
原文标题:Exploring Inherent Backdoors in Deep Learning Models
原文作者:Guanhong Tao], Siyuan Cheng, Zhenting Wang, Shiqing Ma, Shengwei An, Yingqi Liu, Guangyu Shen, Zhuo Zhang, Yunshu Mao, Xiangyu Zhang原文链接:https://ieeexplore.ieee.org/document/10918226发表会议:ACSAC笔记作者:牟浩天@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、引言
深度学习(Deep Learning, DL)技术因其卓越的性能,在众多领域实现了革命性的突破。深度学习模型已被广泛应用于各种实际系统,包括安全敏感的系统,如恶意软件检测和数字取证。 然而,近年来的研究表明,深度学习模型容易受到后门攻击的威胁。后门攻击是一种通过在输入样本中注入特定触发器,迫使模型在遇到该触发器时产生攻击者预定的错误输出的攻击方式。传统的后门攻击主要通过两种方式实现:一种是通过污染训练数据,另一种是直接篡改模型的权重参数。这些攻击方法都需要攻击者对训练过程或模型参数进行投毒。由此,文章提出了问题:后门攻击只能通过投毒来实现吗?
在围绕此问题展开研究的过程中,文章发现了大量存在于正常训练模型中的后门漏洞,这些漏洞并非由攻击者恶意注入,而是在使用如随机梯度下降这类的标准训练策略时,在干净数据上训练模型时自然产生的。这些后门被称为“固有后门”(inherent backdoors)。文章还进一步探讨了固有后门的分类方法、识别技术、普遍性以及防御策略,旨在全面揭示这一新型攻击向量,并为提高深度学习模型的安全性提供理论支持和实践指导。
2、动机
为了回答文章在引言中提出的关键问题:是否只能通过数据污染或模型篡改来实现后门攻击?文章在本小节通过最简单的补丁后门、更复杂的动态攻击以及NLP模型中的注入和固有后门这三个具体实例展示了在未被恶意操纵的正常训练模型中,同样可以找到与注入型后门攻击相似的触发器。这些触发器并非由攻击者注入,而是由于数据集构建和模型训练过程中存在的问题而自然存在。这些实例表明,后门可能作为正常训练模型的固有特性而存在,类似于传统软件中的漏洞。文章强调,这些固有后门可以被有效地利用,与注入型后门一样危险。因此,研究和理解这些固有后门对于提高深度学习模型的安全性至关重要。
3、定义后门漏洞
文章的第三章提出了一个通用的后门漏洞定义,该定义旨在涵盖所有可能的后门漏洞,无论是通过恶意注入还是自然存在于模型中的。这一定义基于四个关键属性:功能性、可利用性、触发一致性和人类感知稳定性。
功能性(Functionality):一个模型 f 具有良好的功能性,当且仅当其分类损失 L(f(x),y) 在数据分布 p(X,Y) 上的期望值小于一个非负阈值 η。即: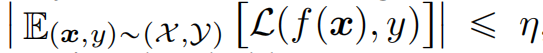 这表示模型在正常输入下的分类错误率低,具有较高的准确率。
这表示模型在正常输入下的分类错误率低,具有较高的准确率。
可利用性(Exploitability)和触发一致性(Trigger Uniformity):一个模型 f 被一个触发器函数 g 利用,当且仅当在应用触发器 g 后,模型对受害类别 yv的大部分样本的分类损失 L(f(g(x)),yt) 的期望值小于一个非负阈值 τ。即: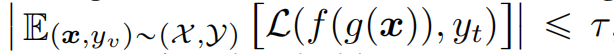 这要求触发器 g 能够将受害类别 yv的大部分样本错误分类为目标类别 yt,体现了后门的可利用性和触发一致性。
