基本信息
原文标题:VULPO: Context-Aware Vulnerability Detection via On-Policy LLM Optimization
原文作者:Youpeng Li, Fuxun Yu, Xinda Wang
作者单位:University of Texas at Dallas(Youpeng Li, Xinda Wang),Microsoft(Fuxun Yu)
关键词:大语言模型、强化学习、上下文感知、漏洞检测、ContextVul、政策优化、奖励函数、深度学习
原文链接:https://arxiv.org/pdf/2511.11896
开源代码:暂无
论文要点
论文简介:本文聚焦于提升大语言模型(LLM)在真实软件项目中漏洞检测(Vulnerability Detection, VD)的能力。传统VD方法和当前主流LLM范式(如prompt工程、监督微调、off-policy RL)虽取得一定进展,但由于缺乏对代码上下文的全面建模,难以实现具备上下文感知能力的漏洞检测,即无法准确捕捉跨文件、跨函数以及全局程序状态相关的漏洞特征。文章提出了一种新颖的政策优化框架——VULPO(Vulnerability-Adaptive Policy Optimization),这是首个专为上下文感知漏洞检测设计的基于on-policy RL的LLM优化方法。
为支撑该方法,作者首先构建了ContextVul数据集,通过轻量级流程为函数级代码补充了仓库级的上下文信息。在此基础上,VULPO提出了多维度奖励结构、难度自适应奖励缩放以及LLM裁判机制,显著增强了模型的上下文推理和泛化能力。大量实验结果表明,VULPO在各主要评测指标(如F1、召回率等)上均大幅超越了基线方法,且达到与百倍参数量大模型媲美的效果。这一工作填补了上下文感知VD领域的重要技术空白,为自动化漏洞检测的实用化落地奠定了坚实基础。
研究目的:本研究旨在解决当前学习型漏洞检测系统在上下文语境理解和分析方面的重大瓶颈。多数现有模型受限于静态输入、固定偏好的数据集或功能级标注,无法动态地挖掘和利用跨文件、跨函数、全局变量等仓库级上下文信息。这限制了模型对现实世界中高度依赖上下文的复杂漏洞的检测能力,导致高漏报和误报。作者提出的核心科学问题包括:如何高效构建具备丰富仓库级上下文的数据集?如何设计多维度奖励函数和自适应奖励缩放,实现强化学习在漏洞检测中的有效引导?以及如何通过on-policy RL优化,使LLM具备类人上下文推理能力并适应实际软件工程场景。
研究贡献:
构建了ContextVul,这是一个面向C/C++的、丰富上下文信息的全新漏洞检测数据集,显著提升了上下文级VD研究的实验基础。
提出两阶段政策优化框架:通过SFT(supervised fine-tuning)冷启动,继以VULPO为核心的on-policy RL阶段,显著提升模型能力。
首创性地引入多维奖励机制,覆盖预测正确性、漏洞定位精度和上下文推理的语义相关性,并辅以结构一致性校验,推动模型产生连贯和可解释的分析结果。
提出标签级和样本级的难度自适应奖励缩放,大幅缓解强化学习训练中的奖励劫持问题,促使模型重点关注挑战性强的漏洞案例。
实现VULPO系统原型,并承诺后续开源代码,便于学界和业界复现和扩展。
引言
在当今软件工程实践中,复杂漏洞往往并非孤立地出现在某一函数内部,而是源于跨文件、跨模块、跨调用链等多层次的代码交互。具备经验的安全分析师往往会结合代码的全局变量、调用关系、验证逻辑和数据流,进行全景式的推理判断,以决定漏洞能否真正被触发或早已通过外部防护被消除。但现有学习型漏洞检测系统多因结构选型、范式机制及数据集限制,难以还原和利用这类人类式的上下文推理。
