基本信息
原文标题:VulnLLM-R: Specialized Reasoning LLM with Agent Scaffold for Vulnerability Detection
原文作者:Yuzhou Nie, Hongwei Li, Chengquan Guo, Ruizhe Jiang, Zhun Wang, Bo Li, Dawn Song, Wenbo Guo
作者单位:加州大学圣塔芭芭拉分校、芝加哥大学、加州大学伯克利分校、伊利诺伊大学厄本那香槟分校
关键词:软件漏洞检测、大语言模型、推理能力、模型蒸馏、Agent系统、安全自动化
原文链接:https://arxiv.org/abs/2512.07533
开源代码:暂无
论文要点
论文简介:当前AI在软件安全漏洞检测领域的应用正受到极大关注,然而现有方法多依赖于模式匹配、特征学习,难以应对实际项目中的复杂变种与推理需求。本文提出VulnLLM-R——首个专为漏洞检测任务定制的推理型大语言模型。作者通过独特的数据筛选与精细化训练流程,将泛用途大模型转化为能够“类人推理”、高效定位并解释安全漏洞的专业工具。VulnLLM-R不仅在多语言、多类型漏洞(Python、C/C++、Java及超过50类CWE)上实现了超越当下开源与商业模型、静态分析工具的性能,更凭借Agent系统在真实项目中发现多例零日漏洞,有力推动了漏洞自动检测的智能化进程。论文系统论证了推理能力对模型泛化、效率与实际威胁识别的重要作用,并首次验证了“专用小模型,优于通用大模型”在安全领域的成立性。
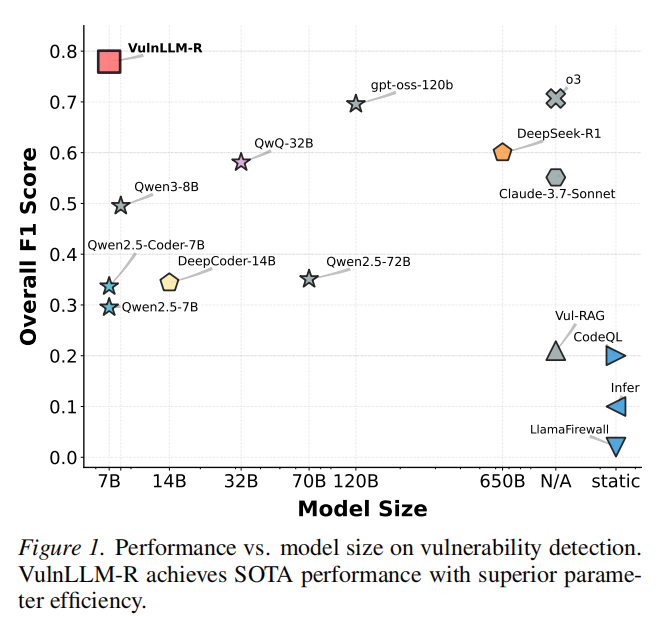
研究目的:随着大模型在编程相关任务中的突破,研究者试图将其拓展至安全领域的复杂问题——如漏洞检测。然而,现有数据驱动的模型多局限于对已知特征的模式化学习,难以对新颖漏洞、跨语言、复杂项目结构做出准确判断,缺乏“推理过程”导致泛化能力薄弱。更甚者,多数模型容量仍偏小、受限于training set窗口,只能应对简单函数级别的问题。现有通用型超大模型虽具强大能力,却包含大量无关功能,安全漏洞分析这种高专业性任务中效果有限且部署成本高。同时,使用第三方黑盒模型还存在数据隐私、定制化难等实际障碍。因此,作者旨在通过训练专用小型推理模型,赋予其深度理解代码上下文、推理软件状态与安全隐患的能力,并开发自动Agent框架以适应项目级真实场景,全面提升AI在漏洞检测中的泛化性、效率与实用价值。
研究贡献:
研究者提出了首个漏洞检测专用推理模型 VulnLLM-R,设计了一套包含数据筛选、推理数据生成、推理数据过滤与修正及测试阶段优化的创新训练方案。
研究者基于该方案训练了一个 70 亿参数模型,证实其在漏洞函数检测任务中,性能优于当前最优(SOTA)静态分析工具、大型开源模型及商业模型。
