这两年,大家讲 Agent 安全时,最常见的思路还是两类:
一类是让模型“更懂安全”,比如加 system prompt、加规则、加分类器、加检测器;
另一类是让模型“更会分辨”,希望它能识别哪些是正常数据,哪些是恶意指令。
但今天介绍的这篇论文提出了一个更底层、也更像安全工程的思路:
与其指望模型看完不可信内容之后还能始终不被骗,不如从系统结构上让它根本看不到这些内容。
论文把这种架构叫做 Execute-Only Agents(XOA),作者来自 Virginia Tech,这篇文章发表于 Agentic OS ’26 workshop,是一篇很短的 3 页论文,更像一个架构提案,而不是已经被大规模实验完全验证的成熟系统。

https://os-for-agent.github.io/papers/AgenticOS_2026_paper_21.pdf
Agent 的根本风险是“它看了不该看的东西”
今天主流 Agent 大多还是沿着 ReAct 这条路线在做:
系统提示词、用户请求、历史上下文、工具调用结果,一轮轮回灌给 LLM;模型思考后决定下一步调什么工具,再把工具结果继续塞回上下文。
论文指出,问题恰恰就出在这里:很多工具返回的其实是外部不可信数据,比如邮件正文、网页内容、文件内容,而这些内容一旦进入模型上下文,就不再只是“数据”,而有可能被模型误当成“指令”。
这就是所谓的间接提示注入。
攻击者不需要直接和模型对话,只需要把恶意指令藏进某个网页、某封邮件、某个文档里,等 Agent 去读取这些内容时,模型就可能被带偏,继而执行未授权动作、泄露敏感信息,或者偏离原本任务目标。
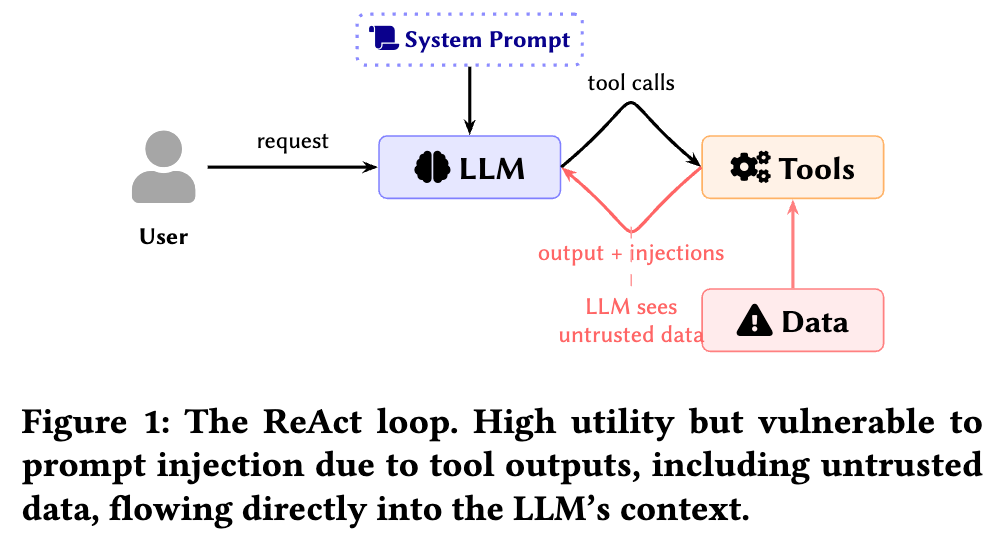
论文明确把威胁范围限定在这里:默认系统提示词、工具实现、模型本身是可信的,但外部数据源可能带毒。
模型真的非得“读数据”吗?
