OpenAI 发布开源权重的 Privacy Filter 模型,一款专为敏感信息检测与脱敏设计的模型。

传统敏感信息检测难以适配 AI 时代需求
AI 的规模化落地,带来了海量文本数据的处理需求。
从大模型训练语料清洗、企业日志脱敏,到文档存储与检索前的敏感信息处理,
都对个人信息检测提出了更高要求。
传统敏感信息检测多依赖正则与固定格式匹配,仅能覆盖手机号、邮箱等标准字段。
对依赖上下文判断的非标准化敏感信息识别能力不足。
举个例子,文本中的名字正则如何检测?
但是AI可以。
GPT-OSS同源架构
Privacy Filter 基于 GPT-OSS 同源的预训练 checkpoint 改造而来.OpenAI将该checkpoint转换为基于隐私标签分类体系的双向token分类器,并进行后训练。
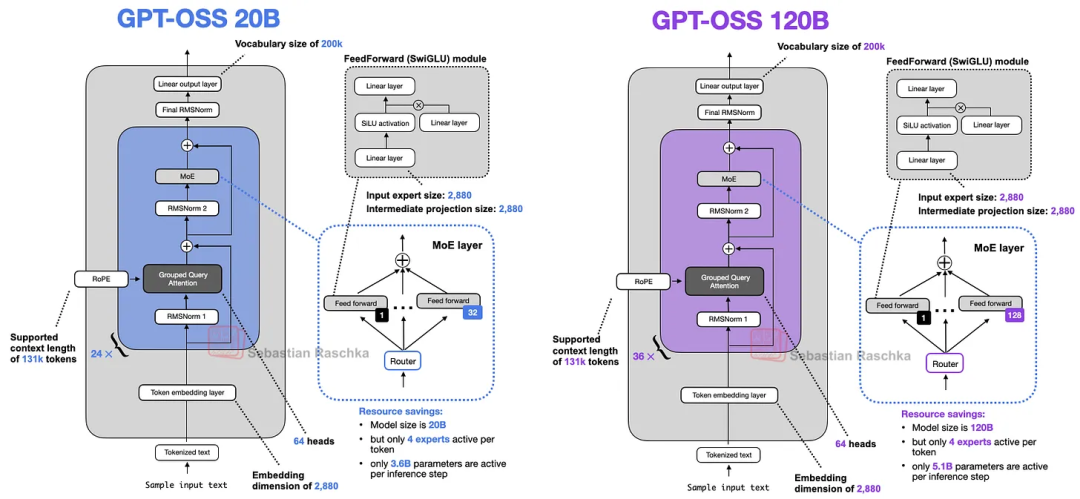
模型总参数量15 亿,活跃参数量仅5000 万.
这个参数可以本地运行,实现敏感数据 “不出设备” 即可完成脱敏。
同时模型支持128K的上下文窗口。
它能检测什么
Privacy Filter 覆盖了常见的敏感数据类型:
姓名和身份信息
地址和地理位置
邮箱和电话号码
URL 和日期
银行账号、信用卡号、ID号
API 密钥和密码
特别是 API 密钥和密码的检测,对开发者来说简直是救命神器。
多少公司因为代码里不小心提交了密钥,导致整个系统被黑客入侵。
传统的密钥检测严重依赖正则。
根据WIZ的研究,此类方法只能捕获约 60% 的潜在泄露,且误报率较高。

现在有了它,这种低级错误将成为历史。
Privacy Filter模型采用 Apache 2.0 开源许可,许可宽泛,降低了隐私保护能力的落地门槛。
实测表现
在性能测试中,Privacy Filter 展现了行业领先的检测能力。
在 PII-Masking-300k 基准测试中,模型基线版本实现了 96% 的 token 级 F1 值,其中精准率 94%,召回率 98%。
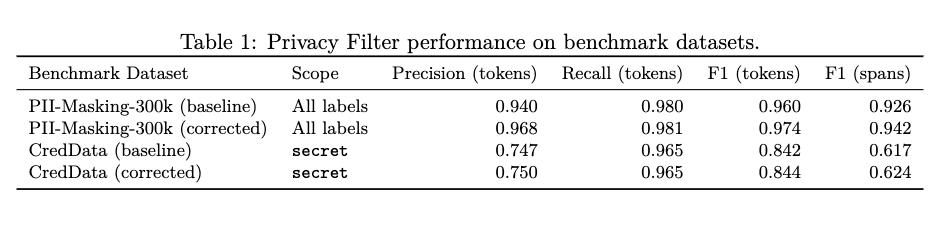
在领域适配能力上,模型的微调效率表现亮眼。
在法律与医疗场景的 SPY 数据集测试中,仅使用 10% 的训练数据进行微调,模型的 F1 值即可从原生的 54% 提升至 96%,快速适配行业敏感信息识别需求。
此外,模型在多语言与对抗场景中也有稳定表现,中文场景下 F1 值可达 91.7%。
指标计算方式:
召回率 = TP / (TP + FN)
精确率 = TP / (TP + FP)
F1 = 2PR / (P + R)
不是万能,但足够好用
OpenAI 在文档中明确,
Privacy Filter 是一款数据最小化的辅助工具,
而非匿名化解决方案、合规认证凭证,
更不能替代高风险场景下的人工合规审核。
模型的能力受限于训练的标签体系,不同企业的合规要求可能需要额外的微调与校准.
在非英语文本、小众命名规则的场景下,模型性能可能出现下降。
不过小编测试下来对于中文支持还可以,是否自谦看各位自行测试了。
同时也存在罕见标识符漏检、上下文不足时过度脱敏等潜在问题。
在医疗等高敏感场景,OpenAI建议仍需保留人工审核环节与领域专属的适配优化。
在线demo:https://huggingface.co/spaces/openai/privacy-filter
参考资料:
Introducing OpenAI Privacy Filter https://openai.com/index/introducing-openai-privacy-filter/
https://huggingface.co/openai/privacy-filter
Model Card for OpenAI Privacy Filter https://cdn.openai.com/pdf/c66281ed-b638-456a-8ce1-97e9f5264a90/OpenAI-Privacy-Filter-Model-Card.pdf
https://github.com/openai/privacy-filter
声明:本文来自玄月调查小组,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
