概述 (Overview)
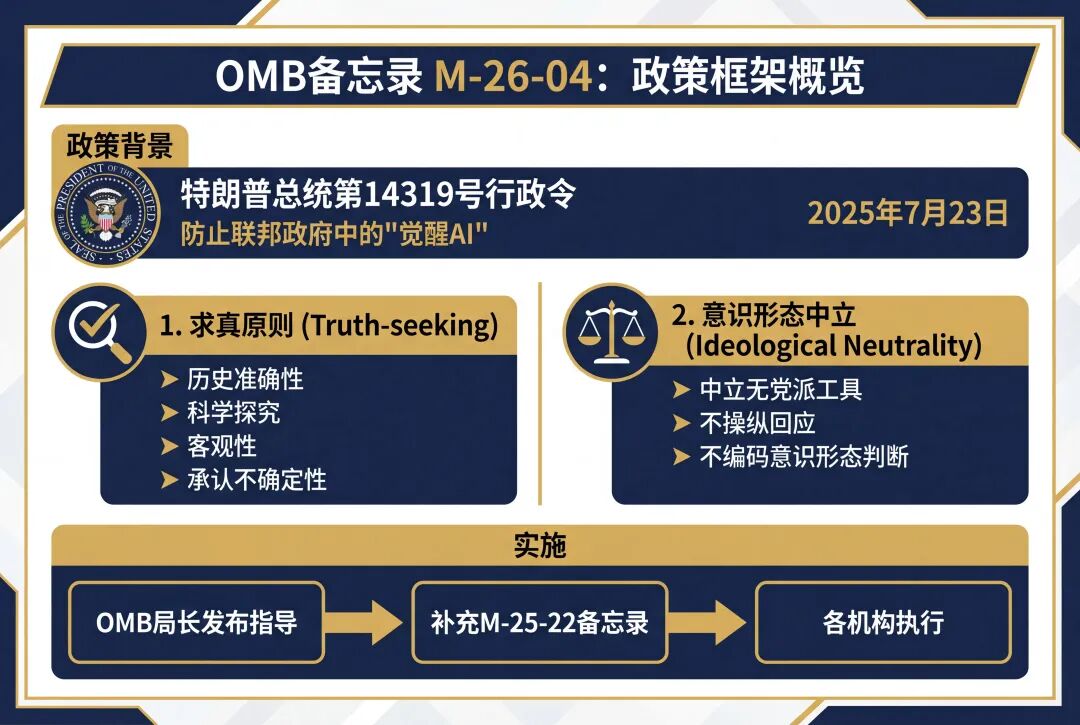
本“概述”部分至关重要,它为整个备忘录的政策背景和核心目标奠定了基础,明确指出本备忘录旨在执行特朗普总统关于防止“觉醒AI”(Woke AI)的行政命令,并确立了两大指导原则。
2025年7月23日,特朗普总统签署了第14319号行政命令《防止联邦政府中的觉醒AI》(以下简称“E.O.”)【1】,旨在确保联邦政府采购的大语言模型(LLMs)能够产生可靠的输出,不含有害的意识形态偏见或社会议程。为进一步推进这项旨在促进创新和使用可信赖人工智能(AI)的政策,该行政命令确定了两项“无偏见AI原则”【2】:
求真 (Truth-seeking) :大型语言模型【3】在回应用户寻求事实信息或分析的提示时,应做到真实。大型语言模型应优先考虑历史准确性、科学探究和客观性,并在可靠信息不完整或相互矛盾时承认不确定性。
意识形态中立 (Ideological Neutrality) :大型语言模型应作为中立、无党派的工具,不应为偏袒意识形态教条而操纵回应。除非这些判断是由用户提示或以其他方式易于为最终用户所获取,否则开发者不得有意将党派或意识形态判断编码到大型语言模型的输出中。
该行政命令第4节要求行政管理和预算局(OMB)局长发布指导意见,以帮助各机构实施这些原则。本备忘录即履行了该要求,并对OMB M-25-22号备忘录《推动政府高效采购人工智能》进行了补充。【4】
在明确了作为备忘录基石的核心原则后,接下来将界定这些原则的具体适用范围,以确保政策的精确执行。
适用范围 (Scope)
界定“适用范围”对于政策执行具有重要的战略意义,它明确了哪些机构和系统必须遵守该备忘录,哪些则被排除在外,从而避免了执行过程中的混淆和误用。
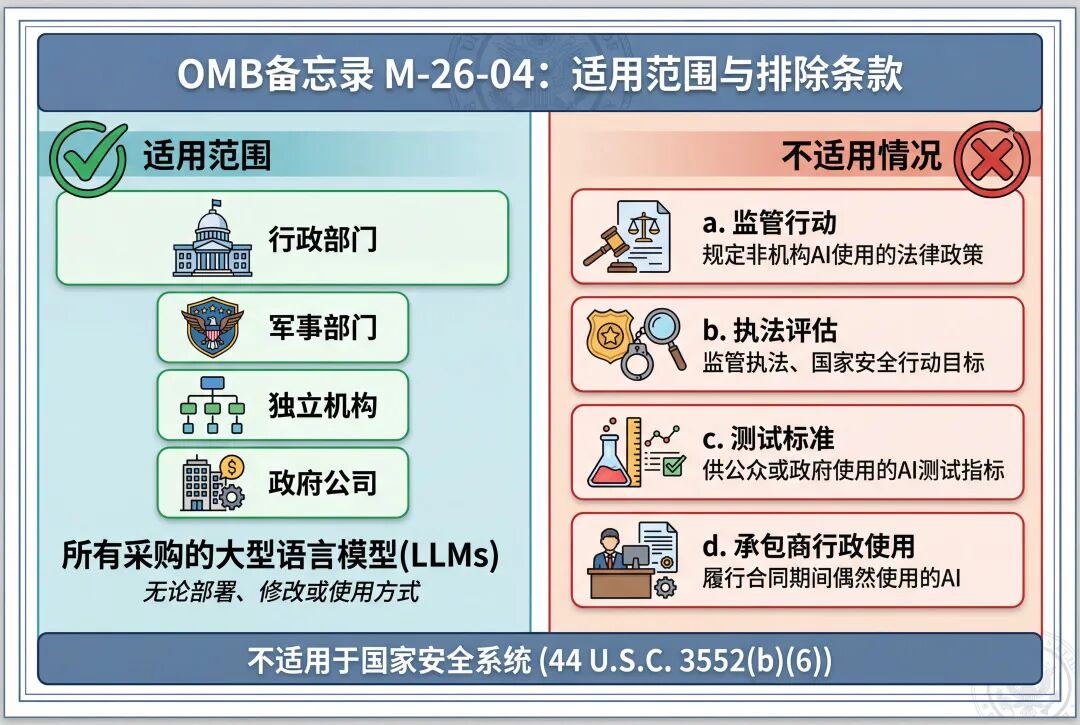
本备忘录的要求适用于每个“机构”,其中“机构”指行政部门、军事部门,或分别符合《美国法典》第5篇第101、102和104(1)条定义的任何独立机构,或符合《美国法典》第31篇第9101条定义的任何全资政府公司。这些要求不适用于《美国法典》第44篇第3552(b)(6)条定义的国家安全系统。【5】然而,鼓励在实际可行的情况下将本备忘录应用于国家安全系统。
在此范围内,本备忘录的要求适用于机构采购的任何大型语言模型,无论该模型将以何种方式被部署、进一步修改或使用。【6】机构在决定是否将这些要求应用于由本机构开发的大型语言模型,以及采购的非大型语言模型的人工智能模型时,也必须考虑附录A.2中确定的相关因素。【7】
本备忘录不适用于以下情况:
a. 机构旨在规定关于非机构使用人工智能的法律或政策的监管行动;