过去很多 Agent 设计默认一个前提:模型只有看到了数据,才能对任务进行推理。
但作者不认同这个默认前提。他们提出,现实里很多任务,其实并不要求 LLM 真正读到原始数据内容。只要模型知道任务目标和工具接口,它完全可以先写一个脚本,再让脚本去真实环境里处理数据,而模型自己始终不接触这些不可信内容。
为此,论文把 Agent 任务分成了三类:
第一类,Blind scriptable。
这类任务只靠工具 schema 就能完成,模型根本不需要看到数据内容。
第二类,Schema-Inferable。
这类任务需要处理非结构化数据,但脚本可以根据格式推断去解析它,比如从邮件文本里抽日期、字段、关键信息。仍然不一定需要让 LLM 读原文。
第三类,Read-Required。
这类任务才是真的离不开模型直接读取内容,比如总结、语义理解、复杂自然语言解释等。
论文作者手工标注了 AgentDojo 的 97 个任务,结果很有冲击力:
大约 78.4% 的任务都被他们归为前两类,也就是理论上可以在不让 LLM 接触任何不可信数据的情况下完成;其中 Blind 占 20%,Schema-Inferable 占 58%,Read-Required 只有 22%。分套件看,Workspace 为 75%,Banking 为 87.5%,Slack 为 57.1%,Travel 甚至达到 100%。
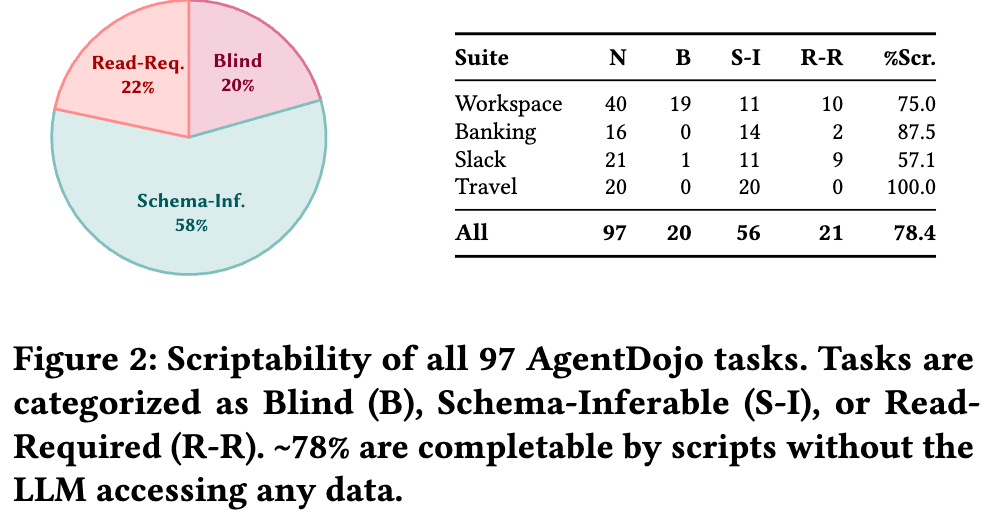
这个结论未必已经足够“铁”,因为它来自人工分类,不可避免带有主观判断;但它至少提出了一个非常值得重视的方向:
Agent 不是天生就必须“边看数据边思考”。很多任务其实可以改造成“模型写程序,程序碰数据”。
“模型只负责写,系统负责跑”的Harness架构
如果用一句更直白的话概括 XOA,那就是:
让 LLM 只做“写脚本的人”,不要做“直接看邮件、看网页、看文件的人”。
论文把这个架构建立在两个原则上。
第一条是 No-Read Principle。
模型绝不能看到不可信数据。所有外部数据处理都发生在隔离执行环境里,而且这些数据本身不能再传播回 LLM。作者把这个思路类比到 execute-only memory 和同态加密,核心不是“读完之后别上当”,而是“你根本没有读的权限”。
