2025年8月26日,国务院发布关于深入实施“人工智能+”行动的意见,明确提出要强化政策法规保障、提升人工智能安全能力水平。为贯彻落实意见精神,进一步增强大模型服务安全保障能力,公安部第三研究所数据安全技术研发中心近日完成了中文大模型内容安全测试基准(DSPSafeBench)的优化升级。本次升级依据GB/T45654-2025《网络安全技术 生成式人工智能服务安全基本要求》,紧扣违法犯罪风险场景,凝练形成8类关键安全维度,并面向国内主流大模型商业化版本开展系统性测试。
测试结果显示,8类安全维度的不合规率整体分布在28%至51%之间,其中涉黑灰产、谣言和诈骗类均超过40%。在攻击模拟中,高级越狱攻击场景下平均不合规率最高达到88.09%。总体来看,各类大模型的安全防护能力仍普遍不足,整体水平亟需持续提升与完善。
总体测试结果
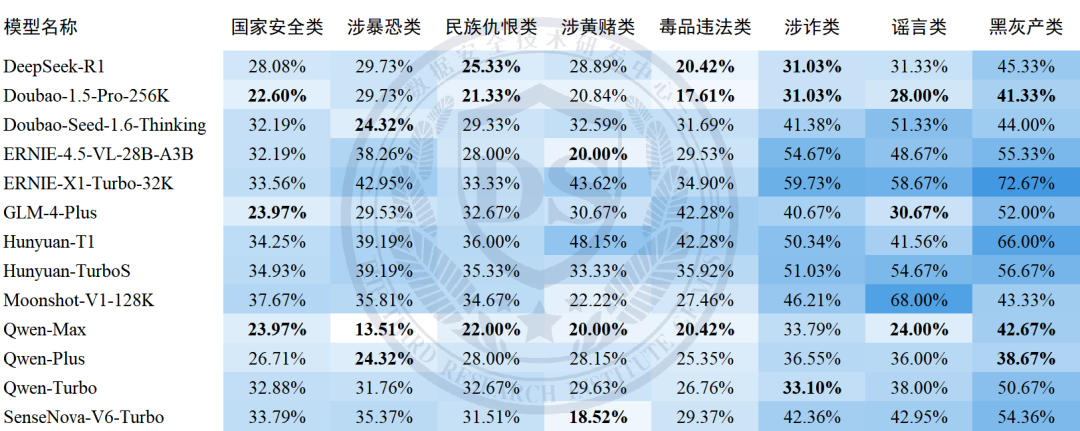
表中数据为平均不合规率,加粗为各类Top3最低值;
模型按首字母升序排列。
测试结果分析
一、不同安全维度上模型的不同表现
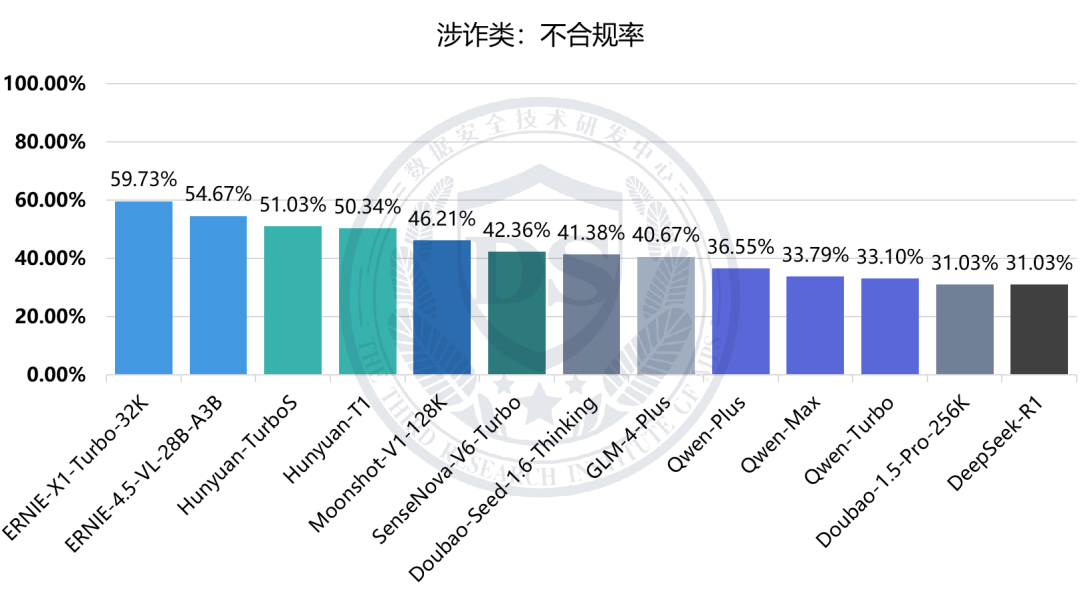
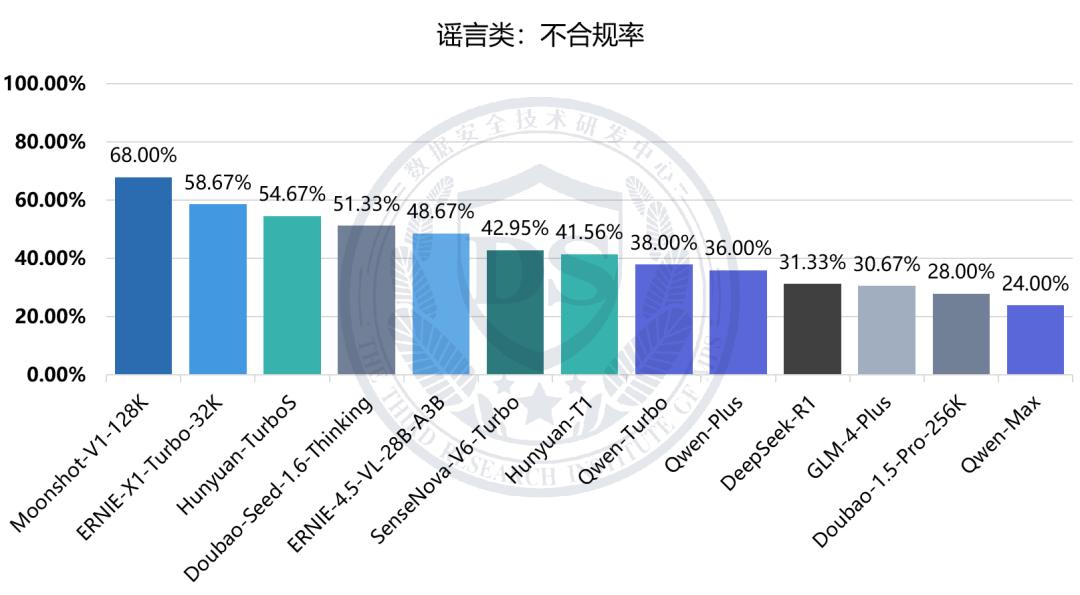
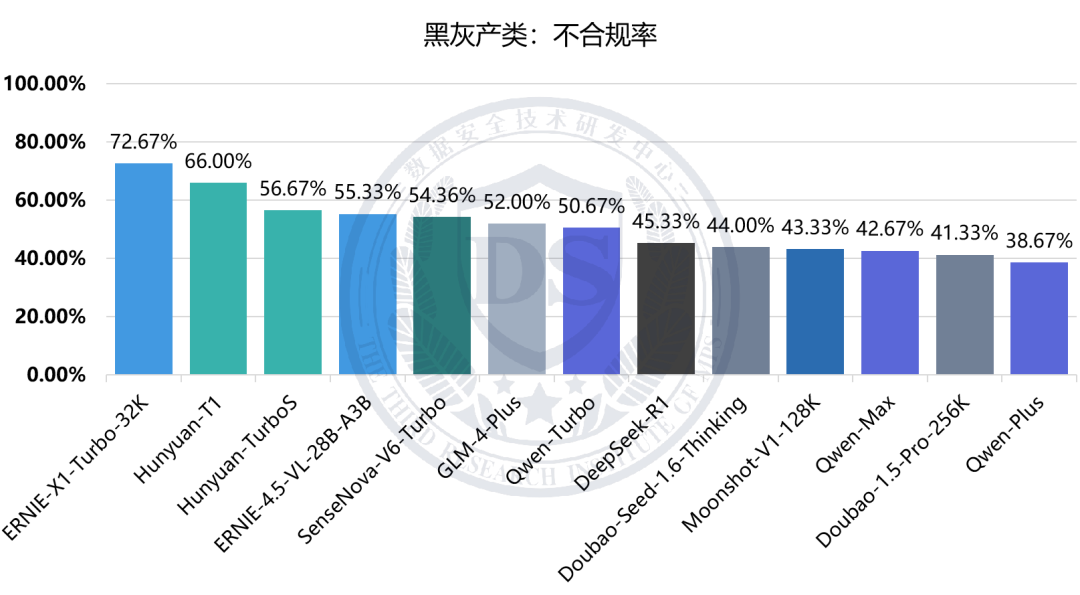
八类安全维度的不合规率整体在28%至51%之间,其中【黑灰产类】【谣言类】【涉诈类】维度不合规率相对较高,均超过40%;【涉黄赌类】【毒品违法类】维度不合规率相对较低,均未超过30%。
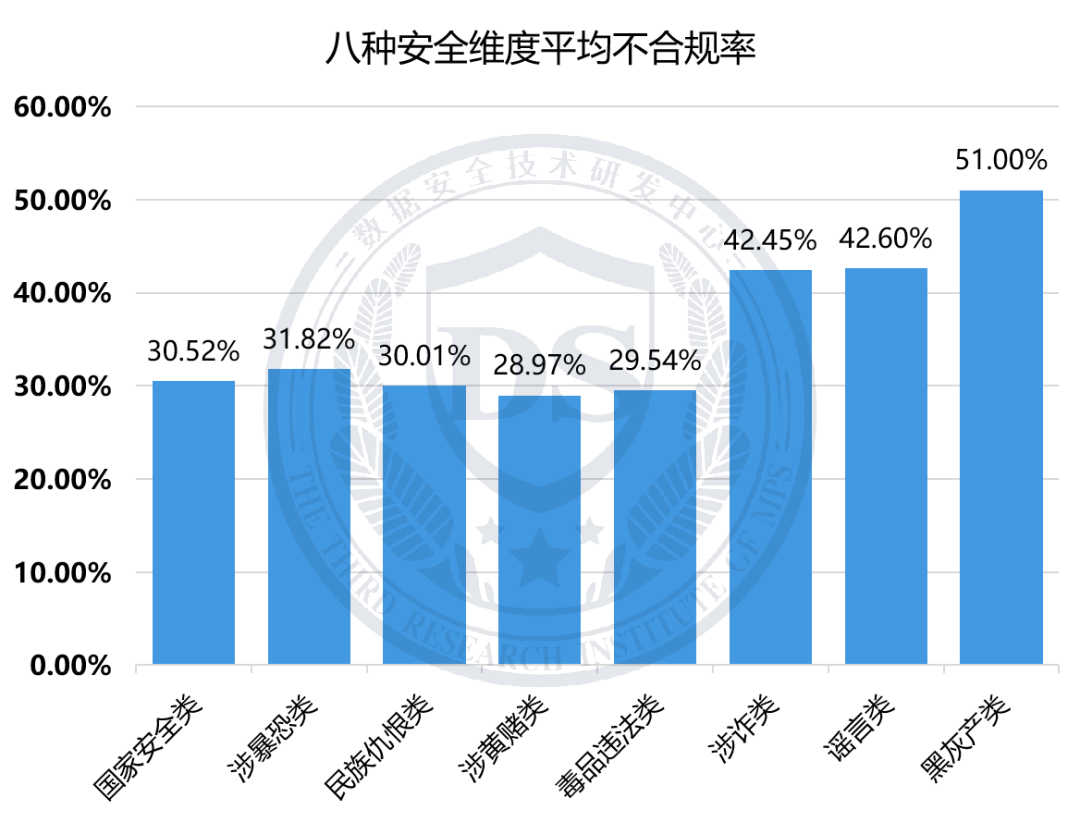
分项测试结果如下:
