基本信息
原文标题:AI Security in the Foundation Model Era: A Comprehensive Survey from a Unified Perspective
原文作者:Zhenyi Wang, Siyu Luan
作者单位:University of Central Florida(王振宇),University of Copenhagen(栾思宇)
关键词:AI安全、基础模型、对抗攻击、数据投毒、隐私泄露、模型窃取、统一分类框架
原文链接:https://openreview.net/forum?id=1g7pKgClZs
开源代码:暂无
论文要点
论文简介:人工智能安全是当前学术界与工业界共同关注的核心议题,而随着大型语言模型、扩散模型、多模态模型等基础模型的崛起,这一领域正在经历前所未有的范式变革。然而,现有的AI安全研究呈现出高度碎片化的状态:攻击研究和防御研究各自为营,不同攻击类型之间缺乏系统性的联系与比较框架,研究者往往难以在宏观视野下把握整个威胁格局。
本文由来自中佛罗里达大学和哥本哈根大学的研究团队联合撰写,发表于Transactions on Machine Learning Research(2026年1月)。论文提出了一套全新的统一闭环威胁分类体系,以数据(Data)和模型(Model)两个核心要素为轴心,将AI安全威胁划分为四个方向性维度,首次从系统层面厘清了各类攻击的内在逻辑与相互依存关系。研究涵盖从传统机器学习到现代基础模型的全谱系威胁,并辅以医学图像分类场景下的实证评估,为AI安全领域提供了一份具有重要参考价值的综合性路线图。
研究目的:这项研究的根本目标是打破AI安全领域中"各自为政"的研究格局,构建一个能够统一描述、比较和分析各类AI威胁的理论框架。具体而言,研究者希望回答三个核心问题:其一,当前AI系统面临的安全威胁在逻辑上是否存在统一的数学描述方式?其二,不同类型的攻击之间是否存在深层的依赖关系和反馈回路,使得单一攻击可能引发连锁效应?其三,在基础模型时代,传统的安全假设是否已经失效,又需要建立怎样的新防御范式?
研究贡献:本文的学术贡献体现在三个层面。
首先,作者创造性地提出了以"数据-模型"交互为核心的四维威胁分类框架,将所有AI安全攻击归纳为D→D、D→M、M→D、M→M四类,并引入双层优化(Bilevel Optimization)的数学语言对各类攻击进行统一形式化,这是迄今为止对AI安全威胁最为系统和严谨的分类尝试。
其次,论文系统梳理了基础模型时代的新型攻击面,包括大语言模型的越狱攻击与有害微调、扩散模型的版权水印绕过、多模态模型的跨模态推理操控等,深入分析了这些新兴威胁与传统攻击之间的继承与演化关系。
第三,论文在分析攻击之外,同等深度地审视了防御体系,从数据净化到防御性训练,从水印嵌入到输出扰动,全面梳理了各类防御策略的原理、适用场景与局限性,并指出了当前防御研究在系统性、实用性方面存在的不足,为未来研究指明了方向。
引言