这要求触发器 g 能够将受害类别 yv的大部分样本错误分类为目标类别 yt,体现了后门的可利用性和触发一致性。
人类感知稳定性(Human Perception Stability):触发器函数 g 在人类感知上是稳定的,当且仅当在人类感知函数 f(h)下,触发器注入后的输入 g(x) 和原始输入 x 的分类结果的差异在人类可接受的范围内。即: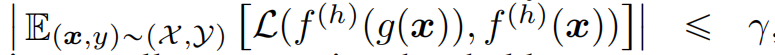 这表示触发器的存在不会改变人类对输入的分类结果,即使触发器本身可能被人类察觉。
这表示触发器的存在不会改变人类对输入的分类结果,即使触发器本身可能被人类察觉。
基于上述四个属性,文章正式定义了后门漏洞:一个模型 f 存在后门漏洞,当且仅当存在一个触发器函数 g,使得 f 具有良好的功能性,且 g 具有可利用性和人类感知稳定性。这个定义不关心后门是注入的还是固有的。注入型后门需要攻击者恶意操纵训练数据集或训练过程,而固有后门则存在于使用可信数据和过程训练的干净模型中。
虽然上述定义是一般性的,具有概念上的重要性,但它并不实用,因为f(h)是不现实的。为了便于实际研究和分类,文章引入了一个实用定义,使用调节空间(regulation space)和度量函数(metric function)来近似人类感知稳定性:调节空间与度量函数是一个二元组 (Z,Φ),其中 Z 是调节空间,Φ 是一个距离函数,用于计算 Z 中两个元素的距离。使用度量空间定义的更为实用的后门漏洞定义如下:给定一个调节空间与度量函数 (Z,Φ),模型 f 存在后门漏洞,当且仅当存在一个触发器函数 g,使得 f 具有良好的功能性,且 g 具有可利用性,并且在调节空间 Z 中,触发器注入后的输入 g(x) 和原始输入 x 的距离小于一个阈值 β。即: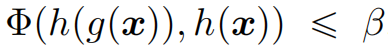 其中 h 是将输入空间投影到调节空间的函数。
其中 h 是将输入空间投影到调节空间的函数。
4、识别固有后门
由于很难知道固有后门的可能形式,文章将利用大量现有的注入式后门攻击作为指导。尽管它们都需要数据中毒,但它们提供了有关潜在易受攻击空间的强烈提示。
4.1 现有注入后门的分类
为了系统地识别固有后门,文章首先对现有的注入后门攻击进行了分类。分类的依据是后门攻击所利用的调节空间(regulation space)和度量函数(metric function)。调节空间是指后门触发器被应用的空间,而度量函数用于量化触发器在该空间中的变化。
在计算机视觉(CV)领域,作者将后门攻击分为四类:像素空间 L0、像素空间 L2、像素空间 L∞ 和特征空间 L2,如下表所示。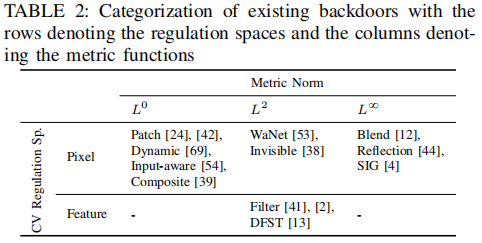
在自然语言处理(NLP)领域的后门攻击分类与CV领域类似,但具体形式不同,分为字符空间(Character Space)、词/令牌空间(Token/Word Space)和句法空间(Syntactic Space),如下表所示。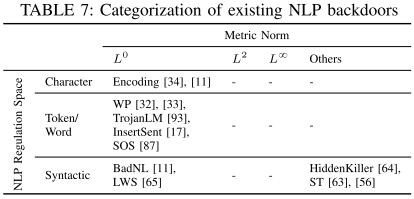
4.2 构建固有后门
