
原文标题:PaDeLLM-NER: Parallel Decoding in Large Language Models for Named Entity Recognition
原文作者: Jinghui Lu, Ziwei Yang, Yanjie Wang, Xuejing Liu, Brian Mac Namee, Can Huang原文链接:https://openreview.net/pdf?id=vjw4TIf8Bo发表会议:Nips"24笔记作者:彭佳仁@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1. 研究背景
命名实体识别(NER)中存在两种典型的自回归输出格式:
(1)调整原始输入文本以包含标签信息,这被称为“增强语言”;
(2)直接使用一种定制的、易于解析的结构化格式来输出所有标签和提及,这被称为“结构化标注”。
这些格式带来了一些挑战。例如,增强语言需要复制所有原始输入文本,从而增加了输出长度并导致推理效率低下。虽然结构化标注避免了复制整个输入,但它以自回归的方式生成所有标签和提及。这意味着每个后续生成的对都依赖于其前面的对,当标签-提及对的数量很大时,会导致序列更长。之前研究证明LLM 中的高延迟主要源于长序列生成,作者认为通过减少序列长度,可以为 NER 任务提供更高效的推理方案。
2 方法
2.1 指令微调的重构
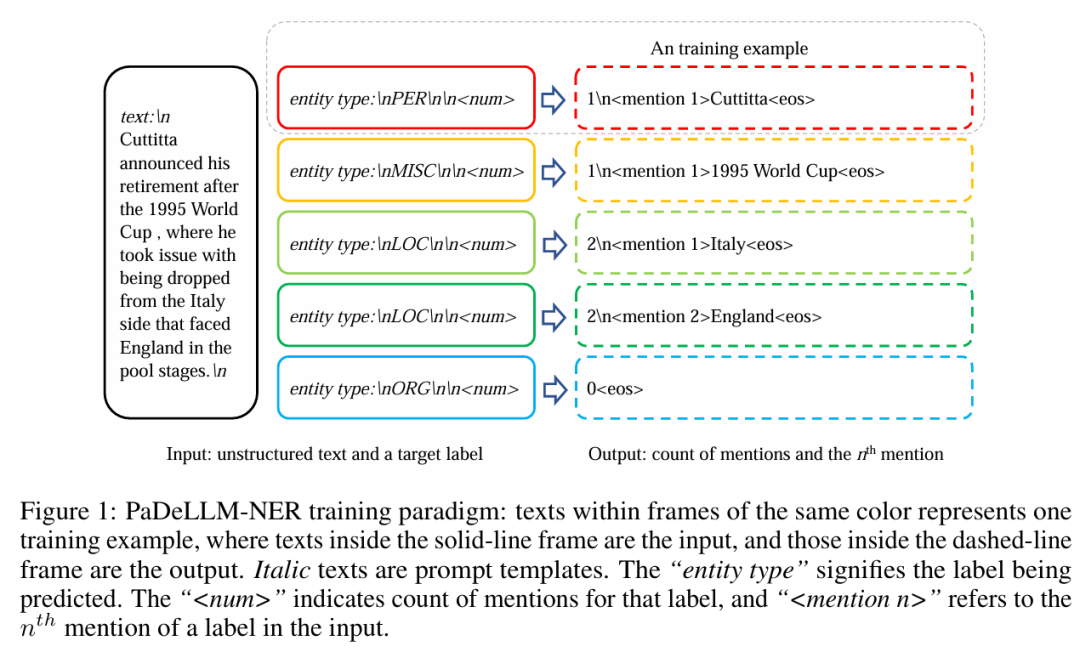
重构的图示在图 1 中展示。其中包含四个标签:person (PER), miscellaneous (MISC), location (LOC), 和 organization (ORG)。
在重构过程中,一个包含所有标签-提及对的非结构化文本被分割成多个序列。每个新序列的输出包括一个指定标签(表示为“entity type”)的提及数量,后跟该标签的第 个提及(表示为“”)。因此,在这个例子中,一个原始的训练数据被转换成五个新的训练数据条目。其中包括两个用于预测“LOC”(有 2 个提及),一个用于预测“MISC”(有 1 个提及),一个用于预测“PER”(有 1 个提及),以及一个用于预测“ORG”(有 0 个提及,直接预测“”)。
2.2 标签-提及对的推理
给定一个训练好的 LLM,作者提出一个两步推理方法:首先,根据提示预测特定标签的提及数量;其次,给定标签和提供的索引,精确地识别相应的提及。
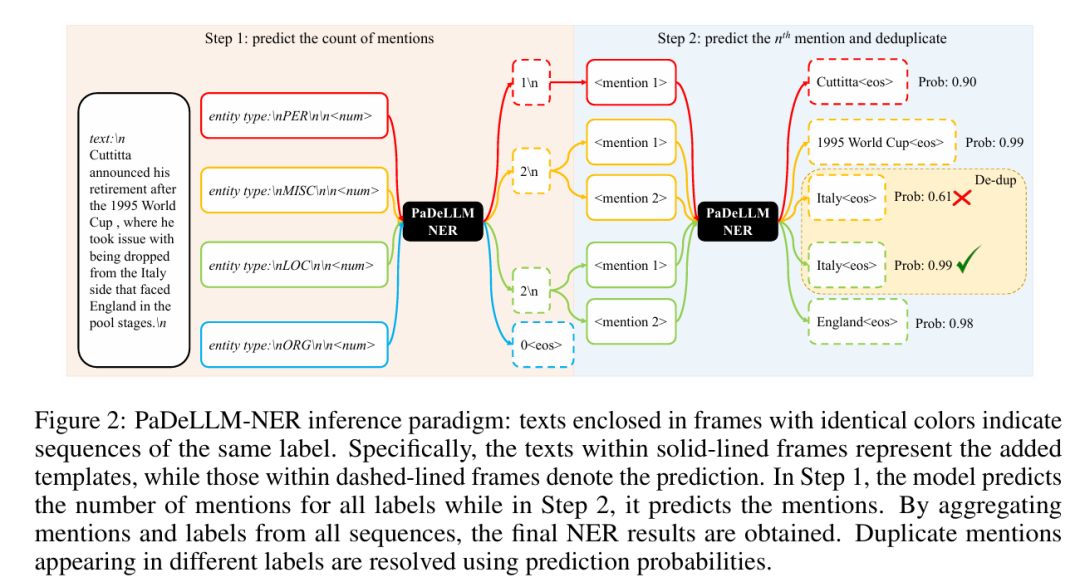
