基本信息
原文标题:A Systematic Study on Generating Web Vulnerability Proof-of-Concepts Using Large Language Models
原文作者:Mengyao Zhao, Kaixuan Li, Lyuye Zhang, Wenjing Dang, Chenggong Ding, Sen Chen, Zheli Liu
作者单位:天津大学智能与计算学部,南开大学网络空间安全学院,新加坡南洋理工大学计算与数据科学学院
关键词:Web应用安全、大语言模型(LLM)、漏洞利用、PoC自动生成、CVE基准、提示工程、上下文增强、实证评测
原文链接:https://arxiv.org/pdf/2510.10148
开源代码:暂无
论文要点
论文简介:本文系统性评估了大语言模型(LLMs)在Web应用程序漏洞PoC(Proof-of-Concept)生成任务中的能力及局限性。面向真实安全实践,作者围绕CVE公开流程的三个典型阶段(仅描述、补丁发布、源代码全公开),构建了100个可复现Web漏洞的高质量基准,全面测试了GPT-4o和DeepSeek-R1两类大型语言模型。
研究结果表明,LLMs仅凭公共可得的信息即可在8%至34%的CVE案例上自动产生有效PoC,其中DeepSeek-R1表现优于GPT-4o。进一步,通过补充函数级与文件级代码上下文,智能提示工程(如分步骤推理和实时反馈),可将最佳PoC自动生成成功率提升至68%—72%。研究揭示,LLMs不仅有望重塑漏洞利用与防御工作流、显著降低技术门槛,同时也引发了信息透明度与安全实践之间的新政策权衡。截至论文发表时,已有23个由LLM生成的新PoC被NVD与Exploit DB收录认证。
研究目的:当前Web漏洞PoC自动化生成领域,传统方法面临对特定代码依赖、专家模板难泛化、符号执行扩展性不足等瓶颈,导致公开CVE大多数缺失可复现实用PoC,重现依赖高强度人工逆向。与此同时,LLMs在代码理解与多模态文本整合上的强大能力,为自动利用公开阶段性信息生成PoC提供了新机遇。
本文旨在严密测试LLMs能否在现实CVEs不同公开阶段,利用描述、补丁、源码等可获取的多元信息自动生成高质量、真实可用的Web漏洞PoC,并剖析其失败根因、上下文与提示工程能否突破原生极限。通过实证分析,论文既聚焦安全攻防门槛变化、自动化安全运维新机会,又关注自动化利用扩散带来的监管与政策挑战,探讨技术演进下的信息披露最佳实践策略。
研究贡献:
1. 原创性评测框架:首次以全生命周期视角,系统性实证评估LLMs在CVE公开描述、补丁、完整代码三阶段下PoC自动生成能力,采用100个高可复现Web漏洞(涵盖5大主流类型、3000余次实验),覆盖多阶段、多输入、模块化实验流程。
2. 多阶段深度实验:设计四阶段评测方法,依次包括原始能力测试、分步骤故障分析、上下文补充增效、智能提示工程优化。实验共耗时逾600人时环境搭建、120人时人工验证,体现极高工程信度和实际意义。