b. 机构对特定人工智能应用的评估,因为该AI提供者是监管执法、法律执行或国家安全行动的目标或潜在目标;或者机构正在评估该AI应用是因为它被犯罪嫌疑人使用;
c. 机构为测试和衡量人工智能而开发的指标、方法和标准,而这些指标、方法和标准是供公众或整个政府使用,而非用于测试特定机构应用的人工智能;【8】或
d. 承包商在履行合同期间为行政目的偶然使用的人工智能(例如,承包商在非为履行合同要求所指示或必要的情况下,自行选择使用的人工智能)。
在明确了政策的适用边界之后,备忘录将具体阐述各机构为落实这些原则而必须采取的强制性行动。
译者注:
这两项排除条款(a 和 b)共同界定了该备忘录的管辖边界。简单来说,这项备忘录是为了规范政府“自己如何购买和使用”人工智能,而不是为了限制政府“如何监管他人”或“如何打击犯罪”。
以下是针对这两点的详细解析:
关于条款 (a):监管行动的排除
核心含义:对内不对外。
理解要点:该条款规定,当联邦机构(如联邦贸易委员会 FTC 或证券交易委员会 SEC)制定针对私营企业或公众使用 AI 的法律、法规或政策时,不受本备忘录约束。
深层逻辑:本备忘录的目的是确保政府采办的 LLM 具有“寻求真理”和“意识形态中立”的特性,。然而,机构在进行监管执法或制定宏观政策时,需要根据其职权范围内的特定法律(如反垄断法、消费者保护法)来行动。如果将本备忘录的采购标准硬套在监管政策上,可能会干扰机构履行其法律赋予的监管职责。
结论:这明确了本备忘录是一份内部采购与管理指南,而非一份普适性的、针对全社会的 AI 监管框架。
关于条款 (b):执法与国家安全评估的排除
核心含义:调查不受限。
理解要点:当机构出于以下原因评估某个 AI 应用时,可以不遵守本备忘录的要求:
该 AI 的提供商正是执法、监管或国家安全行动的调查对象。
该 AI 应用被犯罪嫌疑人使用过,机构正在对其进行取证或评估。
深层逻辑:
保护调查独立性:如果 FBI 或国家安全部门正在调查一个涉嫌传播虚假信息或存在危险偏见的 AI 供应商,他们必须能够自由地剖析、测试该 AI 的缺陷。如果要求这些“调查行为”也必须符合备忘录中的“无偏见原则”,逻辑上会产生冲突——调查人员正是为了发现其“有偏见”或“不实”的证据。
证据分析:当 AI 被用作犯罪工具时(例如嫌疑人用它编写恶意代码或进行诈骗),执法部门需要对其进行技术评估。这种评估属于刑事侦查范畴,而非行政办公使用,因此不应受到针对政府办公工具的采购标准限制。
衔接:这与备忘录中"不适用于国家安全系统"的整体原则相呼应,确保了在敏感的执法和防御领域,机构拥有必要的灵活性。
机构行动 (Agency Actions)
“机构行动”部分是本备忘录中操作性最强的核心内容,它将高层级的指导原则转化为各联邦机构必须在规定时间内完成的具体、强制性的任务,确保政策能够切实落地。
各机构必须遵守以下要求,并采取附录A中所述的额外实施措施:
