近期,开源社区项目 Anthropic-Cybersecurity-Skills (由开发者 mukul975 维护[1])因提供高达 754 个结构化安全技能。
本文将结合该开源库的底层架构,以及墨子智能体安全运行平台 的实际运行,从技术深度客观剖析这类“海量技能库”的真实业务价值与能力边界。
一、 工程价值:从“非结构化工具”到“大模型可读API”
对于高级安全分析师而言,这754个Skill覆盖的内容可能只是常规操作。但从AI工程化的角度来看,该项目的核心贡献在于解决了大语言模型(LLM)调用复杂安全工具时的上下文过载与规范化问题 。
仔细查阅该项目的开源代码库可以发现,它遵循了 agentskills.io 标准。这个标准的设计极其克制:它将庞杂的工具封装成了“渐进式上下文(Progressive Disclosure)”[1]。每个Skill被拆分为两部分:
YAML 前置元数据(约30个Token): 包含名称、简介、所属领域(如数字取证、红队操作)。
Markdown 详细工作流(500-2000个Token): 包含前置条件(Prerequisites)、执行步骤(Workflow)和验证方法(Verification)[1]。
大模型在决策时,只需花费极少的算力扫描几百个YAML标签,命中目标后再加载详细说明[1]。这种架构有效避免了AI产生幻觉。
映射到墨子平台的实际产品界面(截图)中,我们可以看到包含云安全、威胁狩猎、恶意软件分析等26个安全域的零散能力。
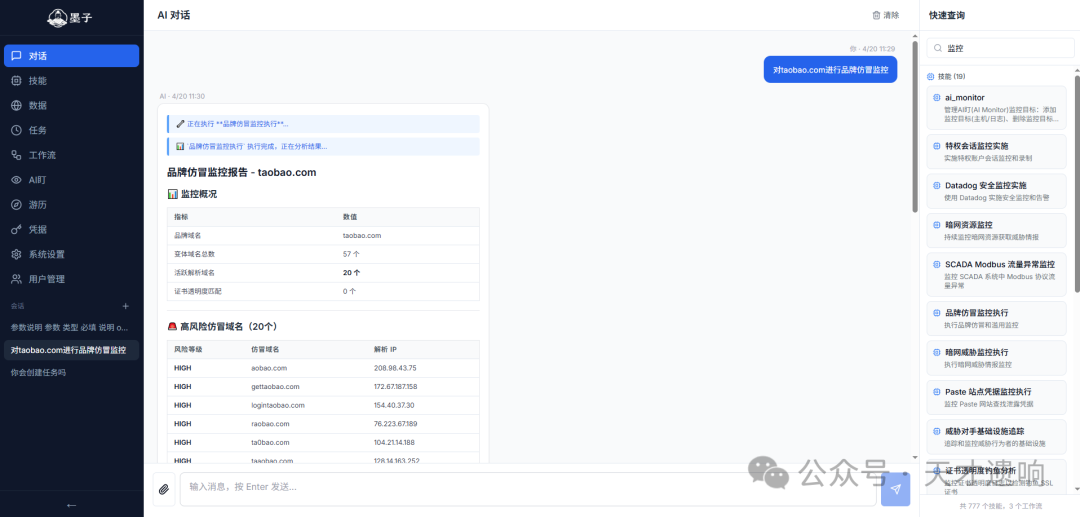
在业务落地上(截图),得益于这种标准化,AI展现出了极高的意图识别与执行效率。当用户输入“对 taobao.com 进行品牌仿冒监控”时,精确命中并执行了对应的品牌监控Skill。最终输出的不再是冗长的原始终端日志,而是经过结构化提取的高风险域名与解析IP表格。这就将安全运营的门槛大幅降低了。
此外,该库实现了统一的合规框架映射 。所有Skill均在底层打上了 MITRE ATT&CK(攻击战术)、NIST CSF 2.0(防御框架)、MITRE ATLAS(AI威胁)等五大框架的标签[1]。这意味着AI的每一次调用操作,都能直接输出符合企业审计标准的溯源报告。这在以往是需要安全工程师手动花费数小时梳理的。
二、 剖析“深度缺失”:为何754个技能堆不出一个“高级分析师”?