研究者基于该模型构建了智能体(Agent),并在 5 个真实世界项目中验证:该智能体的检测效果超越了当前最优的静态与动态分析工具。通过大量评估实验,研究者得出结论:漏洞检测任务既能够从专用小型推理模型中获益,也能借助精心设计的智能体提升性能。
引言
在软件安全领域,漏洞自动检测一直是关键但又难解的研究课题。传统机器学习方法,例如基于特征的分类器、深度神经网络以及Transformer模型,虽然在特定数据集上不断刷新指标,但由于本质上依赖“模式判别”与“特征记忆”,其泛化能力受到严格限制。这些方法往往在遇到新颖漏洞、复杂调用关系等现实场景时表现不佳。此外,目前大多数ML模型容量有限,仅适用于短小、单一函数的检测,难以扩展至实际项目级别分析。因此,业内依然广泛依靠静态分析(如CodeQL、AFL++等)等传统工具。
近年来大模型因其在通用推理、自然语言处理乃至代码生成任务中表现卓著,研究如何将推理能力迁移至安全领域成为热点。作者敏锐地捕捉到漏洞检测本质上要求模型“深度推理”程序状态与安全逻辑、跳脱浅层pattern依赖。如果AI能够像人类一样,“解释性地”分析代码,并给出推理流程,理论上可以大幅提升对复杂、跨分布漏洞的判别能力。然而现有推理能力强的大模型大多为超大规模、多用途的封闭商用产品,远超实际漏洞检测需用的资源范围,且缺乏针对安全领域的知识内化与机制适配。通常的开源模型即便有相应规模,也极难获得推理链条及专业高质量样本训练。此前虽有少数工作(如LLM4Vul、LLMxCPG)关注于推理型模型的评估与context感知,但并未提出系统的训练与推理流程,更未解决推理链条校验与泛化瓶颈。
本文创新地提出:要想真正赋予模型“推理-泛化-适应”能力,必须设计专用小模型体系,并通过定制化训练流程使其深度学习推理链、知识规则、错误校正和高效输出机制。为支持实际工程部署,还需将其与自动Agent框架结合,激活上下文自主检索能力,迁移到项目级、真实零日威胁检测应用中。论文以系统化数据分析与工程实践为支撑,不仅在主流公开基准上迭代,且主动推动安全领域AI Agent智能实践的落地。
研究背景
大语言模型(LLMs)近年来以Transformer架构为基础,通过大规模自监督预训练和精细化微调,催生出诸多在复杂任务(如代码生成、数学推演、科学分析等)中表现卓越的实例。其推理能力不仅源自网络规模和训练数据广度,更在于创新的推理链型训练范式,例如Chain-of-Thought(CoT)、Tree-of-Thought、ReAct等。这些机制促使模型在响应时显式输出推理过程,显著提升复杂任务的可解释性、准确性与泛化性
在推理型LLM方面,当前领域顶级模型如OpenAI o3、Claude-3.7-Sonnet、QwQ-32B、DeepSeek-R1等,已被验证能够优于传统系统在各类难度任务上实现SOTA,但通常体量极大,资源消耗和闭源特性限制其在特定场景下的实际落地。安全领域的漏洞检测任务具有极高的专业性和稀缺性,现有公开大模型未能充分学习漏洞原理及广泛安全知识,且多余能力(如图像/视频处理、复杂自然语言场景)反而拖累定制效率。
