基本信息
原文标题:LLMHoney: A Real-Time SSH Honeypot with Large Language Model-Driven Dynamic Response Generation
原文作者:Pranjay Malhotra
作者单位:Birla Institute of Technology and Science, Pilani
关键词:SSH蜜罐,大语言模型(LLM),动态应答,虚拟文件系统,网络安全,攻击诱捕,命令仿真,系统实现,性能评测
原文链接:https://arxiv.org/abs/2509.01463
开源代码:暂无
论文要点
论文简介:本文提出一种全新架构的动态高交互SSH蜜罐系统——LLMHoney,利用大语言模型(LLM)驱动生成现实感极强的shell命令响应,以突破传统低/中交互蜜罐响应静态、可被识别的局限。LLMHoney将基于字典的虚拟文件系统与LLM结合,实现常见命令的快速仿真与非常规操作的灵活应对,在保证输出仿真度的同时大幅降低系统延迟。作者实现了完善的原型系统,基于十三种LLM,包括开源与商用模型,在138条Linux典型命令覆盖下系统性评估其准确率、响应延迟、内存消耗等指标。研究进一步对比分析LLMHoney与主流蜜罐方案Cowrie的优劣,并探讨了LLM接入带来的新挑战和未来方向,为网络安全攻防与蜜罐智能化进化提供了有力的实证支撑。
研究目的:针对当前传统SSH蜜罐以有限脚本和静态内容应对攻击、难以欺骗高水平攻击者、缺乏灵活性的关键问题,本文旨在探索大语言模型在网络诱捕系统中的创新应用,即实现能够以“人类水平”智能、动态地应答任意shell命令,显著提升蜜罐的交互真实性与扩展性,同时兼顾响应延迟与运算成本,推动蜜罐技术向更真实、更自动化的方向演进。
研究贡献:
首次提出将预训练大语言模型集成到SSH蜜罐命令应答闭环,实时输出丰富多变的shell响应,极大提升系统诱骗能力。
设计并实现了状态化虚拟文件系统与命令状态跟踪机制,通过字典缓存通用命令、状态感知地指导LLM调用,兼顾仿真一致性、低延迟与灵活泛化,显著降低“幻想”式错误。
构建了覆盖13种LLM的自动化评估框架,综合评测输出准确性(多重相似度量/成功率)、延迟、内存,量化各类型模型在蜜罐场景下的适配性与表现边界。
系统性比较LLMHoney与Cowrie等传统蜜罐的本质差异、性能优劣与安全性特征,总结LLM集成带来的实际收益与挑战,为相关领域后续发展提供理论与实现参考。
引言
蜜罐作为网络安全中的关键防御技术,通过构建诱捕系统吸引并研究攻击者行为,实现情报收集和主动防御。当前行业主流SSH蜜罐如Cowrie依赖固定应答脚本与预设文件系统,仅能捕捉基础攻击或自动化行为,难以有效挑战复杂攻击者,这成为蜜罐技术进步的显著制约因素。高交互蜜罐虽然能增强仿真能力,但维护成本极高且有被攻陷风险。