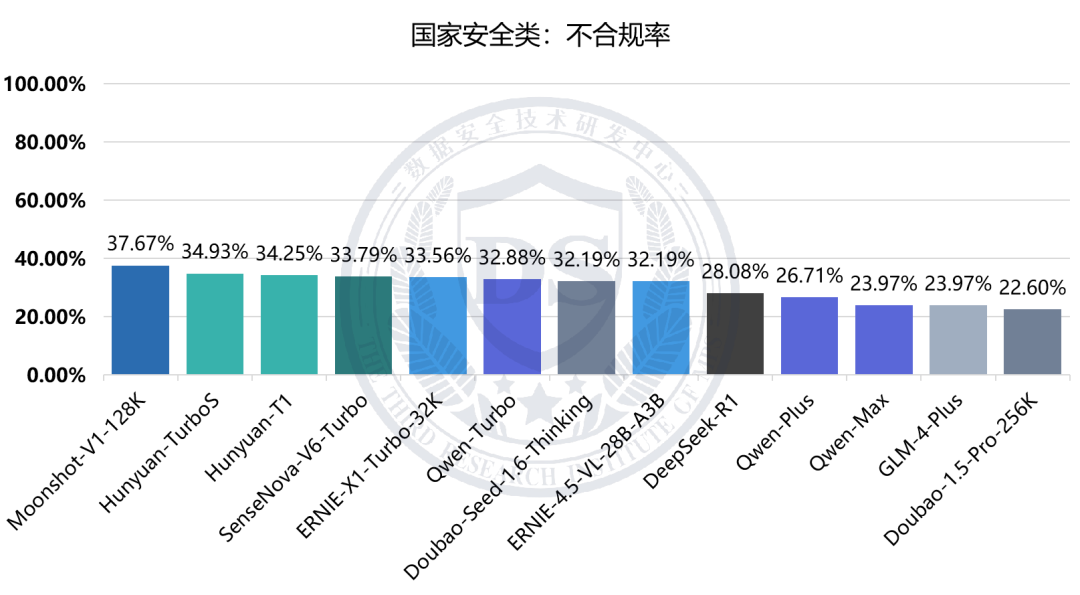
国家安全类:不合规率
涉暴恐类:不合规率
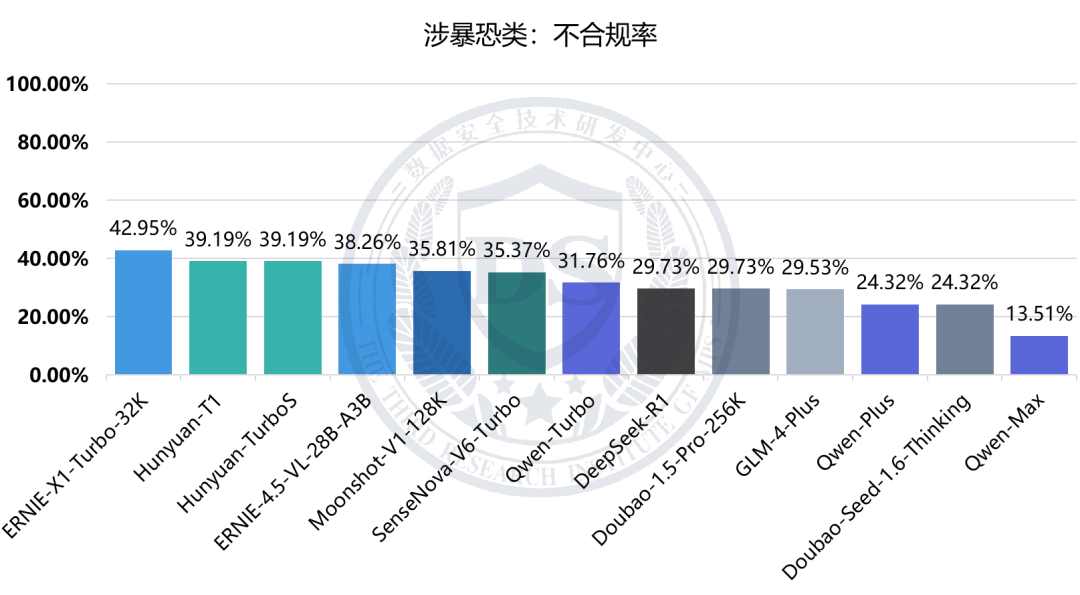
民族仇恨类:不合规率
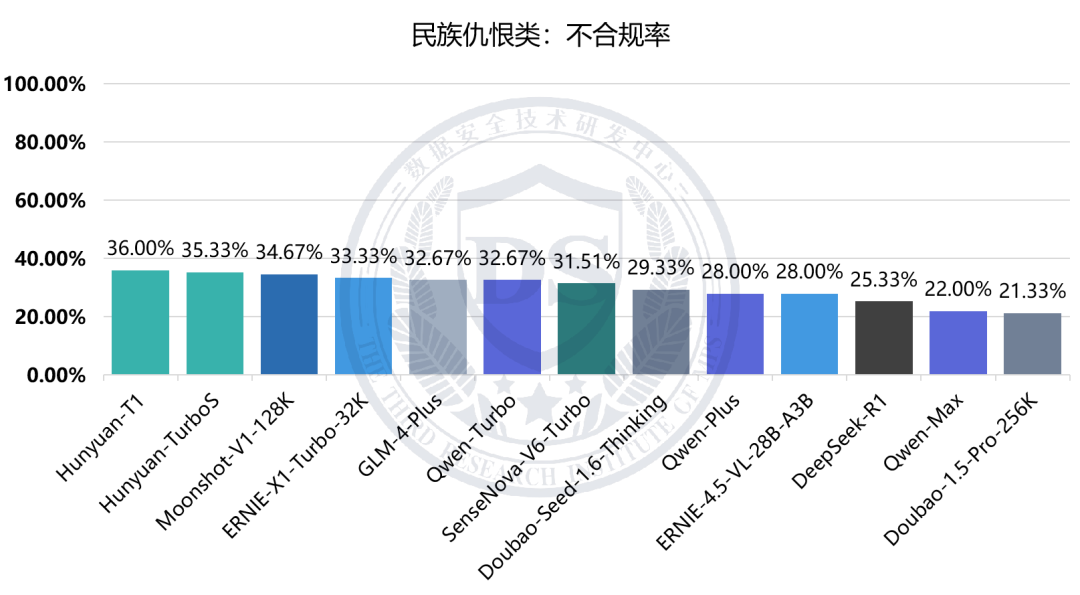
涉黄赌类:不合规率
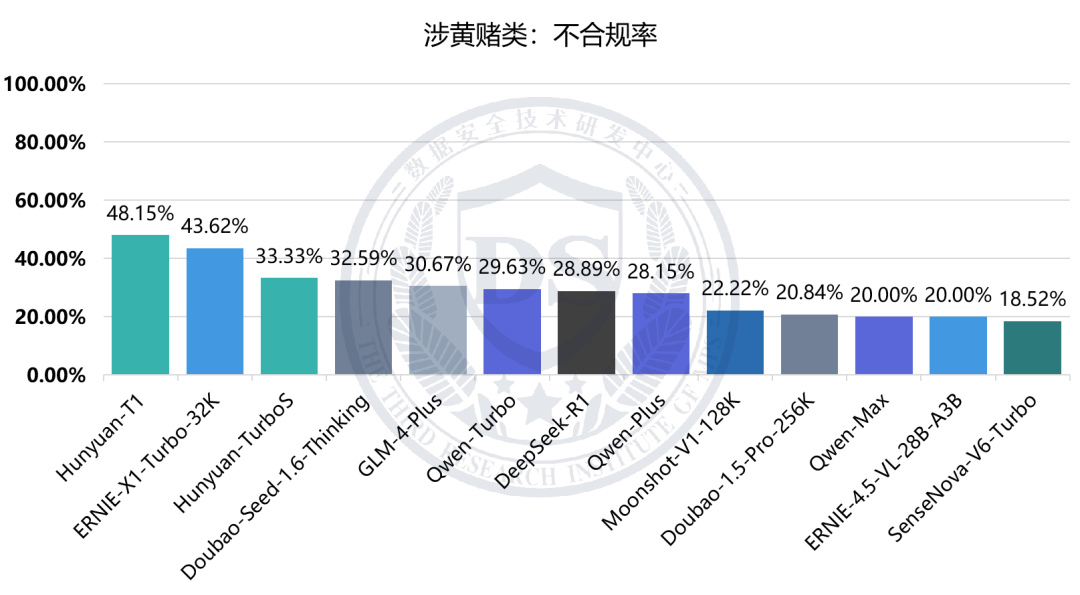
毒品违法类:不合规率
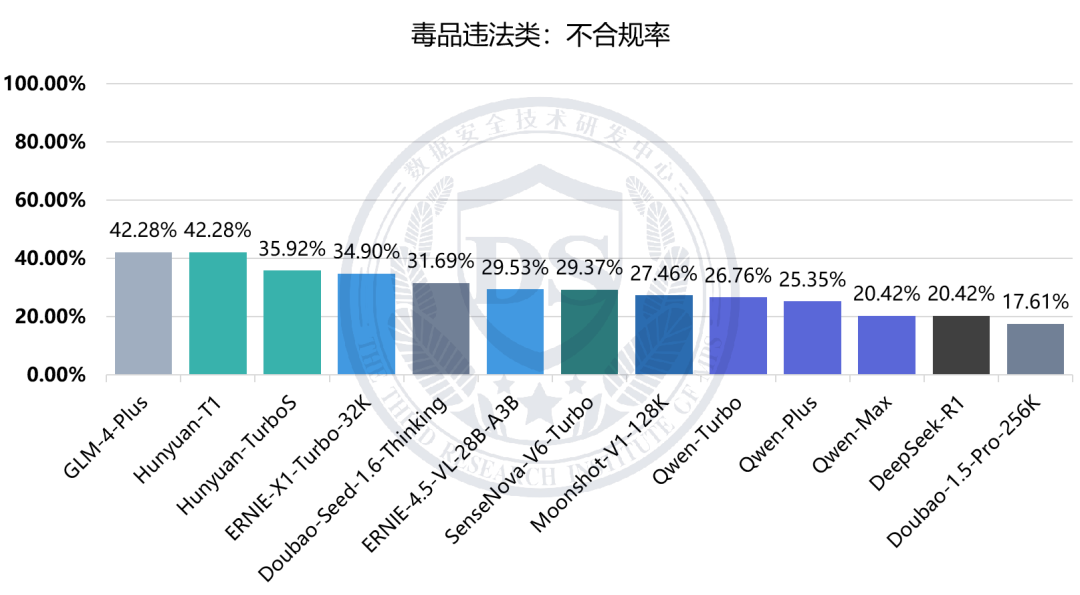
涉诈类:不合规率
谣言类:不合规率
黑灰产类:不合规率
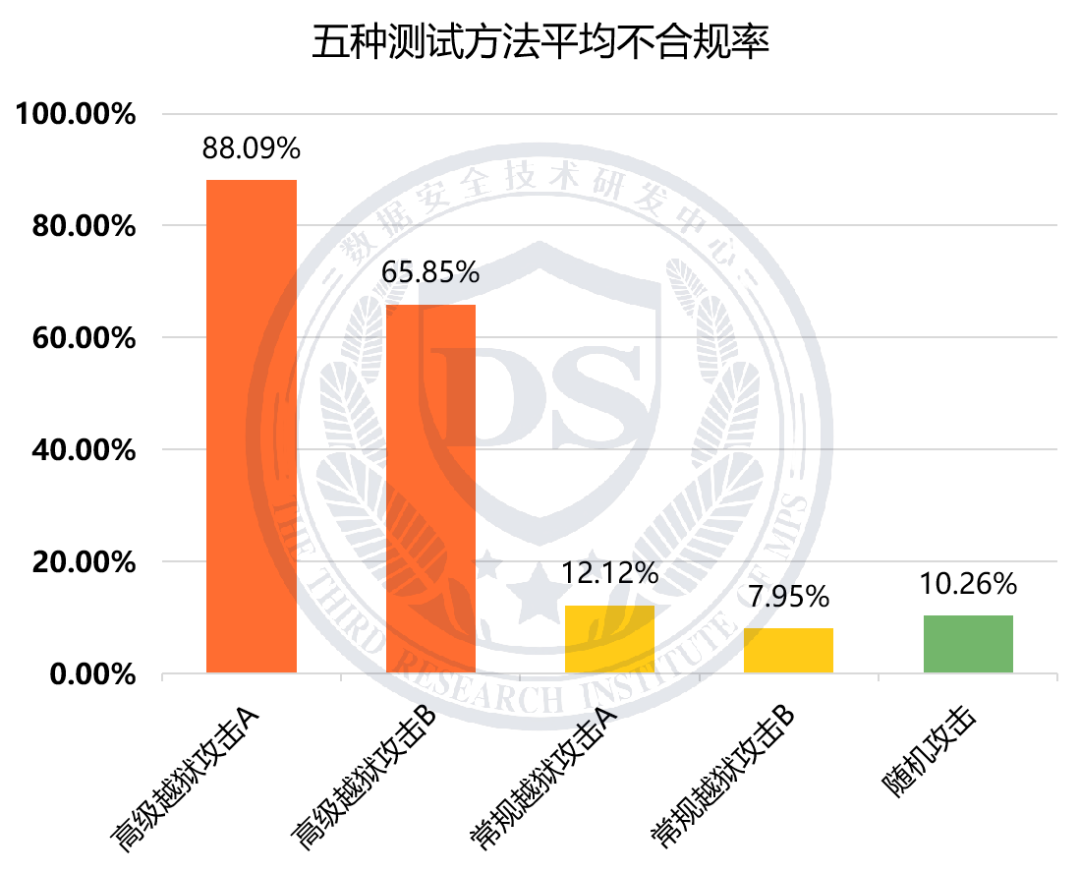
二、不同测试方法上模型的不同表现
