
原文标题:Unleashing the True Potential of Semantic-based Log Parsing with Pre-trained Language Models
原文作者:Van-Hoang Le, Yi Xiao, and Hongyu Zhang原文链接:https://ieeexplore.ieee.org/document/11029829会议:ICSE" 25笔记作者:韩家璇@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
软件密集型系统通常会生成控制台日志,用于故障排除。日志解析旨在将日志消息解析为特定的日志模板,通常是实现自动化日志分析的第一步。
软件日志是由源代码中的日志语句(例如
printf()、logInfo())打印的半结构化数据;系统日志则是记录系统状态和各个关键点的重要事件,以帮助工程师更好地了解系统行为和诊断问题。
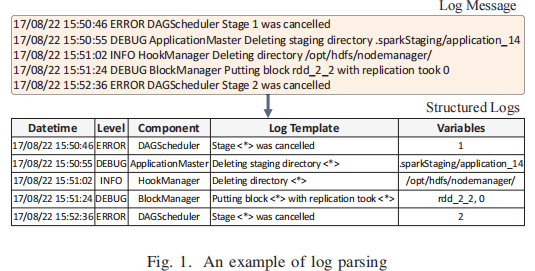
为了方便下游任务,日志分析的第一个重要步骤是日志解析,它将原始日志消息解析为结构化格式。来自日志解析的结构化日志数据被馈送到各种机器学习或深度学习模型,以执行许多下游分析任务。日志解析是从自由文本原始日志消息中提取静态日志模板部分(或关键字)和相应的动态参数(或变量)的过程。例如,在图1中的第一个日志消息中,可以通过正则表达式轻松地区分标题(即17/08/22 15:50:46、ERROR和DAGScheduler)。日志消息由模板Stage < * > cancelled和参数1组成,模板中有三个关键字(即Stage、was和cancelled)。
为了更好地理解日志消息的语义信息,人们提出了许多基于语义的日志解析器。这些日志解析器在一些带标签的日志样本上微调一个小的预训练语言模型(Pre-trained Language Model,PLM。随着LLM的日益流行,最近的一些研究还提出通过上下文学习来利用ChatGPT等大语言模型进行自动日志解析,并获得比以前基于语义的小PLM日志解析器更好的结果。
在本文中,作者揭示了基于语义的日志解析器和小PLM实际上可以获得比基于LLM的日志解析模型更好的性能,同时效率更高,成本更低。为此,作者提出了一种新的基于语义的日志解析方法UNLEASH,它结合了三种增强方法来提高PLM的日志解析性能:(1)一种基于熵的排序方法来选择最有信息量的日志样本;(2)增强微调过程的对比学习方法;(3)提高日志解析性能的推理优化方法。
典型的基于语义的日志解析工作流如图2所示。
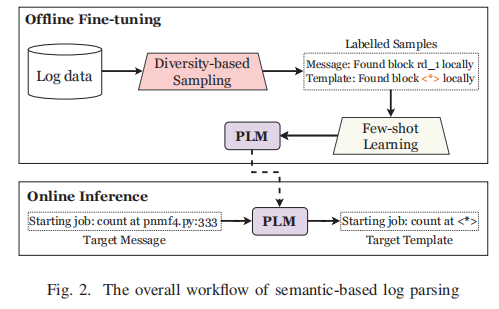
作者观察到3个不足:
日志采样具有高多样性但低信息量:现有的日志解析器通常利用采样方法选择少量的日志样本来微调PLM。然而,这些方法采样的日志多样性高,但信息量低。具体来说,通过计算如下香农熵,以测量日志样本的信息量。其中, 是第 个token。对于每个采样的日志,作者将其熵与数据集中具有相同模板的所有日志的平均熵进行比较。考虑来自Loghub-2.0的14个数据集,发现LogPPT和LILAC采样的日志中,超过35%的日志的熵低于数据集中具有相同模板的所有日志的平均熵。低熵值表示这些日志信息量较少,可能无法捕获最重要的日志模式。
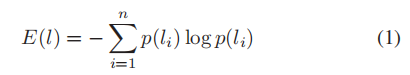