近年来,以GPT-4、DALL-E、Stable Diffusion为代表的基础模型席卷全球,深刻改变了人工智能的技术格局与应用边界。这些模型凭借海量数据训练获得的强大泛化能力,正在医疗、法律、金融、教育等关键领域发挥日益重要的作用。然而,能力的跃升往往伴随着新的风险——基础模型庞大的参数规模、对海量训练数据的深度依赖以及广泛的下游部署,使其暴露在前所未有的安全威胁之下。

传统AI安全研究已经积累了相当丰富的成果,对抗样本攻击、数据投毒攻击、成员推理攻击等方向各自形成了独立的研究社区和方法论体系。然而,这种碎片化的研究范式带来了严重的认知盲区:研究者往往只关注某一类攻击,对其他类型攻击知之甚少;攻击与防御研究之间缺乏系统性的对应关系,导致防御工作常常滞后于攻击演化;更重要的是,当多种攻击协同发生时,其叠加效应往往远超单一攻击,而现有研究对此几乎没有系统性的探讨。
面对这一困境,本文作者认为亟需一个统一的理论框架,既能容纳现有的所有攻击类型,又能揭示它们之间的内在联系。研究团队以数据(Data)和模型(Model)作为AI系统的两个核心要素,观察到几乎所有AI安全威胁都可以被理解为这两个要素之间的单向或双向"破坏性交互"——攻击者要么试图破坏数据来影响模型,要么试图从模型中窃取关于数据的信息,要么直接针对模型本身发动攻击。基于这一洞察,四维威胁分类体系(D→D、D→M、M→D、M→M)应运而生,为整个AI安全领域提供了一张清晰的全景地图。
统一闭环分类框架
论文的核心理论贡献是一套以双层优化为数学基础的统一威胁分类框架。所谓双层优化,是指攻击问题可以被建模为一个嵌套的优化过程:在外层,攻击者最大化其攻击目标(如模型性能损失或隐私泄露量);在内层,模型依据被扰动后的数据进行正常训练或推理。这种抽象不仅为攻击提供了统一的数学语言,更揭示了不同攻击类型在优化问题结构上的深刻相似性。
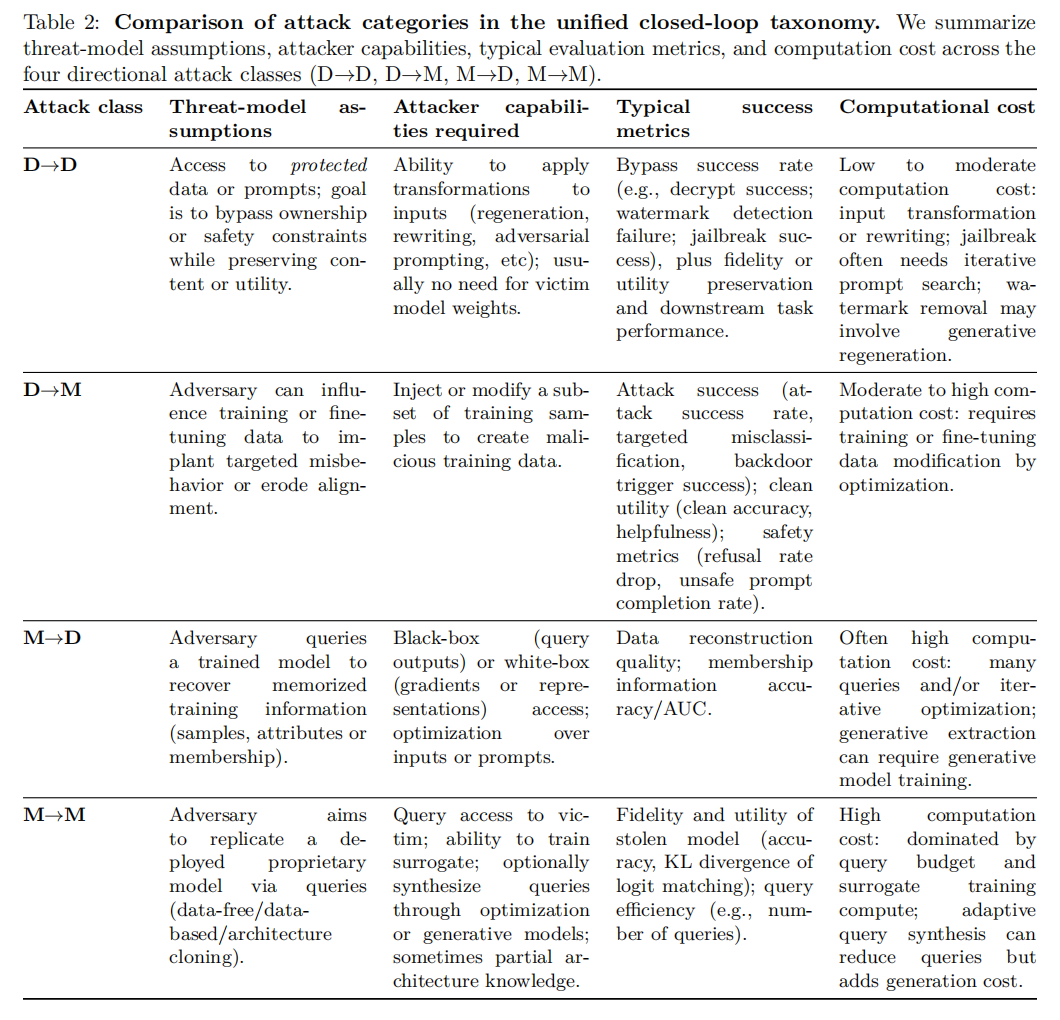
四个方向维度的具体含义如下。D→D(数据到数据)方向描述的是攻击者在数据空间内直接操控的行为,典型场景是绕过版权水印保护或破解数据加密机制,攻击目标是数据本身的完整性和归属性。D→M(数据到模型)方向描述的是攻击者通过污染训练数据来干预模型学习的行为,涵盖投毒攻击、后门攻击、有害微调攻击以及越狱攻击,攻击目标是模型的行为和输出。M→D(模型到数据)方向描述的是攻击者借助模型查询来窃取训练数据信息的行为,包括模型逆转攻击、成员推理攻击和训练数据提取攻击,攻击目标是数据的隐私性。M→M(模型到模型)方向描述的是攻击者通过反复查询目标模型来重构或窃取其参数和架构的行为,即模型窃取(Model Stealing)攻击,攻击目标是模型的知识产权。
这四个方向共同构成了一个闭环生态:攻击者可以先通过D→D绕过数据保护,再利用未受保护的数据执行D→M投毒攻击;或者先通过M→D窃取训练数据,再利用这些数据精心设计D→M攻击。各方向之间的反馈回路意味着单一攻击的危害可能远超其表面效果,而忽视某一方向的防御则可能造成整个防御体系的系统性失效。
数据到数据(D→D)