早期基于机器学习的VD方法普遍依赖人工特征和简化的程序表示,天生无法容纳程序仓库级语义和函数间依赖,断裂的上下文整合严重削弱了对漏洞本质的建模。随后流行的深度学习模型虽然一定程度上改善了特征学习,但受限于模型容量、预训练语料覆盖及输入窗口长度等,依然难以俯瞰复杂软件系统中的漫长依赖和组件联动。
大语言模型(LLM)的出现极大提升了代码理解和生成的能力,但当前主流LLM增强VD方法仍囿于函数级输入,本质受限于以下三类范式:
一是prompt工程及链式推理在没有目的性训练时难以动态甄别关键信息,模型易出现主观臆断、错漏变量、忽视外部验证逻辑、缺乏上下文归纳的现象;
二是监督微调范式因缺少高质量上下文级标注,模型仅停留于模仿而非类比推理,极易过拟合以及遗忘原有能力;
三是off-policy RL方法处理偏好优化时只依赖静态数据,无法主动探索丰富语义空间,从而只能记忆而非内生推理上下文关系。
最新的on-policy RL突破则为上下文感知漏洞检测带来了可能:模型可以实时与“环境”交互、动态分析并接收多维奖励反馈,实现自适应推理能力的迭代提升。然而,要将on-policy RL真正用于上下文级VD还面临两大难题:一是缺乏支持仓库级上下文的大规模高质量数据集,二是奖励机制设计粗糙、无法细致引导模型关注推理过程本身。本文以此为切入,通过高效的数据集扩充策略、丰富的奖励建模和奖励缩放设计,提出了VULPO方法,实证验证了RL赋能下LLM在检测复杂现实漏洞中的显著突破。
相关工作
当前基于LLM的漏洞检测研究以实现自动化、可迁移和高准确性的安全分析为核心目标,形成了以prompt工程和模型范式优化为代表的两大技术流派。第一类方法通过定制推理指导信息(如手工设计的指令、链式结构提示等),试图重现安全专家的思维分析过程,或者从代码结构和语义层面,为大语言模型提供辅助信息以便发现潜在漏洞。但prompt工程的性能高度依赖于基础模型的先验知识和推理深度,且缺乏对真实语境中跨文件依赖和复杂关系的动态挖掘能力。
第二类方法则尝试通过有监督微调、模型蒸馏、off-policy RL等优化范式提升模型性能。例如,通过教师模型输出收集高质量推理样本,以SFT或DPO等优化算法传递强模型的能力值给学生模型。然而,这一类方法仍然存在对有限模板的严重依赖,实际推理能力和泛化性受限,尤其在面对现实场景的高复杂度和数据分布变化时,容易出现过拟合和能力退化。同时,常用的off-policy范式限制了模型对自身决策结果的反馈调整能力,缺乏“探索-反馈-调整”的闭环机制。
相较之下,on-policy优化理论上允许政策网络与环境实时交互,动态修正推理路径、主动挖掘潜在的环境特征,极大拓展了模型的推理边界。尽管部分研究已探索将on-policy RL应用于代码推理,但针对漏洞检测任务普遍采用极其简单的奖励函数,如仅对最终判断对错打分,导致模型出现“答对但推理过程严重缺陷”或偏好片面模式的reward hacking问题。此外,当前数据集多以函数级切片为主,仓库级上下文严重缺失,使得模型无法获知外部依赖、调度与防御机制,极大制约了上下文VD的研究进展。
基于上述系统性瓶颈,本文的研究动机在于:1)解决数据层面的上下文极度稀缺,2)丰富奖励设计缓解模型训练与泛化中的结构性障碍,3)以RL范式赋能大模型具备类人上下文推理与自我优化能力,最终推动漏洞检测方法朝着更贴合工程实际和安全专家认知的方向发展。
系统设计