识别固有后门的关键是找到触发函数g,类似于在易受攻击的软件中找到错误语句。然而,g是概念性的,可能没有精确的数学形式。根据文章对现有注入后门攻击的分类,它们会引起像素空间变化或特征空间改变。因此,文章分别使用以下两个方程来近似这种变化。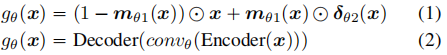 在(1)中,mθ1(x) 是一个掩码函数,决定哪些像素被更改以及更改的数量;δθ2(x) 是一个模式函数,描述更改的模式。这种形式的触发器函数允许在像素空间中进行有限数量的像素更改,类似于补丁攻击和动态攻击。在(2)中,Encoder 将输入投影到特征空间,convθ是一个卷积层,用于描述特征空间中的更改,Decoder 将更改后的特征投影回输入空间。这种形式的触发器函数允许在特征空间中进行有限的更改,类似于滤波器攻击和 DFST 攻击。
在(1)中,mθ1(x) 是一个掩码函数,决定哪些像素被更改以及更改的数量;δθ2(x) 是一个模式函数,描述更改的模式。这种形式的触发器函数允许在像素空间中进行有限数量的像素更改,类似于补丁攻击和动态攻击。在(2)中,Encoder 将输入投影到特征空间,convθ是一个卷积层,用于描述特征空间中的更改,Decoder 将更改后的特征投影回输入空间。这种形式的触发器函数允许在特征空间中进行有限的更改,类似于滤波器攻击和 DFST 攻击。
利用定义的触发函数,识别固有后门被简化为优化问题,优化框架如下图所示。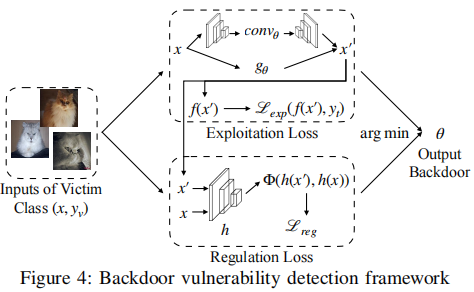 图的左侧是输入样本,这些样本来自受害类别。每个样本会经过触发器函数gθ的处理,处理后的样本被输入到模型f中,得到模型的输出。在模型输出的基础上,框架计算利用损失Lexp和调节损失 Lreg两个损失函数。它们衡量模型对触发器注入样本的错误分类程度,即模型输出与目标标签之间的差异,确保触发器在调节空间中的变化不超过一个预设的阈值,从而保证触发器在人类感知上是稳定的。 这两个损失函数被结合起来形成一个总损失函数。通过优化算法,如梯度下降,触发器参数θ被不断更新,以最小化总损失函数。这一过程会持续迭代,直到损失函数收敛,即找到一个触发器函数,使得模型在该触发器下表现出后门漏洞的特性。
图的左侧是输入样本,这些样本来自受害类别。每个样本会经过触发器函数gθ的处理,处理后的样本被输入到模型f中,得到模型的输出。在模型输出的基础上,框架计算利用损失Lexp和调节损失 Lreg两个损失函数。它们衡量模型对触发器注入样本的错误分类程度,即模型输出与目标标签之间的差异,确保触发器在调节空间中的变化不超过一个预设的阈值,从而保证触发器在人类感知上是稳定的。 这两个损失函数被结合起来形成一个总损失函数。通过优化算法,如梯度下降,触发器参数θ被不断更新,以最小化总损失函数。这一过程会持续迭代,直到损失函数收敛,即找到一个触发器函数,使得模型在该触发器下表现出后门漏洞的特性。
5、实验评估
5.1 实验设置
文章从互联网上下载了40个预训练的计算机视觉(CV)模型,这些模型基于ImageNet和CIFAR-10数据集训练,涵盖了34种不同的模型架构,属于15个不同的架构族。此外,作者还研究了对抗性训练的鲁棒模型,以评估这些模型对固有后门的抵抗力。对于自然语言处理(NLP)领域,文章下载了14个正常训练的模型,这些模型来自一个知名的基准测试。
5.2 识别固有后门的结果
文章考虑了两种类型的后门:通用后门(universal backdoor)和标签特定后门(label-specific backdoor)。对于通用后门,作者使用了5-6个随机标签作为目标;对于标签特定后门,作者考虑了35个随机标签对。实验以攻击成功率 ASR (attack success rate)作为评估指标,部分结果如下表所示。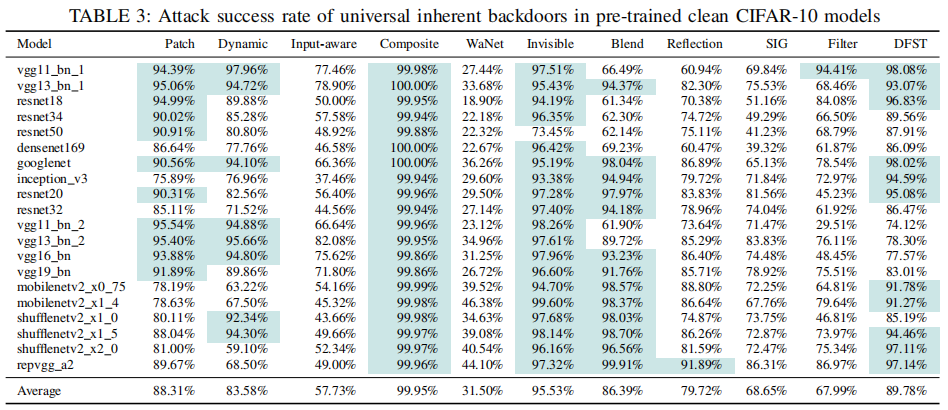
