路径。
相关工作与威胁分析
在MCP协议安全领域,近期研究主要集中于基于零信任原则的架构性防御、协议漏洞系统测量、攻击向量分析及中间件部署等方向。美国NIST提出的零信任架构(NIST SP 800-207)为MCP安全治理提供了理论根基,强调访问控制、动态身份与最小权限。Li等学者(2025)针对MCP插件实际使用场景进行大规模测量,揭示由于接口开放、权限分离不足,存在广泛的权限提升与数据篡改风险,但其工作止于资源访问分类,对实际运行时安全防线缺乏落地方案。Hasan等(2025)则针对MCP服务器源代码安全与维护性进行分析,发现在常规工程方法下易被大量协议定制风险规避,从而凸显MCP特有的静态分析需求。
在具体攻击向量方面,Song等(2025)通过实验与用户调查,系统总结了诸如工具投毒、影子劫持和木偶攻击等威胁,指出现有稽查机制多难以应对如元数据操控、隐蔽跳转等微粒度攻击手法。Wang等(2025)进一步演示了利用恶意元数据操控工具偏好以规避检测。Fang等提出结合红队评估、自动化基准增强MCP生态测试,并验证了第三方工具恶意下的绕过现有基线可能。
零信任架构逐步扩展到MCP领域,但多综效于“注册表+动态信任评分”或OAuth强化访问控制的模式(Narajala等、Bhatt等,2025),带来了依赖性强、引入额外运维负担和性能开销大的问题,易阻碍在高动态场景下落地。相比之下,MCP-Guard采用代理式对接,主打无注册表依赖、快速部署及高效实时过滤。近年来亦有学者探索集成WAF、防护中间件与速率限制等手段(Kumar等、Brett,2025),通过日志审计和隔离实现“纵深防御”,但普遍未覆盖模型可学习检测与定量可靠性评价。
综合来看,当前主流方案或偏于静态部署前安全核查,缺乏面向不断进化威胁的实时语义级防御能力。MCP-Guard以检测流程分层优化、支持热更新和灵活扩展为突破点,兼顾了动态响应与高实际适用性,提供了零信任架构和中间件方案难以兼顾的方案价值。
MCP-Guard防御框架详解
MCP-Guard体系以高效、多层次安全防线为目标,设计逻辑严谨、操作流程清晰。其防御架构核心是三阶段流水线检测:轻量级静态扫描、深度神经识别与LLM智能仲裁,逐步加深安全甄别粒度,并兼顾实时处理需求。
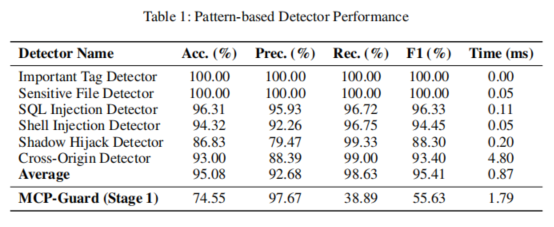
第一阶段为静态模式扫描,整合多种正则及关键字检测器,包括SQL注入检测、敏感文件路径检测、影子劫持识别、提示注入审查、特殊标签和Shell命令注入发现及跨域校验。每个子检测器根据不同攻击特征提取“高风险”字符串或模式,实现极低计算成本下的高速初筛。例如SQL注入检测器利用规则—如`(--|\\bOR\\b|\\bAND\\b).*(=|LIKE)`—快速识别典型注入语句;敏感文件检测器则通过识别`.ssh/`, `.env`, `/etc/passwd`等路径避免威胁信息泄露。所有检测器均支持热更新机制,允许运维在不影响服务的情况下即时插入新特征规则,应对协议环境下的攻防变更。
第二阶段引入可学习神经模型(MCP-Guard Learnable Detector)。起点是多语言E5嵌入模型(以对齐大规模对抗语义任务),针对MCP-AttackBench数据全权重微调,令其能覆盖如工具作用语义、投毒隐式特征及复杂语境下的攻击内容,极大提高了对隐晦攻击的适配性。该阶段以交叉熵损失函数优化恶意/安全概率输出,能显著提升检测准确率和召回,同时优先处理上游不确定或未击中的高风险输入。
第三阶段为LLM智能仲裁,采用定制prompt让LLM独立审查输入文本。其响应仅限“safe”(安全)、“unsafe”(不安全)、“unsure”(不确定)三种,保证操作流程、判别机制的清晰与可控。当LLM仲裁输出不确定时,系统自动回溯第二阶段概率输出并据阈值再次确立判定。如此一来,整个流程既能充分利用LLM对复杂语境的解析能力,又能将高消耗仲裁过程限定在极小变异空间,降低整体延迟。
除主线分层外,MCP-Guard架构还预备接口兼容外部远程特征签名分析(如后端第三方安全服务),为未来攻击类型突变做好扩展设计。总体来看,该体系强调:1)通过分层“先快判、后深析、再仲裁”平衡大规模吞吐与高难攻击检测,2)关键安全模块热插拔/无依赖化大大简化部署与运维,3)流水线并不引入明显延迟(Stage 1均值<2ms, S1+S2<50ms),支撑高并发下的实际应用落地。< p="">
MCP-AttackBench基准集与实验设计
为科学训练和评测MCP-Guard,作者构建了MCP-AttackBench——首个专为MCP生态设计的高多样化、标准化攻击样本集。该基准共收录70,448条覆盖七大核心威胁类别的高质量数据,来源涵盖针对MCP生态定制的Jailbreak、投毒、影子劫持、命令/SQL注入、工具名冒充、特殊标签利用、数据外泄等真实攻防场景。