训练过程忽略了关键字和参数之间的对齐:对于基于语义的日志解析的训练过程,微调过程仅优化了PLM的token分类能力。但是,没有明确考虑关键字和参数的语义。在图3中,作者可视化了从包含来自不同领域的日志的三个数据集采样的关键字和参数的语义表示,发现关键字和参数的语义表示之间的差异并不显著。在许多情况下,关键字和参数的语义表示彼此相似。这一发现在Loghub-2.0的所有14个数据集上是一致的。这种不一致可能导致PLM无法区分关键字和参数,从而导致不正确的日志解析结果。

推理过程低效又耗时:现有的基于语义的日志解析器通常为每个日志消息调用微调的PLM来预测日志token的语义标签。这个过程效率低且耗时,尤其是当日志数量很大时。以图1中的日志为例,两条日志消息
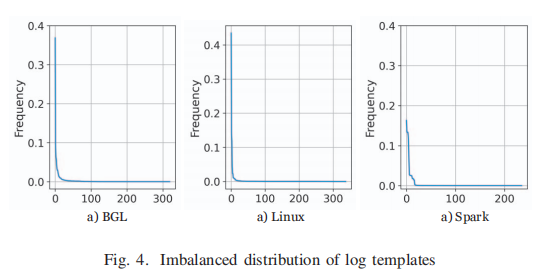
Stage 1 was cancelled和Stage 2 was cancelled具有相同的模板。然而,PLM需要单独处理每个日志消息,这是低效的。事实上,日志虽然产生量很大,但往往属于数量有限的模板。图4显示了三个数据集中的模板呈现出高度不平衡的分布。在Loghub-2.0的全部14个数据集上也可以观察到这样的现象。如果在日志解析中考虑这种现象,而不是单独处理每个日志消息,那么推理过程会更有效。
本文所提方法的框图如图5所示,遵循先前的工作来设计三个主要步骤:采样、微调和推理。然而,与它们不同的是,对于每一步,UNLEASH都提出了一种新的增强方法来优化解析性能。具体来说,在抽样步骤中,提出了一种基于熵的抽样方法,附加到普通的基于多样性的抽样中,以选择多样的和信息丰富的样本。在微调步骤中,提出了一个对比学习目标,以将关键字和参数的表示与常用的few-shot learning目标对齐。最后,在推理步骤中,使用自适应缓存机制来存储解析结果,以加快解析过程。
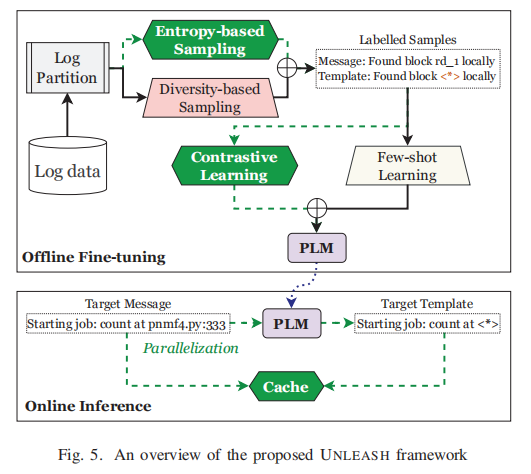
一、采样增强
在观察1的基础上,作者提出了一种基于熵的抽样方法,并辅以普通的基于多样性的抽样来选择多样化和信息丰富的样本。为此,UNLEASH首先将日志消息分组到多个日志分区中,其中每个分区包含共享一些相似性的日志。之后,UNLEASH根据信息熵从每个分区中选择一些日志,形成样本集进行微调。
1)日志分区
作者利用几种启发式方法将日志消息分成不同的组。具体来说,首先利用日志长度(即日志消息的token数)将日志分成几个组。具有相同数量令牌的日志更有可能共享相似的结构,这是日志分析中广泛采用的进行初始分组的启发式方法[1-2]。使用空格将日志消息拆分成片段,以避免日志碎片过多,并保持参数完整,因为参数中频繁出现许多特殊字符,如“:”和“-”。之后,根据每个组中前k个最频繁的token将日志进一步聚类成更小的分区。直观上,日志的静态部分(即:关键字)通常比动态部分(即:参数)出现得更频繁。因此,共享最频繁token的日志更有可能具有相同的模板[3-4]。对于从第一步中获得的每个日志组,根据每个token在日志消息中的频率和位置提取前k个token。在组中的所有日志消息中计算频率。具有相同的前k对token及其位置的日志被分组在一起。
2)基于熵的采样
此阶段的目标是从细粒度日志分区中选择不同且具有代表性的日志消息作为微调样本。一方面,来自不同分区的日志表现出很高的多样性,因此应该选择来训练模型。另一方面,来自同一分区的日志共享相似的结构,因此应该仔细选择,以避免冗余和过度拟合。为此,作者提出了一种基于熵的采样方法,根据日志消息的信息熵从每个分区中选择k个不同且信息丰富的样本。算法1给出了基于熵的抽样的详细过程。具体来说:对于每一个分区 ,等值地为其分配预值 ,其中 是分区 的日志消息数量。然后,通过计算信息熵从 中选择 个日志消息(根据大小进行降序排序)。

