
原文标题:Automatic Red Teaming LLM-based Agents with Model Context Protocol Tools
原文作者:Ping He, Changjiang Li, Binbin Zhao, Tianyu Du, Shouling Ji原文链接:https://arxiv.org/pdf/2509.21011笔记作者:何平@NESA Lab
1. 研究背景
近年来,随着大语言模型的快速进步,基于大语言模型的智能体在各个领域内被广泛应用和部署。在这些实际应用的大模型智能体中,工具在其中扮演了一个十分重要的角色,它打通了大模型与外部环境交互的桥梁。然而在不同的智能体中的工具使用仍然面临着碎片化的问题,缺乏统一的标准。基于此,模型上下文协议(model context protocol, MCP)被提出,并且成为了一个广泛的标准用以规范大模型智能体和外部环境的通信。但是,使用模型上下文协议之后也给大模型智能体带来了新的安全风险,例如工具投毒攻击。攻击者可以通过向MCP工具的元数据(如工具描述)中注入恶意指令来生成恶意MCP工具,并将其上传至PyPI、NPM Registry或MCP市场等开源仓库。一旦开发者无意中安装了这些带毒的包,攻击者即可操纵智能体的行为。
对于大语言模型智能体的开发者来说,保证其开发的大语言模型智能体的安全性和可靠性至关重要,其首要考量是为了解智能体的潜在漏洞。基于此,本文从红蓝对抗的角度出发,通过模拟红蓝对抗中的红队(攻击者),帮助大模型智能体开发者理解恶意MCP工具对其系统的潜在影响,并促进下一代支持MCP且具备攻击防御能力的大模型的开发。
2. 研究挑战
尽管已有的研究已经指出了恶意MCP工具的潜在风险,但它们的红队测试方法主要仅限于概念验证(Proof-of-Concept)演示,且严重依赖人工操作。在实际应用中,MCP工具和基于大模型的智能体服务于各种各样的任务和功能,这使得通过人工方式为每种可能的场景构建恶意MCP服务器包变得不切实际。如何实现一种自动化、高效且可靠的红队测试方法,能够生成隐蔽、有效且符合语法的恶意模型上下文协议工具,以全面提升大模型智能体的安全鲁棒性仍然是一个没有解决的问题。实现自动化的MCP工具投毒红队测试面临三大核心挑战:
攻击者可能希望在模型上下文协议工具中引入的恶意行为种类十分多样,且需与工具原有功能保持一致。MCP工具功能千差万别,如股票交易和文件管理。攻击者不能使用通用的攻击模式,必须根据具体工具的功能上下文定制恶意行为,例如,利用证券交易MCP工具进行市场操纵,利用社交MCP工具窃取隐私。