漏洞检测方向,传统静态分析方法依赖人工设定的规则与模式匹配,如CodeQL、Bandit、Infer等,长期作为业界主流工具。然而这一方法由于对语法/语义规则的完备性及专家经验依赖强,面对新型/变异漏洞和复杂跨函数关系时易产生误判/漏判。动态分析中Fuzzing类工具(如AFL++)关注输入空间的系统性探索,能够实际触发未知crash但普遍效率低、覆盖率有限、难以赋予明确漏洞类型解释。
早期深度学习方法尝试解决上述问题,利用图神经网络、循环网络、卷积结构等分析代码结构与语义,但由于模型体量所限和训练数据的问题,依然在函数级别、跨分布泛化等方面捉襟见肘。此外,现有大部分开源/商用模型并未专为安全任务设计,缺失安全特定知识和推理链数据,模型部署和更新上的数据隐私、定制化需求也未得到很好解决。
此前诸如LLM4Vul、LLMxCPG等新兴方法探索了大模型在漏洞检测领域的适用性,提出以评估框架结合代码属性图等方式提取context并辅助检测,但其本质仍是分类策略,缺乏面向推理链“全过程”的系统训练体系,无法从原理层面保证模型能真正“理解”安全隐患的本质和全局关联。
VulnLLM-R概述
VulnLLM-R提出了一套专为漏洞检测推理服务的全新训练体系和推理机制,其设计理念围绕模型轻量化、专用化、安全性、推理力、泛化性几大核心目标展开。
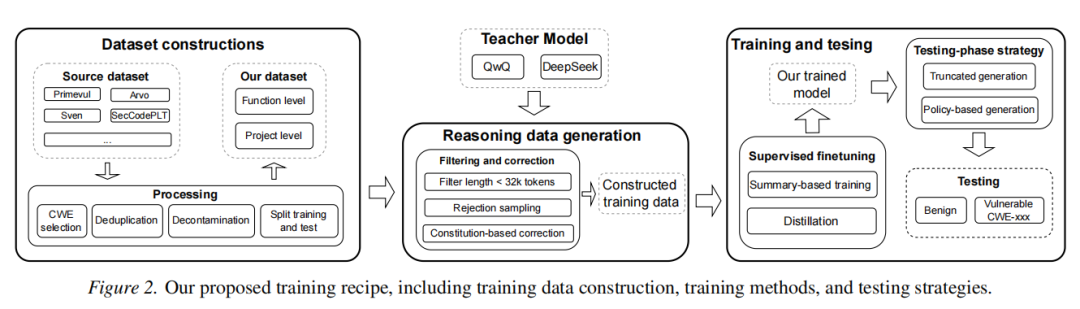
1. 模型体系与训练策略总览
作者以Qwen2.5-7B-Instruct为基座,通过“推理型知识蒸馏——多Teacher联合——主动过滤与宪法校正——推理总结(Finetune)”四步流程,有效将通用大模型的推理力凝聚到针对漏洞检测的小模型上。首先,选取两类顶尖开源推理模型(DeepSeek-R1与QwQ-32B)为Teacher,分布生成多样推理链数据,既丰富推理结构又分散单一模型偏差。每一训练样本均要求output中包含系统化的推理过程,而非直给答案。
2. 数据构建与过滤机制
数据来源高度多元,覆盖Python、C/C++、Java以及实用级项目,涵盖50余种关键CWE。数据选取严格遵循(1)CWE类型广度,确保漏洞类型覆盖丰富;(2)规模/复杂度多样性,兼顾短函数、长函数和跨函数调用,采集自Juliet 1.3、PrimeVul、ARVO等知名数据集并经人工+模型二重校验。为确保数据质量,整个训练流程严格去重、去重叠(20-token n-gram规则)、数据污染剔除及人工二次审核。Benign样本除补丁代码,还特别引入真实无漏洞功能代码,以防模型过拟合于简单差分。
3. 推理链生成与宪法校正机制创新
针对每一代码片段,Teacher模型分别生成8条推理链,并通过拒绝采样严格过滤掉推理结论错误的样本。此处不同于一般数学/编程任务的模型蒸馏,作者发现安全领域下,小模型如果仅学推理结构而非正确知识将无法提升泛化力。过滤导致数据量锐减后,引入“宪法校正”机制:人工分析典型错误并为每类CWE撰写“推理宪法”,通过指令让Teacher模型依据这些“宪法”重新分析错误样本,形成更为严谨的推理链并提炼出约三成新增高质量数据。