随着大语言模型(LLM)在自然语言生成领域取得突破,研究者看到了利用LLM打造“高真实感、低风险”新型蜜罐的可能性。LLM能够理解并生成上下文相关的自然语言内容,对于模拟复杂终端环境与攻击交互场景具备独特优势。基于此,本文面向SSH服务场景,提出LLMHoney系统,深度融合LLM智能应答与虚拟化文件系统,有效强化蜜罐的互动真实性、灵活性和安全隔离能力。
通过prompt工程和定制系统状态维护,让LLM能基于历史操作输出不自相矛盾、仿真度极高的shell响应,并为常规命令走高速字典缓存通路,实现低延迟与大覆盖的统一。文中不仅详述系统全流程设计,还基于开放与商用多种LLM模型,设计全面测评体系,首次量化了不同规模、类型LLM在该场景下的性能边界与适用性,总结了LLMHoney对蜜罐演进的推动意义与挑战,对比传统蜜罐体系指出本方案在自动化智能诱捕方向的重大创新及未来改进空间。
相关工作
蜜罐技术在网络安全领域已有广泛研究,方法按交互深度分为低/中/高交互类型。低交互蜜罐如Honeyd仅模拟部分协议,功能有限。中交互蜜罐Cowrie等以Unix shell仿真、虚拟文件系统为代表,能较好捕捉攻击,但依赖固定脚本和静态文件内容,缺乏对未知和复杂行为的自适应响应能力,易被熟练攻击者识破。高交互蜜罐通过真实操作系统环境诱捕,虽仿真度高,但执行真实命令引入极高的运维成本及攻陷风险。为提升欺骗性,业界探索了诸如伪造Banner、引入时延扰动等简单动态手段,但本质仍未突破静态或半静态脚本限制。
近期,随着LLM模型普及,研究者开始尝试将其引入蜜罐,拓展系统智能与实感。例如,Otal与Canbaz(2024)提出基于LLM模型微调的交互式蜜罐,通过传统蜜罐日志命令-响应对进行定向训练,实现更真实的交互仿真。上述方案虽拓宽了蜜罐应答范围,却局限于单一模型和特定训练,对实际通用性、扩展性与性能并未系统量化。本文在此基础上实现关键突破:一方面,支持多类开源与商用LLM后端可替换接入,首次系统评估13款模型的输出表现;另一方面,提出基于字典的虚拟文件系统与命令状态追踪,有效解决了响应时延高、系统状态易“幻想”失真的痛点,这均为现有工作所未覆盖。综上,本文在提升蜜罐智能化动态交互及性能评测维度上,实现了理论与工程的系统创新。
LLMHoney系统设计
LLMHoney总体架构围绕五大模块展开,具体为:配置模块、网络监听模块、认证管理模块、会话与LLM引擎模块、日志存储模块。系统初始化时,通过解析配置文件载入SSH服务参数、密钥、账户密码、LLM后端类型及shell环境展示信息,实现灵活系统部署和多模型动态切换。网络监听采用AsyncSSH异步框架,实现SSH handshake、安全密钥协商及Banner/版本信息展示,多用户并发接入。
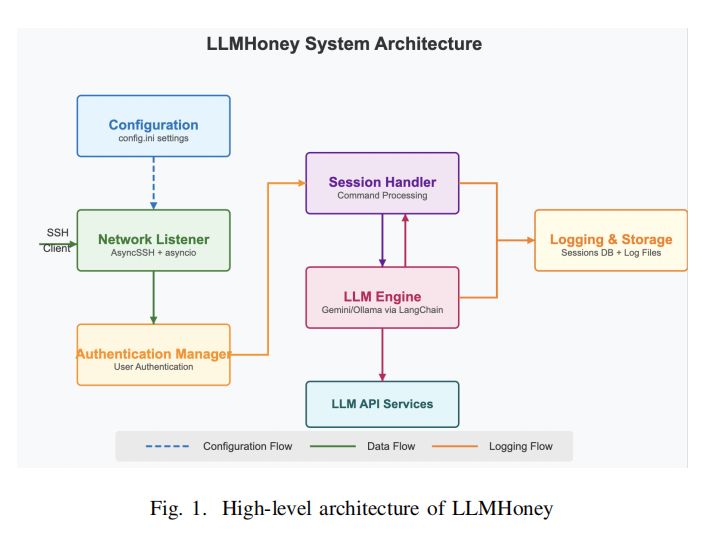