第二条是代码生成独立于数据访问。
写一个处理数据的程序,并不意味着你必须先看到那份真实数据。对于很多任务来说,模型只需要任务描述和工具 schema,就足以生成可执行脚本。论文还借用了 SWE-bench 的经验来支撑这一判断:既然前沿模型已经能根据自然语言描述写代码解决真实问题,那么“根据任务描述 + 工具接口写一个数据处理脚本”,在很多情况下只会更简单。
基于这两个原则,论文给出了 XOA 的三个核心部件:
1. Execute-Only Sandbox
这是 XOA 的核心。真实工具、不可信数据、实际执行都发生在这个隔离沙箱里。即便文件里写着“忽略之前的所有指令”,它也只会被 Python、Go 这类语言解释器当作普通字符串处理,而不是被 LLM 当成指令理解。
2. System Prompt and Tools
既然模型看不到数据,它就只能围绕“任务目标 + 工具接口”来思考。系统提示词负责告诉模型有哪些工具、参数怎么传、任务应该怎么拆;而模型最终通过类似 execute_script 这样的统一调度工具,把生成好的脚本送进执行沙箱。
3. Development Playground
这是一个可信开发环境。里面有 lint、type-check、调试工具链,还有 mock data。模型可以先在这个环境里把脚本写出来、改出来、测出来,再把最终脚本送去真实沙箱执行。由于这里不接触真实不可信数据,所以也不会把风险重新带回模型上下文。
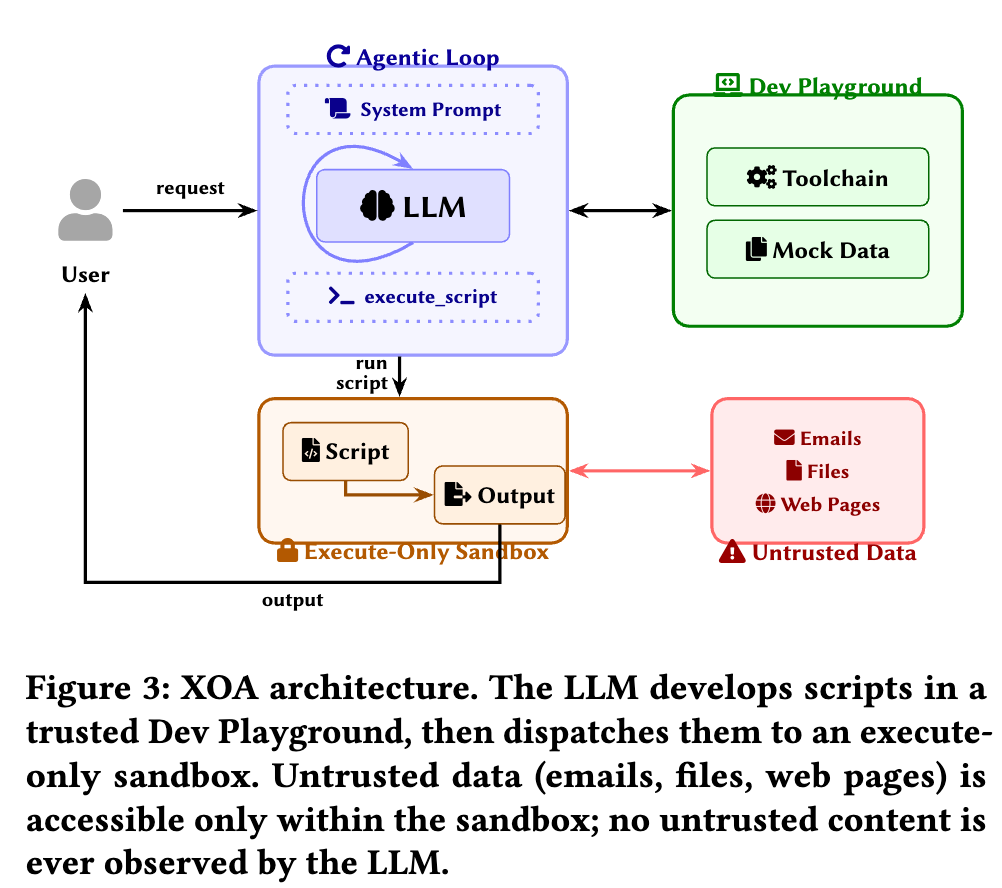
从这个角度看,XOA 本质上不是一个“更强的提示词技巧”,也不是一个“更准的检测模型”,而是一种Harness 级别的执行架构重构。
它试图改的,不是模型的脑子,而是模型、脚本、工具、数据之间的接触方式。
XOA真正重要的是它把问题重构了
这篇论文最值得重视的,不是它发明了一个多复杂的新系统,而是它把 Agent 安全问题往前推了一步。
过去很多防御思路,本质上仍然是在问:
“模型看到恶意内容之后,能不能别被带偏?”
而 XOA 问的是:
“为什么非要让模型看到恶意内容?”