3. 开放基准资源:构建并开放了包含丰富上下文、人工复现判定和完整实验数据的Web漏洞CVE基准,以及可复用、涵盖CoT链式推理、上下文注入与实时反馈的多样化LLM PoC生成提示集合,推动后续研究可复现和方法迭代。
4. 实证与理论启示:揭示LLM可直接由公开描述或部分上下文自动拼接出有效漏洞利用PoC,突破传统模板或符号执行瓶颈。通过上下文与推理增强,显著提升多种漏洞类型的利用成功率,为攻防技术、快速回归测试和漏洞响应提供新范式,同时对信息披露政策和生成式能力扩散提出政策新挑战。
引言
Web应用是现代数字服务的核心,但长期位于网络攻击的前沿。PHP等支撑后端的主流语言更是覆盖了超过七成网站。每年安全社区都会披露大量涉及XSS、SQL注入、CSRF、命令注入和文件上传等典型高危Web漏洞。对防御者而言,可复现且高效的PoC不仅是漏洞验证的基础,也是溯源分析、回归测试和运维补丁效果的必要抓手。然而,实证表明,近半公开CVE并无可用PoC,或提交的PoC第三方难以复现,安全团队需大量人工逆向重现攻防环境,造成巨大技术和人力鸿沟。
对漏洞自动化利用的研究,长期以来局限于零日检测与精细化模板,如符号执行、专家模板及语法规则推导等,虽然在专用代码下表现优秀,但缺乏通用性难以应对Web应用的多态和不断演化。此外,随着CVE等数据库公开透明度提升,丰富的描述、补丁diff、源码逐步曝光,极大拓宽了利用与防护双方的信息基础。理论上,LLMs能接收描述、补丁及源码等多模态信息,自动推理并产生可执行攻击样例。如果这种能力可以系统可靠地发挥,不仅能让防御者快速生成回归用例、流式响应新威胁,也可能大幅降低攻击门槛,在公开到补丁部署的关键窗口引发新的安全威胁。因此,如何定量而严谨地评估LLMs在真实Web漏洞场景下,利用不同阶段公开信息自动生成高效PoC的能力,并区分其上下文、推理和工程瓶颈,成为新的安全社区与政策监管研究前沿。
本论文从此出发,结合CVE披露实际工作流,聚焦描述初始、补丁发布及完整源码三大现实阶段,分别模拟最小可利用信息、中等定位能力和完全可见环境,围绕100个真实、可本地重现的Web漏洞组件,全面测试业界代表性的通用(GPT-4o)与推理型(DeepSeek-R1)LLM在PoC自动生成领域的原始水平、瓶颈成因、上下文提升潜力,以及智能提示/链式推理工程强化空间。研究结果为未来高质量漏洞披露、自动防御工具、生成式安全监管等提供了理论和数据双支撑,也为攻防双方的能力重塑与管理带来崭新视角。
相关背景与研究动机
Web漏洞自动利用(PoC生成)在安全社区具有举足轻重地位。PoC不仅直接帮助漏洞验证与复现,还能支撑补丁测试、自动化回归和威胁情报分析。典型的Web漏洞类型有XSS、SQL注入、CSRF、命令注入和任意文件上传等,这些漏洞往往涉及从用户输入到敏感操作(sink)的数据流、控制流和复杂语法约束,且攻击路线普遍受限于应用文件结构和动态访问入口。
传统的PoC自动生成依赖三大技术:
1)对漏洞代码完整可见,基于符号执行或路径遍历推导利用链,但面临Web应用框架重/动态性所致的状态空间爆炸与复杂控制流困境,难以大规模通用;
