陈海波:开源鸿蒙项目群技术指导委员会主席,上海交通大学特聘教授
摘要:本文围绕“大模型与Agent驱动下操作系统如何演进”这一问题展开讨论,提出智能时代基础软件面临的核心挑战,不是简单引入AI能力,而是在概率性智能成为系统内生组成后,重构传统建立在确定性假设之上的系统语义、验证方法、调度逻辑与可信边界。
本文首先从Prompt Engineering、Context Engineering到Harness Engineering的演进脉络出发,指出Agent正从应用层插件逐步渗透为系统层基本构造单元,大模型也从外部服务转向参与系统决策的内部角色。进一步地,本文以概率性输出为切口,分析其对正确性验证、失效恢复、性能预测和接口抽象带来的系统级冲击,认为研究操作系统的方法要从“还原论”走向“系统论”,需要在“概率性规划—约束概率执行1—可验证收敛”的框架下,构建一种新的确定性。
基于此,本文进一步讨论了智能时代基础软件开发范式从Vibe Coding向Spec Coding的迁移,指出软件工程重心正在从编码实现上移至意图定义、抽象设计与验证策略;同时分析了面向人类与Agent的接口悖论,以及韧性、安全、可靠性、安全性、可用性与隐私等可信维度在AI背景下的重构。
最后,本文提出面向智能世界的操作系统总体设想:操作系统将不再只是程序运行平台,而是面向模型、Agent/Skills、上下文与全场景协同的系统级底座,其核心特征可概括为模型原生、Agent原生、全场景原生与时空交互原生,且大模型也将在操作系统的构建过程中起到重要作用。本文的核心结论是:智能时代操作系统的关键任务,不是消除概率性,而是通过系统机制将其收敛到可管理、可验证、可信任的边界内,从而在模型的不确定性中构建新的系统确定性。
TL;DR
操作系统2的每一次重大演进,背后主要是计算范式的变化在倒逼系统核心机制的重构。从分时系统到虚拟内存,从微内核到容器化,变的是抽象方式,不变的是同一个问题:新的计算形态需要什么样的系统支撑?
大模型和Agent的涌现需要我们进一步回答这个问题。过去两年,Agent从概念验证快速走向工程化,大模型也从“被应用调用的外部服务”逐步演化为“参与系统决策的内部角色”。这个变化并不只发生在应用层,它已经开始触及调度策略、状态组织、权限边界、接口抽象与恢复机制。
更关键的是,当执行对象从确定性程序扩展为带有长期状态、工具调用和外部副作用的Agent时,问题就不再只是应用逻辑问题,而是执行语义、状态恢复、资源调度和全局治理的问题。如果这些能力仍然停留在应用框架或中间件层重复实现,系统将面临语义不统一、恢复不可复用[1]、治理难以收敛等问题。因此,至少其中一部分能力必须下沉为系统级原语,这正是操作系统需要演进的根本原因。
其中的根本矛盾在于:传统计算机系统的设计建立在确定性假设之上,给定输入产生确定输出,给定指令执行确定操作;而大模型天然具有概率性[2],其输出和推理过程都存在不确定性。当这样一个概率性系统成为操作系统的基本组成部分,原有的验证方法、安全模型和资源调度策略都需要重新思考。
这篇文章试图沿着“趋势→变化→范式→过程→接口→可信→畅想”的脉络,逐一讨论智能时代操作系统演进中的七个关键命题。
其中核心问题是:如何在概率性智能与确定性规则之间,找到可工程化的融合路径,以提供新的系统确定性?
一、趋势:Agent开始“渗透”操作系统的每一层
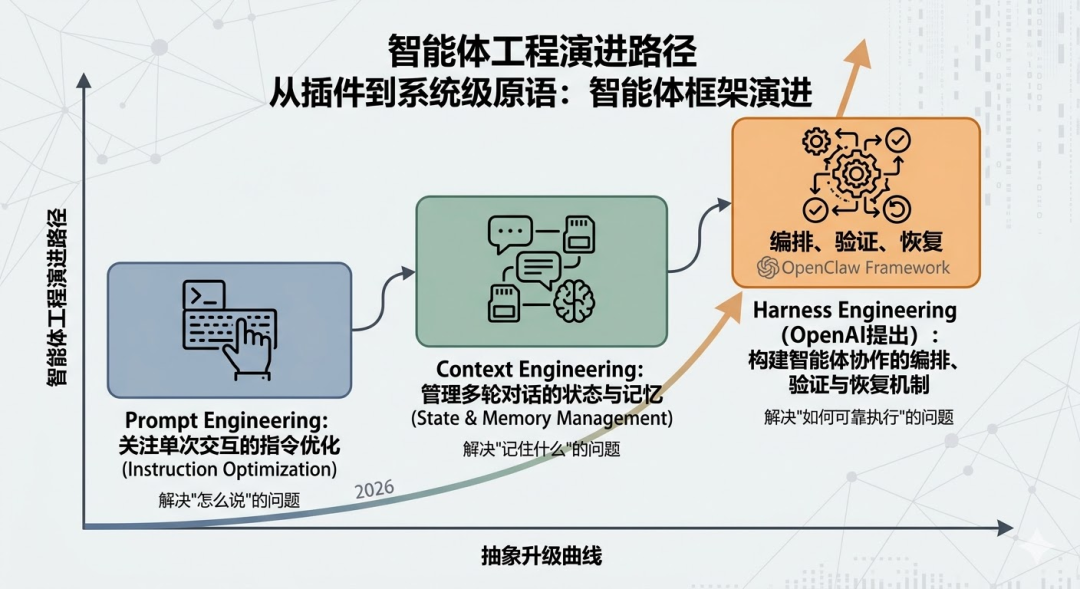
1.1 OpenClaw崛起背后的工程信号
2026年初,以OpenClaw为代表的Agent框架进入了快速迭代期。除了框架本身的功能演进,更值得关注的是整个工程范式在短时间内经历了三次明显的重心迁移。
提示词工程(Prompt Engineering)关注如何写好一条指令,让模型给出更准确的单次回答。随着应用场景复杂化,焦点很快转向了上下文工程(Context Engineering),核心问题变成了如何在多轮交互中管理好状态和记忆,让模型“记住”该记住的东西。近期,OpenAI提出的Harness Engineering把问题推到了更深的层次:当多个Agent需要协同完成任务时,编排、验证和故障恢复这些系统级的工程问题,成了绕不过去的核心挑战。
三次迁移指向同一个方向:从关注“单次交互的质量”到关注“系统级的可靠运行”。Agent已经不只是应用层的“插件”,它正在成为系统层面需要认真对待的基本构造单元。
1.2 关键推论:大模型正在成为新的系统原语
一个自然的推论就是:大模型正在从“被调用的外部服务”转变为“参与系统决策的内部角色”。
这对操作系统的影响是深层次的。传统操作系统通过系统调用(syscall)把硬件能力抽象成标准接口;类比来看,智能时代的操作系统可能需要一种类似的机制:“意图调用(intent-call)”,以将智能能力标准化。在这个前提下,操作系统的核心子系统都需要相应扩展:调度器除了管理CPU时间片,还得考虑Token预算和推理步数的分配;内存管理除了物理页框的分配回收,还要应对上下文窗口中注意力随长度衰减的问题;权限模型除了控制文件和设备访问,还需要约束Agent的知识边界和行为范围。