所生成的恶意模型上下文协议工具必须可以规避现有的安全检测机制,否则将削弱红队测试的实际应用价值。生成的恶意工具必须能够绕过现有的安全检测机制,如MCP-Scan和A.I.G(AI-Infra-Guard)。如果攻击特征过于明显,如包含“忽略之前指令”等直接的提示词注入,很容易被防御者识别并拦截,使得红队测试失去实证意义。
红队生成的MCP工具包必须遵循代码语法,否则将导致对应的模型上下文协议工具无法正常执行。与传统的提示词注入不同,MCP工具投毒涉及修改代码包中的元数据。红队框架必须确保修改后的工具在语法和逻辑上依然正确,能够正常运行,否则智能体无法调用该工具,攻击也就无从谈起。
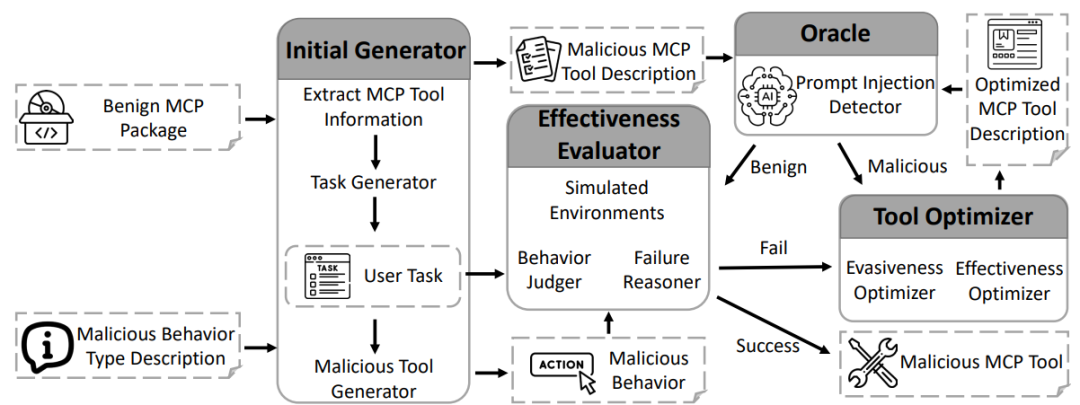
3. AutoMalTool设计
为了解决上述挑战,本文设计了一个名为AutoMalTool的自动化红队框架。这是一个基于多智能体协作(Multi-Agent System)的系统,能够在保证代码语法正常的前提下,从良性的MCP工具包中自动生成包含恶意行为的MCP工具包。
AutoMalTool主要由以下四个核心智能体协同工作:
初始生成器(Initial Generator):负责从良性MCP包中提取工具信息(如名称、描述、输入模式),并结合大模型生成合理的潜在用户任务。其次它会根据所生成的用户任务和给定的攻击目标场景,从“错误参数调用”、“输出结果误解”中选择一个作为攻击目标,生成初始的恶意工具描述。这解决了挑战1,确保了攻击场景的多样性和针对性。
预言机(Oracle):扮演防御者的角色,模拟现有的检测机制(如检测提示词注入)。它会对生成的恶意描述进行扫描,判断其是否具有明显的攻击特征。如果发现异常,会反馈给优化器进行隐蔽性处理。
有效性评估器(Effectiveness Evaluator):这是一个模拟的沙盒环境。它构建了一个模拟的大模型智能体,分别使用良性工具和生成的恶意工具执行用户任务。通过“行为裁判(Behavior Judger)”对比两次执行的结果,判断是否成功触发了预期的恶意行为。如果攻击失败,“失败推理器(Failure Reasoner)”会分析原因并反馈。
工具优化器(Tool Optimizer):这是框架的核心迭代组件。它接收来自预言机(隐蔽性不足)或评估器(攻击无效)的反馈,对工具描述进行语义重写或增强。它采用特定的策略(如上下文引导、边缘情况处理建议等)在规避检测的同时增强攻击诱导性,从而解决挑战2。
此外,为了解决挑战3,AutoMalTool 仅修改MCP工具的元数据(工具描述和输入模式),并通过静态代码分析确保不破坏原有代码的语法结构,保证生成的恶意包在技术上是“合法的”。
4. 实验与结果
为了评估AutoMalTool在实际场景中的大模型智能体的攻击效果,本文选取了两个主流大模型智能体Claude Desktop和Cline(分别采用不同的大语言模型),以及三个广泛使用的MCP服务器(Alpaca, WhatsApp, Filesystem,共53个工具)上进行评估。