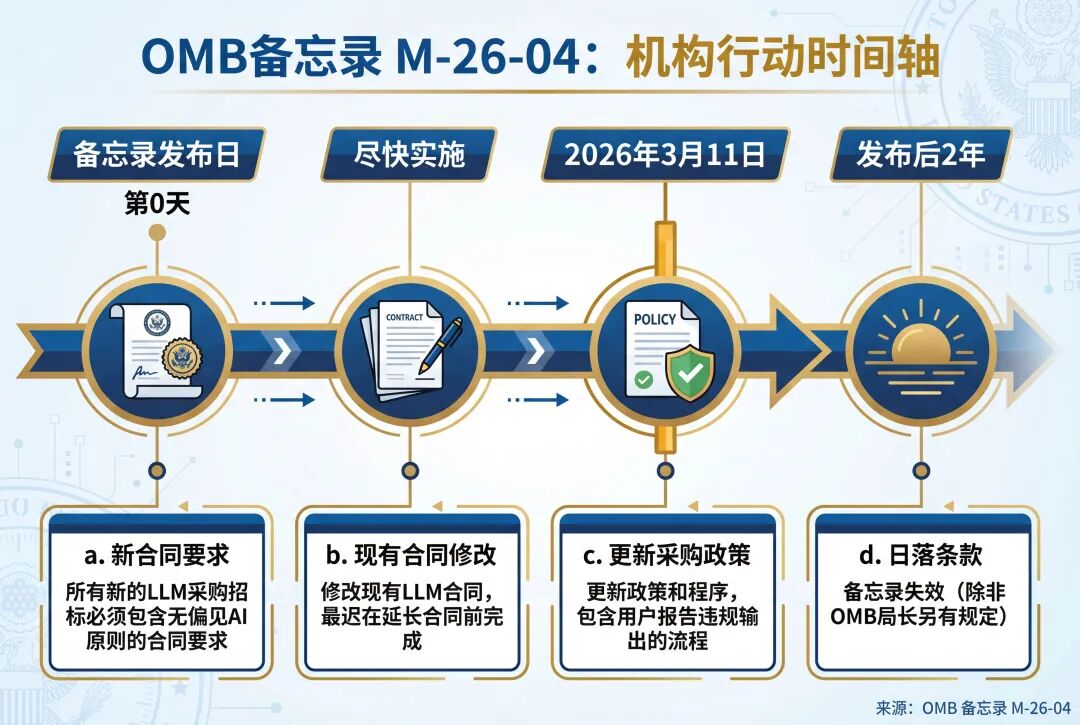
a. 新合同的合同要求 (Contractual Requirements for New Contracts)
在本备忘录发布之日后,各机构发布的任何大型语言模型采购的招标或订单,都必须包含附录A中所解释的、涉及遵守“无偏见AI原则”的合同要求。对于经机构确定应适用本备忘录要求的其他非大型语言模型的人工智能模型,其招标或订单也必须包含此类合同要求。
b. 现有合同的要求 (Requirements for Existing Contracts)
各机构应在实际可行的情况下,修改现有的大型语言模型合同,以包含前述段落中描述的要求。此类修改最迟应在执行任何延长合同履行期限的选项之前完成。
c. 更新机构采购政策 (Updating Agency Procurement Policies)
不迟于2026年3月11日,各机构必须更新其政策和程序,以确保大型语言模型的采购合同中包含涉及遵守“无偏见AI原则”的合同要求。更新后的政策必须包括供机构大型语言模型用户报告违反“无偏见AI原则”的输出的流程。
d. 日落条款 (Sunset Provision)
除非行政管理和预算局局长另有规定,本备忘录将在其发布之日起两年后失效。
为有效支持上述行动的实施,备忘录在附录中为各机构提供了更为详尽和具体的操作指南。
附录 A:机构实施指南 (Appendix A: Implementation Guidance for Agencies)
附录A是本备忘录的重要组成部分,它为各机构提供了一份详细的操作手册和技术考量清单,旨在帮助它们将备忘录中的高层原则转化为实际的采购流程和技术开发规范。
本指南建立在现有的关于机构采购和使用人工智能的指令和政策基础之上,例如特朗普总统的第13960号行政命令《促进在联邦政府中使用可信赖的人工智能》【9】*,*以及OMB的M-25-22号备忘录《推动政府高效采购人工智能》【10】和M-25-21号备忘录《通过创新、治理和公众信任加速联邦政府对人工智能的应用》。【11】通过遵守这些指令和政策以及本备忘录,各机构将确保在涉及大型语言模型的机构行动和决策中,由人类承担最终责任。
1. 合同要求 (CONTRACTUAL REQUIREMENTS)
在采购大型语言模型时,各机构必须从供应商处获取足够的信息,以判断该模型是否符合“无偏见AI原则”。可用信息的数量和类型将取决于供应商在软件供应链中的角色及其与大型语言模型开发者本身的关系,通常情况下,信息源越接近原始的LLM开发者,可获得的信息就越多。
