上回说到,奥巴马deepfake怼川普,斯嘉丽怒斥网友假视频。
deepfake,视频造假神器,把一个人的脸庞,转移到另一个的身上,让假新闻轻松传播到全网。
这下,不管是政要还是明星,都被“有视频有真相”的绯闻缠身,跳进密西西比河洗不清了。
即使是普通人,万一哪天被人构陷,做了小视频发到女朋友那里,恐怕是膝盖跪键盘,有嘴说不清。
因为你看,这些视频你能辨认出真假?

这张动图来自一段电视新闻男主播说话的视频,它是真的吗?

换这位女主播,她口播的这段视频是真的吗?

这位呢?
看起来毫无违和感,实际上,没有一个是真的。
视频(动图)上的这些人,从来都没有做出过这些口型和表情。
而且,这样的假视频,最近市面上出现了一大堆,来自一个德国意大利跨国团伙。
这一批视频里,包含没处理过的真实视频和处理过的假视频。真实视频都来自YouTube;而假视频则是他们用三种方法造假生成的。
这批视频数量也很惊人,总量多达1000段,总共超过150万帧,原始视频超过1.5 TB,其中视频质量最差的也有480p,甚至还有达到1080p的高清视频。
嗯,没错,这个团伙是一群高校里的AI研究者,而这些假视频,是一个数据集,名叫FaceForensics++。
有了这个数据集,就可以训练神经网络,鉴定出那些被AI换了脸的假视频,证明你的清白,拯救你的膝盖、键盘和女友。
以AI攻AI
这些假视频不仅出自不同的造假方法,质量也分三个等级。有原始的输出视频RAW、高质量视频HQ(使用h.264,参数为23进行压缩)和低质量视频LQ(参数为40)。
效果怎么样呢?肉眼很难分辨。
研究团队先找100多名学生测试了一下,让他们从两个视频中选出哪个是真哪个是假。
在最厉害的造假方法面前,人类学生们的准确率只有40%左右,还不如随便瞎蒙,可谓是假的比真的还像真的了。