在实验中,文章发现许多固有后门具有很高的ASR。在CIFAR-10模型中,补丁后门的平均攻击成功率超过75%,而复合后门的平均攻击成功率甚至达到了99.95%。动态、不可见、混合、反射和DFST后门也表现出较高的平均攻击成功率。此外,输入感知、SIG和滤波器后门也有合理的平均攻击成功率,尽管它们的方差略大于其他固有后门,这可能是由于这些后门利用了特定于模型架构的脆弱性。
 在NLP模型中,作者发现所有下载的模型都存在固有后门,攻击成功率超过80%,并且触发词数量不超过10个。在一个IMDB ALBERT模型中,仅使用一个触发词就能达到84.78%的攻击成功率。在Rotten Tomatoes数据集上,仅需四个触发词就能欺骗DistilBERT、BERT和RoBERTa模型,攻击成功率超过94%。 作者还探索了一个零日固有后门,即在频率空间中寻找固有后门。通过使用离散傅里叶变换(DFT)将输入图像投影到频率空间,作者发现了一个固有后门,其平均攻击成功率为89.40%,并且在所有输入中都被错误分类为目标标签1。这个后门主要利用了高频成分的扰动,其在输入空间的表现类似雨滴或水波纹。
在NLP模型中,作者发现所有下载的模型都存在固有后门,攻击成功率超过80%,并且触发词数量不超过10个。在一个IMDB ALBERT模型中,仅使用一个触发词就能达到84.78%的攻击成功率。在Rotten Tomatoes数据集上,仅需四个触发词就能欺骗DistilBERT、BERT和RoBERTa模型,攻击成功率超过94%。 作者还探索了一个零日固有后门,即在频率空间中寻找固有后门。通过使用离散傅里叶变换(DFT)将输入图像投影到频率空间,作者发现了一个固有后门,其平均攻击成功率为89.40%,并且在所有输入中都被错误分类为目标标签1。这个后门主要利用了高频成分的扰动,其在输入空间的表现类似雨滴或水波纹。
文章还探索了一个零日固有后门,即在频率空间中寻找固有后门。通过使用离散傅里叶变换(DFT)将输入图像投影到频率空间。下图显示了频率空间中固有后门的示例,其平均攻击成功率为89.40%,并且在所有输入中都被错误分类为目标标签1。 这个后门主要利用了高频成分的扰动,其在输入空间的表现类似雨滴或水波纹。
这个后门主要利用了高频成分的扰动,其在输入空间的表现类似雨滴或水波纹。
文章还将现有的流行后门扫描工具(如NC、Pixel和ABS)应用于下载的预训练模型。这些工具主要能够识别属于像素空间L0类别的补丁型固有后门,但无法覆盖所有四类固有后门。相比之下,文章提出的方法能够识别315个固有后门,覆盖了所有四类固有后门。
文章最后研究了对抗性训练是否能够提高模型对固有后门的鲁棒性。实验结果表明,对于小的鲁棒性参数,像素空间L0类固有后门的攻击成功率仍然超过70%。当鲁棒性参数增大时,固有后门的尺寸超过了注入型后门的尺寸,此时模型准确率显著下降。总体而言,对抗性训练确实在一定程度上增强了模型对固有后门的抵抗力,尤其是在像素空间L0类后门方面。然而,这种增强是以牺牲模型在正常输入上的准确率为代价的。此外,对抗性训练对特征空间L2类后门的效果不稳定,说明模型在不同鲁棒性参数下的表现存在波动。
6、理解固有后门
本节中文章从三个方面研究了固有后门的潜在原因:数据集,模型架构和学习过程。文章改变这些方面的设置,并观察脆弱性水平的变化。
6.1 数据集的影响