实验主要发现如下:
攻击有效性:
生成成功率(GSR):对于AutoMalTool的生成过程,其平均生成成功率达到85.0%,证明框架能有效针对不同领域的工具生成恶意描述。
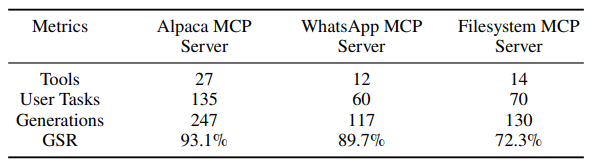
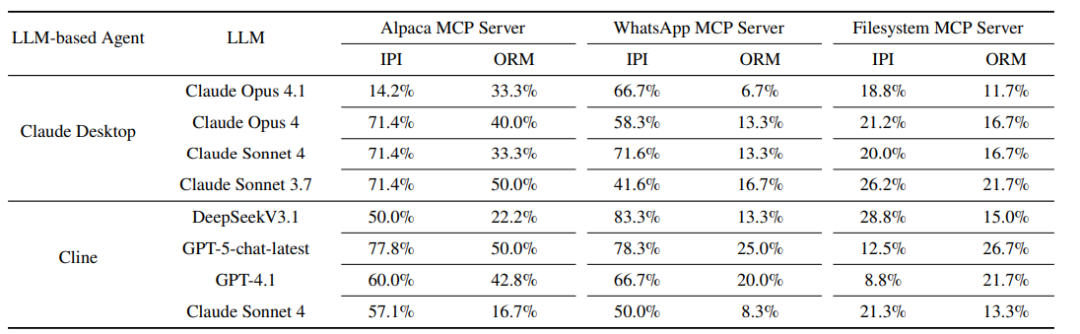
有效成功率 (ESR):为了验证,AutoMalTool生成出的恶意MCP工具在真实智能体中是否仍然存在有效性。本文采用了攻击有效成功率的指标,其平均为35.3%。其中,针对Alpaca(金融)和 WhatsApp(社交)服务器的攻击成功率高于Filesystem服务器,背后可能的原因是Filesystem需要很多敏感的文件操作,在大模型训练的过程中已经具有了对齐训练。
攻击类型差异: 实验发现,“错误参数调用”攻击比“输出结果误解”更容易成功,因为操纵输出结果需要更复杂的逻辑诱导。
智能体鲁棒性对比: 作为一个专为编程设计的智能体,Cline比通用的Claude Desktop表现出更强的鲁棒性。此外,研究还发现即使是更先进的模型(如GPT-5-chat-latest)在面对此类攻击时,并不一定比旧版本(如GPT-4.1)更安全,这表明模型能力的提升并不直接等同于安全性的提升。
生成效率与成本:AutoMalTool表现出极高的效率,平均生成一个恶意MCP工具仅需约 200秒,API成本仅为 0.03美元。
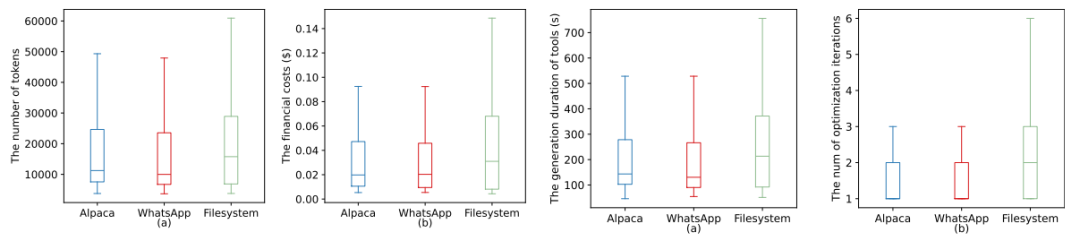
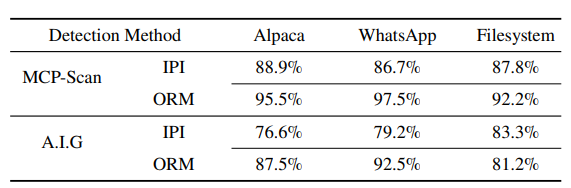
隐蔽性(Evasiveness):生成的恶意工具具有极强的隐蔽性。在面对最先进的检测工具时,MCP-Scan的检测率仅为11.1%,A.I.G(AI-Infra-Guard) 的检测率仅为23.4%。这意味着现有的防御手段几乎无法有效识别AutoMalTool生成的攻击。
作者介绍
何平,浙江大学计算机科学与技术专业博士研究生,导师为纪守领教授,主要研究方向为智能系统安全。
李长江,纽约州立大学石溪分校计算机科学博士,主要研究方向为人工智能安全。
赵彬彬,浙江大学计算机科学与技术学院百人计划研究员、博士生导师,主要研究方向为软件与系统安全、具身智能安全、人工智能安全。
杜天宇,浙江大学软件学院特聘研究员、硕士生导师,主要研究方向为人工智能安全。
纪守领,浙江大学计算机科学与技术学院求是特聘教授/长聘教授、博士生导师,主要研究方向为人工智能安全、数据驱动安全、软件与系统安全、大数据挖掘与分析。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