4. 摘要式训练与推理输出压缩
为提高模型推理效率,作者在小模型一轮推理基础上,额外训练模型提纯后的“推理摘要”,使其最终输出既能充分表达论证逻辑,又能在token两倍压缩下极大提升推理速度,突破通用大模型常见的推理冗余、效率低下等瓶颈。
5. Agent框架与工程落地
针对项目级场景,作者搭建Agent脚手架,自动化实现目标函数筛选、调用链context检索、辅助信息动态获取。系统集成CodeQL等静态工具辅助context收集,并设计有限轮人工调用函数实现集成。在Agent层面也采用推理链微调以增强模型自动用工具、跨多步推理的能力,显著增强了项目级多函数跨文件漏洞定位的现实适用性。
总体而言,VulnLLM-R的训练与推理体系既凸显方法论创新——多模型多样校验、审慎过滤和经验规则注入,又极度重视工程实践和泛化瓶颈突破,为安全推理大模型设立了新的科学规范。
实验设计与功能评测
作者搭建立体化实验体系,从函数级别到真实项目级、从多语言多CWE到跨分布泛化,对模型效果、效率、实际可用性进行了全方位验证。
1. 数据集与基线设置
使用六大主流+自建数据集(Juliet 1.3、ARVO、PrimeVul、SVEN、SecCodePLT、SecLLMHolmes),涵盖Python、C/C++、Java程序、项目及50余类高危CWE,数据量和难度大大扩展了以往基准。为公平性,所有基线方法(含模型)均用一致的数据集、prompt及context,防止数据污染和label泄露。基线涵盖主流静态工具(CodeQL、Infer)、新型规则引擎(LlamaFireWall),及多类高性能LLM(含商业o3、Claude-3.7-Sonnet,开源QwQ-32B、DeepSeek-R1、本征Qwen2.5-7B、RAG等),并单独重训LLMxCPG等上下文感知方法。
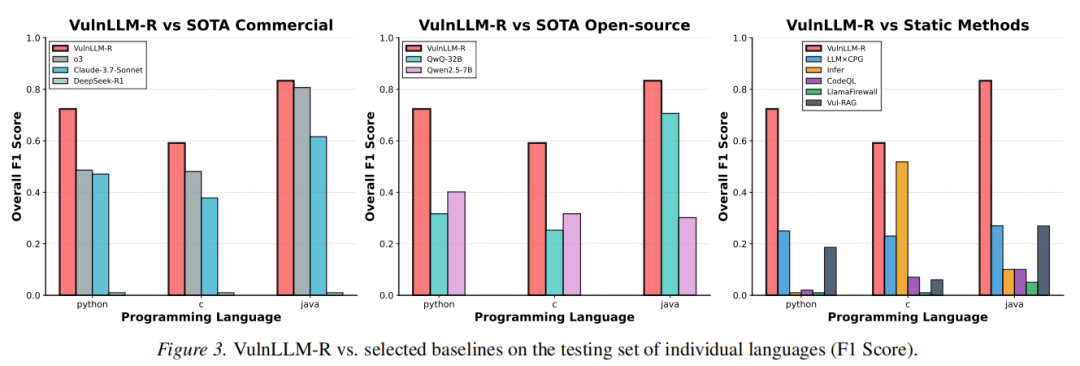
2. 实验流程与指标
函数级任务采用每条样本标准prompt,要求输出推理链及最终CWE判定,评估准确率、F1分数、假阳性/假阴性比等。进一步进行消融实验(如无推理、单Teacher、无宪法/总结优化等),全面评估各关键设计对性能的提升贡献。泛化验证采用持出CWE测试(OOD)及未见语言(Java)跨分布效果。效率评估上,统计模型平均推理token数、消耗时间等。
3. 项目级Agent实测
选用五个真实且带ground truth的开源项目(含AIxCC DARPA挑战官方数据),跨C/Java,涵盖多元漏洞类型,要求模型能够在限定时间(一小时内)判定所有目标函数的漏洞状态及类型,与主流静态(CodeQL)、动态(AFL++/Jazzer)、LLM辅助(RepoAudit、G2Fuzz)及商业模型进行真是对比。Agent方案评测包括调用路径构建、函数context动态检索、工具协同等全栈流程,重点关注实际新型高危零日漏洞自动发现能力并人工核实。