在认证环节,系统自定义SSH服务端逻辑,检查登录凭据是否合法,只有在配置内设定的账户密码组合下允许进入shell。成功登录后,会话控制切换至核心“命令应答”模块——每接收到一条shell命令,优先检索本地字典缓存(涵盖uname、ls、cat等常见类Unix操作),如命中即返回标准输出并记录;如遇未涵盖命令,则通过LangChain桥接选定LLM(如Gemini、Ollama下的多款开源模型),将命令及当前虚拟系统状态集成到LLM prompt中,请求上下文相关输出,再返回给攻击者。此设计显著提升了常规操作的高性能仿真,同时保证对未知/非常规输入具备智能、灵活的仿真能力。
为保证多命令交互过程中仿真一致性和状态持久性,系统设计了状态化虚拟文件系统与命令追踪机制,所有文件创建、删除、读写及目录变化均实时记录并作用于后续会话,防止LLM“忘记”历史操作、出现逻辑冲突。日志与交互细节则完整落盘,含时间戳、连接信息、命令序列、应答内容等,便于后续行为分析及蜜罐效果评估。整个系统不执行真实命令,完全在用户态仿真,保证了安全隔离与可管控性。
实验方法
实验测试环境基于macOS主机(Apple M2,10核CPU,8GB内存),围绕Python 3.10环境、AsyncSSH结构独立部署。数据集人工整理了138条覆盖文件操作、系统管理、网络、包管理、通用工具类Linux命令,并记录标准真值输出,形成权威命令-响应评测对。LLMHoney支持包括Gemini、Ollama平台下Gemma、LLaMA3.2、Qwen2.5、SMoLLM2、Granite、CodeGemma、DeepSeek、StableLM、Falcon、Phi3等13种模型,参数量涵盖0.36B至3.8B,兼具开源和商用代表性。
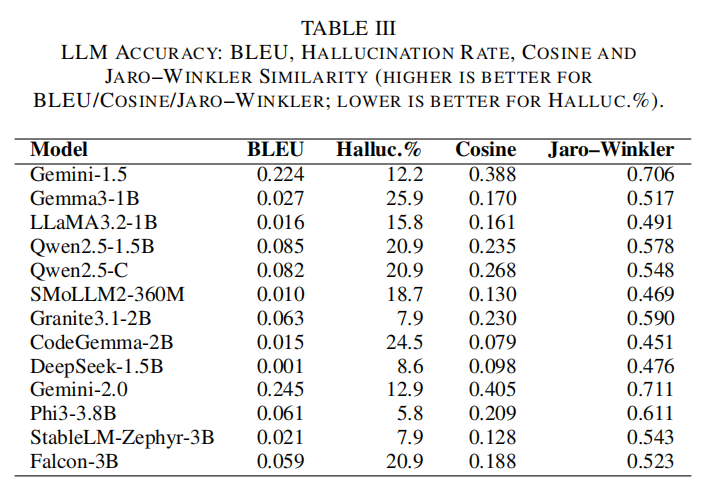
测评流程方面,自动加载所有命令逐一遍历,按模型逐条执行,精准计量每次应答的响应延迟(wall-clock)、内存消耗(以psutil和操作系统API)、以及输出内容与标准真值的多重相似度/准确率指标(Exact Match、Cosine Similarity、Jaro-Winkler、Levenshtein、BLEU分数等)。自动化脚本保证全过程可追溯和数据收集,所有输出被归档并生成可视化对比(热力图、箱线图、雷达图等),详细揭示不同模型在仿真质量与性能上的全面表现。
结果分析