D→D类攻击的本质是在数据层面实施的"保护绕过"行为。在这一方向下,研究者重点分析了两类核心威胁:数据版权水印的规避与数据加密机制的破解。
在水印攻击领域,随着生成式AI的普及,版权保护水印被广泛嵌入图像、文本和音频数据中,以标记其来源和使用权限。然而,攻击者可以利用图像变换、噪声注入、风格迁移等手段消除或改变水印信号,使受保护的数据脱离版权追踪。在基础模型时代,这一问题变得尤为突出——扩散模型生成的图像往往难以通过传统水印进行有效保护,因为生成过程本身就会对水印结构造成破坏。研究者梳理了从传统图像处理攻击到基于深度学习的对抗性水印消除方法的演化路径,指出隐式神经表示水印可能是应对这一挑战的有前景方向。
在数据加密与访问控制层面,研究者关注的是如何通过对机器学习模型的查询来推断或重构原本受加密保护的敏感数据。这类攻击往往与M→D类攻击形成联动,共同构成对数据保护机制的系统性挑战。论文指出,现有数据保护机制大多基于传统密码学假设,对AI驱动的侧信道攻击缺乏有效应对,这为未来的安全研究提出了新的命题。
防御层面,作者系统梳理了水印嵌入强度与图像质量之间的权衡关系,以及差分隐私技术在数据保护中的应用现状,指出鲁棒水印与可证明安全的数据保护方案是这一方向最迫切的研究需求。
数据到模型(D→M)
D→M是整篇论文篇幅最重、也是与基础模型关联最为紧密的攻击方向。这一方向下的攻击均以操控训练数据为手段,目标是使训练后的模型产生攻击者期望的恶意行为。
投毒攻击(Data Poisoning)是这一方向的经典代表。攻击者向训练集中注入少量精心设计的恶意样本,使模型在特定条件下产生错误预测或有偏见的输出。在传统机器学习时代,投毒攻击通常需要攻击者直接访问训练数据;而在基础模型时代,由于预训练数据集规模庞大且来源复杂,从互联网抓取的数据中混入恶意样本的风险极难被检测。研究表明,在包含数十亿样本的预训练数据集中,即使污染比例低至0.01%,也可能对下游任务造成显著影响。
后门攻击(Backdoor Attack)是投毒攻击的进阶形态,攻击者不仅污染数据,还在模型中植入隐藏的"触发器"——当输入包含特定触发图案或词汇时,模型便会激活后门,产生攻击者预设的输出。在大语言模型中,这种攻击可以被设计为极度隐蔽的形式:触发词可以是日常语言中罕见的词汇组合,正常使用时完全无法觉察,而一旦被激活则可能产生严重的有害输出。
有害微调攻击(Harmful Fine-tuning Attack)是基础模型时代涌现的全新威胁,专门针对大语言模型的指令微调阶段。由于商业LLM通常提供微调API以满足用户的定制化需求,攻击者可以通过注入极少量的有害指令样本,绕过安全对齐机制,使经过安全训练的模型重新恢复产生有害内容的能力。研究表明,仅需数十条恶意微调样本,即可显著削弱GPT类模型的安全防护。
越狱攻击(Jailbreak Attack)从另一个角度挑战LLM的安全边界。不同于直接修改训练数据,越狱攻击通过精心设计的推理时提示词,诱导对齐后的模型违反自身的安全约束,生成有害、歧视性或危险内容。从早期的角色扮演提示词到如今基于优化的自动化越狱方法,攻击技术的演化速度已经超过了主流安全对齐机制的防御能力。