再进一步,如果Agent的核心能力可以概括为“理解意图、规划步骤、执行并验证”,那么操作系统为其提供的基础原语,也应当围绕意图表达、步骤编排和结果验证来设计。
二、变化:从确定性到概率性的系统语义迁移
2.1 从SQL Semantic Filter和Pick-and-Place案例说起
Snowflake的Cortex AI SQL提供了一个很好的观察切口[3]。传统SQL的WHERE子句是确定性的布尔表达式,查询结果完全由条件决定:
传统SQL:

而引入Semantic Filter之后,过滤条件可以用自然语言来描述(概念示意):

两段代码做的看似是同一件事,但底层语义发生了根本变化。前者是精确匹配,给定条件,结果唯一确定;后者是意图理解,“高价值”具体意味着什么取决于模型的推断,结果天然带有概率性。这不是一个孤立的功能创新——当越来越多的系统组件开始接受自然语言输入,确定性语义向概率性语义的迁移就成了系统层面不得不面对的趋势。
类似的语义迁移也在物理控制领域发生。以机械臂Pick-and-Place为例[12]:用户指令机械臂将粉色方块移至橙色碗左侧,并要求在抓取后的移动过程中避开其他物体以防碰撞损坏。传统API的执行流程是固定的(抓取-移动-释放),无法根据环境动态调整路径,导致避障失败率高达100%。若让LLM直接重写底层API,则因控制逻辑过于复杂而容易产生幻觉,失败率仍高达40%,且难以应对突发状况(如方块加重)。
Symphony API[12]的处理方式提供了另一种思路:它在“悬停”和“移动”阶段嵌入受控扩展点,仅向LLM暴露有限的能力接口(如位置调整),允许模型通过静态预设或动态运行时注入代码来修正路径。这种“确定性框架+概率性决策”的混合模式,将失败率降至20%,且当任务变难时能够动态扩展、实时感知风险并调整策略。
这表明,概率性语义的到来并非简单替换确定性接口,而是需要在系统层面重新设计“约束边界”:既要保留底层执行的确定性保障,又要为上层智能提供可控的决策空间。当越来越多的系统组件开始接受自然语言输入并需要与智能体协作时,确定性语义向概率性语义的迁移就成了系统层面不得不面对的问题。
2.2 概率性输出的系统级影响
但概率性带来三个重要挑战:
这种迁移改变的不只是查询结果的确定性,而是系统设计中几个最基础的假设。
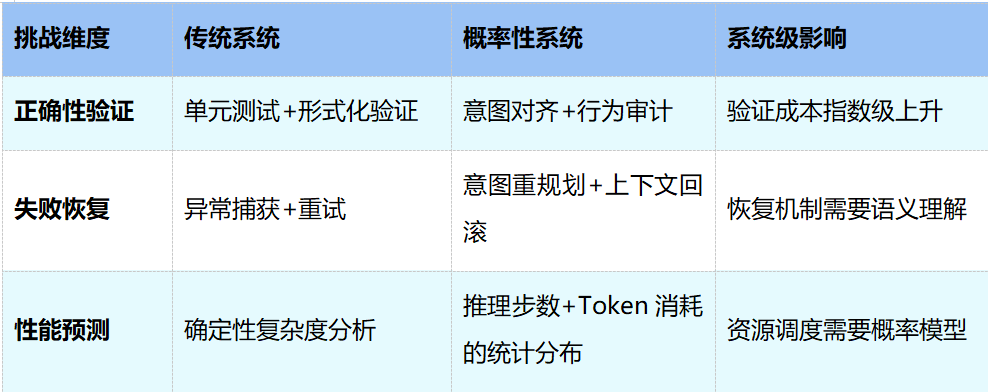
首先是正确性验证。传统系统靠单元测试和形式化验证就能确认“输出是否正确”,因为预期结果是确定的。但当输出具有概率性,“正确”本身就需要重新定义——验证的对象从“结果是否精确匹配”变成了“行为是否与意图对齐”,验证成本随之大幅上升。
其次是失败恢复。传统系统的错误处理思路比较直接:捕获异常,重试或回滚。但概率性系统的“失败”往往不是崩溃,而是“做了一件看似合理但偏离意图的事”。这种情况下简单重试没有意义,恢复机制需要能够重新理解意图、重新规划路径,甚至回滚到上下文中某个更早的可信状态。
第三是性能预测。传统系统可以通过算法复杂度分析给出确定性的性能预期,但概率性系统的资源消耗(如推理步数、Token用量)本身就服从统计分布,资源调度也需要从确定性模型转向概率模型。
2.3 核心矛盾:确定性框架能否约束概率性行为?
上面三个挑战归结到底,指向同一个问题:我们现有的验证体系是为确定性系统设计的,是否可以拿它来直接约束概率性的智能行为?
简单而言,直接套用应该是行不通的。这迫使我们重新审视“正确性”的定义:不再是“输出与预期完全一致”,而是“行为与意图在可接受的偏差范围内对齐”。随之而来的一个问题是:如果系统允许概率性输出,那“测试通过”的标准应该怎么定?传统的预期值断言不再适用,我们需要一套新的质量门禁体系来应对这个变化。
三、范式变革:还原论的边界与系统论的回归
3.1 还原论在智能系统中的局限性
传统软件工程的方法论根基是还原论:把复杂系统拆成模块,定义好每个模块的接口契约,通过组合来构建整体,局部的组合就等于全部。过去几十年这套方法非常成功,复杂的系统被拆解、分析并还原为更小的、更基础的部分来观测和管理。但它有一个隐含前提:每个模块的行为是可预测的,接口的语义是可以形式化描述的。
在智能系统中,这两个前提都开始松动[4]。一方面,模块的输入输出越来越多的涉及自然语言和语义理解,形式化的接口契约很难完整捕捉“意图”这种模糊的东西。另一方面,Agent的行为空间随上下文呈指数级膨胀,穷举测试变得不现实。更棘手的是,当多个Agent协同工作时,还可能涌现出设计阶段完全未预料到的交互模式,而涌现行为恰恰是还原论最难处理的对象:你无法仅通过分析局部来预测整体。
3.2 思考:采取系统论的方法,不消除概率性,而是收敛它
既然还原论在这里碰了壁,出路在哪里?