正如一线实战人员的直观感受——这些Skill显得“大而全,但很多只是简单的功能”。深入剖析其实现逻辑,这种“肤浅感”是当前AI Agent范式与该项目静态架构带来的必然结果。
1. 原子化功能与多步战术推理的鸿沟
阅读该项目 skills/ 目录下的具体文件(如 Volatility3 内存取证技能),可以发现其所谓的 Workflow,本质上是一份“直线型标准操作程序(SOP)”[1]。这只是对现成安全工具的“一层皮封装”。它教给大模型的只是:“执行命令A,得到结果B。”但在真实的攻防深水区,安全从来不是线性的。高级分析师在发现内存转储中有异常凭证导出(Credential Dumping)时,会进行多点关联:跳转去查EDR的遥测数据、翻阅活动目录(AD)的特定日志、甚至通过流量溯源C2控制端。目前的单一Skill无法承载这种跨领域、非线性的网状推理过程。它只提供了工具,并没有提供战术上下文)。
2. 缺乏动态容错机制与对抗环境适应性
真实网络环境是充满对抗的(脏数据、WAF拦截、目标系统版本魔改)。
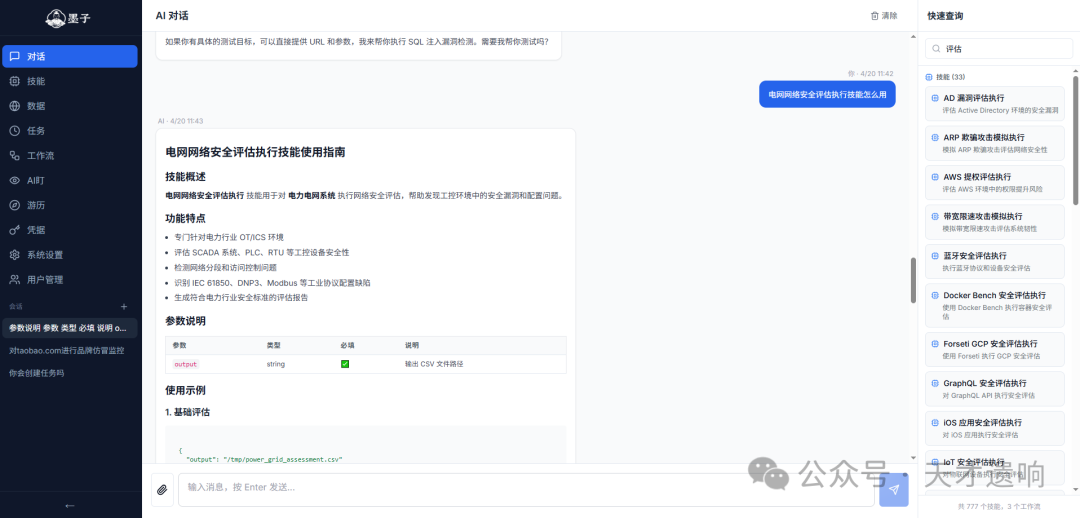
从截图中可以看到,“电网网络安全评估”被简化为输入一个输出路径(CSV)即可运行的简单指令。但在实际的工业控制系统(ICS)环境中,直接进行主动探测极易导致老旧PLC设备宕机,或者遇到私有化的 Modbus 协议返回乱码。
开源库中的 Markdown 执行逻辑是无法穷尽这些异常处理分支的。当工具执行报错时,当前的 Agent 往往会直接判定任务失败,而不具备资深专家“查看报错、分析原因、手工构造发包、绕过限制(Plan B)”的动态博弈能力。
3. 仅具备操作深度,缺乏业务逻辑深度
很多高阶漏洞(如复杂的越权、条件竞争、甚至是深入业务流的SSRF)根本无法被沉淀为通用的静态Skill。它们高度依赖于目标系统特有的业务逻辑。一个通用的“Web缓存投毒”Skill,在面对不同架构(Nginx/Varnish/CDN)以及不同业务配置时,其发包特征完全不同。这些Skill充其量只能做到通用指纹识别或低阶扫描,无法替代专家级的深度人工渗透。
三、 结语
综上所述,mukul975 维护的 Anthropic-Cybersecurity-Skills 项目[1],其核心定位应当是:为大语言模型打造的一套具有标准化接口的“基础安全工具集(Toolbox)” 。
结合墨子安全运行平台来看,它的实际价值在于将L1级别(初级)的安全运营任务实现了高度自动化 :例如基础资产测绘、IOC提取、标准合规性核查、初级告警的上下文丰富等。
但它距离实现真正的“专家级AI安全智能体”还有很长的路要走。让安全人员失业更不可能!目前,受限于LLM处理复杂长链路逻辑时的“规划漂移(Planning Drift)”,单纯增加Skill的数量并不能产生质变。要突破“大而全但深度不够”的瓶颈,未来的安全平台需要突破原子技能的限制,构建包含多Agent协同(如红队Agent与环境分析Agent博弈) 、具备企业私有知识库记忆 以及强大环境反思反馈(Reflection)能力 的动态战术引擎。
声明:本文来自天才遗响,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