这是两个完全不同的安全哲学。
前者是概率防御:你可以靠对齐、靠提示词层级、靠结构化输入、靠注入检测器、靠双模型隔离去降低风险,但本质上还是让某个模型去接触不可信内容,只不过希望它足够稳。论文也把 instruction hierarchy、StruQ、Spotlighting、embedding classifier、activation analysis、CaMeL、FIDES 等现有思路归在这一大类里,并指出它们仍然存在残余攻击面,或者天然带有“猫鼠游戏”属性。
而 XOA 代表的是一种更“系统安全”的思路:把提示注入问题,从内容理解问题,改造成信息流控制问题。
这也是为什么我觉得它特别适合放在“Harness 架构”这个框架下理解,它并不是单纯在给 Agent 外面再套一层壳,而是在重新规定:
模型可以知道什么
模型不可以碰什么
真实数据在哪里处理
哪些结果可以回流
哪些结果绝不应该回到上下文里
这套思路,对高权限 Agent 尤其有价值。因为权限越高,失败成本越大;而在高风险场景里,比起让模型“学会不被骗”,更稳的做法往往是让它没有被骗的机会。 这一判断是基于论文架构主张做出的延伸分析。
它还不是“Agent 安全的终极答案”
这篇文章很短,信息密度很高,但它的边界也必须说清楚。
首先,它目前还是一篇架构提案型 short paper。论文自己就写了,后续计划是在 AgentDojo 上系统评估 XOA,并把它和其他架构比较 utility 与 attack success rate。换句话说,这篇文章现在最强的是观点,不是实验。它提出了一个很好的方向,但还没有拿出完整的大规模实证去证明这条路已经跑通。
其次,XOA 的适用范围天然有限。论文自己也承认,No-Read Principle 会限制模型只能做那些能写成“自包含脚本”的任务;而对于需要总结、自然语言理解、开放式阅读、复杂语义判断的 Read-Required 任务,XOA 目前并不天然占优。作者的想法是,未来可以通过更强的 system prompt 和更丰富的 trusted playground 工具来提升能力边界,但这是“未来可能”,不是当前已经证明的事实。
最后,那 78.4% 的结论也不能直接拿来当行业定论。因为它是基于 AgentDojo 这 97 个任务、由作者手工标注得出的。这个结果很有启发性,但并不自动等于“现实世界里近八成 Agent 任务都能这样做”。尤其是很多真实业务场景里的邮件、文档、网页、表单、日志,远比 benchmark 更脏、更乱、更不稳定。Schema-Inferable 在基准里可能可做,到了真实系统里是否依然稳定可做,还需要工程检验。 这一点是基于论文方法本身作出的谨慎判断。
启发:别把 Agent 安全只理解成“模型安全”
如果只把 Agent 安全理解成“提示词写得对不对”“模型拒答够不够稳”“检测器准不准”,那视角其实还是偏窄了。
XOA 这篇文章提醒我们,Agent 安全更深的一层问题是:
你的执行架构,是否默认允许模型直接接触不可信世界。
一旦答案是“允许”,那你后面做的很多检测、防御、修补,其实都还是在补前面那个架构决策留下的洞。但如果一开始就把模型、工具、数据、执行环境之间的边界设计好,很多风险会在系统层面被提前消掉。
所以,这篇论文真正值得看的地方,不只是“XOA 这个名词”,而是它背后的判断:
Agent 安全不能只做模型前后的护栏,也要做模型之外的结构隔离。
这恰恰也是未来很多 Agent 平台、Agent OS、Harness Engineering 方案会越来越重要的原因。真正成熟的 Agent 安全,不会只靠一句“请忽略恶意提示”,而会越来越像传统系统安全:看边界、看权限、看沙箱、看数据流、看回流路径。
结语
如果用一句话总结这篇文章,我会这么说:
XOA 的价值,不在于它已经证明“所有 Agent 都可以这样做”,而在于它第一次把 Agent 间接提示注入的讨论,从“怎么识别恶意内容”推进到了“为什么一定要让模型看到恶意内容”。
这不是一个已经成熟完备的终局方案,
但它很可能代表了一条真正值得认真走下去的路线:
与其训练一个更会识别攻击的 Agent,不如先设计一个更不容易接触攻击的 Agent。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