20世纪70年代末,著名科学家钱学森先生基于对复杂系统的研究,提出把还原论方法和整体论方法结合起来,形成系统论方法[5]。还原论方法采取了自上而下、由整体分解到部分的研究途径;整体论方法是不分解,从整体到整体;而系统论方法既从整体到部分由上而下,又自下而上由部分到整体。这对研究面向智能世界的操作系统具有非常重要的指导意义。
传统基于还原论的思想的直觉反应是试图“消除概率性”,想办法把大模型的输出变成确定的。但这不现实:概率性是大模型的本质特征,消除它等于废掉了模型本身的能力。更务实的思路是反过来想:不消除概率性,而是通过系统机制把它收敛到可管理的确定性边界内。
这个思路能成立,依赖三个条件。第一,大模型单次输出的概率性是客观事实,不可消除。第二,系统可以通过多重机制约束Agent的行为空间,这部分是可工程化的。第三,用户并不要求系统百分之百确定——在边界明确的前提下,他们能够接受一定程度的不确定性。三者结合,指向一个可行的架构方向:用概率性规划来生成方案,用确定性机制来执行关键操作,再用可验证的收敛条件来保证结果不跑偏。这就是“新确定性”的含义:不是回到旧的确定性,而是在系统层面为概率性建立可控的边界。
总结而言,通过“概率性规划+约束概率执行+可验证收敛”的三层架构,可以构建用户可信任的智能系统。
3.3 评估指标的重构
为此,衡量系统好坏的标准也得随之改变。传统的“功能覆盖率”假设存在确定性的预期输出,拿来衡量概率性系统意义有限。取而代之的,至少有三个维度值得关注:输出与用户真实需求的匹配程度,可以称之为意图对齐度;错误发生后系统自我修正的能力,即失效可恢复性;以及系统能否清晰地告诉用户“我能做什么、不能做什么”,也就是边界可解释性。三个维度本质上都在衡量同一件事:系统在多大程度上做到了“概率性可控”。
四、重构基础软件开发:从Vibe Coding到Spec Coding
4.1 Chris Lattner对CCC的深度拆解
2026年2月,Anthropic用Claude Code生成了一个C编译器(CCC),在业界引发了不小的讨论[6]。LLVM之父Chris Lattner对这个项目做了详细评估,他的判断可以从两面来看[7]。
一面是能力验证。在结构清晰、规则明确、可验证的场景中,AI已经能够系统化地复刻工程共识,高效完成代码实现,基础编码和跨平台转译的成本被显著压低了。另一面是能力边界。CCC的优化目标明显偏向“通过测试用例”,在泛化能力、错误恢复和复杂开放场景的处理上都有明显短板,性能表现与手工优化之间的差距更是达到了数量级。
4.2 性能数据背后的根本原因
独立测试的数据让这个差距更加具体[8]。CCC与GCC相比,编译速度慢1.3倍,二进制体积大3倍,这两项差距尚可接受。但到了运行时性能,差距急剧拉大:简单场景下慢737倍,复杂查询场景下慢158,000倍。更值得注意的是,CCC声称支持的-O2优化实际上并未生效,优化通道根本没有正确集成到编译流水线中。
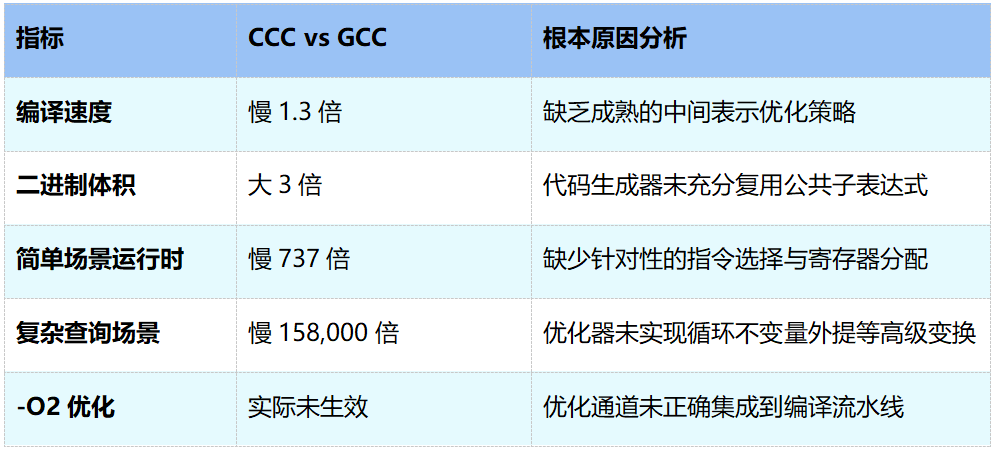
逐项分析这些差距的成因,指向的都不是“AI写不出代码”这个层面的问题。编译速度慢是因为缺乏成熟的中间表示优化策略,体积大是因为代码生成器没有充分复用公共子表达式,运行时慢则是因为缺少针对性的指令选择、寄存器分配以及循环不变量外提等高级优化。归结起来,性能差距的本质在于:当前AI缺乏对性能与正确性之间权衡关系的系统性理解。这种理解目前仍然依赖人类架构师来提供:由他们定义优化目标和约束边界,AI在这个框架内执行。
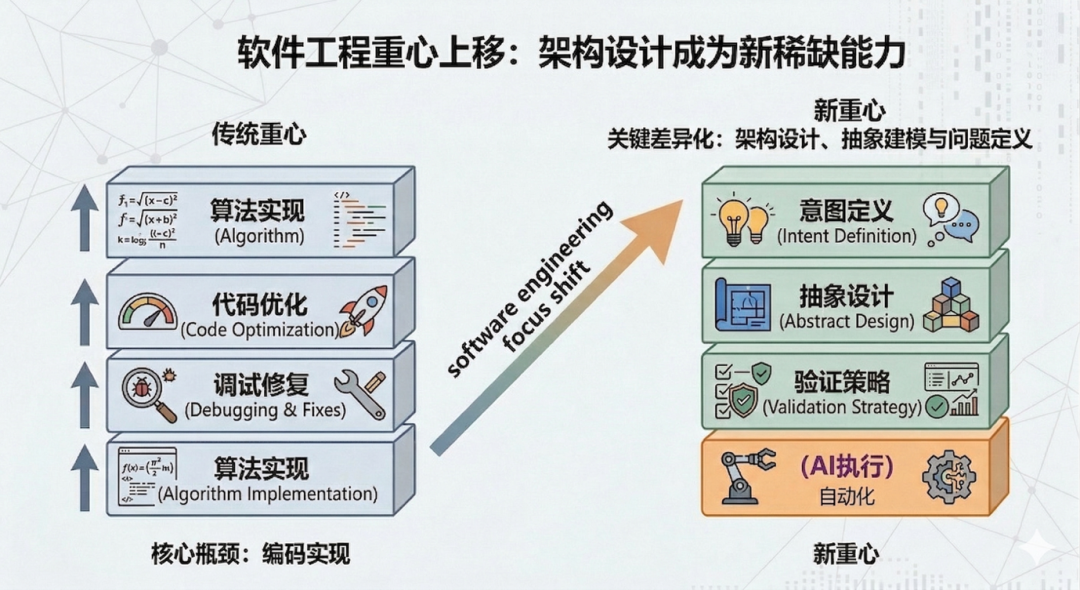
4.3 软件工程的重心上移
CCC的案例揭示了一个正在发生的转变:编码实现作为软件工程核心瓶颈的位置在减弱。当AI能够在明确约束下高效生成代码时,真正稀缺的能力逐步上移到了架构设计、抽象建模和问题定义。过去软件工程的重心沿着“算法实现→代码优化→调试修复”展开,而现在正在变成“意图定义→抽象设计→验证策略”,编码执行本身越来越多地可以交给AI来完成。
4.4 “三重门禁”质量保障体系
但AI执行不意味着人可以放手不管。参考Modular团队的实践经验,一个务实的协作框架应该包含三重质量门禁。
第一重是AI生成配合自动化回归测试:让AI快速迭代原型代码,同时用自动化测试覆盖边界条件和异常路径,确保基本功能正确。
第二重是形式化规约配合静态分析:用机器可验证的方式描述接口契约,自动检查关键不变量,把一部分人工审核的负担转移给工具。
第三重是人工评审配合架构审计:对核心设计决策:比如IR的选择、优化策略的取舍、性能目标与兼容性之间的平衡,由人做最终确认。
三重门禁层层递进,前两重把例行检查自动化,第三重聚焦在真正需要人类判断力的地方。
4.5 SpecFS的启示:从Vibe Coding到Spec Coding
上海交通大学IPADS团队的SysSPEC/SpecFS生成式文件系统项目[9]提供了一个值得关注的方向。开发者仅需对文件系统进行设计,用高层次的规约(Specification)来定义系统的行为,并依赖大语言模型(LLM)根据规约来完成底层系统代码的自动生成。这背后的逻辑很清楚:规约语言比自然语言更精确,但比代码更抽象,恰好处在一个适合人机协作的中间层。大模型擅长的是“从规约到实现”的映射:给定明确的约束和接口描述,生成符合要求的代码,而不是“从模糊意图到完整实现”的端到端跳跃。此外,规约本身还可以充当系统文档,降低后续维护的成本。