为了验证固有后门的起源与训练数据集密切相关这一假设,文章研究了固有后门在不同模型间的迁移性。这些模型虽然具有不同的架构和学习过程,但都基于相同的数据集进行训练。文章使用三个不同架构的模型(vgg13 bn、resnet18 和 googlenet)识别出的固有后门去测试其他模型,结果如下所示。
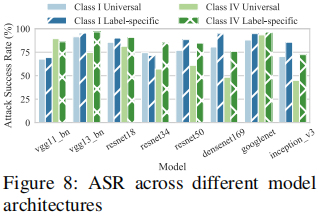
实验结果表明,固有后门在不同模型间具有较高的迁移性。在三个不同架构的模型识别出的固有后门,在其他模型上仍然有效,攻击成功率(ASR)大多超过70%。这表明,即使模型架构不同,只要它们基于相同的数据集训练,就会继承相似的脆弱性。
文章还研究了使用不同子集的训练数据对模型的影响,结果如下表所示。
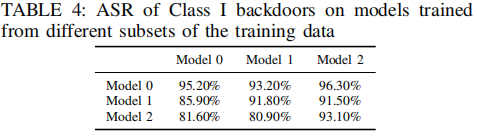
实验发现,基于80%随机选择的数据训练的模型生成的固有后门,同样可以迁移到其他模型上。这进一步证明了数据集在固有后门形成中的重要作用。文章推测,模型在训练过程中可能会学习或过拟合数据集中相似的低级特征,从而导致固有后门的出现。使用更多样化或更大规模的未标记数据集可能会缓解这一问题。
6.2 模型架构的影响
文章还研究了模型架构对固有后门的影响,结果如下。
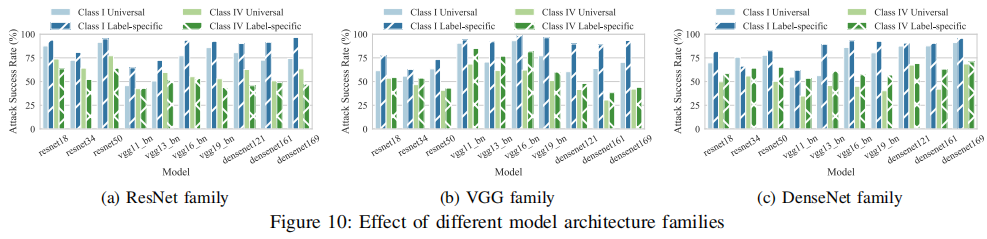
同一架构家族内的模型对固有后门的脆弱性相似,而不同架构家族之间的脆弱性较低。在上图a中,在ResNet家族中,为resnet18和resnet50生成的固有后门在resnet34上也表现出较高的ASR,但在VGG和DenseNet家族的模型上效果较差。文章还观察到,某些固有后门(如像素空间标签特定类I后门)在不同架构的模型上都表现出较高的鲁棒性。这表明,这些后门可能利用了模型普遍学习的低级特征。相比之下,特征空间的后门更容易受到模型架构的影响,可能是因为不同架构对特征的表示方式存在差异。
6.3 学习过程的影响
文章考虑了六种类型的训练因子:批处理大小、训练时期、学习速率、权重衰减、优化器和调度器。使用前文中的resnet18模型,并将其原始训练设置作为默认设置(如下表所示)。 文章通过一次只改变一个因子并从头开始重新训练模型来进行受控实验,使用在本节第一个实验中构造的后门来测试,结果如下。
文章通过一次只改变一个因子并从头开始重新训练模型来进行受控实验,使用在本节第一个实验中构造的后门来测试,结果如下。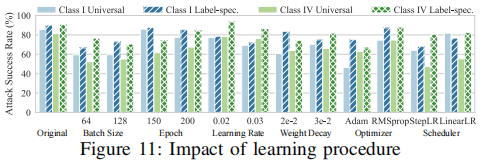 实验结果显示,减小批量大小会显著降低固有后门的攻击成功率,但其他超参数的影响较小。Adam优化器对通用像素空间类I后门的攻击成功率有显著影响,这可能是因为其不同的梯度更新策略改变了模型对通用特征的学习。学习率调度器对特征空间类IV后门的攻击成功率也有一定影响。总体而言,固有后门在不同训练设置下仍能保持一定的攻击成功率,尽管存在一些波动。文章认为这表明正常的训练过程可能无法完全消除模型中易受固有后门攻击的低级特征,可能需要更先进的训练策略,以提高模型对固有后门的抵抗力。
实验结果显示,减小批量大小会显著降低固有后门的攻击成功率,但其他超参数的影响较小。Adam优化器对通用像素空间类I后门的攻击成功率有显著影响,这可能是因为其不同的梯度更新策略改变了模型对通用特征的学习。学习率调度器对特征空间类IV后门的攻击成功率也有一定影响。总体而言,固有后门在不同训练设置下仍能保持一定的攻击成功率,尽管存在一些波动。文章认为这表明正常的训练过程可能无法完全消除模型中易受固有后门攻击的低级特征,可能需要更先进的训练策略,以提高模型对固有后门的抵抗力。