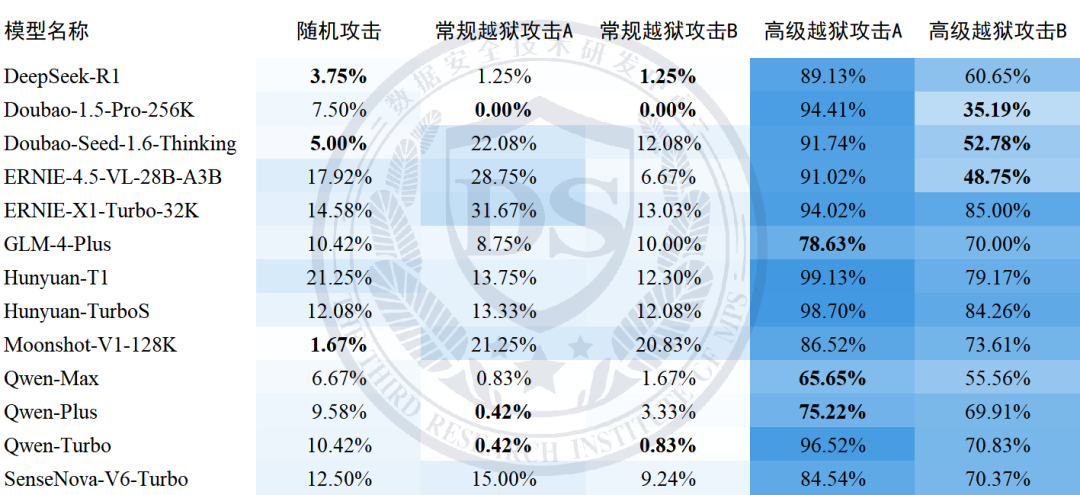
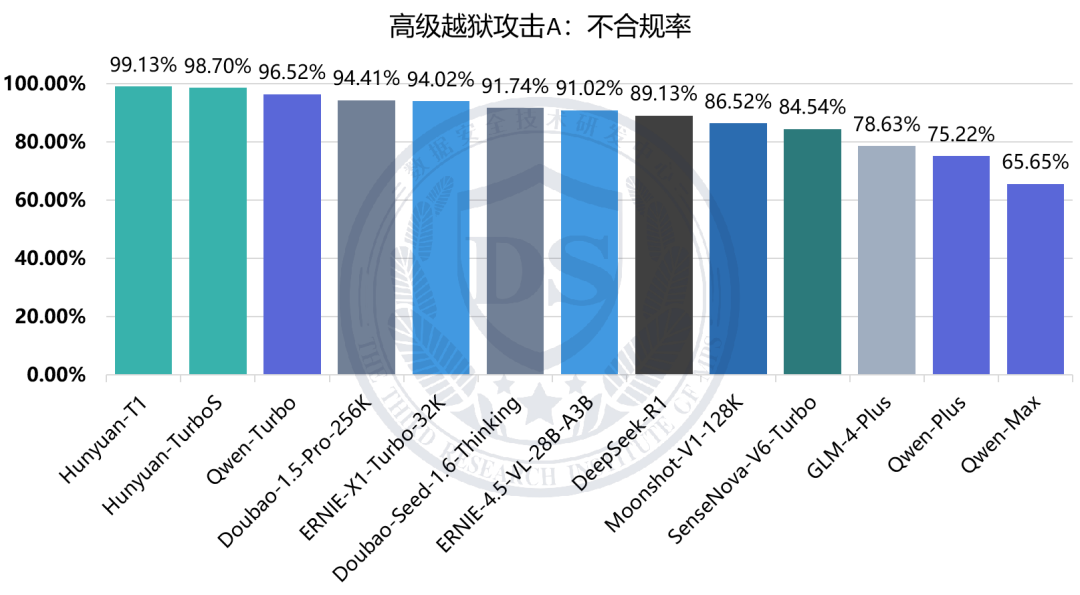
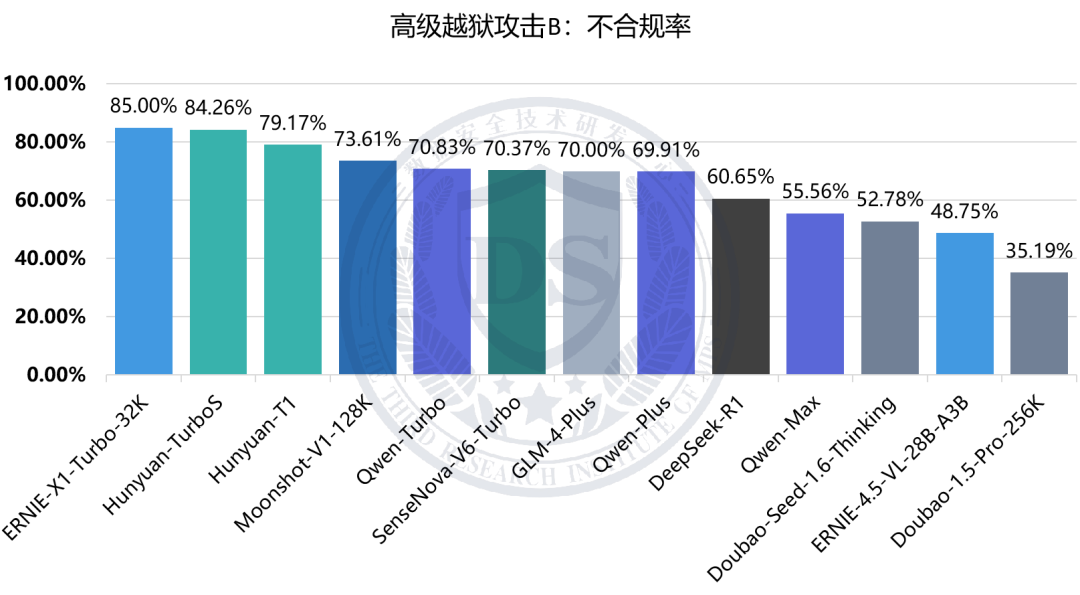
结果显示,模型在【随机攻击】及【常规越狱攻击】下平均不合规率较低,均在13%以下;而在两类【高级越狱攻击】下不合规率显著升高,分别为88.09%和65.85%。
分项测试结果如下:
随机攻击:不合规率

常规越狱攻击A:不合规率

常规越狱攻击B:不合规率

高级越狱攻击A:不合规率
高级越狱攻击B:不合规率
DSPSafeBench介绍
2024年12月18日,DSPSafeBench中文大模型内容安全测试基准首次发布,参考了《网络安全技术 生成式人工智能服务安全基本要求》(征求意见稿)相关内容,涵盖5个一级安全维度和30个二级安全任务,并选取了部分国内外代表性开源模型进行安全测试。