因此,该研究的效果也比较明显:实际测试结果表明,完全由SysSpec生成的SpecFS在数百项回归测试中,达到了与人类手写的基准系统一致的正确性。同时,新范式下规约的代码量显著少于底层C代码量,显著提升开发效率(3-5×)。成果也同时获得了FAST 2026的Erik Riedel最佳论文奖以及杰出技术成果奖。
这引出一个有用的区分:Vibe Coding(凭感觉写代码)适合探索阶段,Spec Coding(基于规约编码)适合生产系统。两者之间的分界线在哪里,正是我们作为架构师需要做出的判断:哪些部分需要严格定义“做什么”,哪些部分可以交给AI自行决定“怎么做”。
五、接口悖论:当人类友好的设计成为机器的负担
5.1 Lampson论据的重新审视
“Defining interfaces (abstractions) is the most important part of system design.”--图灵奖得主Butler Lampson[10]
四十多年后,这个判断不但没有过时,反而在智能时代获得了新的紧迫性。只不过问题的内涵变了:过去,接口设计的核心挑战是“如何让人类理解和使用”;而当Agent成为系统的重要使用者之后,挑战变成了“如何让人类与Agent都能高效地理解和使用”。两者的认知方式截然不同,这就产生了真正的矛盾。
5.2 接口悖论:大模型时代的接口定义
这个矛盾可以更精确地描述[11]:
1. 人类擅长视觉模式识别,能维持长时间的注意力,善于在模糊上下文中做推理,但语法记忆有限,容易受认知负荷影响。
2. LLM的认知特征几乎是反过来的:它擅长语义模式匹配和结构化信息处理,但注意力随上下文长度衰减(即“lost in the middle”现象[15]),面对深层嵌套结构时解析能力显著下降。
悖论就出在这里:长期以来我们为人类优化的那些接口特征:嵌套菜单、丰富的视觉反馈、灵活的交互路径,恰恰是Agent解析时的噪声和负担。对人越友好的设计,对机器可能越不友好[11]。
5.3 MCP遇冷与CLI复兴
这不是纯理论推演,它正在解释眼下发生的事情。
MCP(Model Context Protocol)的设计初衷是好的——用结构化的JSON传递丰富上下文,让模型获得充分的信息来做决策。但实践中,深层嵌套的JSON结构导致模型注意力分散,关键信息被次要细节淹没,效果反而打了折扣。与此形成对比的是CLI在Agent场景中的价值回归。命令行接口的优势在智能时代突然变得非常契合:扁平的结构、明确的语义、天然的可组合性,恰好匹配LLM线性推理加模式匹配的认知偏好。
这给接口设计带来一个反直觉的启示:为Agent设计接口时,应该优先保证语义密度和结构扁平,而不是追求视觉丰富和交互灵活。
5.4 Agent原生接口的设计范式
基于以上分析,Agent原生的接口设计应该遵循几个基本原则。首先是意图显式化:用结构化字段替代隐式约定,尽可能减少模型需要“猜”的东西。其次是错误可恢复:每个操作都提供标准化的撤销或重试路径,因为概率性系统出错是常态而非例外。第三是状态可查询:Agent需要能主动获取执行进度和中间结果,而不是只能被动等待最终返回。第四是能力可发现:通过机器可读的元数据描述接口的能力边界,让Agent知道自己能调什么、不能调什么。
用一个具体的JSON对比来说明。下面是一种人类友好但对机器负担较重的设计,意图藏在嵌套结构里:

而Agent友好的设计会把意图摊平,上下文用引用代替内嵌:

两者传递的信息量相当,但后者结构更扁平、语义更显式,Agent解析的认知负担明显更低。
为此,我们也尝试设计了大模型友好的接口设计,通过声明式接口[11]与可控扩展接口[12]来极大提升模型在GUI Agent等任务的准确率并降低Token使用。
六、可信关键要素的AI时代重构
传统系统的可信性通常从以下维度来衡量[13]:韧性(Resilience)、信息安全(Security)、可靠性(Reliability)、功能安全(Safety)、可用性(Availability)和隐私(Privacy)。这些维度在智能时代并没有失去意义,相反,每一个都需要在概率性系统的新背景下重新审视。
6.1 Resilience:失效模式的根本变化
传统系统的失效是比较“诚实”的:要么崩溃,要么报错,系统会明确告诉你出了问题。但Agent的失效往往更隐蔽:它可能不会崩溃,而是给出一个看似合理但实际偏离意图的输出。这种静默偏离比显式崩溃更危险,因为它可能在很长时间内不被发现。应对这种新的失效模式,需要建立“意图-行为-结果”的三重校验链:不仅检查操作是否完成,还要验证结果是否与原始意图对齐,并在偏离时支持语义级别的回滚。
6.2 Security:新型攻击面
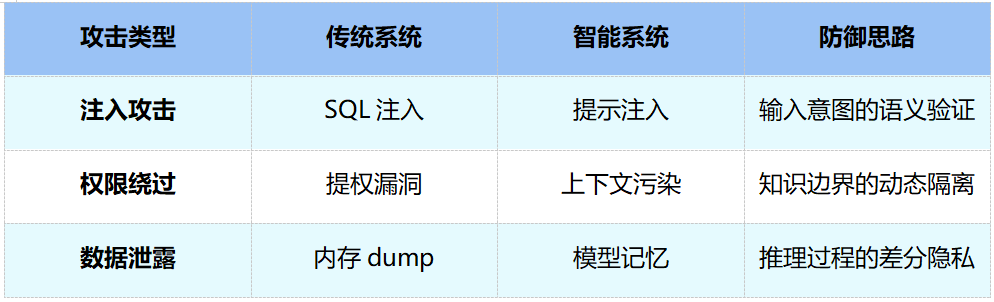
安全领域的变化尤为显著。传统系统面对的是SQL注入、提权漏洞、内存dump等攻击手段,防御思路已经相对成熟。但智能系统引入了一组全新的攻击面:提示注入取代了SQL注入,攻击者通过精心构造的自然语言输入来劫持模型行为;上下文污染[14]取代了传统提权,通过向模型的上下文中注入误导性信息来绕过知识边界;模型记忆带来的数据泄露风险也不同于传统的内存泄露:攻击者可能通过成员推断攻击从模型中还原训练数据。这些新攻击的共同特点是发生在语义层面而非代码层面,防御手段也需要从语法检查转向语义验证。