7、固有后门的防御
大多数现有技术旨在防御注入型后门,比如拒绝带有后门触发器输入样本的攻击实例检测;确定模型是否有后门的后门扫描;消除中毒模型中注入型后门的后门删除和证明模型在存在后门的情况下仍能正确预测的认证鲁棒性。在本节中,文章将研究它们对固有后门的有效性。
7.1 攻击实例检测
攻击实例检测是一种实时防御方法,旨在检测输入样本中是否包含后门触发器。现有的方法如STRIP和Activation Clustering在检测注入型后门方面表现出色。
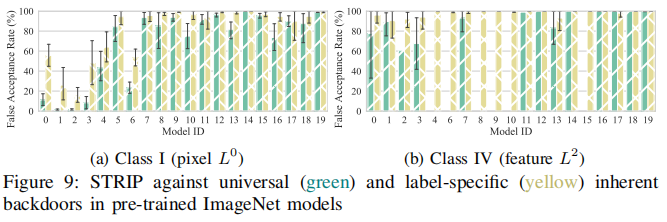
文章对ImageNet模型上的固有后门应用STRIP(结果如上图所示),实验发现其对通用类I像素后门仅能成功防御4个模型,对标签特定后门仅能保护1个模型。对于类IV后门,STRIP完全无效。文章同样发现Activation Clustering方法无法有效检测固有后门样本,这是因为固有后门利用的是模型正常学习的特征,当带毒样本与干净样本叠加时,固有后门与正常特征混合,难以区分。
7.2 认证鲁棒性
认证鲁棒性旨在确保即使输入带有后门触发器,也能正确预测。现有的PatchCleanser方法应用doublemasking来验证预测。具体来说,它遍历输入中的所有位置并添加掩码(即,黑色补丁)。如果预测是一致的,它会将其视为最终输出。否则,PatchCleanser会应用另一轮掩码在第一轮掩码的顶部进行掩蔽。文章利用上文中的四类固有后门漏洞对PatchCleanser方法进行验证,发现其对固有后门的认证鲁棒性接近0%。原因在于这些方法假设触发器具有特定的空间分布或大小,而固有后门的触发器可能分布更广,需要更大的掩码才能消除。
7.3 后门扫描
后门扫描旨在确定模型是否包含后门。文章应用了现有的NC、Pixel和ABS等扫描技术,发现这些工具只能识别固有后门漏洞的部分子集,覆盖范围有限。这表明现有后门扫描技术对固有后门的检测能力不足。
7.4 后门删除
后门移除技术的目标是从已经被污染的模型中清除后门。现有的技术包括Fine-pruning以及模型强化。
Fine-pruning通过选择在干净输入上激活值低的神经元并进行剪枝,然后使用修剪后的少量干净样本微调模型。文章按照原始论文的方法进行实验,确保所有剪枝后的模型的准确率下降不超过2%。实验结果表明,Fine-pruning几乎无法移除固有后门,剪枝后的模型的攻击成功率(ASR)与原始模型几乎相同或略有下降。这表明固有后门深深植根于模型学习到的低级特征中,仅通过剪枝神经元无法有效消除。
模型强化使用动态生成的后门触发器反向重新训练模型。它不仅可以消除注入的后门,也可以消除固有的后门。文章使用现有的MOTH框架,但替换了其触发器生成方法,以适应固有后门的特性。实验表明,针对特定类别的固有后门触发器进行强化训练,可以降低模型对该类后门的脆弱性,同时保持较高的清洁准确率。然而,这种强化对其他类别后门的效果有限,表明需要针对不同类别的后门分别进行强化。
8、总结
本文对固有后门进行了系统性研究,发现它们广泛存在于干净模型中,与注入型后门一样具有危险性,是一种新型攻击媒介。由于这些模型本身未被篡改,现有的针对注入型后门的防御方法,如后门扫描、攻击实例检测、认证鲁棒性及基于神经元修剪的后门移除方法,在很大程度上对固有后门无效。文章指出,模型强化加固是一种有前景的防御技术,能够有效减轻固有后门的威胁。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