在联邦采购中,供应商通常通过经销商或其他AI开发者产品的中间部署者,间接向机构提供对大型语言模型和其他AI的访问。机构也经常与软件集成商和平台运营商签订合同,这些集成商和运营商将大型语言模型作为其更广泛产品的一部分提供。当机构与此类第三方大型语言模型提供商交易时,产品信息的可用性和直接产品干预的可能性将取决于实际的AI开发者是否愿意通过第三方分销商进行合作。各机构在决定如何应用本备忘录的要求时,应考虑大型语言模型采购的这些细微差别,以确保所采购的模型符合“无偏见AI原则”。【12】
在可行的情况下,各机构应避免提出迫使供应商披露敏感技术数据(如特定的模型权重)的要求。文件要求应旨在获取足够的信息,以便机构能够在模型、系统和/或应用层面评估供应商的风险管理措施,以确定其是否符合“无偏见AI原则”。【13】
除了获取正在考虑采购的独立大型语言模型的信息外,当这些模型被集成到其他待采购的软件产品或服务中时,各机构也必须要求提供有关大型语言模型开发和运营的信息。【14】
A. 最低LLM透明度门槛 (Minimum Threshold for LLM Transparency)
在大型语言模型的招标中,各机构必须要求供应商提供以下信息:
i. 可接受使用政策 (Acceptable Use Policy)。 该文件通常由原始LLM开发者起草,用于描述和区分其产品的适当与不当使用方式。
ii. 模型、系统和/或数据卡 (Model, System, and/or Data Cards)。 这些来自LLM开发者的材料概述了与产品相关的所有关于模型、系统和/或数据的基本信息。提供的信息通常包括训练过程摘要、已识别的风险与缓解措施,以及LLM在基准测试中的模型评估分数。供应商通常不会同时提供所有三种类型(模型、系统、数据)的摘要卡。
iii. 最终用户资源 (End User Resources)。 此类资源可包括产品教程、开发者指南或其他最佳工具,以帮助客户确保正确使用LLM并最大化其效用。
iv. 最终用户反馈机制 (Mechanism For End User Feedback)。 此要求可以通过一个通用邮箱、特定的产品联系人或类似的机制来满足,以便就违反“无偏见AI原则”的输出向供应商提供反馈。
B. 增强LLM透明度门槛 (Threshold for Enhanced LLM Transparency)
根据对特定大型语言模型的计划用途,机构可能会认为需要超出上述范围的信息,以确保该模型符合“无偏见AI原则”。【15】任何对此类额外信息的要求都应侧重于与这些原则直接相关的行动,例如:
i. 训练前与训练后活动 (Pre-Training and Post-Training Activities)。
A. 为影响LLM输出的事实性和基础性而采取的行动。
B. 为模型提供自然语言指令的系统级提示,具体说明回应用户生成查询的准则,特别是在可靠信息不完整、矛盾或存在个人解读空间时模型应如何回应。
C.通过内容审核和安全过滤器限制的输出类型。
D. 使用“红队测试”作为持续评估模型的手段,以防范生成输出中的偏见事件。