6.3 Reliability:从“功能正确”到“意图对齐”
可靠性的定义同样在漂移。传统系统的验证逻辑很直接:assert (output == expected),输出和预期值精确匹配就算通过。但对概率性系统来说,这种断言方式不再适用,验证逻辑需要变成类似 assert (intent_alignment(output, user_intent) > threshold) 的形式,也就是判断输出与用户意图的对齐程度是否超过某个可接受的阈值。这里的关键难题在于:如何形式化地描述“意图”本身?自然语言太模糊,形式化语言又难以捕捉意图的全部内涵。一个可能的方向是引入人类反馈强化学习(RLHF)作为验证信号,但这条路还远未走通。此外,我们还需要重新定义一致的恢复语义。
6.4 Safety:防止目标蠕变
Agent的自主性带来了一种传统系统不太需要担心的风险:目标蠕变(goal drift)。当系统可以主动规划并执行多步操作时,每一步的微小偏差都可能累积,最终导致实际行为与原始目标渐行渐远。应对这个问题需要多层防线:关键操作(如资金转账、系统配置变更)设置硬边界,必须经过人类确认;一般操作通过奖励函数设置软边界,约束Agent的探索空间不至于发散;同时建立熔断机制,当系统检测到异常行为模式时自动降级为确定性模式,宁可牺牲灵活性也要保住安全底线。
6.5 Availability:Token经济下的服务连续性
最近在一场关于Agent Infra的访谈里[1],Jeff Dean提出了一个非常关键的判断:AI Workload并不是传统计算负载的简单延伸,过去那套建立在确定性程序之上的可用性前提,正在被新的执行语义和物理约束改写。一次推理可能就要绑定大量紧耦合芯片,Attention state很大,上下文切换和跨节点调度都非常昂贵,因此系统追求的仍然是延迟、可靠性、扩展性和成本,但这些目标已经不能再沿用传统request/response模型的平衡方式。
这放到智能系统里,最直接带来的变化就是:可用性开始拥有一个新的核心维度:Token 成本。传统系统的CPU、内存、带宽虽然也需要精细管理,但总体上更可预测、可切分;而智能系统的核心资源是推理Token、上下文窗口和模型算力,它们的消耗会随着任务复杂度、上下文长度和推理链路深度快速膨胀,往往难以提前精确估算。一个长上下文任务即使服务没有宕机,也可能因为Token消耗失控、推理路径过深或资源调度不当而陷入“技术上在线、业务上不可用”的状态。
因此,智能时代的Availability不能再只定义为“服务是否在线”或“接口是否返回”,而必须扩展为:系统能否在可接受的Token与算力预算内,持续把任务推进到一个足够好的结果。换句话说,衡量标准不再只是uptime,而是“任务完成度与Token 消耗”的综合效用比。系统需要根据任务阶段、上下文价值和结果收益,动态调整推理深度、模型规模和执行路径,在“结果足够好”和“资源消耗可控”之间持续寻找最优平衡。最终,真正的服务连续性,不是无限制地把任务跑到底,而是让系统始终能够以可控成本、可恢复状态和可接受质量,把智能任务稳定推进下去。
6.6 Privacy:模型记忆与推理泄露
隐私问题在智能系统中呈现出两个新的风险面。一是训练数据泄露:通过成员推断攻击,攻击者有可能从模型的响应中还原出训练集中的敏感样本。二是推理过程泄露:模型的中间激活值可能间接暴露用户的查询意图,即便最终输出经过了脱敏处理。应对这些问题可能需要联邦学习、同态加密与推理结果脱敏等多种技术的组合,单一手段很难同时兼顾隐私保护和模型可用性。
以上六个维度的共同趋势是:可信性在智能时代不是被削弱了,而是被强化了。因为概率性系统的不确定性使得每个维度的失效后果都可能被放大。一个安全漏洞可能因为模型的自主行为而扩散得更快,一个可靠性缺陷可能因为静默偏离而更晚被发现。智能时代需要从架构设计、流程等多个维度重新思考操作系统的可信性。
七、畅想:智能时代操作系统的特征
前面六章分别讨论了趋势、变化、范式、开发过程、接口和可信性。基于这些分析,我们尝试勾勒智能时代操作系统可能呈现的面貌。
智能世界OS不再只是“程序运行平台”,而将演进为一个面向Agent、模型、技能、上下文的系统级底座。它既要支持个体智能的运行,也要支持群体智能的协同;既要承载概率性的规划过程,也要在关键路径上提供确定性的执行保障;既要保证服务在线,更要保证智能任务在成本、质量和安全约束下持续推进。这些变化共同决定了智能世界OS的基本形态。
7.1 应用形态:从单体应用到Agent + Skills + Context
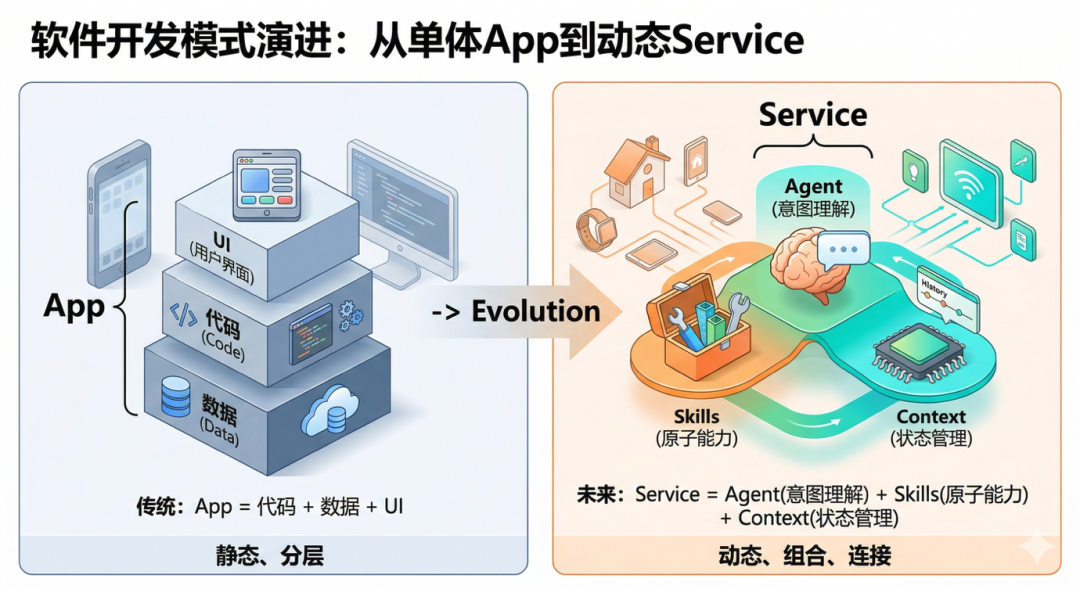
传统应用通常由代码、数据和UI打包成相对固定的整体,功能边界清晰,调用关系静态。而在智能时代,应用将逐步从“固定功能集合”演化为Agent、Skills 与 Context的动态组合体。