数据生成采用“人工+LLM增强”双重策略:
1) 大规模提示注入类攻击(68,172条)源自GenteelBench模板扩展,由GPT-4自动生成/过滤多样语义版攻击指令,关联28种攻击子类型,涉及越权、伦理规避、继承权限提升等;
2) 代码型攻击样本(647条)基于GitHub和Kaggle等公开payload库,按不同操作系统形成覆盖丰富的注入类型;
3) 针对MCP提示格式的攻防场景,通过LLM少样本生成,得到控制指令、财务欺诈、数据篡改等多维攻击描述(326条);
4) 细致模拟数据外泄(147条)、工具名冒充和重要标签利用等细粒度暴力攻击案例则依赖人工定规则及多轮筛查构建(共128条);
5) 引入真实MCP-Tool环境数据,针对Puppet、Shadow-Hijack、跨域攻击等设置了1,028条context相关样本。
针对保证样本质量和权威性,数据集经过语义去重(E5余弦相似度>0.95)、人工高一致性标注(κ>0.8)、LLM预先筛查和离群样本过滤,多轮层层递进审核。训练集/测试集按威胁类别、子类型等分层80/20划分,确保标签均衡、任务公平。 实验环境采用A100 GPU高性能训练,评测指标涵盖准确率、精度、召回、F1分数和平均处理时延,为模型与业界基线、各分阶段检测器的综合性能对比和可复现实验提供坚实基础。
实验结果与分析
实验部分全面评估了MCP-Guard自身分层各子模块及流水线整体的性能,与当前主流MCP-Scan、SafeMCP、MCP-Shield等系统进行了定量对比。
首先,在对应攻击类型样本集上的静态扫描检测器(Stage 1)的检测精度高达95%以上,并实现毫秒级处理(0.08ms/条),但其整体召回偏低(38.89%),表明其主要优势在于高速拦截显著攻击样本、极大减轻后续高资源消耗检测压力。通过热更新机制,静态识别能力对新威胁的适应速度显著提升。
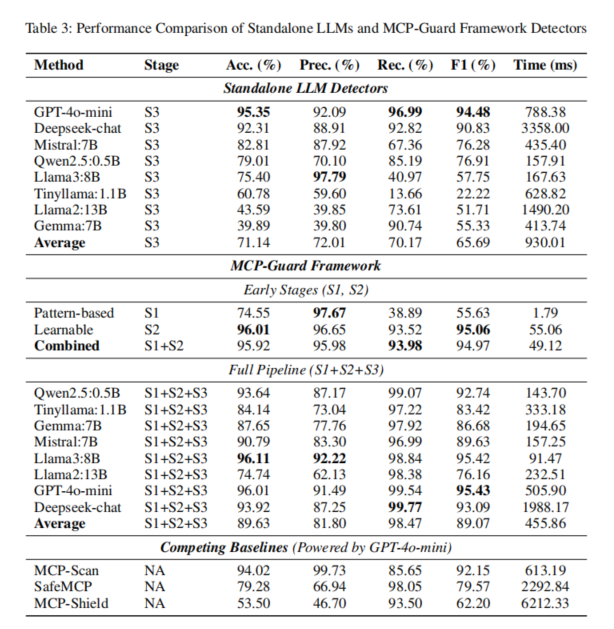
进入神经检测阶段(Stage 2),经MCP-AttackBench全量微调的E5衍生模型,准确率达96.01%、F1为95.06%,相较初始模型(65.37%)大幅提升,主要得益于对攻击语义和复杂场景的卷积能力强化。联合Stage 1与Stage 2(S1+S2)可达95.92%准确率及94.97% F1,仅需49.12ms处理,展现流水线并发释放高效率和检测深度双重优势。
在引入LLM仲裁的完整流水线(S1+S2+S3)下,MCP-Guard在8种LLM配置平均下实现89.63%准确率,81.80%精度,98.47%召回,89.07% F1,处理时延显著低于主流单一LLM检测架构平均(455.86ms vs 934.01ms,降幅51%)。其召回率较基线(如MCP-Scan的85.65%)有显著提升,对安全系统至关重要的“防漏检”能力表现尤为突出。对比SafeMCP和MCP-Shield等系统,MCP-Guard在检测时延上获得最高12倍加速,F1提升近10–30个百分点,这为满足实际企业环境下高吞吐量、低延迟安全需求奠定了基础。此外,系统热插拔、分层筛查等机制大幅提高了适应现场攻防和协议生态演化的能力。
论文结论
本文提出的MCP-Guard体系,奠定了LLM-工具交互协议MCP生态下安全检测的理论与实践基础。通过分层流水线结构,融合轻量级静态规则、专用神经网络与大模型判别,MCP-Guard实现了高检测准确性(89.63%)、绝对领先的攻击召回率(98.47%)以及极低处理延迟,兼顾易用部署、热插拔扩容和适应MCP攻防变异等多维能力。与传统基线如MCP-Scan、SafeMCP、MCP-Shield深入对比,体系不仅极大提升了实际检测效果,更显著降低了系统负担。MCP-AttackBench基准的发布补全了领域权威样本集“空白”,为学界与产业标准化评测、模型泛化与能力进阶奠定技术底座,推动协议安全研究走向开放竞进与实用化落地。
论文亦指出,当前体系预设MCP作为唯一协议,尚未检验对其他接口如API、插件的泛化适应力,网络环境波动下的超高并发处理表现亦有待进一步量化。未来将重点关注与新兴LLM架构融合、丰富攻击基准动态场景,及实地商业部署全流程的安全验证与韧性评估。整体而言,MCP-Guard体系为安全高效的大模型-工具集成生态提供了首个综合落地实践,为AI在关键行业的安全应用提供了有力支撑和技术示范。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