就算是不那么精致的假视频,人类判断原始视频的平均准确率也只有72%,高质量视频71%,低质量视频因为相对模糊难以辨认,准确率只有61%。
有了足够多的数据,这个研究团队,就开始“以AI攻AI”,训练神经网络,鉴别那些被换脸AI处理过的假视频。
他们挑选了6个模型,用这些数据训练一遍之后,识别造假视频的准确率都比人类的肉眼高得多。
其中最好的模型,准确率达到了99.08%!不过这是在原始的输出视频上,在高质量视频略微降低到97.33%,就算是视频质量低,准确率还能到86.69%。
与人类的识别能力相比,高了20多个百分点。
这个模型是XceptionNet,出自Keras之父Francois Chollet之手,它是一个传统的CNN网络,是在具有残差连接的可分离卷积在ImageNet上训练出来的。
其他的模型虽然没有它优秀,但也有了很显著的提升。
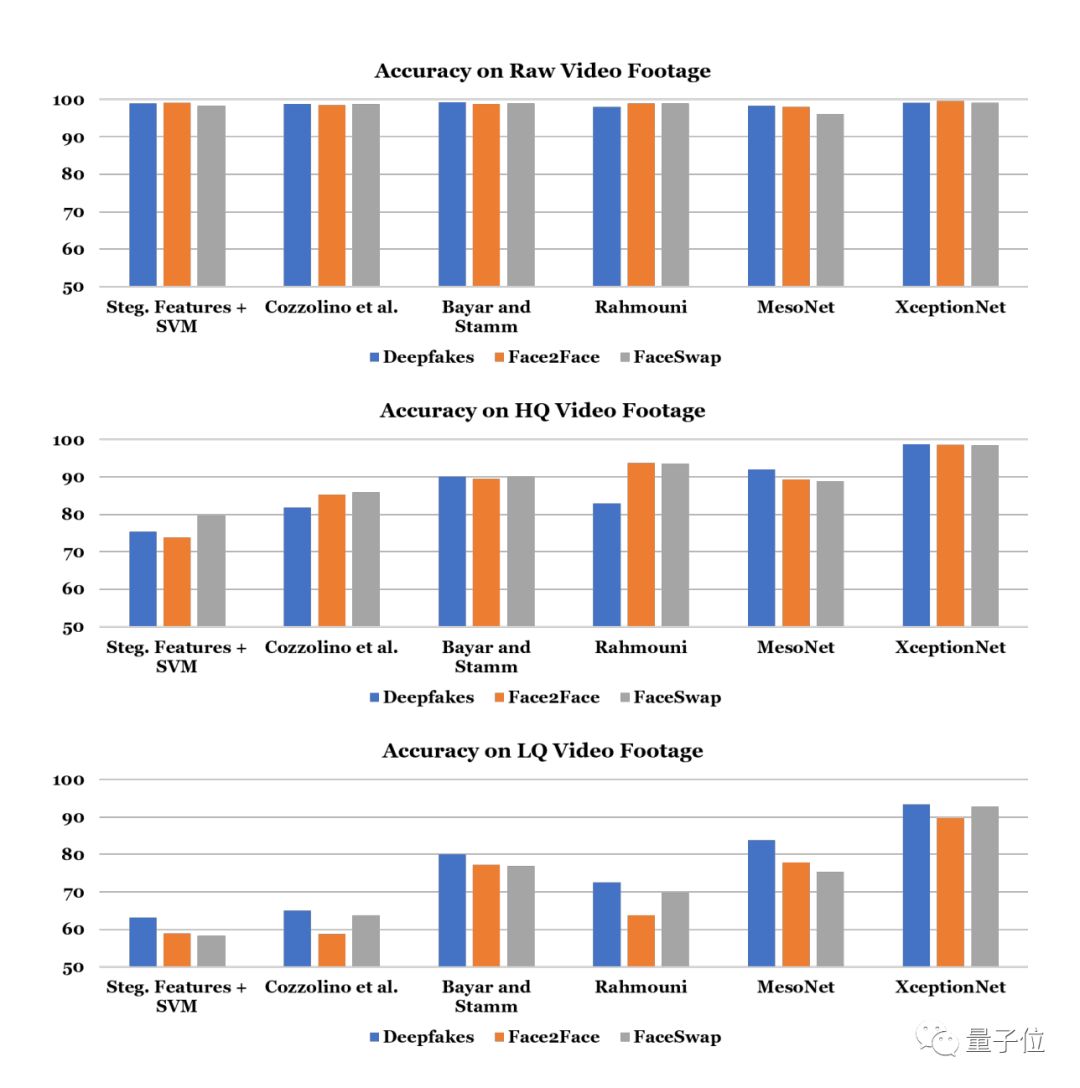
在原始视频上的识别准确率,都能达到95%以上,经过压缩的高质量视频上,是被准确率开始有差别,但XceptionNet依旧强劲。
质量较差的视频上,识别准确率基本上都大幅下降,最低的平均不到60%。但最高的XceptionNet还是能保持在86.69%。
那么,这个“神奇”的数据集是从哪来的呢?
造假の全过程
我们前边也提到过,原本都是YouTube上普普通通的视频,经过三种常用造假手段的改造,就成了这个数据集。
为了让这些假视频显得更加逼真,研究团队想了不少办法。
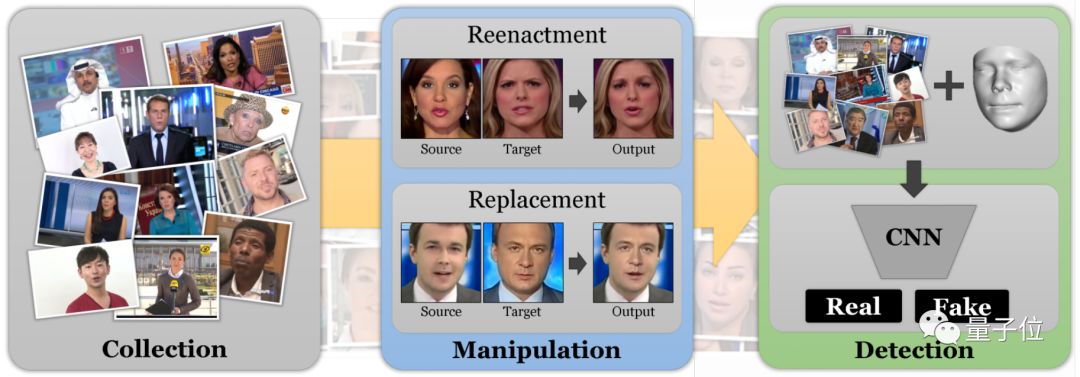
他们找的视频,里边当然都有人脸。这些原视频一部分来自谷歌YouTube-8M数据集,另一部分则是直接从YouTube网站上扒下来的。
视频收集好之后,还要用人脸检测器处理一遍,确保其中人物面部没被遮挡,再去掉渐变、叠加等过渡效果。最后,再人工筛选,确保视频质量够高,以保证后续造假的效果。
造假操作一共分为两类:
一是转移面部表情和动作的面部重演( facial reenactment),需要保留目标人的身份,像给视频里的奥巴马“施法”一样,让他做出一些新的表情。
一是面部交换(face swapping),用原始视频中人的面部替换目标视频中人的面部,比如把盖尔加朵的照片贴到爱情动作片女主角的脸上。