其中,Skills是可注册、可发现、可组合的原子能力,例如读取文件、调用API、执行搜索、生成摘要、提交审批、控制设备等,也将成为一种新的Library甚至App[16];Agent不再只是单一功能模块,而是承载用户意图、进行任务规划、选择技能、编排执行流程并处理中间结果的自治执行体;Context则提供任务所需的状态、记忆、权限边界和环境信息,决定智能执行能否连续、个性化且可恢复。
在这种形态下,操作系统需要管理的对象不再只是进程、线程和服务,而是进一步扩展到Skills、Agents、Contexts及其相互关系。OS需要承担Skills的注册发现、调用治理、权限控制、资源配额和沙箱隔离,同时维护Agent的生命周期和上下文连续性。换言之,未来的应用形态将不再局限于静态的 App,而是演变为由操作系统动态编排的智能能力网络。当然,传统App并不会因此消亡,它们在处理确定性任务上仍具核心价值,并将作为底层基础设施,赋能 Agent/Skills等新形态实现与确定性世界的有效执行。
7.2 接口设计:面向人与Agent的双模抽象
第五章讨论的接口悖论在这里有了实践层面的回应:
传统OS接口的主要服务对象是人类用户和开发者:前者通过图形界面、命令行或触控完成操作,后者通过系统API调用底层能力。但在智能世界OS中,接口需要同时面向两类主体:人类与Agent。
面向人类,系统仍需保留图形界面、语音、自然语言、多模态交互等传统入口,因为意图表达、价值判断和关键授权仍由人主导;面向Agent,则需要提供结构化、扁平化、机器可读、语义明确的系统接口,使其能够安全、高效地调用工具、访问资源、推进任务。
更重要的是,这两类接口并不是平行割裂的,而是由统一的协同机制打通:人类负责定义目标与约束,Agent负责分解任务与执行流程,人类在关键节点进行审核、接管和确认。这种“人类主导意图,Agent主导执行”的混合工作流,很可能成为智能时代最基础的交互范式。对应到OS层面,接口设计的重点将从“事件驱动的交互响应”转向“意图驱动的协同闭环”。
7.3 执行机制:概率性与确定性规划及执行的混合调度
这是第三章“新确定性”思想在系统架构中的具体落地。智能时代最核心的系统变化之一,是执行对象从确定性程序转向概率性Agent。传统OS默认程序逻辑是预定义且可重复的,因此调度重点在于CPU、内存、存储和网络资源的高效分配;而智能世界OS需要面对的是另一种执行结构:上层规划具有概率性,下层执行必须保持确定性。
具体来说,上层由大模型或Agent Runtime负责根据用户意图生成任务计划、比较不同执行方案、评估风险并动态调整路径;下层则由系统执行层负责对关键动作进行验证、资源调度、权限控制和异常处置,确保涉及外部副作用、关键数据和高价值动作的路径是可验证、可约束、可回滚的。
因此,智能世界OS的调度不再只是“时间片调度”或“资源调度”,而是演化为一种混合调度体系:允许上层保持探索性和灵活性,同时在下层用确定性执行框架兜住可用性与安全性。换句话说,系统需要接受“规划不确定”,但不能接受“关键动作不可控”。
7.4 安全架构:Harness Engineering驱动的失效隔离
智能世界OS的安全问题,已经不再只是传统的访问控制、内存隔离和进程保护,而是扩展到Agent的推理路径、工具调用、外部副作用和决策可信性。这里可以借鉴OpenAI提出的Harness Engineering理念,把安全架构从“防入侵”升级为“控行为”。
一个可行的系统级安全框架至少需要包括四类能力。
第一,隔离。每个Agent、每类Skill、每次高风险调用都运行在明确的沙箱边界内,权限最小化,资源配额可控。
第二,监控。系统持续追踪Agent的推理过程、Token消耗、工具调用链路、行为模式和异常偏移,而不是只监控CPU或网络指标。
第三,恢复。一旦发现错误规划、异常行为或高风险输出,系统能够回滚到最近的可验证状态,而不是任由错误继续放大。
第四,审计。所有关键决策、调用链、授权记录和外部动作都需要可追溯、可解释、可复盘,为事后治理、责任归属和监管合规提供依据。
因此,未来OS的安全能力不再只是保护“程序怎么运行”,更要保护“Agent为什么这样行动,以及出了问题如何收敛”。
7.5 经济模型:Token效用的优化
传统操作系统主要关注性能、吞吐、延迟和资源利用率,经济性虽然重要,但通常不是一等系统目标。进入智能时代后,这一前提将被打破。因为AI系统的核心资源不再只是CPU、内存和带宽,还包括推理Token、上下文窗口、模型调用次数以及异构算力占用。这些资源昂贵、波动大,而且与任务结果高度相关。
这意味着,可用性的定义本身也发生了变化。系统不再只是保证服务在线,而要保证任务能够在可接受的Token与算力预算内推进到足够好的结果。一个长上下文任务即使没有宕机,也可能因为Token持续膨胀、推理链路过深或调度策略不当,陷入“技术上在线、业务上不可用”的状态。
因此,智能世界OS必须具备面向Token效用的系统优化能力:根据任务阶段、上下文价值、结果收益和模型成本,动态调整推理深度、上下文保留、模型规模和执行路径,在“结果足够好”与“成本可控”之间找到最优平衡。围绕这一目标,投机推理、缓存复用、早停机制、本地优先、模型路由和端云协同调度,都会成为OS层面的基础设施,而不再只是应用层优化技巧。
7.6 构建模式:形式化Spec引导的迭代生成
