“我更喜欢‘上下文工程’这个术语,而不是提示工程。它更好地描述了核心技能:为任务提供所有上下文,让大模型能够合理解决问题的艺术。” ——Tobi Lütke(Shopify电商平台创始人)
一、上下文工程的提出和发展
随着大模型在各类任务中的广泛应用,人们最初是站在设计提示的角度分析和构建应用,即所谓的“提示工程”。但当任务变得更复杂,涉及与大模型交互时的对话历史、工具调用、检索知识、记忆状态、长期上下文、多轮交互等场景时,仅靠优化提示已无法满足。从2025年4月到6月,经过全球技术社区的讨论,包括 Tobi Lütke、Andrej Karpathy 等业界人士开始明确提出并强调“上下文工程”(context engineering)的应用(相关概念在2002左右由“信息系统开发”领域提出),认为它是比 “提示工程” 更能有效实现大模型应用的核心方法,是一门通过提供上下文信息(情景信息)让大模型合理解决问题的艺术。这一观点迅速得到众多人工智能应用研究人员的认同,他们认为在工业级大语言模型应用中,上下文工程才是关键,是兼具科学性与直觉性的艺术,这一方法能够更好地将所需信息精准构筑到业务信息流中。
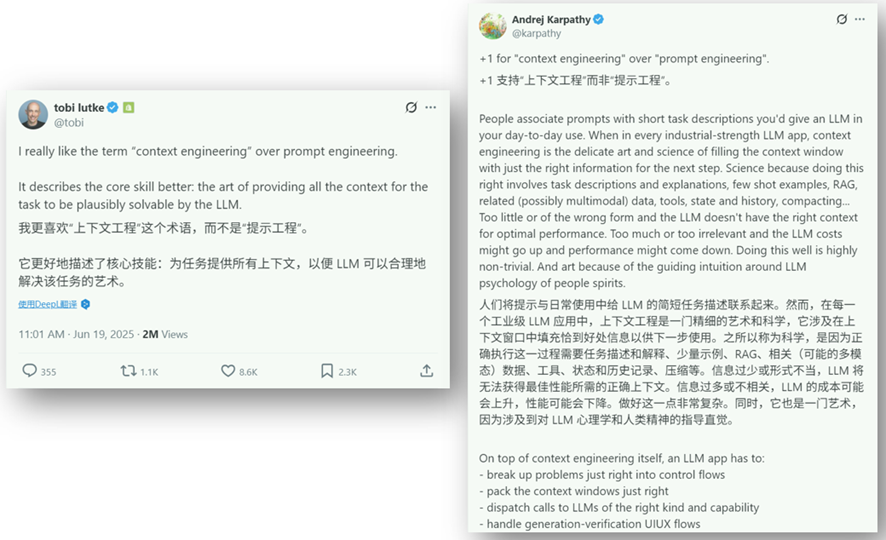
图1 技术社区中上下文工程的部分讨论
上下文工程是在大模型推理时,设计、组织、优化其上下文信息的工程方法,可以理解为 “构建动态系统,提供适当的信息和工具,以正确的格式管控数据,从而使大语言模型能够合理完成任务”。这一方法核心是要确保在对的环节,把对的信息,用对的格式,输入给大模型进行处理,以获得对的输出。该方法的提出是一种认知上的转变,标志着人工智能应用从“单次提示”演变为更契合场景应用的“系统化工程”的发展趋势。
这一方法主要考虑的上下文类型,一般可以分为指令类、信息类和工具类。指令类上下文包括:系统提示、少样本示例、角色设定、工具描述等。信息类上下文包括领域知识、事实片段、检索到的文档、对话记忆等。工具类上下文包括工具调用历史、工具接口说明、执行反馈、历史追踪等。
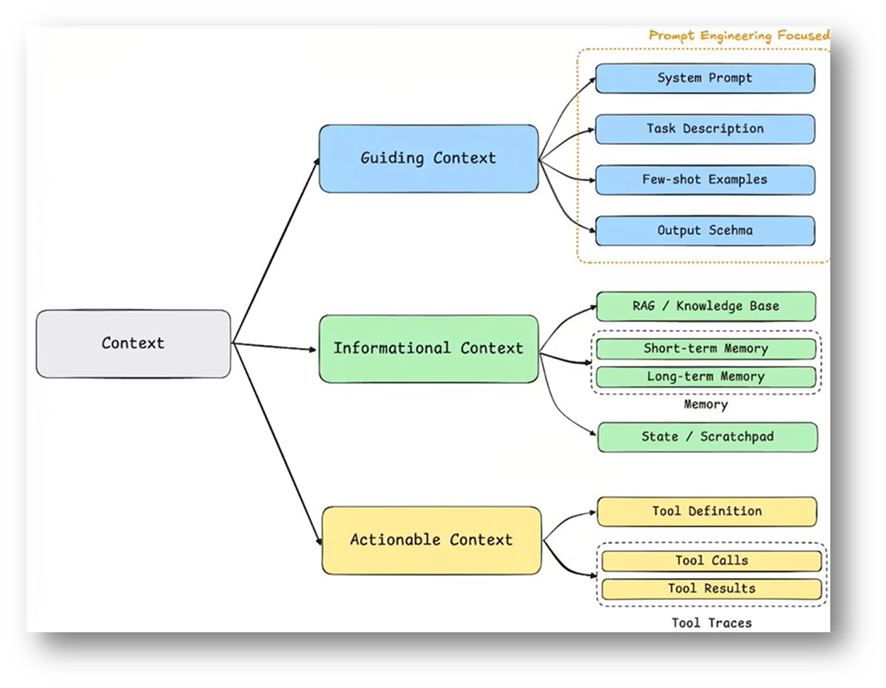
图2 上下文工程关注的上下文类型