2)依赖人工定制攻击模板,泛化与应对新模式能力不足;
3)部分探索在补丁diff基础上追溯利用点,但仍缺乏对仅有漏洞描述或阶段性公开信息的高效解析。
与此同时,CVE等漏洞平台的信息披露日益细致,预披露期常见的简
与此同时,CVE等漏洞平台的信息披露日益细致,预披露期常见的简要描述、补丁发布期新老版本diff、中后期源代码再公开,为攻防双方提供更早、更细粒度的利用线索。这促使LLM基于多模态数据的能力成为新的突破点。当前顶级LLM如GPT-4o以多轮对话推理、代码生成见长,DownSeek-R1则强化了多步骤逐层推理能力。理论上,其有望像“自动化漏洞工程师”一般,随信息逐步丰富实时精进利用策略,突破传统方法的样本依赖与工程瓶颈。若这种自动化能力在实际条件下获得验证,将极大变革漏洞重现、补丁验证和应急响应流程,同时倒逼安全社区重审信息披露边界与监管机制。
因此,本文以“能否可靠、分阶段、自动利用真实公开信息生成可用PoC”为核心,设计了全面、高还原度的基准实验,系统分析LLM在过程各节点的原生与增强能力、失败原因与具体优化空间,为自动化与人力结合的漏洞生命周期管理、攻防对抗升级与合规披露政策制定提供基础理论和实证依据。
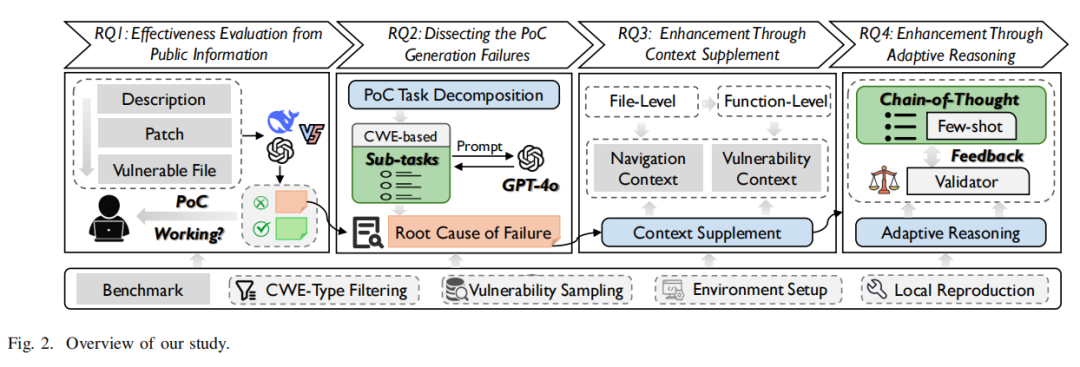
基准构建
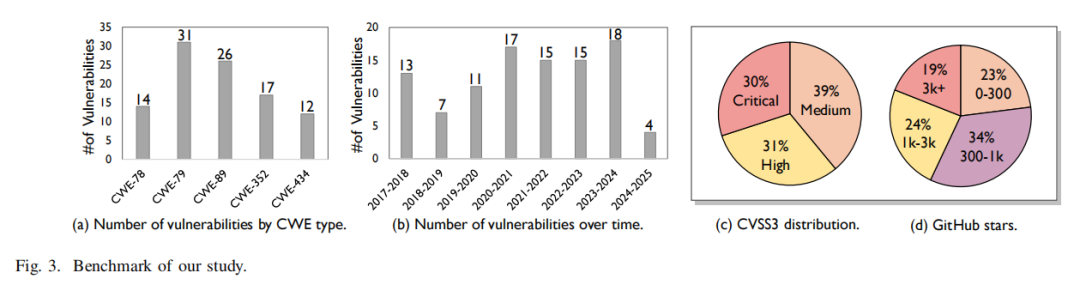
论文首先构建了高质量、可复现的Web漏洞基准。具体包括:1)通过系统性文献调研和CWE排名,筛选XSS(CWE-79)、SQL注入(CWE-89)、CSRF(CWE-352)、命令注入(CWE-78)和任意文件上传(CWE-434)五大主流高危漏洞类型;2)自2017-2024年间,抓取NVD平台全部相关CVE,并以CVSS3评分不低于4.0(中危以上)为准,优选高威胁性样本;3)采用多轮随机采样与人工复现,确保每一个基准漏洞可在局部实验环境中通过标准化操作稳定重现,以剔除模型能力评测之外的环境噪音。最终,得到涵盖不同时间、类型、危害等级,且实现可追溯全流程复现的100个高代表性Web漏洞样本集。
要描述、补丁发布期新老版本diff、中后期源代码再公开,为攻防双方提供更早、更细粒度的利用线索。这促使LLM基于多模态数据的能力成为新的突破点。当前顶级LLM如GPT-4o以多轮对话推理、代码生成见长,DownSeek-R1则强化了多步骤逐层推理能力。理论上,其有望像“自动化漏洞工程师”一般,随信息逐步丰富实时精进利用策略,突破传统方法的样本依赖与工程瓶颈。若这种自动化能力在实际条件下获得验证,将极大变革漏洞重现、补丁验证和应急响应流程,同时倒逼安全社区重审信息披露边界与监管机制。因此,本文以“能否可靠、分阶段、自动利用真实公开信息生成可用PoC”为核心,设计了全面、高还原度的基准实验,系统分析LLM在过程各节点的原生与增强能力、失败原因与具体优化空间,为自动化与人力结合的漏洞生命周期管理、攻防对抗升级与合规披露政策制定提供基础理论和实证依据。基准构建