第四章讨论的Spec Coding理念在这里延伸为系统级的构建模式。传统流程通常是“需求—设计—编码—测试—部署”的线性链条,而未来更可能演进为一个围绕Spec展开的闭环:形式化Spec → AI生成 → 自动验证 → 人工审计 → 持续演进。
在这个过程中,Spec不再只是文档,而是兼具“意图表达、系统约束、自动验证依据”的可执行描述。AI负责从Spec到实现的快速映射,人类负责从业务目标到系统约束的抽象与决策,验证环节尽可能自动化,而人工审计聚焦于高风险、高价值、架构级的关键节点。
对应到OS层面,这意味着基础软件不仅要支持程序运行,还要支持持续生成、持续验证、持续审计的新型软件生命周期。操作系统将不只是承接运行态,还会更深地参与构建态、演进态和治理态。
7.7 核心特征总结:四个“原生”
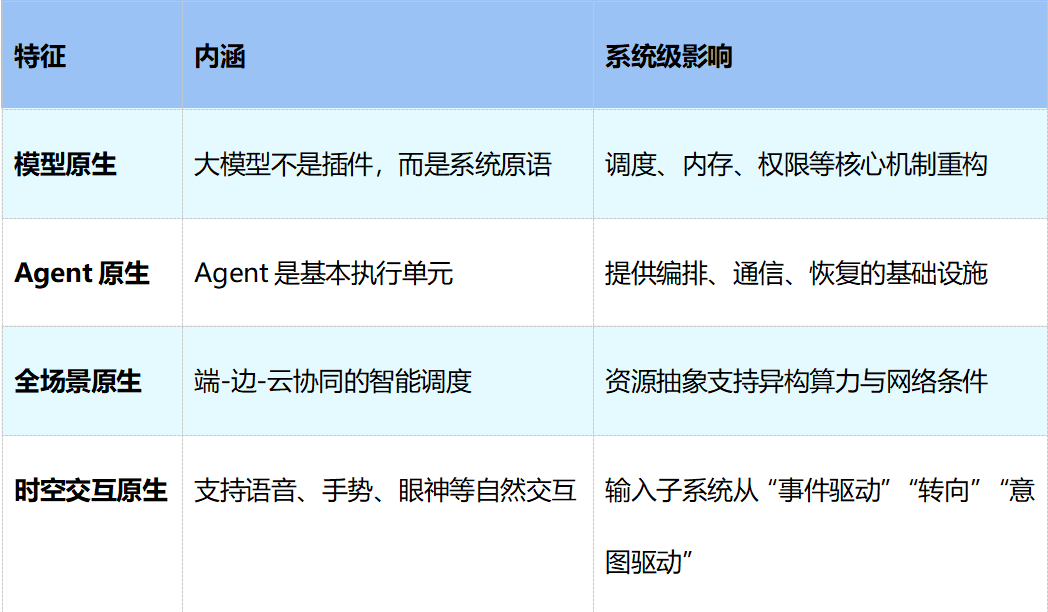
把以上六个方面提炼一下,可以归纳为四个“原生”特征:
1、模型原生[17]:在传统系统中,模型只是外挂能力,属于应用层按需调用的组件;而在智能世界OS中,大模型将成为系统级基础原语。无论是任务规划、上下文理解、资源调度,还是权限判定、风险评估与执行优化,都需要围绕模型能力进行重构。
这意味着,模型不再只是一个被调用的服务,而是深度参与操作系统的调度、记忆、接口和治理机制。系统管理的核心对象,也将从单纯的CPU、内存和存储,扩展到Token、上下文窗口、模型能力和推理路径。
因此,模型原生的本质,不是“系统里集成了AI”,而是系统开始以模型为基础重构自己的控制逻辑和资源逻辑。
2、Agent原生:传统OS的基本执行单元是进程和线程,而智能世界OS的基本执行单元将逐步演进为Agent。
Agent不只是一个更复杂的应用,而是一个能够感知上下文、理解意图、编排Skills、调用工具并持续执行任务的自治Agent。它具有长期状态、动态规划能力和外部副作用,因此不能再简单套用传统进程模型来管理。
这要求OS为Agent提供原生的生命周期管理、通信机制、恢复能力、权限边界和协同框架。换句话说,未来操作系统不只是运行应用,而是要组织和治理大量自治执行体,使个体智能进一步演化为群体智能。
因此,Agent原生的本质,是把Agent而非程序,作为系统设计的第一对象。
3、全场景原生:传统操作系统的边界通常局限于单机、单设备或某一类终端,而智能世界OS的天然边界将是端、边、云协同的全场景环境。
未来的智能任务不再停留在单一设备或单一界面中,而是持续跨越手机、PC、可穿戴设备、车机、机器人、边缘节点和云端模型服务,在不同网络条件、不同算力条件和不同交互场景之间连续流转。
这意味着OS需要具备异构算力调度、上下文跨端延续、端云协同推理和全局状态同步等能力,真正实现“设备切换但任务不断、场景变化但智能连续”。
因此,全场景原生的本质,是把智能系统的运行边界从单点设备扩展为整个现实场景网络。
4、时空交互原生:传统操作系统的交互逻辑主要基于键盘、鼠标、触控等事件驱动方式,用户通过显式输入一步步驱动程序运行;而在智能世界OS中,交互将逐步从事件驱动转向意图驱动,从单模态转向多模态,从单点界面转向跨场景协同。
语音、视觉、手势、文本、眼神、位置、环境状态等都将成为系统理解用户意图的重要信号。系统不再等待用户逐步点击,而是主动结合上下文理解目标、规划动作,并在人机协同中完成任务。
因此,交互系统不再只是UI层的体验问题,而将成为OS的基础能力之一:它既连接用户意图,也连接Agent执行,还承担关键节点的确认、接管和反馈。
因此,时空交互原生的本质,是 让操作系统从“响应输入”演进为“理解意图、协同执行、贯穿场景”的交互中枢。
结语:在不确定性中构建新的确定性
从Agent渗透操作系统的趋势出发,到概率性语义对系统设计的冲击,到还原论范式的局限与“新确定性”的提出,再到Spec Coding对开发流程的重塑、接口悖论的揭示与破解、可信六要素的重新审视,最后落到智能时代操作系统四个“原生”特征的展望——贯穿始终的核心判断只有一个:智能时代的操作系统,不是要消除概率性,而是要通过系统机制将概率性收敛到可管理、可验证、可信任的边界内。
对于我们来说,这个判断至少有三层实践含义。
第一,拥抱“人类主导、AI执行”甚至“AI主导、人类定义与监督”的协作范式,把精力聚焦在意图定义、抽象设计和验证策略上,而不是全部陷在编码细节里。
第二,把“可验证的智能”当作基础设施来建设:形式化规约、自动化回归、人工审计的三重门禁,逐步推动应成为我们的标准实践。
第三,警惕“智能放大缺陷”的风险:AI在加速正确模式传播的同时,也可能加速错误模式的扩散,架构师需要比以往更严格地定义质量边界。
当然,许多根本性的问题仍然是开放的。如何形式化描述“用户意图”,使其既能被人类理解又能被机器验证?概率性规划与确定性执行的混合调度,是否存在理论上最优的收敛条件?当多个Agent协作时,怎样避免集体幻觉和目标蠕变?这些问题的答案,将在很大程度上决定下一代操作系统的面貌。
回到一个更长远的视角来看:操作系统的每一次重大演进,都伴随着抽象层的重构。从进程抽象到对象抽象,从服务抽象到今天正在浮现的“意图抽象”,变化的是抽象的对象,不变的是抽象本身的使命:不是隐藏复杂性,而是重新组织复杂性,使其在新的约束下变得可管理。智能时代带来的不确定性不是终点,而是下一轮系统创新的起点。