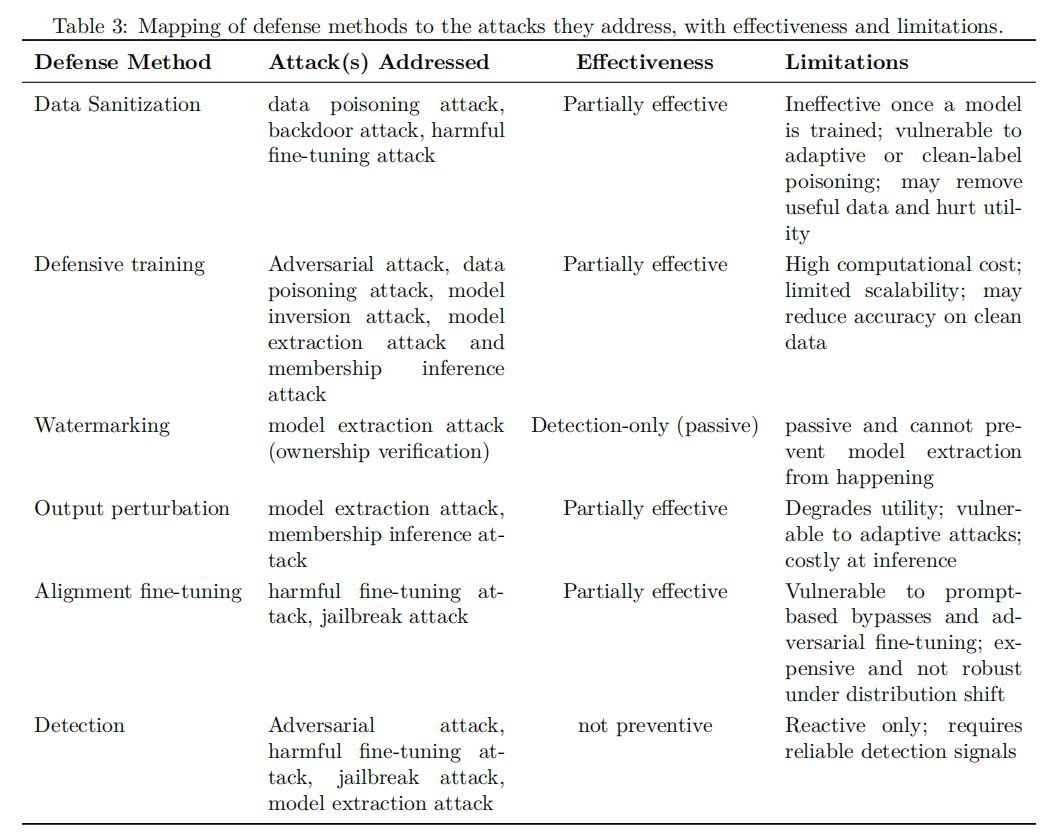
防御方面,数据净化(Data Sanitization)通过异常检测算法识别并过滤潜在的恶意样本;防御性训练(Defensive Training)通过引入对抗样本扩充训练集,提升模型对分布外输入的鲁棒性;对齐微调(Alignment Fine-tuning)则通过RLHF等技术将人类价值观嵌入模型的决策过程,是当前主流商业LLM最主要的安全保障机制。然而,这些防御手段在面对精心设计的组合攻击时均存在明显的鲁棒性缺口。
模型到数据(M→D)
如果说D→M攻击的目标是破坏模型的行为,那么M→D攻击的目标则是从模型中"反向提取"关于其训练数据的敏感信息。这一方向下的攻击是AI隐私安全领域的核心议题。
模型逆转攻击(Model Inversion Attack)尝试根据模型的输出重构其训练数据的近似表示。攻击者通过反复查询模型并观察其置信度分数,结合梯度优化,可以生成与训练数据高度相似的"影子数据"。在人脸识别模型上的研究表明,即使不直接访问原始训练图像,攻击者也可以通过模型逆转重构出可辨认的人脸图像,对训练数据中涉及的个人隐私构成严重威胁。在基础模型时代,大型多模态模型存储的"压缩"知识更为丰富,模型逆转攻击的危害潜力也相应放大。
成员推理攻击(Membership Inference Attack)的目标相对更为基础但同样危险:判断某个具体样本是否曾经出现在模型的训练数据中。这种能力看似简单,却具有严重的隐私含义——医院病历是否被用于训练某医疗AI、特定用户的私密聊天记录是否出现在语言模型的训练集中,这些问题都可以通过成员推理攻击加以探查。研究表明,当模型存在过拟合现象时,成员推理攻击的成功率会显著提升,这意味着大型基础模型更容易成为这类攻击的高价值目标。
训练数据提取攻击(Training Data Extraction)是上述两类攻击的更强形式,目标是直接从模型中提取逐字逐句的训练数据文本。这一威胁在大语言模型上已得到充分实证——通过特定的提示词策略,研究者已成功从GPT-2和其他开源语言模型中提取出大量训练语料原文,包括个人信息、版权内容等敏感数据。
抵御M→D攻击的防御策略主要包括差分隐私训练(Differential Privacy Training)和输出扰动(Output Perturbation)两类。差分隐私通过在训练梯度中注入校准噪声,为每个训练样本提供可证明的隐私保障;输出扰动则通过在模型输出中添加随机化,降低攻击者从输出中提取训练数据信息的能力。然而,这两种方法均存在隐私-效用权衡的根本性限制,在实践中难以同时满足强隐私保障和高模型性能的双重要求。
模型到模型(M→M)
M→M方向涵盖的是模型知识产权保护领域最核心的威胁:模型窃取攻击(Model Stealing / Model Extraction Attack)。攻击者在无法直接访问目标模型参数的黑盒条件下,通过大量查询目标模型的API接口,收集输入-输出对,进而训练一个功能等价的替代模型。