4. 实验现象和数据亮点
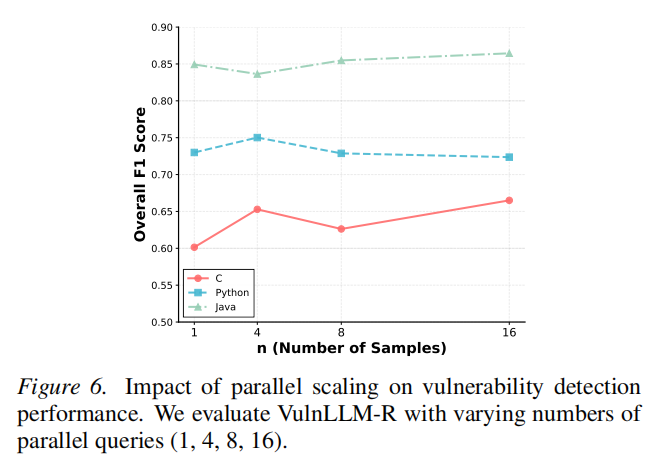
VulnLLM-R在Python/C/C++/Java任务中,均显著超越同参量(7B及以下)和超大体量(高达120B/650B)商业模型和主流静态分析系统,不仅F1分数整体领先,推理token开销最短、效率最优;在未参与训练的CWE及Java全新语言上依然展现卓越泛化力(如Java上F1高达0.87)。在复杂项目级实测中,Agent集成VulnLLM-R以1小时内完成全部函数判定,发现15例官方未披露的“零日漏洞”,远超AFL++等需要24小时/实例的效率和覆盖率。消融结果进一步证实推理链显著增强模型泛化、宪法与总结机制对准确率和推理效率双重提升。
讨论与未来展望
作者从方法论、数据、应用和理论角度对研究局限性与未来方向进行了多维反思。
首先,当前系统尽管已涵盖最主流的Python、C/C++、Java及高危CWE,但受限于现有公开数据集的规模与质量,尚无法全面覆盖所有语言及新兴漏洞类型,如Go、Rust、TypeScript等。未来亟需社区合力升级数据资源,尤其是涉及项目级、多文件、多函数链式安全威胁的高质量标注样本,以及面向流行新兴语言的安全场景。
其次,现有Agent仅实现了静态context检索和有限工具集成,后续有望整合更丰富的分析器、RAG、动态模糊测试等异构工具,即进化为真正的“安全AI多智能体”。Agent调度方面,还可探索让LLM自主规划工具调用、分析分工等提升自动化与智能化水平。
在理论层面,推理链训练范式已被证明对泛化与复杂推理力有独特优势,但如何进一步剖析推理链的“深度/长度/结构”与模型可解释性、鲁棒性的关系?如何进一步防止模型形成“推理陷阱”或过度简化?这些都是未来的重要研究课题。
此外,开放小模型体系为安全敏感场景带来了数据隐私与高定制的基础,业界可据此实现更高频更新、更灵活适配和更安全的数据管理。随着Agent与推理型LLM的结合,预期未来软件安全检测将由“规则+脚本”驱动彻底转变为“推理+Agent”范式,推动行业向自动化、智能化跃迁。
论文结论
研究者提出了首个漏洞检测专用推理模型 VulnLLM-R,设计了一套包含数据筛选、推理数据生成、推理数据过滤与修正及测试阶段优化的创新训练方案。研究者基于该方案训练了一个 70 亿参数模型,证实其在漏洞函数检测任务中,性能优于当前最优(SOTA)静态分析工具、大型开源模型及商业模型。此外,研究者基于该模型构建了智能体(Agent),并在 5 个真实世界项目中验证:该智能体的检测效果超越了当前最优的静态与动态分析工具。通过大量评估实验,研究者得出结论:漏洞检测任务既能够从专用小型推理模型中获益,也能借助精心设计的智能体提升性能。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