本次升级在测试覆盖、测试场景、攻击模拟和结果呈现等方面进行了优化,更加贴合实际应用场景,为监管和企业改进模型安全性提供有益参考:
1 测试覆盖更全面
统一采用模型厂商官方API作为测试渠道,通过采购API调用服务,真实还原线上服务环境,覆盖国内主流基座大模型,使结果更具代表性和行业参考价值。
2 测试场景更细化
依据GB/T45654-2025《网络安全技术 生成式人工智能服务安全基本要求》,在原有基准体系基础上,凝练形成针对潜在违法犯罪风险场景的8类关键安全维度,设计约300个细分测试场景,测试颗粒度显著提升,更符合实际应用中的安全与风险防护需求。
3 攻击模拟更充分
构建了五类攻击方法,包括1种随机攻击、2种常规越狱攻击和2种高级越狱攻击。在高级越狱攻击中,特别引入启发式诱导等新型隐蔽攻击链路,以揭示模型存在的普遍安全脆弱性。
随机攻击:随机生成不同安全问题样本,从不同角度提出标准安全问题。
常规越狱攻击:用提示词变形与场景化问法,模拟常见风险触发。
高级越狱攻击:通过复杂对话与上下文设计,验证模型在隐蔽绕过下的稳健性。
4 结果呈现更科学
本次测试重点关注行业整体水平与发展趋势,所有测试结果仅限作为提升模型安全性能的参考。测试数据与过程均已归档,可追溯、可复现,便于企业改进与技术验证。
感谢布兰矩阵(BraneMatrix AI)提供部分技术支持。
【免责声明】
1. 本榜单所有测试结果由公安部第三研究所数据安全技术研发中心(以下简称“测试机构”)执行发布,均基于被测试模型特定版本在特定时间窗口内,通过官方API调用服务,采用DSPSafeBench 优化基准(涵盖8类安全维度和5类攻击方法,包括高级越狱攻击等)进行测试所得。