图 2 展示了 PaDeLLM-NER 推理的概览。在步骤 1 中,模型根据标签提示预测输入中每个标签的总提及数。一个单独的词元“\\n” 标志着这个计数预测的完成。如果给定标签的提及不存在,模型会生成一个“”词元,并跳过该标签的步骤 2。在步骤 2 中,在将预测的提及数添加到输入之后,会附加提及索引模板。随后,模型在前面词元的条件下生成相应的提及。所有标签-提及对的解码是并行发生的,允许它们同时生成。
在实践中,如果有足够的 GPU 资源,可以为每个标签的提及数量推理以及后续的提及文本片段推理分配在不同的 GPU 上。如果 GPU 资源有限,推理也可以使用批量推理部署在单个 GPU 上,以促进并行解码。以图 2 为例,在步骤 1 中,批处理大小为 4,因为数据集中有四个标签。在步骤 2 中,批处理大小为 5,反映了在步骤 1 中确定的五个标签-提及对(即“PER”中 1 个,“MISC”中 2 个,“LOC”中 2 个)。这种并行解码策略能有效降低推理延迟,特别是在输入以流式方式接收的场景中。
2.3 重复提及的移除
与自回归解码不同,PaDeLLM-NER 独立生成每个标签-提及对。这种推理策略意味着模型可能会错误地生成在多个标签中重复的提及。如图 2 所示,模型正确地将“LOC”的第一个提及预测为“Italy”,但它也错误地将“MISC”的第二个提及预测为“Italy”。
为了解决重复提及的问题,作者建议使用预测概率来移除重复的提及。具体来说,计算每个提及实例的预测概率。这是通过公式 来完成的,其中 代表提及文本的起始词元索引, 代表结束词元索引。然后,对于出现在多个标签中的一个提及,将保留概率最高的那个提及实例。
3 实验
3.1 数据集、主干模型和指标
零样本数据集:使用 Pile-NER 数据集训练 PaDeLLM。为了评估模型在未见过的实体类别上的零样本能力,选择了两个公认的基准:CrossNER 和 MIT。
有监督数据集:英语数据集包括通用领域的扁平化 NER 数据集 CONLL2003、嵌套 NER 数据集 ACE2005 以及生物医学领域的嵌套 NER 数据集 GENIA。中文数据集包括四个常用的通用领域扁平化 NER 基准:Resume(简历)、Weibo(微博)、MSRA 和 Ontonotes 4.0,以及两个垂直工业领域的扁平化 NER 数据集:YouKu(优酷)和 Ecommerce(电商)。
主干模型:使用 Llama2-7b 和 Baichuan2-7b 的预训练版本作为英语和中文研究的基础模型。
指标:评估涵盖两个维度:预测质量和 NER 推理的加速。(1)预测质量,采用微观 F-score。(2)推理速度,使用以下代码记录延迟:
start = time.time(); model.generate(); latency = time.time() start。
3.2 主要结果
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