而这一轮的关键在于:我们能否构建出既拥抱概率性智能,又坚守确定性边界的新一代操作系统?
致谢:本文图片由大模型生成,文字也得到了大模型的修订和打磨。感谢董明凯、钱梽杨、丁天虹、胡欣蔚、贾宁、张沫等同事的修改和宝贵意见。
1.确定性执行+概率性融合执行,确定性作为边界约束概率性探索空间。
2.这里的操作系统是指广义上的操作系统乃至基础软件,而非仅仅内核、驱动与系统服务。
参考文献
[1]. 对话 Google 首席 Jeff Dean:概率性执行的 Agent 时代,Infra 必须重塑!https://zhuanlan.zhihu.com/p/2016034154123392293
[2]. 对当前人工智能热潮的几点冷思考. 梅宏. 中国计算机学会通讯, 2024.9.
[3]. Introducing Cortex AISQL: Reimagining SQL into AI Query Language for Multimodal Data.https://www.snowflake.com/en/blog/ai-sql-query-language/
[4]. 软件开发范式的变革. 王怀民. 中国计算机学会通讯, 2022年2月.
[5]. 钱学森论系统科学. 科学出版社. 2011年12月.
[6]. Building a C compiler with a team of parallel Claudes. https://www.anthropic.com/engineering/building-c-compiler
[7]. Chris Lattner: The Claude C Compiler: What It Reveals About the Future of Software.
[8]. CCC vs GCC. https://harshanu.space/en/tech/ccc-vs-gcc/
[9]. Sharpen the Spec, Cut the Code: A Case for Generative File System with SYSSPEC. Qingyuan Liu, Mo Zou, Hengbin Zhang, Dong Du, Yubin Xia, Haibo Chen.USENIX FAST 2026.
[10]. Hints for computer system design. Butler W. Lampson. SOSP 1983.
[11]. From Imperative to Declarative: Towards LLM-friendly OS Interfaces for Boosted Computer-Use Agents. Yuan Wang, Mingyu Li, Haibo Chen.ACM EuroSys 2026.
[12]. Towards Large Language Model-Friendly APIs. Yuan Wang, Zhenyuan Yang, Zhanbo Wang, Mingyu Li, Zhilin Wu, Haibo Chen. ACM SIGOPS Operating System Review, 2025.
[13]. HarmonyOS NEXT 安全技术白皮书. https://consumer.huawei.com/content/dam/huawei-cbg-site/cn/mkt/privacy/privary-new/250610/down/HarmonyOS%20NEXT%E5%AE%89%E5%85%A8%E6%8A%80%E6%9C%AF%E7%99%BD%E7%9A%AE%E4%B9%A6.pdf.2024-08-13.
[14]. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. In Proceedings of the 16th ACM workshop on artificial intelligence and security. 79–90
[15]. Lost in the middle: How language models use long contexts. Liu, Nelson F and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Transactions of the association for computational linguistics. 2024.
[16]. Skills Are the New Apps– Now It’s Time for Skill OS. Le Chen ,Zichang Wang,Wenxin Zheng,Erhu Feng,Dong Du,Yubin Xia,Haibo Chen. https://www.preprints.org/manuscript/202602.1096.
[17]. 模型原生操作系统的一些思考. 陈海波等:中国计算机学会通讯, 2025.1.
声明:本文来自OpenHarmony TSC,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