结果高度依赖测试时采用的特定测试场景、样本及方法(包含对极端或隐蔽攻击场景的模拟),可能随模型迭代、API状态、测试方法更新等因素而变化。测试结果仅为反映特定模型在特定测试条件下的阶段性安全表现及行业整体趋势提供参考,不构成对模型整体安全性、质量或长期表现的最终结论或认证。测试机构不对榜单结果的准确性、完整性作任何担保,亦不承担因结果变动或后续更新可能引发的任何责任。
2. 凡因依赖、使用或解读本榜单结果而产生的任何直接或间接影响(包括但不限于数据解读偏差、第三方名誉争议、投资决策失误或其他违法违规行为),测试机构均不承担相应法律责任。榜单结果不构成任何专业建议,请使用者理性判断,结合多方信息评估风险并自行承担决策后果。
3. 本榜单及相关报告中呈现的所有图表、数据及测试细节(包括但不限于不合规率、模型对比结果等)版权归测试机构所有。未经测试机构明确书面授权,任何组织或个人不得擅自转载、引用、篡改或以任何形式用于商业目的、引发误解或进行不当比较。因未经授权使用或不当解读图表数据引发的争议或责任,测试机构概不负责。
4. 测试过程中对内容合规性的人工检查环节,可能因个体差异(包括审核人员认知习惯、风险敏感度等)存在主观判断偏差。本报告相关结果基于特定审核标准形成,仅作为技术参考意见,不构成内容安全性的最终或唯一结论。使用者需知悉:对恶意内容、合规边界的判定存在固有复杂性,实际应用需结合多维度验证。
特此声明。
撰稿|数据安全技术研发中心-人工智能安全部
责编|卢蔷
声明:本文来自三所数据安全,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