论文首先构建了高质量、可复现的Web漏洞基准。具体包括:1)通过系统性文献调研和CWE排名,筛选XSS(CWE-79)、SQL注入(CWE-89)、CSRF(CWE-352)、命令注入(CWE-78)和任意文件上传(CWE-434)五大主流高危漏洞类型;2)自2017-2024年间,抓取NVD平台全部相关CVE,并以CVSS3评分不低于4.0(中危以上)为准,优选高威胁性样本;3)采用多轮随机采样与人工复现,确保每一个基准漏洞可在局部实验环境中通过标准化操作稳定重现,以剔除模型能力评测之外的环境噪音。最终,得到涵盖不同时间、类型、危害等级,且实现可追溯全流程复现的100个高代表性Web漏洞样本集。
在实验设计上,论文全流程模拟真实漏洞公开及利用场景,将每个CVE依次放置于三大阶段并输入LLM:1)S1-仅描述,考查模型对公开语义的推理与还原能力;2)S2-描述+补丁,评估对细粒度差异与漏洞定位的敏感度;3)S3-描述+补丁+完整源码,模拟全公开后最大可用信息量。为保证结果可靠性,每个样本在相同提示下独立生成三次,只有全部成功才能计入真有效率,温度参数固定为0以排除随机性影响。
评测方面,不仅统计模型PoC自动生成的成功率,还详细分析输出格式多样性、攻击Payload深度泛化、不同漏洞类型的差异表现。为剖析模型失败的根本原因,进一步将任务细分为攻击向量构造、导航路径生成、最终请求合成等14步模块化子任务,并导出每步中间结果以定位能力短板。此外,论文系统引入文件级与函数级手动上下文补全实验,以及分步骤链式推理、上下文注入、实时反馈等先进提示工程策略,全面评测上下文补充与推理机制对LLM能力释放的作用机制。
实验结果分析
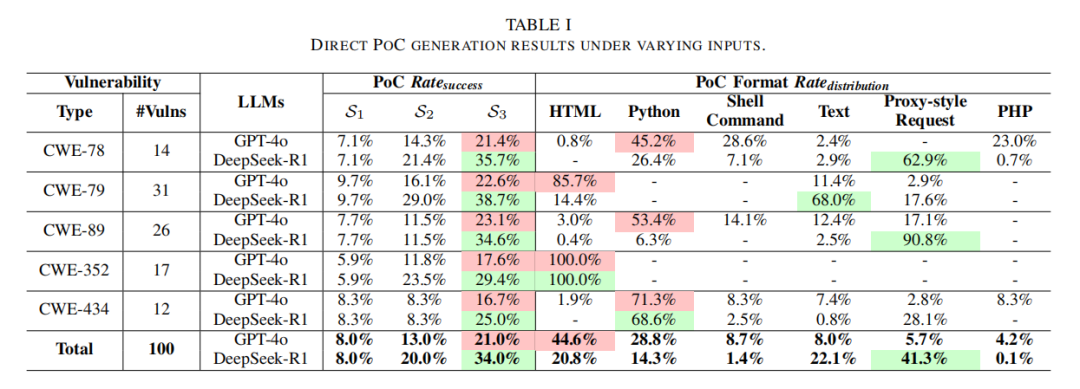
实验发现,LLMs在仅提供描述、补丁等急速初公开阶段,即可在8%(S1)—34%(S3)样本上合成真实可用PoC,部分案例甚至被NVD与Exploit DB认证收录(共23个),首次量化证实公开信息存在直接安全利用风险。具体来看,DeepSeek-R1在所有阶段均显著优于GPT-4o,反映多步骤推理优化对复杂任务的助益。模型在补丁+文件级源码(S3)下能发挥最高潜力,说明完整上下文对漏洞理解不可或缺。
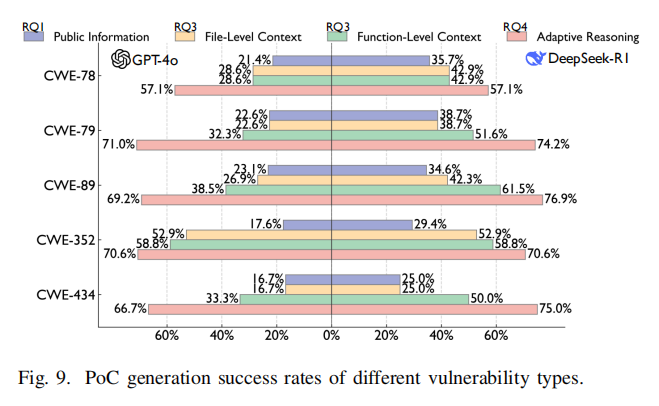
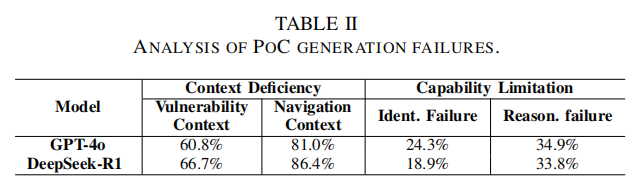
分类型分析表明,两类模型对污点传递型漏洞(如XSS、SQL注入、命令注入)更敏感,得益于其在预训练阶段对常见利用模式积累较多知识积淀。而对于CSRF、文件上传等依赖前端交互和复杂数据流的逻辑型漏洞,原生能力明显受限。通过分步骤故障定位,发现86.4%以上失败源于上下文缺失(如无法感知文件层级/入口、临界变量控制流等),即便信息完整后,推理能力本身也非百分百无缺(如复杂多函数链、多层语法嵌套场景下table-up-to-34%-of-DeepSeekR1-and-expertise-navigate-file-content),GPT-4o的原生推理准确率仅为65.1%。