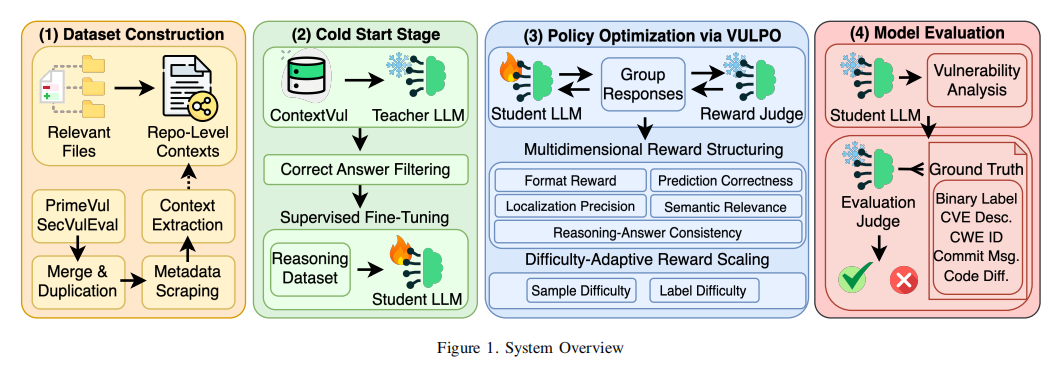
VULPO采用了精心设计的两阶段政策优化体系,以充分发挥大语言模型在复杂漏洞检测任务中的上下文理解和推理能力。完整体系由四大组件紧密耦合:1)上下文感知数据集构建,2)冷启动监督微调,3)VULPO主导的on-policy RL训练,4)多维裁判机制评估。
首先,在数据集建设层面,作者基于现有高质量函数级VD数据集(PrimeVul和SecVulEval),通过代码属性图(Code Property Graph, CPG)自动扩展,极大丰富了每个样本的跨文件、跨调用链和全局状态上下文。为降低构建成本,采用轻量级的局部代码依赖提取方法,结合项目仓库的commit信息、变更diff、CVE标签等元数据,保证涵盖真实项目特征、消除噪声数据及评测偏倚。
第二步,在冷启动阶段,VULPO利用强大的教师模型(如DeepSeek-R1-0528),通过给定目标代码和其上下文,让教师模型生成结合上下文的推理过程与结果(链式推理文本+最终判断)。同时引入LLM-Judge裁判机制对教师输出进行质量把关,确保学生模型不会“学到”包含错误事实或不一致推理的数据。经过一轮高质量SFT,模型掌握基础推理范式,显著提高后续RL阶段的采样效率。
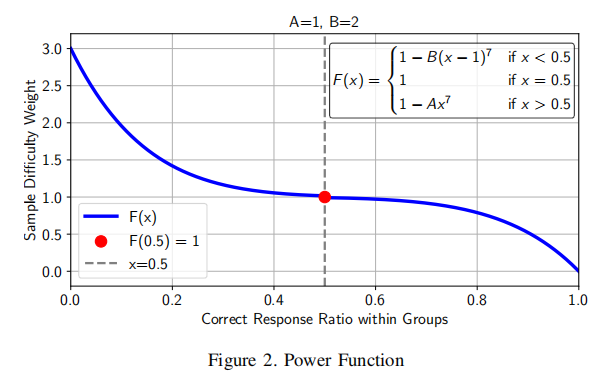
主创新体现在第三阶段的on-policy RL训练。VULPO提出基于GRPO(Group Relative Policy Optimization)框架的定制化优化目标,将模型多路输出通过LLM-Judge裁判沿多维度(格式约束、预测对错、漏洞定位、语义相关性、推理一致性)进行细致评估。奖励机制采用分维加权结构,特别强调对难度较高样本(如稀有类型、跨文件流程)和正类样本(真漏洞)的奖励拉升,有效避免模型偏向侥幸猜测或机械记忆。为防止reward hacking,标签级难度权重确保漏洞样本(正样本)更难被判定正确,样本级难度权重则随模型在当前训练步采样正确率动态调整,实现对复杂case的放大奖励、有效引导模型聚焦难例学习。
最后,VULPO在裁判和评测层面采用LLM-Based Judge机制,由外部LLM参照commit diff、CVE描述等输出鲁棒、细颗粒度的多维评分,确保模型能够获得“过程-结果”全量反馈和能力归因。这套体系大大提升了模型在面对跨场景、复杂项目背景下的鲁棒性和推理可信度。整个方法流程采用开源框架(如HuggingFace TRL、vLLM等)实现,并针对模型参数量、显存配置进行了细致优化,最大程度支持了大规模样本和丰富上下文的训练需求。
数据集与实验设置
为科学评估VULPO方法,作者建设了ContextVul上下文感知漏洞检测数据集。该数据集以C/C++主流开源项目的真实commit为基础,经严格数据清洗和聚合,每个样本均包含函数级代码、仓库级上下文(包括调用函数、头文件、宏定义、全局变量等)、CVE描述、commit diff、补丁信息等全局元数据。数据集最终划分为训练集15760条、验证集1970条、测试集1970条,分割基于commit发布时间(时间顺序分布),有效防止数据泄漏。
推理大模型选用Qwen3家族作为主干,基于Qwen3-4B实现VULPO主实验,深度对比DeepSeek、OpenAI、以及Qwen大家族不同参数量模型。优化对比基线涵盖prompt工程、SFT、代表性off-policy RL(如R2VUL、ReVD)、on-policy RL(如MARCO),并严格采用相同模型结构配置,保证评测公平性。主要评测指标包括pass@1、pass@8、major@8(反映推理准确性及分布);召回率、精确率、F1、MCC等标准分类指标。此外,为评估泛化能力,还主动收集2025年后新发布的31对C/C++真实漏洞补丁样本作为OOD任务测试数据。