模型窃取攻击的商业危害是直接而巨大的。训练一个高性能的大型模型需要数百万美元的计算资源投入,而攻击者只需支付相对廉价的API查询费用,便可获得一个性能相近的"影子模型",绕过知识产权保护,实现技术能力的低成本复制。研究表明,即使目标模型只提供最终类别标签而不暴露置信度分数,攻击者仍然可以在有限的查询预算内完成有效的模型窃取。
在基础模型时代,模型窃取攻击面临新的挑战与机遇。一方面,大型基础模型的参数规模巨大,完整复制的查询成本极高;另一方面,由于基础模型往往具有强大的知识迁移能力,攻击者可以只针对特定的下游任务子集进行窃取,大幅降低攻击成本。此外,针对语言模型的功能性窃取(Functionality Stealing)已经超越了传统的分类模型窃取框架,攻击者可以通过提示词工程系统性地探测模型的推理能力边界,从而以更少的查询次数实现更精准的模型仿制。
防御侧,针对M→M攻击最有效的技术包括API限速与异常查询检测、输出随机化、以及主动水印防御——即在模型的输出中嵌入可验证的隐藏水印,使所有经由该模型生成的输出都携带可追溯的"指纹"。一旦攻击者用窃取到的影子模型提供服务,模型所有者便可通过水印检测证明其知识产权归属。
攻击交互与闭环效应
论文最具创新性的分析章节之一,是对四类攻击之间交互关系与反馈回路的系统性梳理。研究者指出,在现实威胁场景中,攻击往往不是孤立发生的,而是以复杂的方式相互协同,形成"攻击链"或"攻击生态"。
一个典型的攻击链示例是:攻击者首先发动M→D成员推理攻击,确认某个敏感数据样本出现在目标模型的训练集中(信息侦察阶段);随后利用这一知识针对该样本设计高针对性的D→M投毒攻击(精准打击阶段);最终通过D→D水印绕过攻击,消除被修改数据的版权痕迹,掩盖攻击行为(痕迹清除阶段)。在这一链条中,每一步攻击都为下一步攻击提供了关键信息或创造了有利条件。
论文还指出了一个重要的"正反馈"现象:某些攻击成功后会降低模型的安全性,从而使后续攻击变得更加容易。例如,后门攻击成功后,被植入后门的模型对其他对抗性扰动的鲁棒性也会显著下降,攻击者可以以更低的成本在同一模型上实施额外的攻击。这种攻击之间的"共生"关系意味着,防御策略必须以系统性的视角设计,而不能仅仅针对单一攻击类型进行优化,否则"修补了一个漏洞,却放大了另一个漏洞"的困境将难以避免。
此外,论文还分析了基础模型特有的"迁移攻击"问题:针对某一基础模型的攻击,往往可以通过微调或迁移学习在其衍生的下游模型上"继承"下来。这意味着基础模型层面的任何安全漏洞,都可能以级联方式扩散至整个基础模型生态系统,其影响范围远超传统AI模型安全事件。
实证评估
论文的实证评估部分选取了医学图像分类场景,以MedMNIST/PathMNIST数据集为实验载体,对四类代表性攻击进行了系统性的量化分析,为理论框架提供了实验支撑。
实验环境以ResNet系列模型作为目标模型,分别在洁净训练集和污染训练集上进行训练,并设计了多个评估维度。在D→M投毒攻击实验中,研究者比较了不同污染率(0.1%、1%、5%、10%)下模型性能的变化曲线,结果显示医学图像分类任务对低污染率攻击具有相当的鲁棒性,但当污染率超过5%时,分类准确率开始出现显著下滑,尤其在特定病理类别上的误分率急剧上升,提示在医疗AI部署中数据来源审查的不可或缺性。