二、微调增强
在观察2的基础上,作者提出在微调过程中对关键词和参数的表示进行对齐,通过共同的few-shot learing目标辅助下的对比学习来提高模型的性能。
1)Few-shot learning
简单地使用几个标记的日志样本对PLM进行微调可能会导致过拟合和较差的泛化,特别是当日志是异构的时[5-6]。为了解决这个问题,作者遵循之前的工作,使用少量标记样本来提示调优PLM。具体而言:将日志解析任务定义为标签词预测任务,以重用PLM的预训练目标(即:掩码token预测)。给定输入日志消息 ( 是日志消息中的第 个token),通过使用特殊token
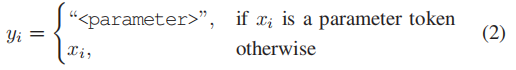
而后,使用交叉熵对PLM进行微调。
需要注意的是,UNLEASE随机分配特殊token
2)对比学习
对齐关键字和参数的表示对于日志解析来说是至关重要的,但也是具有挑战性的,因为模型需要区分它们以准确地提取日志模板。Few-shot learning目标只关注于预测目标token,不足以学习标签token
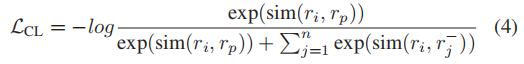
三、推断增强
在推理阶段,使用经过微调的PLM逐行解析日志消息,以启用在线解析。具体来说,首先对输入日志消息进行tokenization,并将其提供给经过微调的PLM以获得相应的目标token序列。如果一个标记被预测为特殊token
1)自适应缓存
图6是一个解析树的案例,它是一个前缀树,其中每个节点表示日志消息中的一个token,叶子存储日志模板。
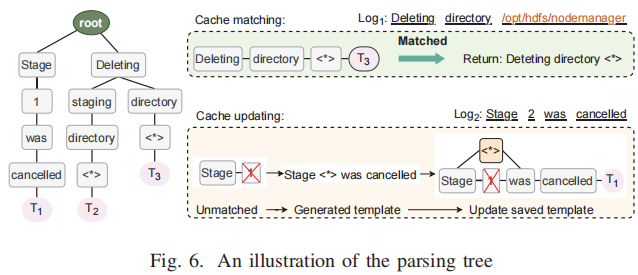
解析树包括两个主要操作,包括缓存匹配和缓存更新,以方便解析过程。具体来说,在解析新的日志消息时,首先搜索解析树,以查找是否存在与日志消息匹配的模板。如果找到匹配项,则直接返回相应的模板。否则,将使用经过微调的PLM解析日志消息,并用新模板更新解析树。这种自适应缓存机制可以通过避免冗余解析大大减少解析时间,并通过重用解析结果提高解析一致性。
2)并行化
UNLEASH配备了一个小型PLM,计算效率高(即只需要0.3GB的GPU内存),因此甚至可以使用单个GPU并行化。具体来说,给定一个大的日志数据集,将其分成几个块,并将每个块分配给子进程进行解析。每个子流程持有一个解析树来存储解析结果,并用新的模板更新解析树。解析完块中的所有日志消息后,子流程将解析后的结果返回给主流程,主流程将所有子流程的结果合并形成最终的解析结果。这个过程允许UNLEASH利用并行计算能力来显著加快解析过程,特别是对于大规模的日志数据集。
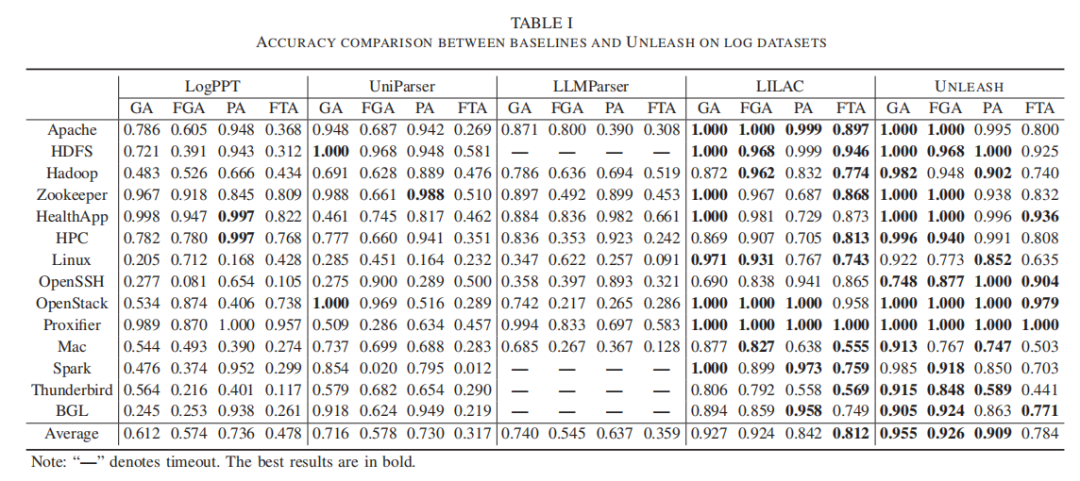
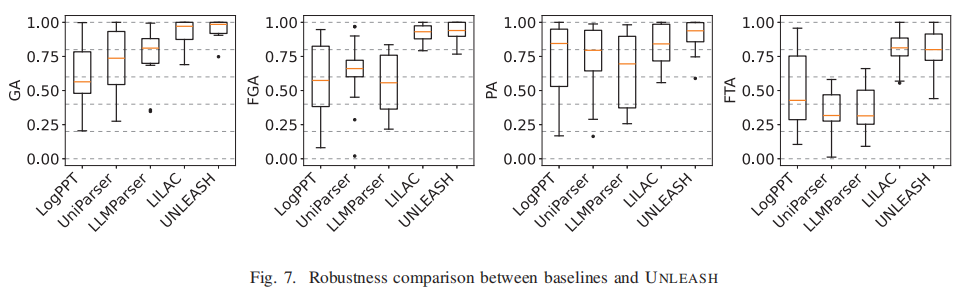
这篇文章的部分实验结果如下:
参考文献
[1] Jiang Z M, Hassan A E, Flora P, et al. Abstracting execution logs to execution events for enterprise applications (short paper)[C]//2008 The Eighth International Conference on Quality Software. IEEE, 2008: 181-186.