E. 在美国境外进行的任何训练或开发活动,包括活动类型及所在国家。
F. 为遵守美国联邦政府以外的任何政府法规而进行的任何修改或配置。
ii. 模型评估 (Model Evaluations)。
A. 供应商进行的偏见评估结果及执行此类测试的方法论(例如,针对政治导向话题的测试提示对)。
B. 供应商评估的基准分数,用于衡量模型在面对模糊问题与直接问题时的偏见、帮助性、诚实度或准确性。在某些情况下,需要跨多种语言比较性能的基准。
iii. 企业级控制 (Enterprise-Level Controls)。
A. 治理工具,例如可定制的系统指令,这些指令是对基础模型系统提示或内容生成过滤器的补充。
B. LLM模型评估工具,能够比较同一模型的不同输出,或跨不同模型进行比较。
C. 要求模型引用其输出来源或以其他方式提供模型输出来源可见性的产品功能。
iv. 第三方修改 (Third Party Modifications)。
A. 如果供应商不是LLM的直接开发者,需披露其为修改LLM输出而应用的额外控制措施(例如,分类器、系统提示、微调、内容审核和过滤器)。
C. 重要性要求 (Materiality Requirement)
各机构应明确将(a)和(b)中确定的相关要求认定为合同资格和付款的实质性条款,以便在供应商拒绝就已识别的违规情况采取纠正措施时,根据行政命令的指示,支持以违约为由终止合同。
在明确了合同中的具体透明度要求后,下一部分将探讨这些要求在不同采购和开发情境下的适用性因素。

2 适用性因素 (APPLICABILITY FACTORS)
在决定是否将本备忘录的要求应用于由本机构开发的大型语言模型,或非大型语言模型的人工智能模型时,机构应考虑以下因素:
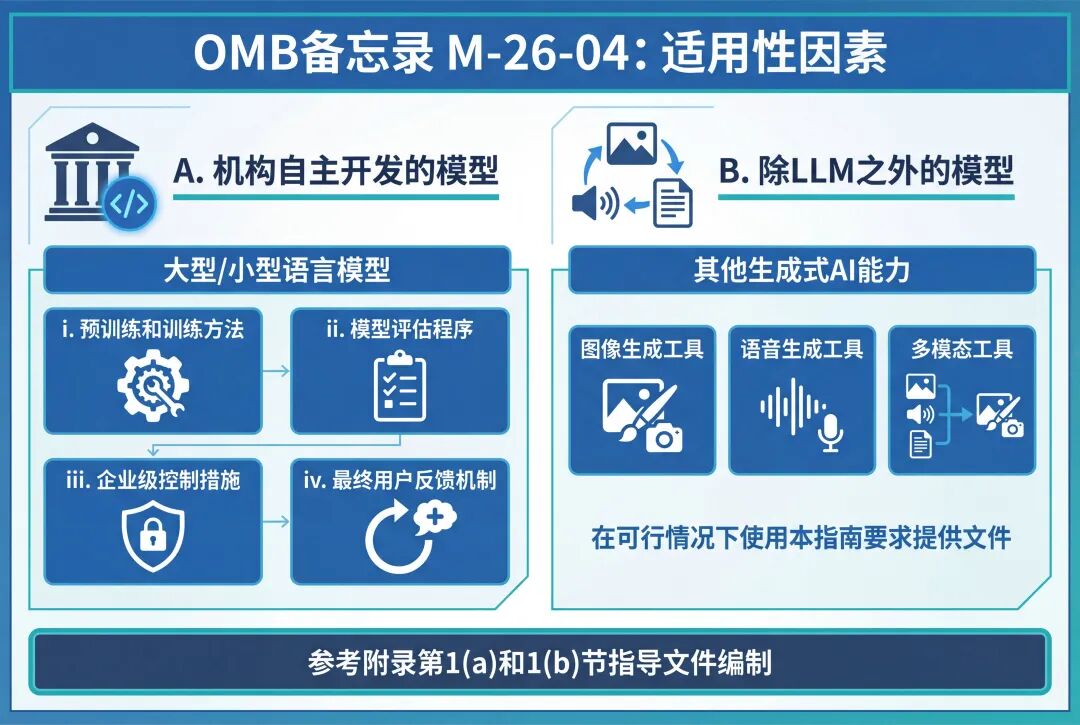
A. 机构开发的模型 (Models Developed by the Agency)
对于机构自行开发大型语言模型或小型语言模型的用例,期望提供类似的文件来证明和评估“无偏见AI原则”在整个开发生命周期中的整合情况。尽管所包含信息的具体性质可能因用例而异,但各机构应参考本附录第1(a)和1(b)节中描述的文件类型,来指导其自身文件的编制。机构文件至少应说明:
i. 机构如何进行模型的预训练和训练;
ii. 机构如何着手评估该模型,以及是否或如何执行定期或持续的评估;
iii. 模型中内置了哪些企业级控制措施,以及如何访问和配置这些控制措施;以及
iv. 机构的开发团队如何考虑来自LLM最终用户的反馈,包括本附录第1(a)(iii)节详述的相关最终用户资源。
B. 除LLM之外的模型 (Models Other Than LLMs)