实验结果显示,各类LLM在蜜罐shell响应生成场景下存在显著性能分层。规模较小的模型如Gemma3-1B虽响应极快(0.49秒/条),但生成内容准确率/语义相关度极低,易出现“幻想”或违背shell语境的回答,无法为高仿真蜜罐提供支撑。对比之下,商用Gemini-2.0与高参数量的Phi3-3.8B、Qwen2.5-1.5B等,则在生成内容的语义相似度(Cosine、Jaro-Winkler)及BLEU分数等衡量上均表现优异,低误差、低幻想率,且三秒左右的平均响应延迟在用户交互层面基本可接受。尤其Gemini-2.0在多重指标取得最佳,BLEU达0.245、Cosine为0.405、Jaro-Winkler为0.711,幻想率仅12.9%,Phi3-3.8B则以5.8%的幻想率达到最低,展示大模型在高交互蜜罐仿真中的天然优势。
在性能消耗方面,除极大模型如StableLM-Zephyr-3B内存开销达到17MB/条外,主流模型普遍在1-2MB水平,对资源有限场景具有一定兼容性。实验进一步揭示,“字典缓存+状态跟踪+LLM”的混合体系能确保常规命令仿真“即刻”响应且完全一致,极大提升仿真稳定性。与传统Cowrie蜜罐相比,LLMHoney能够对任意输入灵活覆写,极大扩展可诱骗的命令空间与攻击场景,提升攻击者驻留时间与数据丰富度。
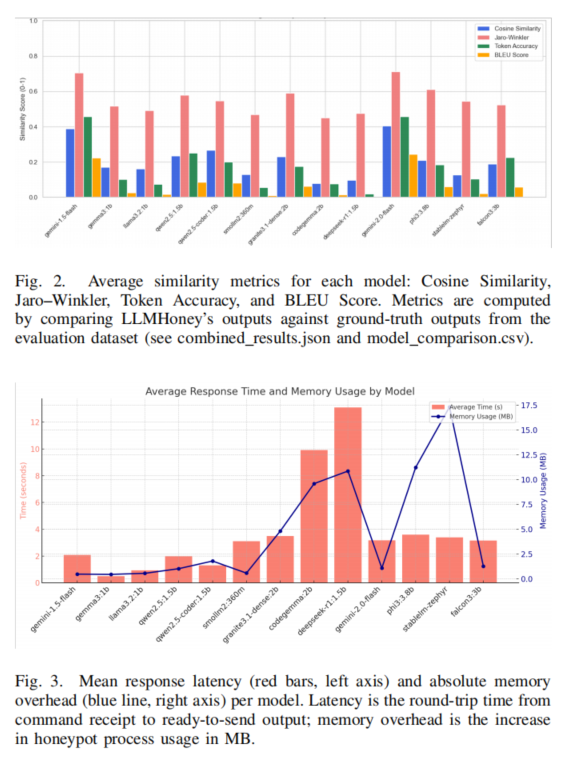
然而,LLM引入也暴露诸多实际限制。首先,系统计算负荷显著高于脚本型蜜罐,5-20倍的资源需求限制了并发与大规模部署能力;其次,输出准确性依赖于模型能力,并非所有命令都能完美仿真,幻想/不符内容偶现,对高水平攻击者间谍可能成为识破切口。此外,系统实际测试采用138命令的实验室环境,未能完全反映复杂威胁形态,对抗真实攻击需进一步实地部署验证。安全方面,尽管LLM受prompt控制未泄露自身属性,但防止“提示注入”与LLM机制外泄仍须持续关注和测试。对比相关如微调LLM蜜罐方案,本文采用即插即用式预训练模型切换,在便捷性与通用性上具突出优势,为后续“定制化”与“泛用化”动态结合提供技术支撑。
论文结论
本文全面提出并系统实现了LLMHoney,开创性地采用大语言模型驱动高交互SSH蜜罐命令仿真,通过混合虚拟文件系统与状态一致性跟踪,构建了兼顾仿真真实感和性能平衡的高智能蜜罐架构。多模型对比实验证实,1.5B~3.8B参数量级LLM(如Gemini-2.0、Phi3)在输出准确率、幻想率及延迟等综合指标下均具可用性,为智能蜜罐技术新演进提供理论与实证基石。尽管存在较大算力消耗和高交互一致性保障压力,以及实验规模受限、真实威胁验证欠缺等不足,本文首次量化揭示了各类LLM在蜜罐场景下的适用边界,并为模型选型和未来部署提出了系统参考。未来工作可聚焦广义场景下对抗真实攻击序列、支持更持久态管理与自动化错误检测机制,扩展虚拟文件系统的内容丰富度并研发更复杂的攻击误导策略。LLMHoney的提出标志着蜜罐从静态、规则化向自主、智能化的跃进,为网络自适应防护、攻防对抗和威胁情报捕捉树立了全新技术范式。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