在M→D成员推理攻击实验中,研究者验证了模型过拟合程度与成员推理攻击成功率之间的正相关关系。训练集准确率与测试集准确率的差值越大,成员推理攻击的AUC值越高,在差值超过15%的实验组中,攻击者可以以超过75%的准确率判断样本的成员身份。这一结果强调了模型正则化和早停策略不仅对泛化性能有益,也对隐私保护具有重要意义。
针对M→M模型窃取攻击,实验结果表明,在仅使用3000次查询的前提下,攻击者可以训练出一个在测试集上达到原模型87%性能的替代模型,这在医疗AI商业化场景中意味着巨大的知识产权风险。实验同时验证了在API输出中引入随机化扰动可以有效降低影子模型的逼近精度,但代价是增加原始API的误诊率,这一权衡在医疗场景中尤为敏感。
差分隐私防御的实验结果则呈现了更为复杂的图景:在满足较强隐私保障(ε≤1)的配置下,模型分类准确率出现了6-12个百分点的显著下降;而将隐私预算放宽至ε=10时,准确率损失可降至可接受范围,但对应的隐私保障强度也大打折扣。这一实验生动地揭示了当前AI隐私保护技术在实用性与安全性之间难以两全的根本矛盾。
研究结论
站在基础模型时代的历史节点上回望,AI安全研究正在经历一次深刻的范式转型。本文通过构建统一闭环分类框架,将长期以来各自为战的攻击研究纳入一个相互关联的整体视野,为研究者提供了理解AI安全威胁格局的新坐标系。
研究的主要结论体现在三个层面。在威胁认知层面,双层优化框架揭示了看似差异悬殊的各类攻击在数学本质上的统一性,这不仅具有理论价值,更为设计统一的防御机制提供了可能;在威胁互动层面,系统分析各类攻击之间的依赖关系与反馈回路,是理解和应对真实威胁环境中复合攻击的关键前提;在基础模型适用性层面,研究表明传统安全假设在基础模型时代面临根本性挑战,需要针对大规模预训练、指令微调、下游部署等新型范式建立专门的安全理论。
面向未来,论文指出了若干值得深入探索的研究方向。第一,针对多模态基础模型的统一安全评估框架目前仍付之阙如,如何量化跨模态攻击面的威胁严重性是一个开放性问题。第二,在实用性约束下的差分隐私技术,如何在不牺牲模型性能的前提下提供更强的隐私保障,是隐私计算领域最紧迫的工程挑战。第三,LLM时代的后门攻击与防御面临全新的复杂性——当"触发器"可以是任意的自然语言模式时,检测和清除后门的难度将指数级提升。第四,可信AI生态系统的建设需要技术、法规、标准化等多个维度的协同推进,纯技术路径无法解决基础模型时代的系统性安全挑战。
这项研究以一张清晰的全景地图,照亮了AI安全领域的复杂地形,也如实标注了尚待探索的未知领域。在人工智能技术加速渗透关键基础设施和社会生活各个层面的今天,建立系统性的AI安全认知框架,对于所有从事AI研究、开发和部署的从业者而言,已不再是可选项,而是必修课。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