正式上手造假时,研究团队主要选择了三种方法。分别是用来换脸的FaceSwap、deepfake,和用来换表情的Face2Face。
Face2Face和FaceSwap都是通过重建面部的3D模型,并在3D模型中进行相应的编辑来完成造假。
其中FaceSwap是一个轻量级的编辑工具,使用比较稀疏的面部标记位置,将一个视频中的脸复制到另一个视频中的脸上。
相比之下,Face2Face的技术更加复杂,能够进行面部跟踪和建模,从而来换表情。
deepfake主要用来执行面部交换的操作,使用自动编码器用原始视频中的面部替换目标视频中的面部。
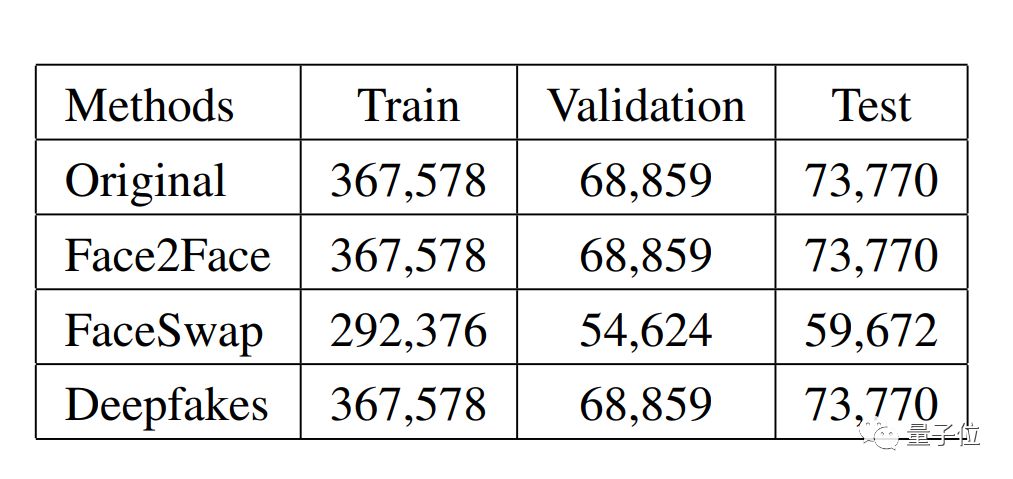
用这三种方法处理出来的数据集,被分成了训练、验证和测试数据集。
其中原始视频、Face2Face、deepfake的训练数据集都有36.7万帧图像,FaceSwap的较少,只有29.2万帧。训练数据集和验证数据集的规模,都在7万左右。
用这三种方法处理视频,都需要将原始视频和目标视频作为输入,最终输出逼真的假视频。
假视频,惹麻烦
在deepfake面世以前,视频换脸技术存在于电影拍摄中,需要相对较高的技术和资金投入。
而现在,deepfake等技术的出现大大降低了换脸门槛,人们不仅用它来制造政要们的假新闻,还用它来制造女明星的色情片。
寡姐斯嘉丽也是因此才公开表示,她对网络上出现的那些贴了她的脸的deepfake视频非常愤怒,但却无可奈何,无法阻止这些视频四处流传。

这下,对许多人来说,哪怕是再注意隐私,也无法阻止艳照门流传了。
去年5月,deepfake已经引起了五角大楼的注意,他们通过美国国防部高级研究计划局(DARPA)委托全美各地的专家,想方设法检测各类视频的真实性。
不久后,DARPA就研发了一款AI工具,能够自动监测处被换了脸的假视频,根据假视频一般不会表现出眨眼、呼吸和眼球运动这些特征,能够以99%的准确率识别出假视频。
不过现在,用不着请美国国防部出山了,只要有了这个FaceForensics++数据集,你也可以DIY训练AI来甄别假视频了。
传送门
论文:FaceForensics++: Learning to Detect Manipulated Facial Images
作者:Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, Matthias Nießner
https://arxiv.org/abs/1901.08971
GitHub:https://github.com/ondyari/FaceForensics
需要数据集的话,请去上面的GitHub页面,根据说明进行邮件申请。
声明:本文来自量子位,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