补全文件级和函数级上下文后,模型PoC生成成功率大幅提升(函数级最高提升至54%/38%),验证了深入补全带来的输入鲁棒性优势。进一步将链式推理(Chain-of-Thought)、少样本示例(ICL)、实时反馈校正机制融入,DeepSeek-R1最终可达72%,GPT-4o提升至68%,基本缩小两者效率差距,充分释放了大模型工程潜能。
细致分析还发现LLM在攻击Payload合成、多步导航与请求组装环节展现出丰富的自动演化能力,有效规避了传统专家模板和符号执行的局限。但依旧存在生成模式偏好性(如GPT-4o偏向直接可运行代码,DeepSeek-R1倾向结构化交互),以及对长链路径与动态复杂路由的推理短板。此外,实验还量化了工程成本,DeepSeek-R1用时较长但费用更低,对大规模自动利用测试更为友好。
局限性
论文在讨论与局限分析中高度坦诚地指出:首先,实验只覆盖了最常见的五大CWE类型Web漏洞,未来亟需拓展至更加多样化、逻辑复杂的新型漏洞类别,并完善分步骤推理与提示工程的泛化适配能力。其次,输入信息的丰富性与选择性对PoC生成效果有直接影响。虽然上下文补全普遍正向提升生成成功率,但过度或无关上下文亦可能引入噪音,如何高效筛选关联内容、构建可复用知识库仍需深入研究。
再次,PoC自动合成的推理环节在多函数、多路径、数据转化链长场景展示出明显瓶颈,LLMs原生概率推理不具备程序精准执行、变量追踪等硬技能,提示未来需结合静态/动态分析、符号执行等刚性工具辅助推理水平提升。同时,PoC生成验证环节仍需依赖部分专家人工判定与反馈,完全端到端的自动化验证与迭代机制仍是开放命题。
针对数据安全与实验外部性,论文也进行了细致控制与验证,规避了数据泄露影响、基准集复现偏差和分步骤任务划分不一致风险。未来工作将聚焦知识增强集成、多层推理模型融合、自动化反馈闭环、跨语言/跨平台泛化,以及面向攻防对抗与安全政策的生成式模型行为管控。
论文结论
本文为大语言模型在Web漏洞自动利用任务中的工程化落地提供了首个大规模、富有实证意义的阶段性测评与深度机理剖析。通过100例高风险可复现CVE在不同公开阶段的多层输入、多模型评测,作者发现:LLMs已具备直接由公开描述及相关上下文生成有效PoC的基础能力,并能借助上下文补全、提示工程和链式反馈显著提升复杂场景下的利用成功率,最高可达68%-72%,在部分类型和样本上已展现出超越传统符号/模板方法的迁移与泛化潜力。
研究不仅为安全自动化工具、漏洞发现与响应带来变革性契机,也揭示出安全政策和信息披露实践下的大模型能力外溢风险,亟需从攻防对抗、风险监管与政策规范角度反思透明度与可利用性的平衡。真实PoC的广泛通过和平台认可,凸显LLMs在漏洞工程系统中的未来关键地位。后续研究有望围绕知识增强、多模态推理、人-机协同和自动化反馈验证等方向深拓,为新一代智能安全体系构建夯实理论和实践基础。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