在实际工程中,构建和管理这些上下文一般采用四种策略:写入、选择、压缩、隔离。写入策略将思考过程、中间状态、回合历史等写入外部存储,比如临时或者长期记忆库,实现持久化与跨会话记忆。选择策略则从多源信息中筛选最相关片段(如从记忆、工具说明、检索结果中挑选),然后将这些信息注入当前上下文。压缩策略对冗长上下文进行总结或修剪,压缩为语义密度更高的内容,以节省 token 并提升效率。隔离策略将不同模块或任务的上下文分区,比如使用多智能体架构或沙箱环境,以防止信息互相干扰或“污染”。
二、上下文工程是适配业务场景的大模型应用方法
上下文工程绝不是“高级的提示工程”或“复杂的RAG”,而是一套面向场景立意的新方法论,可以指导复杂业务场景智能化应用的构建。在复杂业务场景中,大模型应用不仅仅是一句巧妙的提示或检索生成 ,而是需要系统性地构建一个动态、结构化、可信的信息生态。上下文工程提供了这样一种方法论,它通过管理与组织指令、记忆、检索知识、工具调用等全部上下文,来支撑业务场景中的大模型应用,支持可重复、可靠、可审计的应用流程。
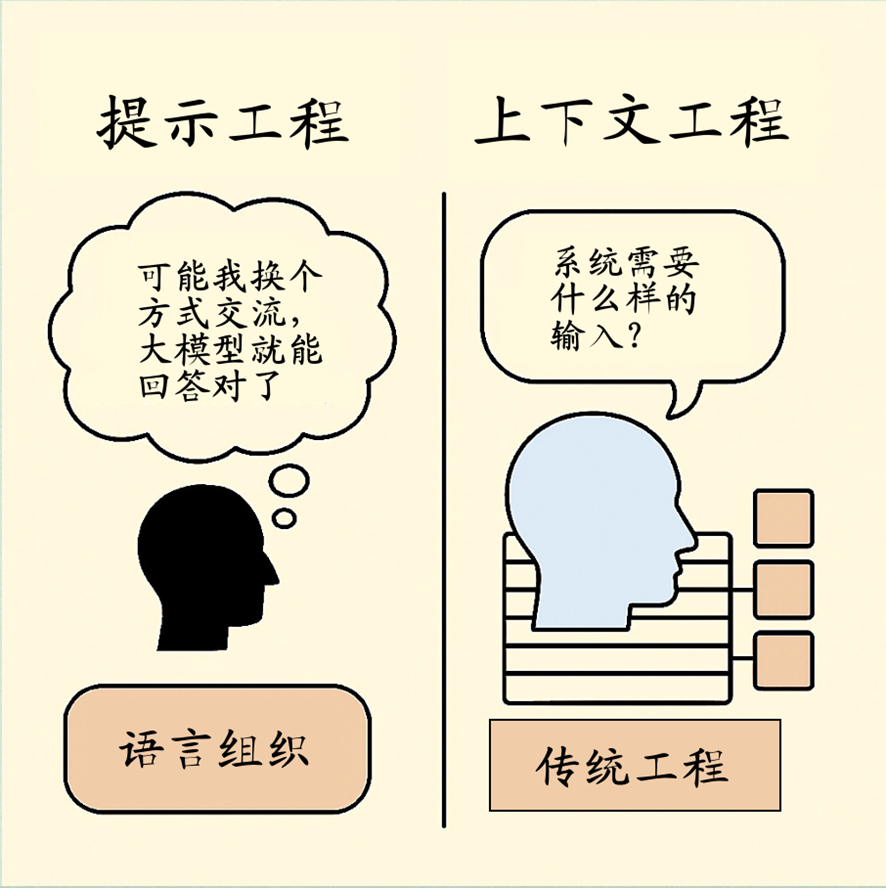
图3 上下文工程与提示工程的对比示意
站在智能化信息处理的角度,一是通过引入跨域记忆机制,把历史对话、关键状态、用户偏好等持久化,以适应跨会话、跨任务的业务要求,二是对历史内容进行压缩或精炼,以节省 token 并聚焦关键信息。这种机制在业务智能化场景非常重要,它使大模型既能“记得”长期关系与用户历史,又不会因为上下文膨胀而效率低下、成本高昂。
站在业务信息流的角度,通过动态组装多个层次的上下文将模型应用组装为一个稳定、可重复、可治理的沙盒环境,这些上下文包括系统提示、业务示例、知识片段、记忆和工具调用等。这等于是新建一个运行时上下文层,这个层经过版本化、测试、监控,能确保模型在每一步都能得到业务相关的正确信息。
站在可靠性角度,上下文工程体现了一种“工程纪律”,不再提倡临时拼贴提示,而是通过信息架构设计,把业务规则、输入输出规范、示例、校验标准等模块化,并在产品中持续演化,这更加符合传统工程思维,易于嵌入流程进行架构设计。通过版本化、模块化的上下文层设计,可以引入审计、校验和监控机制,确保模型调用前后遵循业务规则。此外,结构化输入与输出减少了模型生成出“离谱”或不合规内容的风险。上下文工程还可以结合工具调用反馈,将模型行为约束在业务安全范围内。