如果机构正在采购其他类型的生成式AI能力,例如辅助图像、语音或多模态生成的工具,机构应在可行的情况下,使用本指南来指导采购中对文件提出的要求。
综上所述,本备忘录通过明确的原则、适用范围、机构行动和详细的实施指南,为联邦政府在人工智能时代的采购和开发活动提供了全面的指导框架。
[^1]: 行政命令 14139,防止联邦政府中的“觉醒”人工智能(2025 年 7 月 23 日)
[^3]: E.O. 第3节第 2 条将“LLM”定义为:“一种大型语言模型,是在广泛、多样的数据集上训练的生成式人工智能模型,使该模型能够针对用户提示生成自然语言响应。”
[^4]: OMB M-25-22号备忘录,《推动政府高效采购人工智能》(2025年4月3日),https://www.whitehouse.gov/wp-content/uploads/2025/02/M-25-22-Driving-Efficient-Acquisition-of-Artificial-Intelligence-in-Government.pdf
[^6]: 尽管不要求各机构将本备忘录的要求应用于根据免费、开源许可证获取的大型语言模型,但它们应在使用前建立程序,对此类模型是否符合第14319号行政命令的“无偏见AI原则”以及OMB M-25-21号备忘录的要求进行尽职调查。各机构应继续按照OMB M-16-21号备忘录的指示,负责任地利用开源产品的优势。
[^10]: OMB M-25-22号备忘录,《推动政府高效采购人工智能》(2025年4月3日),https://www.whitehouse.gov/wp-content/uploads/2025/02/M-25-22-Driving-Efficient-Acquisition-of-Artificial-Intelligence-in-Government.pdf
[^11]: OMB M-25-21号备忘录,《通过创新、治理和公众信任加速联邦政府对人工智能的应用》*(2025年4月3日),https://www.whitehouse.gov/wp-content/uploads/2025/02/M-25-21-Accelerating-Federal-Use-of-AI-through-Innovation-Governance-and-Public-Trust.pdf
[^13]: 根据OMB M-25-22号备忘录第3(h)和4(d)(G)节,各机构同样应考虑要求供应商在将新的人工智能增强功能、特性或组件集成到合同项下的LLM时提供更新的披露。根据OMB M-25-22号备忘录第3(g)节的要求,最佳实践,包括由GSA开发的新的AI透明度条款和条件样本,将在可用时发布于共享资源库。
声明:本文来自那一片数据星辰,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