训练实现采用Hugging Face TRL、vLLM和DeepSpeed等主流深度学习框架。在SFT阶段采用学习率1e-5、batch size 32、3轮;RL阶段学习率1e-6、batch size 16(每样本生成8组响应),梯度累积等也根据显存调整设置。奖励判定裁判采用GPT-4.1-mini模型。在输入长度上,最大支持代码及上下文32768 token,确保绝大多数项目上下文能够完整输入模型。
实验结果与分析
大规模实验验证了VULPO在上下文感知漏洞检测中的显著性能提升。与当前业界和学术界主流方法的全面对比显示,VULPO基于Qwen3-4B的实现相较于基础模型和传统SFT,F1指标提升近85%,与规模高达150倍的DeepSeek-R1-0528模型表现相当,远超R2VUL、ReVD等代表性off-policy优化方法。这充分证明了on-policy RL赋能VULPO在复杂上下文场景下的强大泛化能力。

分类型分析显示,VULPO对于核心内存安全类漏洞表现卓越,如CWE-415(Double Free)、CWE-119(内存边界限制缺失)、CWE-416(Use After Free)等召回率均80%以上,对于涉及数据流、并发和访问控制等高复杂度CWE类型同样优于其他模型。这一优势源于上下文级信息的系统性利用和多维度奖励机制的准确采集。

消融实验进一步揭示各模块对性能提升的核心贡献。标签难度奖励缩放是决定性因素,合理调整reward结构能有效缓解模型“reward hacking”,大幅降低假阴性。样本难度缩放机制保证模型关注难例的有效探索,配合多维奖励机制,进一步提升推理过程的完整性和准确性。冷启动SFT阶段对模型RL训练收敛与泛化有积极影响,但过度微调反而会限制探索能力,合理平衡阶段训练轮数是提升最终性能的关键。

在新发(OOD)漏洞数据上,VULPO依然展现出显著的迁移泛化能力,F1提升超40%并大幅减少完全错误判决,表明强化学习驱动下模型学到了能够适应场景迁移的动态推理规则。
综合各项结果可见,VULPO不仅实现了上下文感知VD任务在指标上的突破,更通过机制创新带来推理范式的质变,有力拓宽了LLM在安全工程领域的应用边界。
论文结论
本文针对长期以来学习型漏洞检测系统在上下文信息理解和演绎中的顽疾,系统性提出了VULPO:一套面向上下文感知漏洞检测的on-policy LLM RL优化框架。通过构建ContextVul仓库级数据集、多维度精细奖励函、标签/样本双层难度自适应调节和LLM评测裁判机制,VULPO显著提升了模型的推理能力和泛化性,实验结果在各主流评测指标上实现了对现有方法的大幅超越,且性能可与参数量百倍大模型媲美。消融实验和迁移测试进一步验证了各创新模块和机制对于实际效能的关键作用。
该研究不仅在方法论和理论上突破了现有瓶颈,更为实际大规模、跨项目的自动化漏洞检测提供了可行路径。未来工作展望包括训练更大规模的VULPO模型,扩展至多语言和多任务安全分析,以及构建跨语言仓库级上下文数据集以提升方法的普适性和应用广度。相关代码和构件将在论文录用后开源,有望推动学界与产业在代码安全智能分析领域的纵深发展。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