上下文工程的提出标志着从“巧妙一句提示”向“系统化、信息整合、流程化”的人工智能应用工程方式的演进。它为大模型在复杂业务场景中实现可信、可靠、可控应用提供了理论与实践基础。一是提高模型输出的准确性与业务适配性,通过为模型提供贴切、结构化、与业务目标一致的上下文,减少模型偏离、减少“胡说八道”的可能。二是增强模型在真实场景中的可靠性和一致性,在多轮对话、状态变更、工具调用、知识检索等复杂场景下,能够维持上下文连贯,提升用户信任。三是降低模型误用、误判风险,通过对上下文来源、工具定义、用户状态、历史记录等的信息管理,实现更好的可控、安全、可审计的智能系统。四是更符合传统工程思维,易于构建可规模化、可复用的智能系统,将上下文管理流程化、模块化,使得不同业务场景可以复用“上下文工程”框架,而不仅重新做提示。五是优化资源使用,合理选取、构建上下文,可避免上下文窗口冗余、token浪费、执行效率低下等问题。
三、上下文工程将推动国防领域可信人工智能应用的发展
参考美国国防部《负责任的人工智能战略》和美国航空航天工业协会发布的文件思路,在国防和航空航天领域,引入大模型等生成式人工智能系统必须格外注重责任、可追溯性 、可靠性与可治理性。上下文工程正是合乎这一领域的关键路径,为可信人工智能应用的落地提供了系统性支撑。

图4 美国国防部《负责任的人工智能战略和实施路径》封面
一是增强可追溯性,在国防和航空航天领域中运行的智能体,其每一步行动都可能影响研制、战备或安全。上下文工程能够记录与大模型交互相关的指令、检索到的知识、工具调用以及记忆状态,形成可审计的上下文 “快照”。这一机制支持事后回溯、责任界定与审计。
二是强化安全与失控预防,上下文工程通过隔离子流程或子智能体,可为系统设计 “断开” 或 “回撤” 的机制。这能够很好的响应 “检测及避免意外行为” 并有能力 “停用” 出现问题的系统等安全要求。
三是满足高保障验证要求,利用写入、选择、压缩等上下文工程策略,可将关键对话历史、知识调用、记忆变更等模块化记录,并在测试和验证阶段重放这些上下文。这样,验证团队可以在受控环境下重构复杂交互,并对系统进行鲁棒性和恢复性测试。
四是支持跨组织的互操作性,上下文工程提倡在系统之间或系统模块间构建标准化上下文结构,从技术上增强不同机构在人工智能交互与决策流程中的互操作性,同时使人工智能治理机制趋向一致。(李亮)
主编:张洋
制作:顾鹏程
本篇供稿:工业技术研究所
声明:本文来自空天防务观察,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