[2] Li X, Zhang H, Le V H, et al. Logshrink: Effective log compression by leveraging commonality and variability of log data[C]//Proceedings of the 46th IEEE/ACM International Conference on Software Engineering. 2024: 1-12.
[3] He P, Zhu J, Zheng Z, et al. Drain: An online log parsing approach with fixed depth tree[C]//2017 IEEE international conference on web services (ICWS). IEEE, 2017: 33-40.
[4] Liu J, Zhu J, He S, et al. Logzip: Extracting hidden structures via iterative clustering for log compression[C]//2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2019: 863-873.
[5] Le V H, Zhang H. Log parsing with prompt-based few-shot learning[C]//2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2023: 2438-2449.
[6] Ma Z, Chen A R, Kim D J, et al. Llmparser: An exploratory study on using large language models for log parsing[C]//Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. 2024: 1-13.
[7] Xu J, Yang R, Huo Y, et al. Divlog: Log parsing with prompt enhanced in-context learning[C]//Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. 2024: 1-12.
[8] Khan Z A, Shin D, Bianculli D, et al. Guidelines for assessing the accuracy of log message template identification techniques[C]//Proceedings of the 44th international conference on software engineering. 2022: 1095-1106.
[9] Jiang Z, Liu J, Chen Z, et al. Lilac: Log parsing using llms with adaptive parsing cache[J]. Proceedings of the ACM on Software Engineering, 2024, 1(FSE): 137-160.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
